Jak ulepszyć model usługi Custom Vision
W tym przewodniku dowiesz się, jak poprawić jakość modelu usługi Custom Vision. Jakość klasyfikatora lub detektora obiektów zależy od ilości, jakości i różnych danych oznaczonych etykietami oraz tego, jak zrównoważony jest ogólny zestaw danych. Dobry model ma zrównoważony zestaw danych trenowania, który jest reprezentatywny dla tego, co zostanie przesłane do niego. Proces tworzenia takiego modelu jest iteracyjny; Często trzeba wykonać kilka rund treningu, aby osiągnąć oczekiwane wyniki.
Poniżej przedstawiono ogólny wzorzec ułatwiając trenowanie dokładniejszego modelu:
- Szkolenie w pierwszej rundzie
- Dodawanie większej liczby obrazów i równoważenie danych; Przekwalifikować
- Dodaj obrazy o różnym tle, oświetleniu, rozmiarze obiektu, kątze aparatu i stylu; Przekwalifikować
- Testowanie przewidywania przy użyciu nowych obrazów
- Modyfikowanie istniejących danych treningowych zgodnie z wynikami przewidywania
Zapobieganie nadmiernemu dopasowaniu
Czasami model nauczy się tworzyć przewidywania na podstawie dowolnych cech wspólnych dla obrazów. Na przykład, jeśli tworzysz klasyfikator dla jabłek a cytrusów, a używasz obrazów jabłek w rękach i cytrusów na białych talerzach, klasyfikator może dać niepotrzebne znaczenie dla rąk a talerzy, a nie jabłek a cytrusów.
Aby rozwiązać ten problem, należy udostępnić obrazy pod różnymi kątami, tłami, rozmiarem obiektu, grupami i innymi odmianami. Poniższe sekcje rozszerzają te pojęcia.
Ilość danych
Liczba obrazów szkoleniowych jest najważniejszym czynnikiem dla zestawu danych. Zalecamy używanie co najmniej 50 obrazów na etykietę jako punktu wyjścia. W przypadku mniejszej liczby obrazów występuje większe ryzyko nadmiernego dopasowania, a podczas gdy liczby wydajności mogą sugerować dobrą jakość, model może zmagać się z rzeczywistymi danymi.
Saldo danych
Ważne jest również, aby wziąć pod uwagę względne ilości danych treningowych. Na przykład użycie 500 obrazów dla jednej etykiety i 50 obrazów dla innej etykiety sprawia, że zestaw danych trenowania niezrównoważony. Spowoduje to, że model będzie bardziej dokładny w przewidywaniu jednej etykiety niż innej. Prawdopodobnie zobaczysz lepsze wyniki, jeśli zachowasz co najmniej 1:2 stosunek między etykietą z najmniejszymi obrazami a etykietą z największą liczbą obrazów. Jeśli na przykład etykieta z większością obrazów zawiera 500 obrazów, etykieta z najmniejszymi obrazami powinna zawierać co najmniej 250 obrazów do trenowania.
Różnorodność danych
Pamiętaj, aby używać obrazów, które są reprezentatywne dla klasyfikatora podczas normalnego użytku. W przeciwnym razie model może nauczyć się tworzyć przewidywania na podstawie dowolnych cech wspólnych dla obrazów. Na przykład, jeśli tworzysz klasyfikator dla jabłek a cytrusów, a używasz obrazów jabłek w rękach i cytrusów na białych talerzach, klasyfikator może dać niepotrzebne znaczenie dla rąk a talerzy, a nie jabłek a cytrusów.

Aby rozwiązać ten problem, uwzględnij różne obrazy, aby upewnić się, że model może dobrze uogólnić. Poniżej przedstawiono kilka sposobów, aby zestaw szkoleń był bardziej zróżnicowany:
Tło: podaj obrazy obiektu przed różnymi tłami. Zdjęcia w kontekstach naturalnych są lepsze niż zdjęcia przed neutralnymi tłami, ponieważ zapewniają więcej informacji dla klasyfikatora.

Oświetlenie: Udostępniaj obrazy o zróżnicowanym oświetleniu (czyli wykonanym z lampą błyskową, wysoką ekspozycją itd.), zwłaszcza jeśli obrazy używane do przewidywania mają różne oświetlenie. Warto również używać obrazów o różnym nasyceniu, odcieniu i jasności.

Rozmiar obiektu: podaj obrazy, w których obiekty różnią się rozmiarem i liczbą (na przykład zdjęcie pęczek bananów i zbliżenie pojedynczego bananu). Różne ustalanie rozmiaru pomaga klasyfikatorowi lepiej uogólniać.

kąt Aparat: Udostępnianie obrazów wykonanych z różnymi kątami aparatu. Alternatywnie, jeśli wszystkie zdjęcia muszą być wykonane ze stałymi kamerami (takimi jak kamery monitoringu), pamiętaj, aby przypisać inną etykietę do każdego regularnie występującego obiektu, aby uniknąć nadmiernego dopasowania — interpretowania niepowiązanych obiektów (takich jak latarnie) jako kluczową funkcję.

Styl: podaj obrazy różnych stylów tej samej klasy (na przykład różne odmiany tych samych owoców). Jeśli jednak masz obiekty o drastycznie różnych stylach (takich jak Mysz Miki miki w porównaniu z myszą w życiu rzeczywistym), zalecamy oznaczenie ich jako oddzielnych klas, aby lepiej reprezentować ich odrębne cechy.

Obrazy ujemne (tylko klasyfikatory)
Jeśli używasz klasyfikatora obrazów, może być konieczne dodanie próbek ujemnych, aby ułatwić bardziej precyzyjne klasyfikatorowi. Próbki ujemne to obrazy, które nie pasują do żadnego z innych tagów. Po przekazaniu tych obrazów zastosuj do nich specjalną etykietę Ujemna .
Detektory obiektów automatycznie obsługują próbki ujemne, ponieważ wszystkie obszary obrazów poza narysowanymi polami ograniczenia są uznawane za ujemne.
Uwaga
Usługa Custom Vision obsługuje automatyczną obsługę obrazów ujemnych. Jeśli na przykład tworzysz klasyfikator winogron i bananów i przesyłasz obraz buta do przewidywania, klasyfikator powinien ocenić ten obraz jako zbliżony do 0% zarówno dla winogron, jak i bananów.
Z drugiej strony w przypadkach, gdy obrazy ujemne są tylko odmianą obrazów używanych w trenowaniu, prawdopodobnie model będzie klasyfikować obrazy ujemne jako klasę oznaczona etykietą ze względu na wielkie podobieństwa. Na przykład, jeśli masz pomarańczowy vs klasyfikator grejpfruta, i karmisz się na obrazie klemensyny, może zdobyć klemensyny jako pomarańczę, ponieważ wiele cech klemensyny przypomina te z pomarańczy. Jeśli negatywne obrazy są tego rodzaju, zalecamy utworzenie co najmniej jednego dodatkowego tagu (takiego jak Inne) i oznaczenie obrazów ujemnych tym tagiem podczas trenowania, aby umożliwić modelowi lepsze rozróżnienie między tymi klasami.
Okluzji i obcinania (tylko detektory obiektów)
Jeśli chcesz, aby detektor obiektów wykrył obcięte obiekty (obiekty, które są częściowo wycięte z obrazu) lub obiektów okludowanych (obiektów częściowo zablokowanych przez inne obiekty na obrazie), należy uwzględnić obrazy szkoleniowe, które obejmują te przypadki.
Uwaga
Problem obiektów, które są okludnione przez inne obiekty, nie należy mylić z nakładającymi się progami, parametrem wydajności modelu klasyfikacji. Suwak Nakładający się próg w witrynie internetowej usługi Custom Vision zajmuje się tym, ile przewidywana granica musi nakładać się na rzeczywiste pole ograniczenia, aby było traktowane jako poprawne.
Używanie obrazów przewidywania do dalszego trenowania
Jeśli używasz lub testujesz model, przesyłając obrazy do punktu końcowego przewidywania, usługa Custom Vision przechowuje te obrazy. Następnie można ich użyć, aby ulepszyć model.
Aby wyświetlić obrazy przesłane do modelu, otwórz stronę internetową usługi Custom Vision, przejdź do projektu i wybierz kartę Przewidywania . Widok domyślny przedstawia obrazy z bieżącej iteracji. Możesz użyć menu rozwijanego Iteracji , aby wyświetlić obrazy przesłane podczas poprzednich iteracji.
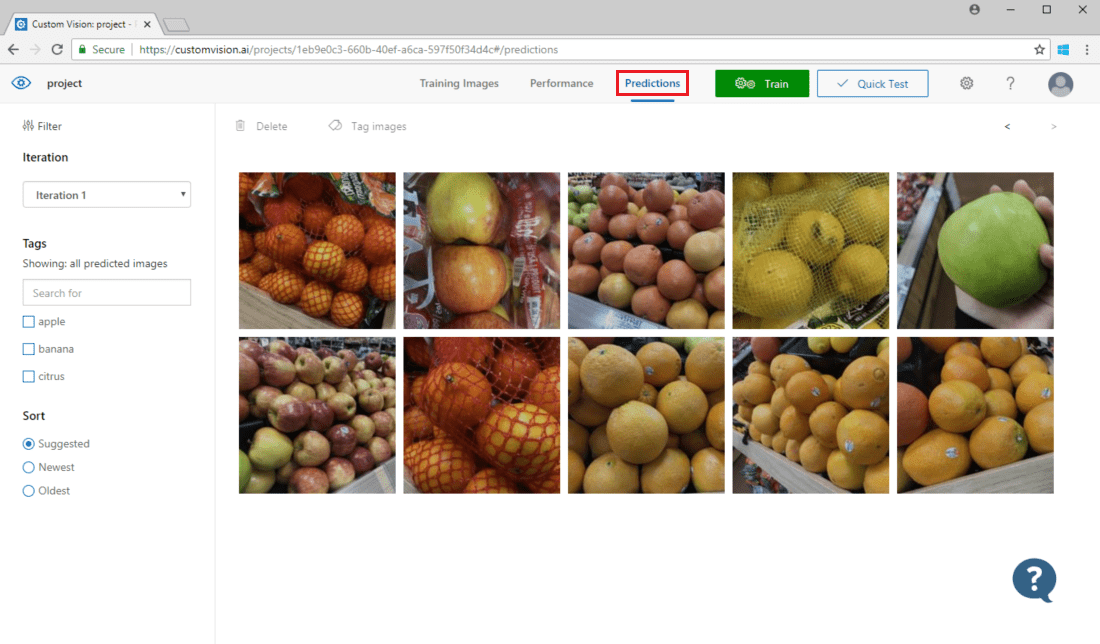
Zatrzymaj wskaźnik myszy na obrazie, aby zobaczyć tagi przewidywane przez model. Obrazy są sortowane tak, aby te, które mogą przynieść najwięcej ulepszeń do modelu, są wymienione na początku. Aby użyć innej metody sortowania, zaznacz pole wyboru w sekcji Sortowanie .
Aby dodać obraz do istniejących danych treningowych, wybierz obraz, ustaw poprawne tagi, a następnie wybierz pozycję Zapisz i zamknij. Obraz zostanie usunięty z sekcji Predictions (Przewidywania) i dodany do zestawu obrazów szkoleniowych. Możesz go wyświetlić, wybierając kartę Obrazy szkoleniowe.
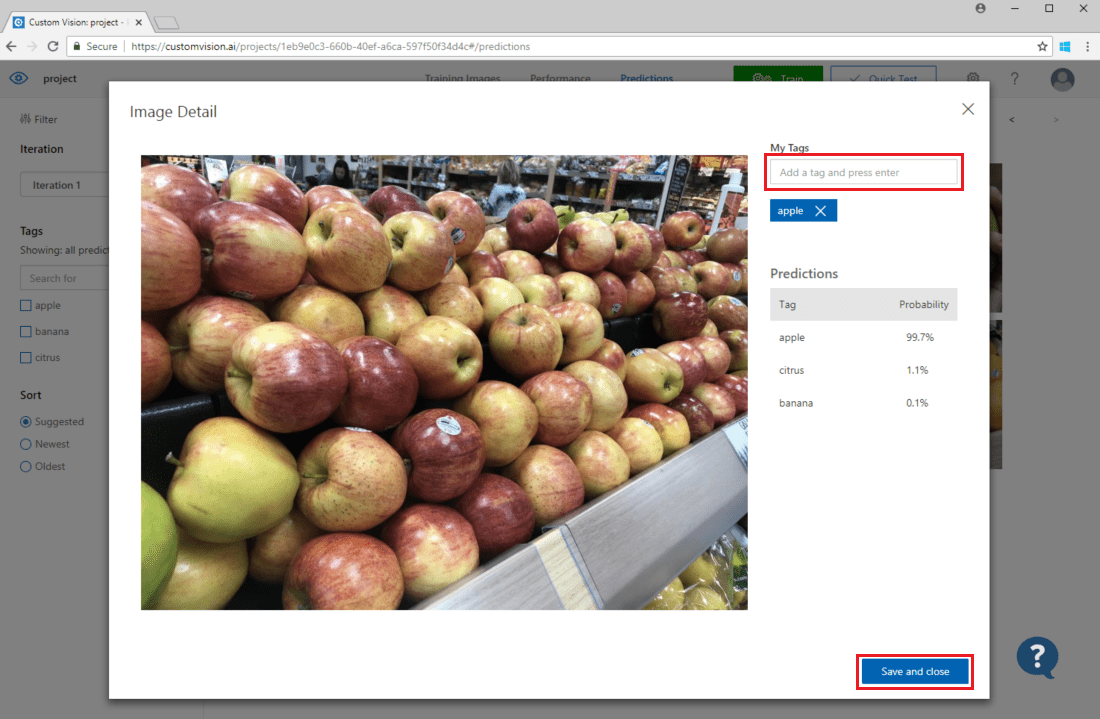
Następnie użyj przycisku Train (Trenowanie), aby ponownie wytrenować model.
Wizualne sprawdzanie przewidywań
Aby sprawdzić przewidywania obrazów, przejdź do karty Obrazy szkoleniowe, wybierz poprzednią iterację trenowania w menu rozwijanym Iteracji i sprawdź co najmniej jeden tag w sekcji Tagi. Widok powinien teraz wyświetlić czerwone pole wokół każdego z obrazów, dla których model nie może poprawnie przewidzieć danego tagu.
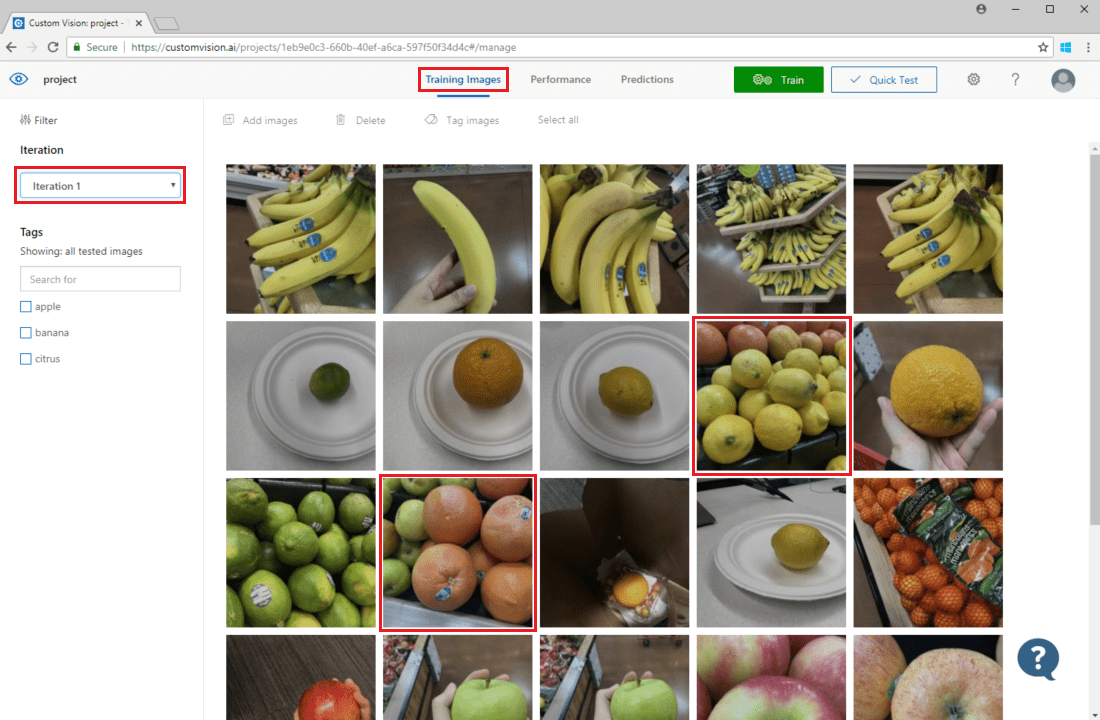
Czasami inspekcja wizualna może identyfikować wzorce, które można następnie poprawić, dodając więcej danych treningowych lub modyfikując istniejące dane szkoleniowe. Na przykład klasyfikator jabłek a limonki może niepoprawnie oznaczyć wszystkie zielone jabłka jako limonki. Następnie możesz rozwiązać ten problem, dodając i dostarczając dane szkoleniowe zawierające oznakowane obrazy zielonych jabłek.
Następne kroki
W tym przewodniku przedstawiono kilka technik, dzięki którym niestandardowy model klasyfikacji obrazów lub model narzędzia do wykrywania obiektów jest bardziej dokładny. Następnie dowiedz się, jak programowo testować obrazy, przesyłając je do interfejsu API przewidywania.