Ten wzorzec architektury pokazuje, jak włączyć rozwiązanie MDM do ekosystemu usług danych platformy Azure, aby poprawić jakość danych używanych do podejmowania decyzji analitycznych i operacyjnych. Rozwiązanie MDM rozwiązuje kilka typowych problemów, w tym:
- Identyfikowanie zduplikowanych danych i zarządzanie nimi (dopasowanie i scalanie).
- Flagowanie i rozwiązywanie problemów z jakością danych.
- Standaryzacja i wzbogacanie danych.
- Umożliwienie stewardom danych proaktywnego zarządzania danymi i ulepszania ich.
Ten wzorzec przedstawia nowoczesne podejście do zarządzania urządzeniami przenośnymi. Wszystkie technologie można wdrażać natywnie na platformie Azure, w tym profisee, które można wdrażać za pośrednictwem kontenerów i zarządzać przy użyciu usługi Azure Kubernetes Service.
Architektura

Pobierz plik programu Visio diagramów używanych w tej architekturze.
Przepływ danych
Poniższy przepływ danych odpowiada powyższemu diagramowi:
Ładowanie danych źródłowych: dane źródłowe z aplikacji biznesowych są kopiami do usługi Azure Data Lake i przechowują je w celu dalszej transformacji i użycia w analizie podrzędnej. Dane źródłowe zazwyczaj należą do jednej z trzech kategorii:
- Dane główne ze strukturą — informacje opisujące klientów, produkty, lokalizacje itd. Dane główne są małe, duże złożoność i zmieniają się powoli w czasie. Często są to dane, z którymi organizacje zmagają się najbardziej pod względem jakości danych.
- Dane transakcyjne ze strukturą — zdarzenia biznesowe występujące w określonym punkcie w czasie, takie jak zamówienie, faktura lub interakcja. Transakcje obejmują metryki dla tej transakcji (takie jak cena sprzedaży) i odwołania do danych głównych (takich jak produkt i klient zaangażowany w zakup). Dane transakcyjne są zazwyczaj duże, małe złożoność i nie zmieniają się w czasie.
- Dane bez struktury — dane, które mogą zawierać dokumenty, obrazy, filmy wideo, zawartość mediów społecznościowych i dźwięk. Nowoczesne platformy analityczne mogą coraz częściej używać danych bez struktury, aby poznać nowe szczegółowe informacje. Dane bez struktury są często kojarzone z danymi głównymi, takimi jak klient skojarzony z kontem w mediach społecznościowych lub produkt skojarzony z obrazem.
Ładowanie danych głównych źródła: dane główne ze źródłowych aplikacji biznesowych są ładowane do aplikacji MDM "tak, jak to jest", z pełnymi informacjami o pochodzenia i minimalnymi przekształceniami.
Automatyczne przetwarzanie MDM: rozwiązanie MDM używa zautomatyzowanych procesów do standaryzacji, weryfikowania i wzbogacania danych, takich jak dane adresowe. Rozwiązanie identyfikuje również problemy z jakością danych, grupuje zduplikowane rekordy (na przykład duplikaty klientów) i generuje rekordy główne, nazywane również "złotymi rekordami".
Zarządzanie danymi: w razie potrzeby stewardzy danych mogą:
- Przeglądanie grup pasowanych rekordów i zarządzanie nimi
- Tworzenie relacji danych i zarządzanie nimi
- Wypełnij brakujące informacje
- Rozwiązywanie problemów z jakością danych.
Stewardzy danych mogą zarządzać wieloma alternatywnymi hierarchicznymi pakietami zbiorczymi zgodnie z wymaganiami, takimi jak hierarchie produktów.
Zarządzane ładowanie danych głównych: wysokiej jakości dane główne przepływają do rozwiązań do analizy podrzędnej. Ta akcja upraszcza proces, ponieważ integracja danych nie wymaga już żadnych przekształceń jakości danych.
Transakcyjne i nieustrukturyzowane ładowanie danych: transakcyjne i nieustrukturyzowane dane są ładowane do rozwiązania do analizy podrzędnej, w którym łączy się z danymi głównymi wysokiej jakości.
Wizualizacja i analiza: dane są modelowane i udostępniane użytkownikom biznesowym na potrzeby analizy. Wysokiej jakości dane główne eliminują typowe problemy z jakością danych, co skutkuje lepszymi szczegółowymi informacjami.
Elementy
Azure Data Factory to hybrydowa usługa integracji danych, która umożliwia tworzenie, planowanie i organizowanie przepływów pracy ETL i ELT.
Usługa Azure Data Lake zapewnia nieograniczony magazyn danych analitycznych.
Profisee to skalowalna platforma MDM zaprojektowana do łatwej integracji z ekosystemem firmy Microsoft.
Usługa Azure Synapse Analytics to szybki, elastyczny i zaufany magazyn danych w chmurze, który umożliwia elastyczne i niezależne skalowanie, obliczenia i przechowywanie danych przy użyciu architektury masowego przetwarzania równoległego.
Usługa Power BI to zestaw narzędzi do analizy biznesowej, który dostarcza szczegółowe informacje w całej organizacji. Połączenie do setek źródeł danych, uprościć przygotowywanie danych i zwiększyć improwizowanych analiz. Twórz piękne raporty, a następnie publikuj je, aby inne osoby w organizacji mogły skorzystać z nich w Internecie lub na swoich urządzeniach przenośnych.
Alternatywy
Brak specjalnie utworzonej aplikacji MDM można znaleźć niektóre możliwości techniczne potrzebne do utworzenia rozwiązania MDM w ekosystemie platformy Azure.
- Jakość danych — podczas ładowania do platformy analitycznej można tworzyć jakość danych w procesach integracji. Na przykład zastosuj przekształcenia jakości danych w potoku usługi Azure Data Factory za pomocą zakodowanych na stałe skryptów.
- Standaryzacja i wzbogacanie danych — usługa Azure Mapy pomaga zapewnić weryfikację i standaryzację danych adresowych, których można używać w usługach Azure Functions i Azure Data Factory. Standaryzacja innych danych może wymagać opracowania zakodowanych na stałe skryptów.
- Zduplikowane zarządzanie danymi — za pomocą usługi Azure Data Factory można deduplikować wiersze , w których wystarczające identyfikatory są dostępne dla dokładnego dopasowania. W takim przypadku logika scalania zgodna z odpowiednimi ocalałymi prawdopodobnie wymaga niestandardowych zakodowanych na stałe skryptów.
- Zarządzanie danymi — usługa Power Apps umożliwia szybkie opracowywanie prostych rozwiązań do zarządzania danymi na platformie Azure oraz odpowiednich interfejsów użytkownika do przeglądania, przepływu pracy, alertów i walidacji.
Szczegóły scenariusza
Wiele programów transformacji cyfrowej używa platformy Azure jako rdzenia. Jednak zależy to od jakości i spójności danych z wielu źródeł, takich jak aplikacje biznesowe, bazy danych, źródła danych itd. Zapewnia również wartość dzięki analizie biznesowej, analizie, uczeniu maszynowem i nie tylko. Rozwiązanie Master Zarządzanie danymi (MDM) profisee's Profisee kończy zasoby danych platformy Azure przy użyciu praktycznej metody "dopasowywania i łączenia" danych z wielu źródeł. Umożliwia to wymuszanie spójnych standardów danych na danych źródłowych, takich jak dopasowanie, scalanie, standaryzacja, weryfikowanie i poprawianie. Natywna integracja z usługą Azure Data Factory i innymi usługami Azure Data Services dodatkowo usprawnia ten proces w celu przyspieszenia dostarczania korzyści biznesowych platformy Azure.
Podstawowym aspektem działania rozwiązań MDM jest połączenie danych z wielu źródeł w celu utworzenia "złotego wzorca rekordów", który zawiera najbardziej znane i zaufane dane dla każdego rekordu. Ta struktura tworzy domenę po domenie zgodnie z wymaganiami, ale prawie zawsze wymaga wielu domen. Typowe domeny to klient, produkt i lokalizacja. Ale domeny mogą reprezentować wszystko, od danych referencyjnych do kontraktów i nazw leków. Ogólnie rzecz biorąc, lepsze pokrycie domeny, które można utworzyć w stosunku do ogólnych wymagań dotyczących danych platformy Azure, tym lepiej.
Potok integracji oprogramowania MDM

Pobierz plik programu Visio z tą architekturą.
Na powyższej ilustracji przedstawiono szczegóły integracji z rozwiązaniem MDM Profisee. Zwróć uwagę, że usługi Azure Data Factory i Profisee obejmują natywną obsługę integracji REST, zapewniając uproszczoną i nowoczesną integrację.
Ładowanie danych źródłowych do rozwiązania MDM: usługa Azure Data Factory wyodrębnia dane z magazynu data lake, przekształca je w celu dopasowania do modelu danych głównych i przesyła strumieniowo do repozytorium MDM za pośrednictwem ujścia REST.
Przetwarzanie MDM: platforma MDM przetwarza dane główne źródła przez sekwencję działań w celu weryfikowania, standaryzacji i wzbogacania danych oraz wykonywania procesów jakości danych. Na koniec rozwiązanie MDM wykonuje dopasowywanie i przetrwanie w celu identyfikowania i grupowania zduplikowanych rekordów oraz tworzenia rekordów głównych. Opcjonalnie stewardzy danych mogą wykonywać zadania, które powodują użycie zestawu danych głównych do użycia w analizie podrzędnej.
Ładowanie danych głównych do analizy: usługa Azure Data Factory używa źródła REST do strumieniowego przesyłania danych głównych z usługi Profisee do usługi Azure Synapse Analytics.
Szablony usługi Azure Data Factory dla profisee
We współpracy z firmą Microsoft profisee opracował zestaw szablonów usługi Azure Data Factory, które ułatwiają szybsze i łatwiejsze integrowanie profisee z ekosystemem usług Azure Data Services. Te szablony używają źródła danych REST i ujścia danych usługi Azure Data Factory, aby odczytywać i zapisywać dane z interfejsu API USŁUGI REST Gateway w usłudze Profisee. Udostępniają szablony zarówno do czytania, jak i pisania do profisee.
Przykładowy szablon usługi Data Factory: kod JSON do profisee za pośrednictwem interfejsu REST
Na poniższych zrzutach ekranu przedstawiono szablon usługi Azure Data Factory, który kopiuje dane z pliku JSON w usłudze Azure Data Lake do profisee za pośrednictwem interfejsu REST.
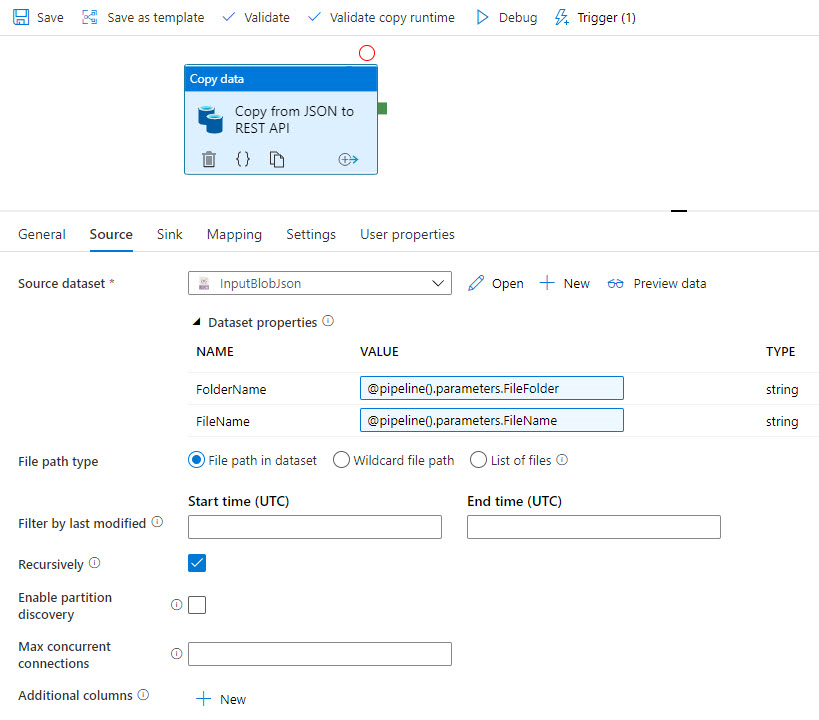
Szablon kopiuje źródłowe dane JSON:
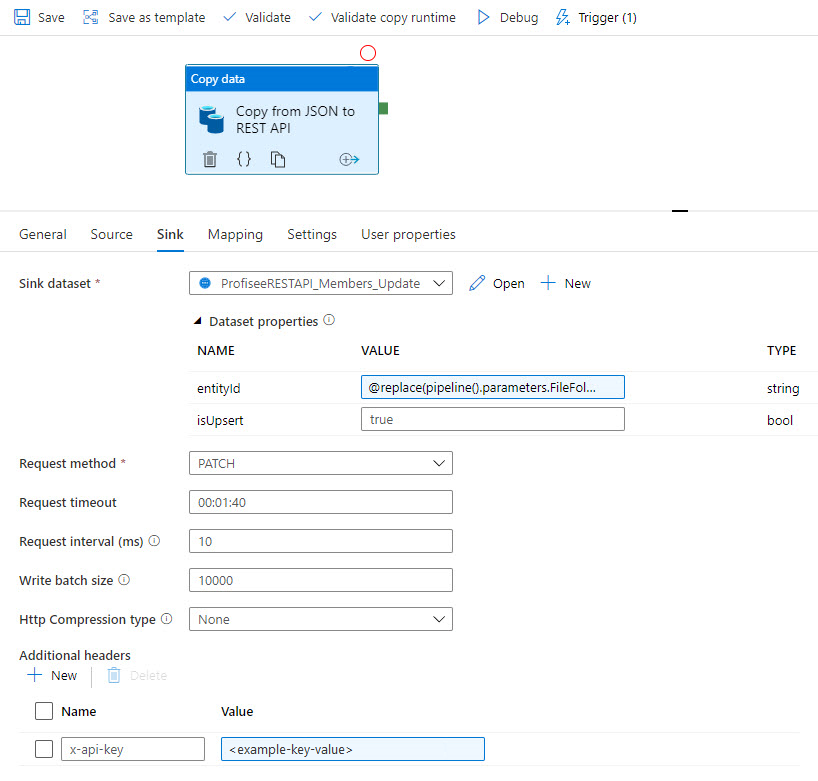
Następnie dane są synchronizowane z profisee za pośrednictwem interfejsu REST:
Aby uzyskać więcej informacji, zobacz Szablony usługi Azure Data Factory dla profisee.
Przetwarzanie zarządzania urządzeniami przenośnymi
W przypadku użycia analitycznego rozwiązania MDM dane często przetwarzają dane za pośrednictwem rozwiązania MDM automatycznie w celu załadowania danych na potrzeby analizy. W poniższych sekcjach przedstawiono typowy proces danych klienta w tym kontekście.
1. Ładowanie danych źródłowych
Dane źródłowe są ładowane do rozwiązania MDM z systemów źródłowych, w tym informacje o pochodzenia. W tym przypadku mamy dwa rekordy źródłowe: jeden z crm i jeden z aplikacji ERP. Podczas inspekcji wizualnej oba rekordy wydają się reprezentować tę samą osobę.
| Nazwa źródłowa | Adres źródłowy | Stan źródła | Telefon źródłowa | Identyfikator źródła | Adres standardowy | Stan standardowy | Nazwa standardu | Telefon w warstwie Standardowa | Similarity |
|---|---|---|---|---|---|---|---|---|---|
| Alana Bosh | 123 Main Street | Ogólna dostępność | 7708434125 | CRM-100 | |||||
| Bosch, Alana | 123 Main St. | Gruzja | 404-854-7736 | CRM-121 | |||||
| Alana Bosch | (404) 854-7736 | ERP-988 |
2. Weryfikacja i standaryzacja danych
Reguły weryfikacji i standaryzacji oraz usługi ułatwiają standaryzację i weryfikowanie informacji o adresie, nazwie i numerze telefonu.
| Nazwa źródłowa | Adres źródłowy | Stan źródła | Telefon źródłowa | Identyfikator źródła | Adres standardowy | Stan standardowy | Nazwa standardu | Telefon w warstwie Standardowa | Similarity |
|---|---|---|---|---|---|---|---|---|---|
| Alana Bosh | 123 Main Street | Ogólna dostępność | 7708434125 | CRM-100 | 123 Main St. | Ogólna dostępność | Alana Bosh | 770 843 4125 | |
| Bosch, Alana | 123 Main St. | Gruzja | 404-854-7736 | CRM-121 | 123 Main St. | Ogólna dostępność | Alana Bosch | 404 854 7736 | |
| Alana Bosch | (404) 854-7736 | ERP-988 | Alana Bosch | 404 854 7736 |
3. Dopasowywanie
W przypadku standaryzacji danych następuje dopasowywanie, identyfikowanie podobieństwa między rekordami w grupie. W tym scenariuszu dwa rekordy pasują do siebie dokładnie w polach Nazwa i Telefon, a pozostałe rozmyte dopasowania w polach Nazwa i Adres.
| Nazwa źródłowa | Adres źródłowy | Stan źródła | Telefon źródłowa | Identyfikator źródła | Adres standardowy | Stan standardowy | Nazwa standardu | Telefon w warstwie Standardowa | Similarity |
|---|---|---|---|---|---|---|---|---|---|
| Alana Bosh | 123 Main Street | Ogólna dostępność | 7708434125 | CRM-100 | 123 Main St. | Ogólna dostępność | Alana Bosh | 770 843 4125 | 0,9 |
| Bosch, Alana | 123 Main St. | Gruzja | 404-854-7736 | CRM-121 | 123 Main St. | Ogólna dostępność | Alana Bosch | 404 854 7736 | 1.0 |
| Alana Bosch | (404) 854-7736 | ERP-988 | Alana Bosch | 404 854 7736 | 1.0 |
4. Ocalały
Po utworzeniu grupy, ocalały tworzy i wypełnia rekord główny (nazywany również "złotym rekordem"), aby reprezentować grupę.
| Nazwa źródłowa | Adres źródłowy | Stan źródła | Telefon źródłowa | Identyfikator źródła | Adres standardowy | Stan standardowy | Nazwa standardu | Telefon w warstwie Standardowa | Similarity |
|---|---|---|---|---|---|---|---|---|---|
| Alana Bosh | 123 Main Street | Ogólna dostępność | 7708434125 | CRM-100 | 123 Main St. | Ogólna dostępność | Alana Bosh | 770 843 4125 | 0,9 |
| Bosch, Alana | 123 Main St. | Gruzja | 404-854-7736 | CRM-121 | 123 Main St. | Ogólna dostępność | Alana Bosch | 404 854 7736 | 1.0 |
| Alana Bosch | (404) 854-7736 | ERP-988 | Alana Bosch | 404 854 7736 | 1.0 | ||||
| Rekord główny: | 123 Main St. | Ogólne udostępnienie | Alana Bosch | 404 854 7736 |
Ten rekord główny wraz z ulepszonymi danymi źródłowymi i informacjami o pochodzenia jest ładowany do rozwiązania do analizy podrzędnej, gdzie łączy się z danymi transakcyjnymi.
W tym przykładzie przedstawiono podstawowe, zautomatyzowane przetwarzanie MDM. Możesz również użyć reguł jakości danych, aby automatycznie obliczać i aktualizować wartości oraz flagować brakujące lub nieprawidłowe wartości dla stewardów danych w celu rozwiązania problemu. Stewardzy danych pomagają zarządzać danymi, w tym zarządzanie hierarchicznymi pakietami zbiorczymi danych.
Wpływ rozwiązania MDM na złożoność integracji
Jak pokazano wcześniej, rozwiązanie MDM rozwiązuje kilka typowych problemów napotykanych podczas integrowania danych z rozwiązaniem analitycznym. Obejmuje to rozwiązywanie problemów z jakością danych, standaryzację i wzbogacanie danych oraz racjonalizacja zduplikowanych danych. Włączenie rozwiązania MDM do architektury analizy zasadniczo zmienia przepływ danych, eliminując zakodowaną na stałe logikę w procesie integracji i odciążając je do rozwiązania MDM, co znacznie upraszcza integrację. W poniższej tabeli przedstawiono niektóre typowe różnice w procesie integracji z rozwiązaniem MDM i bez nich.
| Możliwość | Bez zarządzania urządzeniami przenośnymi | Za pomocą rozwiązania MDM |
|---|---|---|
| Jakość danych | Procesy integracji obejmują reguły jakości i przekształcenia, które ułatwiają naprawianie i poprawianie danych podczas ich przemieszczania. Wymaga ona zasobów technicznych zarówno w przypadku początkowej implementacji, jak i ciągłej konserwacji tych reguł, co sprawia, że procesy integracji danych są skomplikowane i kosztowne do opracowywania i konserwacji. | Rozwiązanie MDM konfiguruje i wymusza logikę i reguły dotyczące jakości danych. Procesy integracji nie wykonują przekształceń jakości danych, a zamiast tego przenoszą dane "zgodnie z oczekiwaniami" do rozwiązania MDM. Procesy integracji danych są proste i niedrogie do opracowania i utrzymania. |
| Standaryzacja i wzbogacanie danych | Procesy integracji obejmują logikę w celu standaryzacji i dostosowania odwołań i danych głównych. Twórz integracje z usługami innych firm, aby przeprowadzać standaryzację adresów, nazw, poczty e-mail i danych telefonicznych. | Korzystając z wbudowanych reguł i wbudowanych integracji z usługami danych innych firm, można standandaryzować dane w rozwiązaniu MDM, co upraszcza integrację. |
| Zduplikowane zarządzanie danymi | Proces integracji identyfikuje i grupuje zduplikowane rekordy, które istnieją w aplikacjach i w oparciu o istniejące unikatowe identyfikatory. Ten proces udostępnia identyfikatory w systemach (na przykład SSN lub e-mail) i pasuje tylko do nich i grupuje je, gdy są identyczne. Bardziej zaawansowane podejścia wymagają znaczących inwestycji w inżynierię integracji. | Wbudowane funkcje dopasowywania uczenia maszynowego identyfikują zduplikowane rekordy w systemach i w systemach, generując złoty rekord reprezentujący grupę. Ten proces umożliwia rekordom "dopasowanie rozmyte", grupowanie rekordów, które są podobne, z objaśnialnymi wynikami. Zarządza grupami w scenariuszach, w których aparat uczenia maszynowego nie może utworzyć grupy z dużą pewnością. |
| Zarządzanie danymi | Działania związane z zarządzaniem danymi aktualizują tylko dane w aplikacjach źródłowych, takich jak ERP lub CRM. Zazwyczaj odnajdują problemy, takie jak brakujące, niekompletne lub nieprawidłowe dane podczas przeprowadzania analizy. Naprawiają problemy w aplikacji źródłowej, a następnie aktualizują je w rozwiązaniu analitycznym podczas następnej aktualizacji. Wszelkie nowe informacje do zarządzania są dodawane do aplikacji źródłowych, co zajmuje trochę czasu i jest kosztowne. | Rozwiązania MDM mają wbudowane funkcje zarządzania danymi, które umożliwiają użytkownikom dostęp do danych i zarządzanie nimi. W idealnym przypadku system flaguje problemy i monituje stewardów danych o ich naprawienie. Szybko skonfiguruj nowe informacje lub hierarchie w rozwiązaniu, aby zarządzać nimi przez stewardów danych. |
Przypadki użycia rozwiązania MDM
Chociaż istnieje wiele przypadków użycia w rozwiązaniu MDM, kilka przypadków użycia obejmuje większość rzeczywistych implementacji zarządzania urządzeniami przenośnymi. Mimo że te przypadki użycia koncentrują się na jednej domenie, jest mało prawdopodobne, aby skompilowane tylko z tej domeny. Innymi słowy, nawet te ukierunkowane przypadki użycia najprawdopodobniej obejmują wiele domen danych głównych.
Customer 360
Konsolidacja danych klientów na potrzeby analizy jest najczęstszym przypadkiem użycia rozwiązania MDM. Organizacje przechwytują dane klientów w coraz większej liczbie aplikacji, tworząc zduplikowane dane klientów w aplikacjach i w aplikacjach z niespójnościami i rozbieżnościami. Te dane klientów o niskiej jakości utrudniają realizację wartości nowoczesnych rozwiązań analitycznych. Objawy obejmują:
- Trudno odpowiedzieć na podstawowe pytania biznesowe, takie jak "KtoTo są naszymi najlepszymi klientami?" i "Ilu nowych klientów mieliśmy?", co wymaga znacznego nakładu pracy ręcznej.
- Brakujące i niedokładne informacje o kliencie, co utrudnia ich zwijanie lub przechodzenie do szczegółów danych.
- Brak możliwości analizowania danych klientów między systemami lub jednostkami biznesowymi ze względu na brak możliwości unikatowego identyfikowania klienta w granicach organizacji i systemu.
- Słabe informacje o jakości ze sztucznej inteligencji i uczenia maszynowego ze względu na niską jakość danych wejściowych.
Produkt 360
Dane produktów często rozprzestrzeniają się w wielu aplikacjach dla przedsiębiorstw, takich jak ERP, PLM lub e-commerce. Rezultatem jest zrozumienie całkowitego wykazu produktów, które mają niespójne definicje właściwości, takie jak nazwa, opis i cechy produktu. A różne definicje danych referencyjnych jeszcze bardziej komplikują tę sytuację. Objawy obejmują:
- Brak możliwości obsługi różnych alternatywnych hierarchicznych ścieżek zbiorczych i przechodzenia do szczegółów na potrzeby analizy produktów.
- Bez względu na to, czy gotowe towary czy zapasy materiałów, trudno zrozumieć dokładnie, jakie produkty masz pod ręką, od dostawców, z których kupujesz produkty, i duplikować produkty, co prowadzi do nadmiaru zapasów.
- Trudność racjonalizacji produktów z powodu sprzecznych definicji, co prowadzi do braku lub niedokładnych informacji w analizie.
Dane referencyjne 360
W kontekście analizy dane referencyjne istnieją jako liczne listy danych, które pomagają dokładniej opisać inne zestawy danych głównych. Dane referencyjne mogą zawierać listy krajów i regionów, walut, kolorów, rozmiarów i jednostek miary. Niespójne dane referencyjne prowadzą do oczywistych błędów w analizie podrzędnej. Objawy obejmują:
- Wiele reprezentacji tego samego elementu. Na przykład stan Georgia pokazuje jako "GA" i "Georgia", co utrudnia agregowanie i przechodzenie do danych spójnie.
- Trudności z agregowaniem danych z różnych aplikacji ze względu na niezdolność do krzyżowania wartości danych referencyjnych między systemami. Na przykład kolor czerwony jest wyświetlany jako "R" w systemie ERP i "Czerwony" w systemie PLM.
- Trudności z dopasowywaniem liczb w organizacjach ze względu na różnice w uzgodnionych wartościach danych referencyjnych dla kategoryzowania danych.
Finanse 360
Organizacje finansowe w dużym stopniu opierają się na danych dotyczących krytycznych działań, takich jak miesięczne, kwartalne i roczne raportowanie. Organizacje z wieloma systemami finansowymi i księgowymi często mają dane finansowe w wielu ogólnych rejestrach, które konsolidują w celu tworzenia raportów finansowych. Rozwiązanie MDM może zapewnić scentralizowane miejsce do mapowania kont, centrów kosztów, jednostek biznesowych i innych zestawów danych finansowych oraz zarządzania nimi w skonsolidowanym widoku. Objawy obejmują:
- Trudności z agregowaniem danych finansowych w wielu systemach w skonsolidowanym widoku.
- Brak procesu dodawania i mapowania nowych elementów danych w systemach finansowych.
- Opóźnienia w tworzeniu sprawozdań finansowych z końca okresu.
Kwestie wymagające rozważenia
Te zagadnienia implementują filary struktury Azure Well-Architected Framework, która jest zestawem wytycznych, które mogą służyć do poprawy jakości obciążenia. Aby uzyskać więcej informacji, zobacz Microsoft Azure Well-Architected Framework.
Niezawodność
Niezawodność zapewnia, że aplikacja może spełnić zobowiązania podjęte przez klientów. Aby uzyskać więcej informacji, zobacz Omówienie filaru niezawodności.
Profisee działa natywnie w usługach Azure Kubernetes Service i Azure SQL Database. Obie usługi oferują gotowe do użycia funkcje w celu zapewnienia wysokiej dostępności.
Efektywność wydajności
Efektywność wydajności to możliwość skalowania obciążenia w celu zaspokojenia zapotrzebowania użytkowników w wydajny sposób. Aby uzyskać więcej informacji, zobacz Omówienie filaru wydajności.
Profisee działa natywnie w usługach Azure Kubernetes Service i Azure SQL Database. Usługę Azure Kubernetes Service można skonfigurować do skalowania profisee w górę i w poziomie, w zależności od potrzeb. Usługę Azure SQL Database można wdrożyć w wielu różnych konfiguracjach, aby równoważyć wydajność, skalowalność i koszty.
Zabezpieczenia
Zabezpieczenia zapewniają ochronę przed celowymi atakami i nadużyciami cennych danych i systemów. Aby uzyskać więcej informacji, zobacz Omówienie filaru zabezpieczeń.
Profisee uwierzytelnia użytkowników za pomocą Połączenie OpenID, która implementuje przepływ uwierzytelniania OAuth 2.0. Większość organizacji konfiguruje profisee w celu uwierzytelniania użytkowników względem identyfikatora Entra firmy Microsoft. Ten proces zapewnia stosowanie i wymuszanie zasad przedsiębiorstwa na potrzeby uwierzytelniania.
Optymalizacja kosztów
Optymalizacja kosztów dotyczy sposobów zmniejszenia niepotrzebnych wydatków i poprawy wydajności operacyjnej. Aby uzyskać więcej informacji, zobacz Omówienie filaru optymalizacji kosztów.
Koszty działania składają się z licencji na oprogramowanie i użycia platformy Azure. Aby uzyskać więcej informacji, skontaktuj się z profisee.
Wdrażanie tego scenariusza
Aby wdrożyć ten scenariusz:
- Wdróż profisee na platformie Azure przy użyciu szablonu usługi ARM.
- Tworzenie usługi Azure Data Factory.
- Skonfiguruj usługę Azure Data Factory, aby nawiązać połączenie z repozytorium Git.
- Dodaj szablony usługi Azure Data Factory profisee do repozytorium Git usługi Azure Data Factory.
- Utwórz nowy potok usługi Azure Data Factory przy użyciu szablonu.
Współautorzy
Ten artykuł jest obsługiwany przez firmę Microsoft. Pierwotnie został napisany przez następujących współautorów.
Główny autor:
- Sunil Sabat | Główny menedżer programu
Aby wyświetlić niepubalne profile serwisu LinkedIn, zaloguj się do serwisu LinkedIn.
Następne kroki
- Poznaj możliwości Połączenie or kopiowania REST w usłudze Azure Data Factory.
- Dowiedz się więcej o usłudze Profisee działającej natywnie na platformie Azure.
- Dowiedz się, jak wdrożyć profisee na platformie Azure przy użyciu szablonu usługi ARM.
- Wyświetl szablony profisee Azure Data Factory.
Powiązane zasoby
Przewodniki dotyczące architektury
- Wyodrębnianie, transformacja i ładowanie (ETL)
- Infrastruktura Integration Runtime w usłudze Azure Data Factory
- Wybieranie technologii aranżacji potoku danych na platformie Azure