Co to jest magazyn typu „data lake”?
Usługa Data Lake to repozytorium magazynu, które przechowuje dużą ilość danych w natywnym, nieprzetworzonym formacie. Magazyny data lake są zoptymalizowane pod kątem skalowania do terabajtów i petabajtów danych. Dane zazwyczaj pochodzą z wielu heterogenicznych źródeł i mogą być ustrukturyzowane, częściowo ustrukturyzowane lub nieustrukturyzowane. Pomysł z usługą Data Lake polega na przechowywaniu wszystkiego w oryginalnym, nieprzetłumaczonym stanie. Takie podejście różni się od tradycyjnego magazynu danych, który przekształca i przetwarza dane w momencie pozyskiwania.
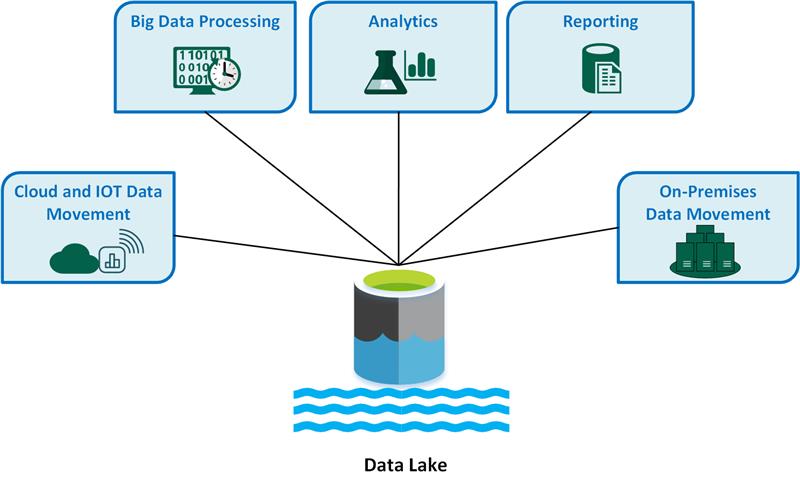
Poniżej przedstawiono kluczowe przypadki użycia usługi Data Lake:
- Przenoszenie danych w chmurze i IoT
- Przetwarzanie danych big data
- Analizy
- Raportowanie
- Przenoszenie danych lokalnych
Zalety usługi Data Lake:
- Dane nigdy nie są odrzucane, ponieważ dane są przechowywane w formacie nieprzetworzonym. Jest to szczególnie przydatne w środowisku danych big data, gdy możesz nie wiedzieć z wyprzedzeniem, jakie szczegółowe informacje są dostępne z danych.
- Użytkownicy mogą eksplorować dane i tworzyć własne zapytania.
- Może być szybszy niż tradycyjne narzędzia ETL.
- Bardziej elastyczny niż magazyn danych, ponieważ może przechowywać dane nieustrukturyzowane i częściowo ustrukturyzowane.
Kompletne rozwiązanie typu data lake składa się zarówno z magazynu, jak i przetwarzania. Usługa Data Lake Storage została zaprojektowana pod kątem odporności na uszkodzenia, nieskończonej skalowalności i wysokiej przepływności pozyskiwania danych o różnych kształtach i rozmiarach. Przetwarzanie w usłudze Data Lake obejmuje co najmniej jeden aparat przetwarzania utworzony z uwzględnieniem tych celów i może działać na danych przechowywanych w usłudze Data Lake na dużą skalę.
Kiedy należy używać usługi Data Lake
Typowe zastosowania usługi Data Lake obejmują eksplorację danych, analizę danych i uczenie maszynowe.
Usługa Data Lake może również pełnić rolę źródła danych dla magazynu danych. W przypadku tego podejścia nieprzetworzone dane są pozyskiwane do usługi Data Lake, a następnie przekształcane w ustrukturyzowany format zapytań. Zazwyczaj ta transformacja korzysta z potoku ELT (extract-load-transform), w którym dane są pozyskiwane i przekształcane. Dane źródłowe, które są już relacyjne, mogą przechodzić bezpośrednio do magazynu danych przy użyciu procesu ETL, pomijając magazyn danych typu data lake.
Magazyny data lake są często używane w scenariuszach przesyłania strumieniowego zdarzeń lub IoT, ponieważ mogą utrwalać duże ilości danych relacyjnych i nierelacyjnych bez przekształcania ani definicji schematu. Są one tworzone w celu obsługi dużych ilości małych zapisów przy małych opóźnieniach i są zoptymalizowane pod kątem ogromnej przepływności.
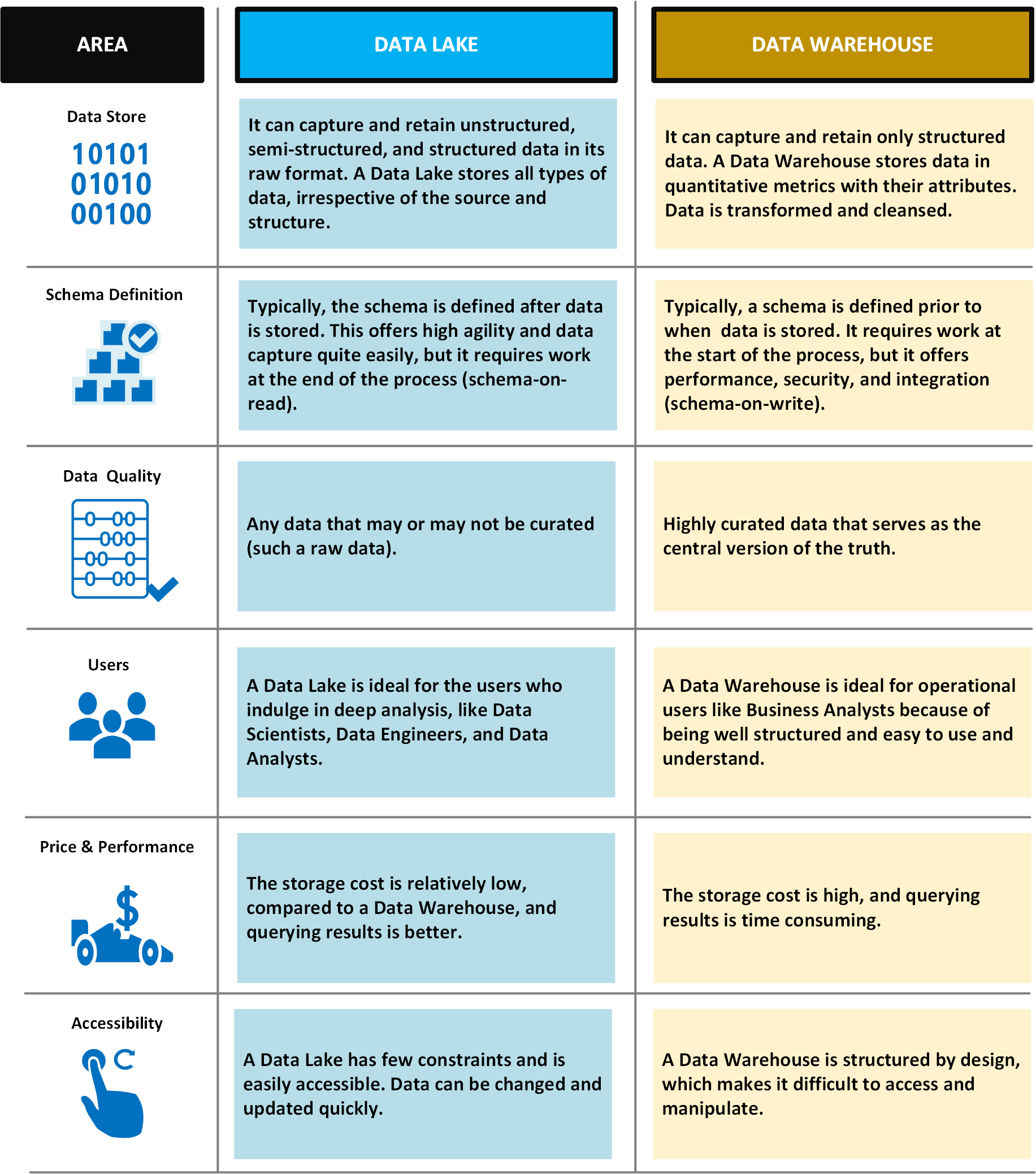
W poniższej tabeli porównano magazyny danych i magazyny danych:
Wyzwania
- Brak schematu lub metadanych opisowych może utrudnić korzystanie z danych lub wykonywanie zapytań.
- Brak spójności semantycznej w danych może utrudnić przeprowadzenie analizy danych, chyba że użytkownicy są wysoko wykwalifikowanych w analizie danych.
- Trudno jest zagwarantować jakość danych przechodzących do magazynu data lake.
- Bez odpowiedniego ładu problemy z kontrolą dostępu i prywatnością mogą być problemami. Jakie informacje będą dostępne w usłudze Data Lake, kto może uzyskiwać dostęp do tych danych i w jakich zastosowaniach?
- Usługa Data Lake może nie być najlepszym sposobem integrowania danych, które są już relacyjne.
- Sama usługa Data Lake nie zapewnia zintegrowanych ani całościowych widoków w całej organizacji.
- Magazyn data lake może stać się ziemią dumpingu dla danych, które nigdy nie są analizowane lub wydobywane w celu uzyskania szczegółowych informacji.
Wybór technologi
Tworzenie rozwiązań data lake przy użyciu następujących usług oferowanych przez platformę Azure:
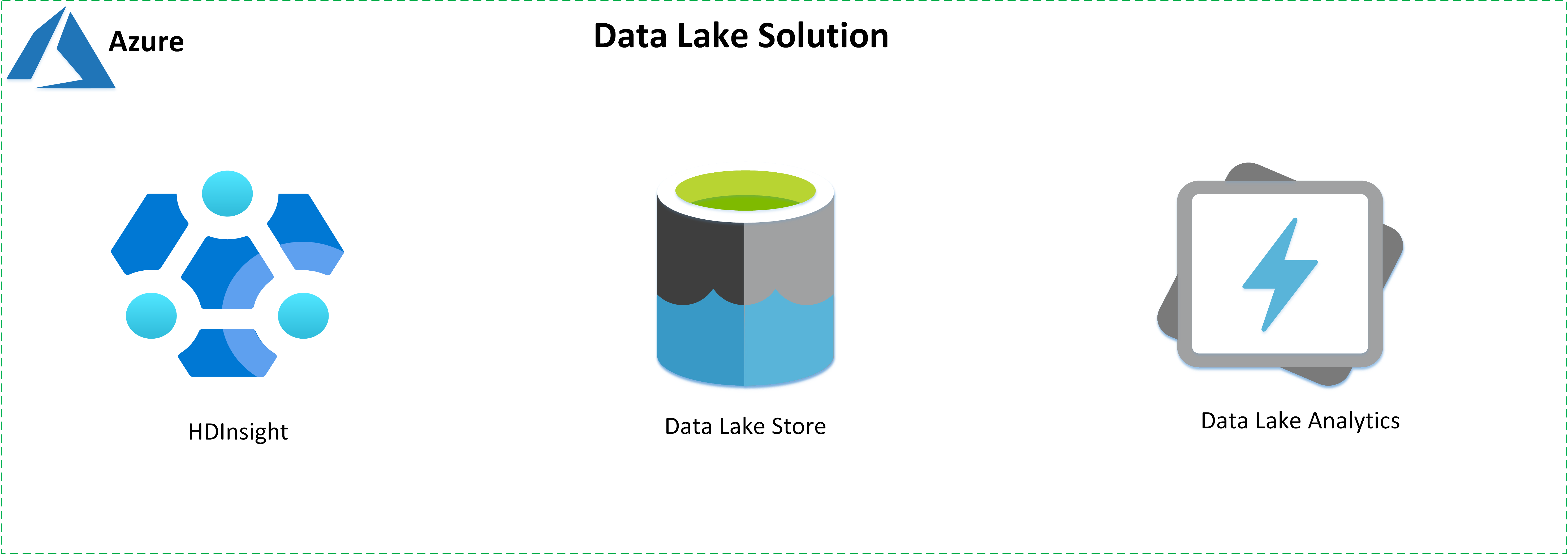
- Usługa Azure HD Insight to zarządzana, w pełni spektrum, usługa analizy typu open source w chmurze dla przedsiębiorstw.
- Azure Data Lake Store to hiperskala, zgodne z platformą Hadoop repozytorium.
- Usługa Azure Data Lake Analytics to usługa zadań analizy na żądanie, która upraszcza analizę danych big data.
Współautorzy
Ten artykuł jest obsługiwany przez firmę Microsoft. Pierwotnie został napisany przez następujących współautorów.
Główny autor:
- Avijit Prasad | Konsultant ds. chmury
Następne kroki
- Co to jest usługa Azure HDInsight?
- Wprowadzenie do usługi Azure Data Lake Storage
- Dokumentacja usługi Azure Data Lake Analytics
- Wprowadzenie do usługi Azure Data Lake Storage (moduł szkoleniowy)
- Co to jest usługa Data Lake?
Powiązane zasoby
- Wybieranie magazynu danych analitycznych na platformie Azure
- Wykonywanie zapytań względem usługi Data Lake lub lakehouse przy użyciu usługi Azure Synapse bezserwerowych
- Zarządzanie danymi w usłudze Azure Data Lake za pomocą usługi Microsoft Purview
- Nowoczesny magazyn danych dla małych i średnich firm
Opinia
Dostępne już wkrótce: W 2024 r. będziemy stopniowo wycofywać zgłoszenia z serwisu GitHub jako mechanizm przesyłania opinii na temat zawartości i zastępować go nowym systemem opinii. Aby uzyskać więcej informacji, sprawdź: https://aka.ms/ContentUserFeedback.
Prześlij i wyświetl opinię dla