W tym artykule opisano najlepsze rozwiązania dotyczące monitorowania aplikacji mikrousług działającej w usłudze Azure Kubernetes Service (AKS). Konkretne tematy obejmują zbieranie danych telemetrycznych, monitorowanie stanu klastra, metryk, rejestrowania, rejestrowania strukturalnego i śledzenia rozproszonego. Ten ostatni przedstawiono na tym diagramie:

Pobierz plik programu Visio z tą architekturą.
Zbieranie danych telemetrycznych
W każdej złożonej aplikacji w pewnym momencie coś pójdzie nie tak. W aplikacji mikrousług należy śledzić, co dzieje się w dziesiątkach lub nawet setkach usług. Aby zrozumieć, co się dzieje, należy zebrać dane telemetryczne z aplikacji. Dane telemetryczne można podzielić na następujące kategorie: dzienniki, ślady i metryki.
Dzienniki to oparte na tekście rekordy zdarzeń występujących podczas działania aplikacji. Obejmują one takie elementy jak dzienniki aplikacji (instrukcje śledzenia) i dzienniki serwera internetowego. Dzienniki są przydatne głównie w przypadku analizy śledczej i głównej przyczyny.
Ślady, nazywane również operacjami, łączą kroki pojedynczego żądania między wieloma wywołaniami w ramach mikrousług i między nimi. Mogą one zapewnić ustrukturyzowaną możliwość wglądu w interakcje składników systemu. Ślady mogą rozpocząć się na wczesnym etapie procesu żądania, na przykład w interfejsie użytkownika aplikacji, i mogą być propagowane za pośrednictwem usług sieciowych w sieci mikrousług obsługujących żądanie.
- Zakresy to jednostki pracy w ramach śledzenia. Każdy zakres jest połączony z jednym śladem i może być zagnieżdżony z innymi zakresami. Często odpowiadają one poszczególnym żądaniom w operacji między usługami, ale mogą również definiować pracę w poszczególnych składnikach usługi. Obejmuje również śledzenie połączeń wychodzących z jednej usługi do innej. (Czasami zakresy są nazywane rekordami zależności).
Metryki to wartości liczbowe , które można analizować. Można ich używać do obserwowania systemu w czasie rzeczywistym (lub blisko czasu rzeczywistego) lub do analizowania trendów wydajności w czasie. Aby zrozumieć system całościowo, musisz zebrać metryki na różnych poziomach architektury, z infrastruktury fizycznej do aplikacji, w tym:
Metryki na poziomie węzła , w tym użycie procesora CPU, pamięci, sieci, dysku i systemu plików. Metryki systemowe ułatwiają zrozumienie alokacji zasobów dla każdego węzła w klastrze oraz rozwiązywanie problemów z wartościami odstających.
Metryki kontenera . W przypadku aplikacji konteneryzowanych należy zbierać metryki na poziomie kontenera, a nie tylko na poziomie maszyny wirtualnej.
Metryki aplikacji . Te metryki są istotne w celu zrozumienia zachowania usługi. Przykłady obejmują liczbę przychodzących żądań HTTP w kolejce, opóźnienie żądań i długość kolejki komunikatów. Aplikacje mogą również używać metryk niestandardowych specyficznych dla domeny, takich jak liczba transakcji biznesowych przetwarzanych na minutę.
Metryki usług zależnych. Usługi czasami nazywają zewnętrzne usługi lub punkty końcowe, takie jak zarządzane usługi PaaS lub SaaS. Usługi innych firm mogą nie udostępniać metryk. Jeśli tak nie jest, musisz polegać na własnych metrykach aplikacji, aby śledzić statystyki dotyczące opóźnień i szybkości błędów.
Monitorowanie stanu klastra
Monitorowanie kondycji klastrów przy użyciu usługi Azure Monitor . Poniższy zrzut ekranu przedstawia klaster, który zawiera krytyczne błędy w zasobnikach wdrożonych przez użytkownika:

W tym miejscu możesz przejść do szczegółów, aby znaleźć problem. Jeśli na przykład stan zasobnika to ImagePullBackoff, platforma Kubernetes nie mogła ściągnąć obrazu kontenera z rejestru. Ten problem może być spowodowany nieprawidłowym tagiem kontenera lub błędem uwierzytelniania podczas ściągania z rejestru.
Jeśli kontener ulegnie awarii, kontener State stanie się Waitingelementem z wartością ReasonCrashLoopBackOff. W typowym scenariuszu, w którym zasobnik jest częścią zestawu replik, a zasady Alwaysponawiania to , ten problem nie jest wyświetlany jako błąd w stanie klastra. Można jednak uruchamiać zapytania lub konfigurować alerty dla tego warunku. Aby uzyskać więcej informacji, zobacz Omówienie wydajności klastra usługi AKS za pomocą usługi Azure Monitor Container Insights.
W okienku skoroszytów zasobu usługi AKS jest dostępnych wiele skoroszytów specyficznych dla kontenera. Tych skoroszytów można użyć do szybkiego omówienia, rozwiązywania problemów, zarządzania i szczegółowych informacji. Poniższy zrzut ekranu przedstawia listę skoroszytów, które są domyślnie dostępne dla obciążeń usługi AKS.

Mierniki
Zalecamy używanie monitora do zbierania i wyświetlania metryk dla klastrów usługi AKS i innych zależnych usług platformy Azure.
W przypadku metryk klastra i kontenera włącz usługę Azure Monitor Container Insights. Po włączeniu tej funkcji monitor zbiera metryki pamięci i procesora z kontrolerów, węzłów i kontenerów za pośrednictwem interfejsu API metryk platformy Kubernetes. Aby uzyskać więcej informacji na temat metryk dostępnych w usłudze Container Insights, zobacz Omówienie wydajności klastra usługi AKS za pomocą usługi Azure Monitor Container Insights.
Użyj Szczegółowe informacje aplikacji do zbierania metryk aplikacji. Szczegółowe informacje aplikacji to rozszerzalna usługa zarządzania wydajnością aplikacji (APM). Aby go używać, należy zainstalować pakiet instrumentacji w aplikacji. Ten pakiet monitoruje aplikację i wysyła dane telemetryczne do usługi Application Szczegółowe informacje. Może również ściągać dane telemetryczne ze środowiska hosta. Dane są następnie wysyłane do monitora. Szczegółowe informacje aplikacji zapewnia również wbudowane śledzenie korelacji i zależności. (Zobacz Śledzenie rozproszone, w dalszej części tego artykułu).
Aplikacja Szczegółowe informacje ma maksymalną przepływność mierzoną w zdarzeniach na sekundę i ogranicza dane telemetryczne, jeśli szybkość danych przekroczy limit. Aby uzyskać szczegółowe informacje, zobacz Application Szczegółowe informacje limits (Limity Szczegółowe informacje aplikacji). Utwórz różne wystąpienia aplikacji Szczegółowe informacje dla każdego środowiska, aby środowiska deweloperskie/testowe nie konkurowały z produkcyjną telemetrią dla limitu przydziału.
Pojedyncza operacja może generować wiele zdarzeń telemetrii, więc jeśli aplikacja doświadcza dużego ruchu, jego przechwytywanie danych telemetrycznych może zostać ograniczone. Aby rozwiązać ten problem, możesz wykonać próbkowanie w celu zmniejszenia ruchu telemetrycznego. Kompromis polega na tym, że metryki będą mniej precyzyjne, chyba że instrumentacja obsługuje agregację wstępną. W takim przypadku będzie mniej próbek śledzenia na potrzeby rozwiązywania problemów, ale metryki zachowują dokładność. Aby uzyskać więcej informacji, zobacz Próbkowanie w Szczegółowe informacje aplikacji. Możesz również zmniejszyć ilość danych przez wstępne agregowanie metryk. Oznacza to, że można obliczyć wartości statystyczne, takie jak średnia i odchylenie standardowe, i wysłać te wartości zamiast nieprzetworzonych danych telemetrycznych. W tym wpisie w blogu opisano podejście do korzystania z usługi Application Szczegółowe informacje na dużą skalę: Monitorowanie i analiza na dużą skalę platformy Azure.
Jeśli szybkość danych jest wystarczająco wysoka, aby wyzwolić ograniczanie przepustowości, a próbkowanie lub agregacja nie są akceptowalne, rozważ wyeksportowanie metryk do bazy danych szeregów czasowych, takiej jak Azure Data Explorer, Prometheus lub InfluxDB, uruchomione w klastrze.
Azure Data Explorer to natywna, wysoce skalowalna usługa eksploracji danych na platformie Azure na potrzeby danych dzienników i danych telemetrycznych. Oferuje obsługę wielu formatów danych, rozbudowanego języka zapytań i połączeń do korzystania z danych w popularnych narzędziach, takich jak Jupyter Notebooks i Grafana. Usługa Azure Data Explorer ma wbudowane łączniki do pozyskiwania danych dzienników i metryk za pośrednictwem usługi Azure Event Hubs. Aby uzyskać więcej informacji, zobacz Pozyskiwanie i wykonywanie zapytań dotyczących danych monitorowania w usłudze Azure Data Explorer.
InfluxDB to system oparty na wypychaniach. Agent musi wypchnąć metryki. Możesz użyć stosu TICK, aby skonfigurować monitorowanie platformy Kubernetes. Następnie możesz wypchnąć metryki do bazy danych InfluxDB przy użyciu programu Telegraf, który jest agentem do zbierania i raportowania metryk. Można użyć bazy danych InfluxDB dla nieregularnych zdarzeń i typów danych ciągów.
Prometheus to system oparty na ściąganiu. Okresowo skrada metryki ze skonfigurowanych lokalizacji. Rozwiązanie Prometheus może zeskrobać metryki generowane przez usługę Azure Monitor lub kube-state-metrics. kube-state-metrics to usługa, która zbiera metryki z serwera interfejsu API Kubernetes i udostępnia je rozwiązaniu Prometheus (lub złomnik zgodny z punktem końcowym klienta Rozwiązania Prometheus). W przypadku metryk systemowych użyj eksportera węzłów, który jest eksporterem Prometheus dla metryk systemowych. Rozwiązanie Prometheus obsługuje dane zmiennoprzecinkowe, ale nie dane ciągów, dlatego jest odpowiednie dla metryk systemowych, ale nie dzienników. Serwer metryk Kubernetes to agregator danych użycia zasobów w całym klastrze.
Rejestrowanie
Poniżej przedstawiono niektóre ogólne wyzwania związane z logowaniem w aplikacji mikrousług:
- Zrozumienie kompleksowego przetwarzania żądania klienta, w którym może być wywoływanych wiele usług w celu obsługi pojedynczego żądania.
- Konsolidowanie dzienników z wielu usług w jednym zagregowanym widoku.
- Analizowanie dzienników pochodzących z wielu źródeł, które używają własnych schematów rejestrowania lub nie mają określonego schematu. Dzienniki mogą być generowane przez składniki innych firm, których nie kontrolujesz.
- Architektury mikrousług często generują większą liczbę dzienników niż tradycyjne monolityczne, ponieważ istnieje więcej usług, wywołań sieciowych i kroków transakcji. Oznacza to, że rejestrowanie może być wąskim gardłem wydajności lub zasobów dla aplikacji.
Istnieją pewne dodatkowe wyzwania związane z architekturami opartymi na platformie Kubernetes:
- Kontenery można przenosić i zmieniać ich harmonogramy.
- Platforma Kubernetes ma abstrakcję sieci, która używa wirtualnych adresów IP i mapowań portów.
W usłudze Kubernetes standardowe podejście do rejestrowania dotyczy kontenera do zapisywania dzienników w stdout i stderr. Aparat kontenera przekierowuje te strumienie do sterownika rejestrowania. Aby ułatwić wykonywanie zapytań i zapobiec ewentualnej utracie danych dziennika, jeśli węzeł przestanie odpowiadać, zwykle należy zebrać dzienniki z każdego węzła i wysłać je do centralnej lokalizacji magazynu.
Usługa Azure Monitor integruje się z usługą AKS w celu obsługi tego podejścia. Monitor zbiera dzienniki kontenerów i wysyła je do obszaru roboczego usługi Log Analytics. Z tego miejsca można użyć język zapytań Kusto do zapisywania zapytań w zagregowanych dziennikach. Oto zapytanie Kusto dotyczące wyświetlania dzienników kontenera dla określonego zasobnika:
ContainerLogV2
| where PodName == "podName" //update with target pod
| project TimeGenerated, Computer, ContainerId, LogMessage, LogSource
Usługa Azure Monitor jest usługą zarządzaną i konfigurowanie klastra usługi AKS do korzystania z usługi Monitor jest prostą zmianą konfiguracji w interfejsie wiersza polecenia lub szablonie usługi Azure Resource Manager. (Aby uzyskać więcej informacji, zobacz Jak włączyć usługę Azure Monitor Container Insights). Kolejną zaletą korzystania z usługi Azure Monitor jest to, że konsoliduje dzienniki usługi AKS z innymi dziennikami platformy Azure w celu zapewnienia ujednoliconego środowiska monitorowania.
Usługa Azure Monitor jest rozliczana za gigabajt (GB) danych pozyskanych do usługi. (Zobacz Cennik usługi Azure Monitor). Przy dużych ilościach koszt może stać się brany pod uwagę. Istnieje wiele alternatywnych rozwiązań typu open source dostępnych dla ekosystemu Kubernetes. Na przykład wiele organizacji używa rozwiązania Fluentd z usługą Elasticsearch. Fluentd to moduł zbierający dane typu open source, a Elasticsearch to baza danych dokumentów używana do wyszukiwania. Wyzwaniem dla tych opcji jest to, że wymagają dodatkowej konfiguracji i zarządzania klastrem. W przypadku obciążenia produkcyjnego może być konieczne eksperymentowanie z ustawieniami konfiguracji. Należy również monitorować wydajność infrastruktury rejestrowania.
OpenTelemetry
OpenTelemetry to między branżowy wysiłek, który usprawnia śledzenie poprzez standaryzację interfejsu między aplikacjami, bibliotekami, telemetrią i modułami zbierającym dane. W przypadku korzystania z biblioteki i platformy, które są instrumentowane za pomocą biblioteki OpenTelemetry, większość operacji śledzenia, które są tradycyjnie operacjami systemowymi, jest obsługiwana przez biblioteki bazowe, które obejmują następujące typowe scenariusze:
- Rejestrowanie podstawowych operacji żądań, takich jak czas rozpoczęcia, czas zakończenia i czas trwania
- Zgłoszone wyjątki
- Propagacja kontekstu (na przykład wysyłanie identyfikatora korelacji w granicach wywołań HTTP)
Zamiast tego podstawowe biblioteki i struktury obsługujące te operacje tworzą rozbudowane powiązane struktury danych i śledzenia oraz propagują je w kontekstach. Przed openTelemetry były one zwykle wstrzykiwane jako specjalne komunikaty dziennika lub jako zastrzeżone struktury danych, które były specyficzne dla dostawcy, który utworzył narzędzia do monitorowania. OpenTelemetry zachęca również do bardziej zaawansowanego modelu danych instrumentacji niż tradycyjne podejście oparte na rejestrowaniu, a dzienniki są bardziej przydatne, ponieważ komunikaty dziennika są połączone ze śladami i zakresami, w których zostały wygenerowane. Często sprawia to, że wyszukiwanie dzienników skojarzonych z określoną operacją lub żądanie jest łatwe.
Wiele zestawów SDK platformy Azure zostało instrumentowanych za pomocą biblioteki OpenTelemetry lub jest w trakcie jej implementowania.
Deweloper aplikacji może dodać instrumentację ręczną przy użyciu zestawów SDK OpenTelemetry, aby wykonać następujące czynności:
- Dodaj instrumentację, w której nie udostępnia biblioteki bazowej.
- Wzbogacanie kontekstu śledzenia przez dodanie zakresów w celu uwidocznienia jednostek pracy specyficznych dla aplikacji (na przykład pętli zamówienia, która tworzy zakres przetwarzania każdego wiersza zamówienia).
- Wzbogacanie istniejących zakresów za pomocą kluczy jednostek w celu ułatwienia śledzenia. (Na przykład dodaj klucz/wartość OrderID do żądania, które przetwarza to zamówienie). Te klucze są udostępniane przez narzędzia do monitorowania jako wartości ustrukturyzowane do wykonywania zapytań, filtrowania i agregowania (bez analizowania ciągów komunikatów dziennika lub wyszukiwania kombinacji sekwencji komunikatów dziennika, podobnie jak w przypadku podejścia opartego na rejestrowaniu).
- Propagacja kontekstu śledzenia przez uzyskanie dostępu do atrybutów śledzenia i zakresu, wstrzykiwanie identyfikatorów traceId do odpowiedzi i ładunków oraz/lub odczytywanie identyfikatorów traceId z przychodzących komunikatów w celu utworzenia żądań i zakresów.
Przeczytaj więcej na temat instrumentacji i zestawów SDK OpenTelemetry w dokumentacji biblioteki OpenTelemetry.
Szczegółowe dane dotyczące aplikacji
Aplikacja Szczegółowe informacje zbiera zaawansowane dane z bibliotek OpenTelemetry i instrumentacji oraz przechwytuje je w wydajnym magazynie danych w celu zapewnienia rozbudowanej obsługi wizualizacji i zapytań. Biblioteki instrumentacji oparte na technologii OpenTelemetry Szczegółowe informacje Aplikacji dla języków takich jak .NET, Java, Node.js i Python ułatwiają wysyłanie danych telemetrycznych do usługi Application Szczegółowe informacje.
Jeśli używasz platformy .NET Core, zalecamy również rozważenie biblioteki Application Szczegółowe informacje for Kubernetes. Ta biblioteka wzbogaca ślady Szczegółowe informacje aplikacji o dodatkowe informacje, takie jak kontener, węzeł, zasobnik, etykiety i zestaw replik.
Szczegółowe informacje aplikacji mapuje kontekst OpenTelemetry na wewnętrzny model danych:
- Śledzenie —> operacja
- Identyfikator śledzenia —> identyfikator operacji
- Span —> żądanie lub zależność
Weź pod uwagę następujące kwestie:
- Aplikacja Szczegółowe informacje ogranicza dane telemetryczne, jeśli szybkość danych przekracza maksymalny limit. Aby uzyskać szczegółowe informacje, zobacz Application Szczegółowe informacje limits (Limity Szczegółowe informacje aplikacji). Pojedyncza operacja może wygenerować kilka zdarzeń telemetrii, więc jeśli aplikacja doświadcza dużego natężenia ruchu, prawdopodobnie będzie ograniczana.
- Ponieważ aplikacja Szczegółowe informacje partii danych, można utracić partię, jeśli proces zakończy się niepowodzeniem z nieobsługiwanym wyjątkiem.
- Rozliczenia Szczegółowe informacje aplikacji są oparte na ilości danych. Aby uzyskać więcej informacji, zobacz Zarządzanie cenami i ilością danych w usłudze Application Szczegółowe informacje.
Rejestrowanie strukturalne
Aby ułatwić analizowanie dzienników, użyj rejestrowania strukturalnego, gdy możesz. W przypadku korzystania z rejestrowania strukturalnego aplikacja zapisuje dzienniki w formacie ustrukturyzowanym, na przykład w formacie JSON, zamiast wyświetlać ciągi tekstowe bez struktury. Dostępnych jest wiele bibliotek rejestrowania strukturalnego. Oto na przykład instrukcja rejestrowania, która używa biblioteki Serilog dla platformy .NET Core:
public async Task<IActionResult> Put([FromBody]Delivery delivery, string id)
{
logger.LogInformation("In Put action with delivery {Id}: {@DeliveryInfo}", id, delivery.ToLogInfo());
...
}
W tym miejscu wywołanie LogInformation polecenia zawiera Id parametr i DeliveryInfo parametr. W przypadku korzystania z rejestrowania strukturalnego te wartości nie są interpolowane w ciągu komunikatu. Zamiast tego dane wyjściowe dziennika wyglądają mniej więcej tak:
{"@t":"2019-06-13T00:57:09.9932697Z","@mt":"In Put action with delivery {Id}: {@DeliveryInfo}","Id":"36585f2d-c1fa-4a3d-9e06-a7f40b7d04ef","DeliveryInfo":{...
Jest to ciąg JSON, w którym @t pole jest znacznikiem czasu, @mt jest ciągiem komunikatu, a pozostałe pary klucz/wartość są parametrami. Przesyłanie danych wyjściowych w formacie JSON ułatwia wykonywanie zapytań o dane w sposób ustrukturyzowany. Na przykład następujące zapytanie usługi Log Analytics napisane w języku zapytań Kusto wyszukuje wystąpienia tego konkretnego komunikatu ze wszystkich kontenerów o nazwie fabrikam-delivery:
traces
| where customDimensions.["Kubernetes.Container.Name"] == "fabrikam-delivery"
| where customDimensions.["{OriginalFormat}"] == "In Put action with delivery {Id}: {@DeliveryInfo}"
| project message, customDimensions["Id"], customDimensions["@DeliveryInfo"]
Jeśli wyświetlisz wynik w witrynie Azure Portal, zobaczysz, że DeliveryInfo jest to rekord ustrukturyzowany zawierający serializowaną reprezentację DeliveryInfo modelu:

Oto kod JSON z tego przykładu:
{
"Id": "36585f2d-c1fa-4a3d-9e06-a7f40b7d04ef",
"Owner": {
"UserId": "user id for logging",
"AccountId": "52dadf0c-0067-43e7-af76-86e32b48bc5e"
},
"Pickup": {
"Altitude": 0.29295161612934972,
"Latitude": 0.26815900219052985,
"Longitude": 0.79841844309047727
},
"Dropoff": {
"Altitude": 0.31507750848078986,
"Latitude": 0.753494655598651,
"Longitude": 0.89352830773849423
},
"Deadline": "string",
"Expedited": true,
"ConfirmationRequired": 0,
"DroneId": "AssignedDroneId01ba4d0b-c01a-4369-ba75-51bde0e76cc9"
}
Wiele komunikatów dziennika oznacza początek lub koniec jednostki pracy albo łączy jednostkę biznesową z zestawem komunikatów i operacji w celu śledzenia. W wielu przypadkach wzbogacanie zakresu OpenTelemetry i obiektów żądań jest lepszym podejściem niż rejestrowanie rozpoczęcia i zakończenia operacji. Spowoduje to dodanie tego kontekstu do wszystkich połączonych operacji śledzenia i operacji podrzędnych oraz umieszcza te informacje w zakresie pełnej operacji. Zestawy SDK OpenTelemetry dla różnych języków obsługują tworzenie zakresów lub dodawanie atrybutów niestandardowych na zakresach. Na przykład poniższy kod używa zestawu JAVA OpenTelemetry SDK, który jest obsługiwany przez usługę Application Szczegółowe informacje. Istniejący zakres nadrzędny (na przykład zakres żądania skojarzony z wywołaniem kontrolera REST i utworzony przez używaną platformę internetową) może zostać wzbogacony o identyfikator jednostki skojarzony z nim, jak pokazano poniżej:
import io.opentelemetry.api.trace.Span;
// ...
Span.current().setAttribute("A1234", deliveryId);
Ten kod ustawia klucz lub wartość dla bieżącego zakresu, który jest połączony z operacjami i komunikatami dziennika, które występują w tym zakresie. Wartość jest wyświetlana w obiekcie żądania Szczegółowe informacje aplikacji, jak pokazano poniżej:
requests
| extend deliveryId = tostring(customDimensions.deliveryId) // promote to column value (optional)
| where deliveryId == "A1234"
| project timestamp, name, url, success, resultCode, duration, operation_Id, deliveryId
Ta technika staje się bardziej zaawansowana w przypadku użycia z dziennikami, filtrowaniem i dodawaniem adnotacji do śladów dzienników z kontekstem zakresu, jak pokazano poniżej:
requests
| extend deliveryId = tostring(customDimensions.deliveryId) // promote to column value (optional)
| where deliveryId == "A1234"
| project deliveryId, operation_Id, requestTimestamp = timestamp, requestDuration = duration // keep some request info
| join kind=inner traces on operation_Id // join logs only for this deliveryId
| project requestTimestamp, requestDuration, logTimestamp = timestamp, deliveryId, message
Jeśli używasz biblioteki lub struktury, która jest już instrumentowana za pomocą biblioteki OpenTelemetry, obsługuje tworzenie zakresów i żądań, ale kod aplikacji może również tworzyć jednostki pracy. Na przykład metoda, która wykonuje pętlę przez tablicę jednostek wykonujących pracę na każdym z nich, może utworzyć zakres dla każdej iteracji pętli przetwarzania. Aby uzyskać informacje na temat dodawania instrumentacji do kodu aplikacji i biblioteki, zobacz dokumentację instrumentacji OpenTelemery.
Rozproszone śledzenie
Jednym z wyzwań związanych z używaniem mikrousług jest zrozumienie przepływu zdarzeń między usługami. Pojedyncza transakcja może obejmować wywołania wielu usług.
Przykład śledzenia rozproszonego
W tym przykładzie opisano ścieżkę transakcji rozproszonej za pośrednictwem zestawu mikrousług. Przykład jest oparty na aplikacji dostarczania dronów.
W tym scenariuszu transakcja rozproszona obejmuje następujące kroki:
- Usługa pozyskiwania umieszcza komunikat w kolejce usługi Azure Service Bus.
- Usługa Przepływu pracy ściąga komunikat z kolejki.
- Usługa Workflow wywołuje trzy usługi zaplecza w celu przetworzenia żądania (Drone Scheduler, Package i Delivery).
Poniższy zrzut ekranu przedstawia mapę aplikacji dla aplikacji dostarczania dronów. Ta mapa przedstawia wywołania publicznego punktu końcowego interfejsu API, które powodują przepływ pracy obejmujący pięć mikrousług.
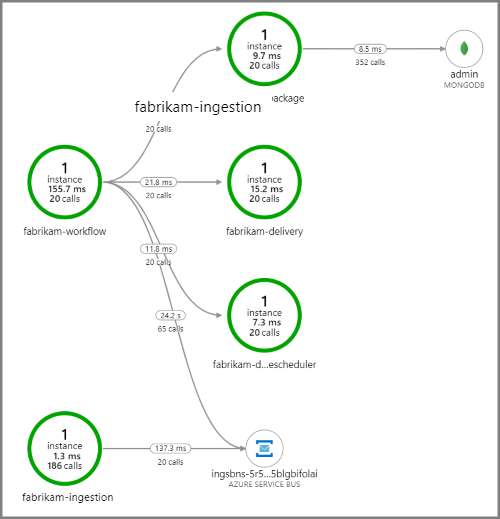
Strzałki z fabrikam-workflow i fabrikam-ingestion do kolejki usługi Service Bus pokazują, gdzie komunikaty są wysyłane i odbierane. Nie można odróżnić od diagramu, który usługa wysyła komunikaty i które odbiera. Strzałki pokazują tylko, że obie usługi wywołuje usługę Service Bus. Jednak informacje o tym, która usługa wysyła i która odbiera, są dostępne w szczegółach:

Ponieważ każde wywołanie zawiera identyfikator operacji, można również wyświetlić kompleksowe kroki pojedynczej transakcji, w tym informacje o chronometrażu i wywołania HTTP w każdym kroku. Oto wizualizacja jednej z takich transakcji:

Ta wizualizacja przedstawia kroki z usługi pozyskiwania do kolejki, z kolejki do usługi Przepływ pracy oraz z usługi Przepływ pracy do innych usług zaplecza. Ostatnim krokiem jest usługa Przepływu pracy z oznaczeniem komunikatu usługi Service Bus zgodnie z zakończeniem.
W tym przykładzie pokazano wywołania usługi zaplecza, które kończą się niepowodzeniem:

Ta mapa pokazuje, że duża część wywołań (36%) wywołań usługi Drone Scheduler nie powiodła się w okresie zapytania. Widok transakcji end-to-end pokazuje, że wyjątek występuje, gdy żądanie HTTP PUT jest wysyłane do usługi:

Jeśli przejdziesz dalej, zobaczysz, że wyjątek jest wyjątkiem gniazda: "Nie ma takiego urządzenia lub adresu".
Fabrikam.Workflow.Service.Services.BackendServiceCallFailedException:
No such device or address
---u003e System.Net.Http.HttpRequestException: No such device or address
---u003e System.Net.Sockets.SocketException: No such device or address
Ten wyjątek sugeruje, że usługa zaplecza nie jest osiągalna. W tym momencie możesz użyć narzędzia kubectl, aby wyświetlić konfigurację wdrożenia. W tym przykładzie nazwa hosta usługi nie jest rozpoznawana z powodu błędu w plikach konfiguracji platformy Kubernetes. Artykuł Debug Services w dokumentacji platformy Kubernetes zawiera wskazówki dotyczące diagnozowania tego typu błędu.
Poniżej przedstawiono niektóre typowe przyczyny błędów:
- Usterki kodu. Te usterki mogą wyglądać następująco:
- Wyjątki. Przejrzyj dzienniki Szczegółowe informacje aplikacji, aby wyświetlić szczegóły wyjątku.
- Proces kończy się niepowodzeniem. Przyjrzyj się stanowi kontenera i zasobnika oraz wyświetl dzienniki kontenera lub ślady Szczegółowe informacje aplikacji.
- Błędy HTTP 5xx .
- Wyczerpanie zasobów:
- Poszukaj ograniczania przepustowości (HTTP 429) lub przekroczenia limitu czasu żądania.
- Sprawdź metryki kontenera pod kątem procesora CPU, pamięci i dysku.
- Zapoznaj się z konfiguracjami limitów zasobów kontenera i zasobnika.
- Odnajdywanie usługi. Zapoznaj się z konfiguracją usługi Kubernetes i mapowaniami portów.
- Niezgodność interfejsu API. Poszukaj błędów HTTP 400. Jeśli interfejsy API są wersjonowane, zapoznaj się z wywoływaną wersją.
- Błąd podczas ściągania obrazu kontenera. Przyjrzyj się specyfikacji zasobnika. Upewnij się również, że klaster jest autoryzowany do ściągania z rejestru kontenerów.
- Problemy z kontrolą dostępu opartą na rolach.
Następne kroki
Dowiedz się więcej o funkcjach w usłudze Azure Monitor, które obsługują monitorowanie aplikacji w usłudze AKS:
- Omówienie szczegółowych informacji o kontenerze usługi Azure Monitor
- Omówienie wydajności klastra usługi AKS za pomocą usługi Azure Monitor Container Insights