Co to jest rozpoznawanie osoby mówiącej?
Rozpoznawanie osoby mówiącej może pomóc w ustaleniu, kto mówi w klipie audio. Usługa może weryfikować i identyfikować osoby mówiące o ich unikatowych cechach głosowych przy użyciu biometrii głosowej.
Udostępniasz dane szkoleniowe audio dla pojedynczego głośnika, który tworzy profil rejestracji na podstawie unikatowych cech głosu osoby mówiącej. Następnie możesz sprawdzić krzyżowo próbki głosu audio w tym profilu, aby sprawdzić, czy osoba mówiąca jest tą samą osobą (weryfikacja osoby mówiącej). Możesz również sprawdzić krzyżowo próbki głosowe dla grupy zarejestrowanych profilów osoby mówiącej, aby sprawdzić, czy pasuje do dowolnego profilu w grupie (identyfikacja osoby mówiącej).
Ważne
Firma Microsoft ogranicza dostęp do rozpoznawania osoby mówiącej. Możesz ubiegać się o dostęp za pośrednictwem przeglądu ograniczonego dostępu w usługach Azure AI services rozpoznawania osoby mówiącej. Aby uzyskać więcej informacji, zobacz Ograniczony dostęp do rozpoznawania osoby mówiącej.
Weryfikacja osoby mówiącej
Weryfikacja osoby mówiącej usprawnia proces weryfikowania zarejestrowanej tożsamości osoby mówiącej przy użyciu haseł lub wprowadzania głosu w dowolnej formie. Można na przykład użyć jej do weryfikacji tożsamości klienta w centrach obsługi telefonicznej lub dostępu do obiektu bez kontaktu.
Jak działa weryfikacja osoby mówiącej?
Poniższy schemat blokowy zawiera wizualizację tego, jak to działa:
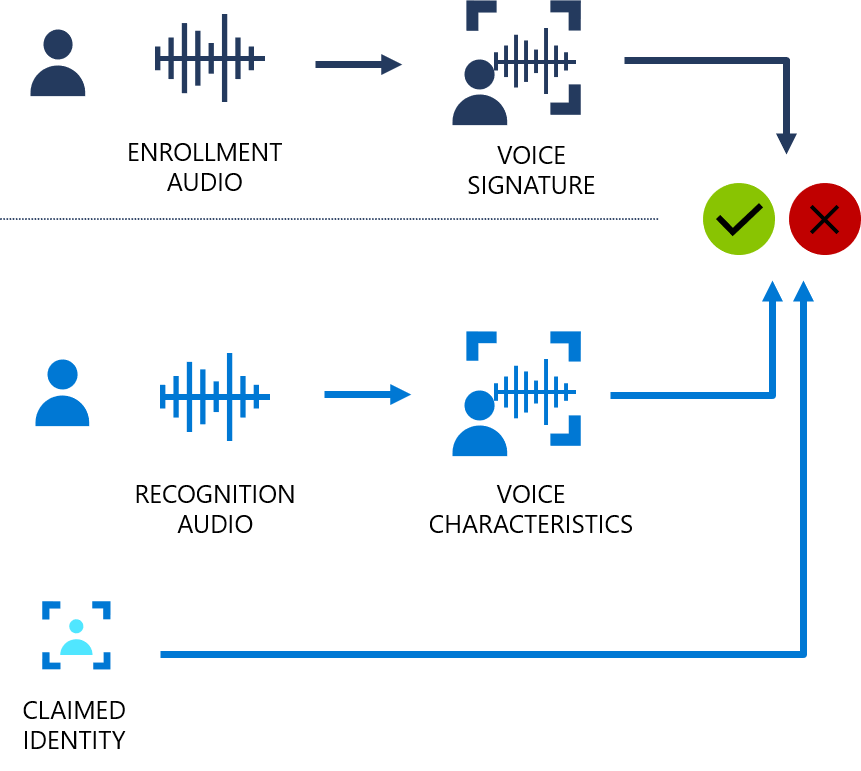
Weryfikacja osoby mówiącej może być zależna od tekstu lub niezależna od tekstu. Weryfikacja zależna od tekstu oznacza, że prelegenci muszą wybrać to samo hasło do użycia zarówno podczas fazy rejestracji, jak i weryfikacji. Weryfikacja niezależna od tekstu oznacza, że osoby mówiące mogą mówić w codziennym języku w ramach rejestracji i fraz weryfikacji.
W przypadku weryfikacji zależnej od tekstu głos osoby mówiącej jest zarejestrowany, mówiąc hasło z zestawu wstępnie zdefiniowanych fraz. Funkcje głosowe są wyodrębniane z nagrania audio w celu utworzenia unikatowego podpisu głosowego, a wybrane hasło jest również rozpoznawane. Razem podpis głosowy i hasło są używane do weryfikowania osoby mówiącej.
Weryfikacja niezależna od tekstu nie ma żadnych ograniczeń dotyczących tego, co mówi prelegent podczas rejestracji, oprócz początkowej frazy aktywacji po włączeniu aktywnej rejestracji. Nie ma żadnych ograniczeń dotyczących próbki audio do zweryfikowania, ponieważ wyodrębnia tylko funkcje głosowe w celu oceny podobieństwa.
Interfejsy API nie mają na celu określenia, czy dźwięk pochodzi od osoby na żywo, czy z imitacji lub nagrywania zarejestrowanego osoby mówiącej.
Identyfikacja osoby mówiącej
Identyfikacja osoby mówiącej pomaga określić tożsamość nieznanego osoby mówiącej w grupie zarejestrowanych osób mówiących. Identyfikacja osoby mówiącej umożliwia przypisywanie mowy do poszczególnych osób mówiących i odblokowywanie wartości ze scenariuszy z wieloma głośnikami, takimi jak:
- Obsługa rozwiązań zwiększających produktywność spotkań zdalnych.
- Tworzenie personalizacji urządzeń z wieloma użytkownikami.
Jak działa identyfikacja osoby mówiącej?
Rejestracja na potrzeby identyfikacji osoby mówiącej jest niezależna od tekstu. Nie ma żadnych ograniczeń dotyczących tego, co mówi głośnik w dźwięku, oprócz początkowej frazy aktywacji po włączeniu aktywnej rejestracji. Podobnie jak w przypadku weryfikacji osoby mówiącej, głos osoby mówiącej jest rejestrowany w fazie rejestracji, a funkcje głosowe są wyodrębniane w celu utworzenia unikatowego podpisu głosowego. W fazie identyfikacji próbka głosu wejściowego jest porównywana z określoną listą zarejestrowanych głosów (do 50 w każdym żądaniu).
Bezpieczeństwo danych i prywatność
Dane rejestracji osoby mówiącej są przechowywane w zabezpieczonym systemie, w tym dźwięk mowy na potrzeby rejestracji i funkcji podpisu głosowego. Dźwięk mowy do rejestracji jest używany tylko podczas uaktualniania algorytmu, a funkcje muszą zostać wyodrębnione ponownie. Usługa nie zachowuje nagrania mowy ani wyodrębnionych funkcji głosowych wysyłanych do usługi w fazie rozpoznawania.
Określasz, jak długo mają być przechowywane dane. Możesz tworzyć, aktualizować i usuwać dane rejestracji dla poszczególnych osób mówiących za pomocą wywołań interfejsu API. Po usunięciu subskrypcji wszystkie dane rejestracji osoby mówiącej skojarzone z subskrypcją również zostaną usunięte.
Podobnie jak we wszystkich zasobach usług Azure AI, deweloperzy korzystający z funkcji rozpoznawania osoby mówiącej muszą mieć świadomość zasad firmy Microsoft dotyczących danych klientów. Upewnij się, że otrzymano odpowiednie uprawnienia od użytkowników. Więcej szczegółów można znaleźć w artykule Dane i prywatność na potrzeby rozpoznawania osoby mówiącej. Aby uzyskać więcej informacji, zobacz stronę usługi Azure AI w Centrum zaufania firmy Microsoft.
Typowe pytania i rozwiązania
| Pytanie | Rozwiązanie |
|---|---|
| Jakie sytuacje najprawdopodobniej używam rozpoznawania osoby mówiącej? | Dobrymi przykładami są weryfikacja klienta w centrum obsługi telefonicznej, ewidencjonowanie pacjentów oparte na głosach, transkrypcja spotkań i personalizacja urządzeń z wieloma użytkownikami. |
| Jaka jest różnica między identyfikacją a weryfikacją? | Identyfikacja to proces wykrywania, który element członkowski z grupy osób mówiących mówi. Weryfikacja to czynność potwierdzenia, że głośnik pasuje do znanego, zarejestrowanego głosu. |
| Jakie języki są obsługiwane? | Zobacz Obsługa języka rozpoznawania osoby mówiącej. |
| Jakie regiony platformy Azure są obsługiwane? | Zobacz Obsługa regionów rozpoznawania osoby mówiącej. |
| Jakie formaty audio są obsługiwane? | Mono 16-bitowy, 16 kHz PCM zakodowany WAV. |
| Czy można zarejestrować jednego głośnika wiele razy? | Tak, w przypadku weryfikacji zależnej od tekstu można zarejestrować osoby mówiącej maksymalnie 50 razy. W przypadku weryfikacji niezależnej od tekstu lub identyfikacji osoby mówiącej można zarejestrować maksymalnie 300 sekund dźwięku. |
| Jakie dane są przechowywane na platformie Azure? | Dźwięk rejestracji jest przechowywany w usłudze do momentu usunięcia profilu głosowego. Przykłady audio rozpoznawania nie są zachowywane ani przechowywane. |
Odpowiedzialne AI
System sztucznej inteligencji obejmuje nie tylko technologię, ale także osoby, które go używają, osoby, których to dotyczy, oraz środowisko, w którym jest wdrażane. Zapoznaj się z uwagami dotyczącymi przejrzystości, aby dowiedzieć się więcej na temat odpowiedzialnego używania sztucznej inteligencji i wdrażania w systemach.
- Notatka dotycząca przezroczystości i przypadki użycia
- Cechy i ograniczenia
- Ograniczony dostęp
- Ogólne wytyczne
- Dane, prywatność i bezpieczeństwo