Migrowanie danych z usługi Amazon S3 do usługi Azure Data Lake Storage Gen2
DOTYCZY: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Napiwek
Wypróbuj usługę Data Factory w usłudze Microsoft Fabric — rozwiązanie analityczne typu all-in-one dla przedsiębiorstw. Usługa Microsoft Fabric obejmuje wszystko, od przenoszenia danych do nauki o danych, analizy w czasie rzeczywistym, analizy biznesowej i raportowania. Dowiedz się, jak bezpłatnie rozpocząć nową wersję próbną !
Użyj szablonów, aby migrować petabajty danych składających się z setek milionów plików z usługi Amazon S3 do usługi Azure Data Lake Storage Gen2.
Uwaga
Jeśli chcesz skopiować mały wolumin danych z usługi AWS S3 na platformę Azure (na przykład mniej niż 10 TB), bardziej wydajne i łatwe jest korzystanie z narzędzia do kopiowania danych usługi Azure Data Factory. Szablon opisany w tym artykule jest czymś więcej niż potrzebnym szablonem.
Informacje o szablonach rozwiązań
Partycja danych jest zalecana szczególnie w przypadku migrowania ponad 10 TB danych. Aby podzielić dane na partycje, użyj ustawienia "prefiks", aby filtrować foldery i pliki w usłudze Amazon S3 według nazwy, a następnie każde zadanie kopiowania usługi ADF może skopiować jedną partycję naraz. W celu uzyskania lepszej przepływności można jednocześnie uruchamiać wiele zadań kopiowania usługi ADF.
Migracja danych zwykle wymaga jednorazowej migracji danych historycznych oraz okresowego synchronizowania zmian z usługi AWS S3 na platformę Azure. Poniżej przedstawiono dwa szablony, w których jeden szablon obejmuje jednorazową migrację danych historycznych, a drugi szablon obejmuje synchronizowanie zmian z usługi AWS S3 na platformę Azure.
Aby szablon migrować dane historyczne z usługi Amazon S3 do usługi Azure Data Lake Storage Gen2
Ten szablon (nazwa szablonu: migrowanie danych historycznych z usługi AWS S3 do usługi Azure Data Lake Storage Gen2) zakłada, że utworzono listę partycji w tabeli kontroli zewnętrznej w usłudze Azure SQL Database. W związku z tym użyje działania Lookup w celu pobrania listy partycji z tabeli kontroli zewnętrznej, iteracji nad każdą partycją i skopiowania każdego zadania kopiowania usługi ADF pojedynczo. Po zakończeniu dowolnego zadania kopiowania jest używane działanie Procedury składowanej w celu zaktualizowania stanu kopiowania każdej partycji w tabeli kontrolnej.
Szablon zawiera pięć działań:
- Odnośnik pobiera partycje, które nie zostały skopiowane do usługi Azure Data Lake Storage Gen2 z tabeli kontroli zewnętrznej. Nazwa tabeli jest s3_partition_control_table, a zapytanie do ładowania danych z tabeli to "SELECT PartitionPrefix FROM s3_partition_control_table WHERE SuccessOrFailure = 0".
- Program ForEach pobiera listę partycji z działania Lookup i iteruje każdą partycję do działania TriggerCopy . Możesz ustawić właściwość batchCount , aby jednocześnie uruchamiać wiele zadań kopiowania usługi ADF. Ustawiliśmy wartość 2 w tym szablonie.
- ExecutePipeline wykonuje potok CopyFolderPartitionFromS3 . Powodem utworzenia innego potoku w celu skopiowania każdego zadania kopiowania partycji jest to, że ułatwi ponowne uruchomienie zadania kopiowania, które zakończyło się niepowodzeniem, aby ponownie załadować tę konkretną partycję z usługi AWS S3. Nie będzie to miało wpływu na wszystkie inne zadania kopiowania ładujący inne partycje.
- Kopiuje każdą partycję z usługi AWS S3 do usługi Azure Data Lake Storage Gen2.
- SqlServerStoredProcedure zaktualizuj stan kopiowania każdej partycji w tabeli kontrolnej.
Szablon zawiera dwa parametry:
- AWS_S3_bucketName to nazwa zasobnika na platformie AWS S3, z której chcesz przeprowadzić migrację danych. Jeśli chcesz przeprowadzić migrację danych z wielu zasobników na platformie AWS S3, możesz dodać jeszcze jedną kolumnę w tabeli kontroli zewnętrznej, aby zapisać nazwę zasobnika dla każdej partycji, a także zaktualizować potok w celu odpowiedniego pobrania danych z tej kolumny.
- Azure_Storage_fileSystem to nazwa systemu plików w usłudze Azure Data Lake Storage Gen2, do której chcesz przeprowadzić migrację danych.
Aby szablon skopiował zmienione pliki tylko z usługi Amazon S3 do usługi Azure Data Lake Storage Gen2
Ten szablon (nazwa szablonu: kopiowanie danych różnicowych z usługi AWS S3 do usługi Azure Data Lake Storage Gen2) używa funkcji LastModifiedTime każdego pliku w celu skopiowania nowych lub zaktualizowanych plików tylko z usługi AWS S3 na platformę Azure. Należy pamiętać, że pliki lub foldery zostały już podzielone na partycje z informacjami o czasie w ramach nazwy pliku lub folderu na platformie AWS S3 (na przykład /rrrr/mm/dd/file.csv), możesz przejść do tego samouczka , aby uzyskać bardziej wydajne podejście do przyrostowego ładowania nowych plików. W tym szablonie przyjęto założenie, że utworzono listę partycji w zewnętrznej tabeli kontroli w usłudze Azure SQL Database. W związku z tym użyje działania Lookup w celu pobrania listy partycji z tabeli kontroli zewnętrznej, iteracji nad każdą partycją i skopiowania każdego zadania kopiowania usługi ADF pojedynczo. Gdy każde zadanie kopiowania zacznie kopiować pliki z usługi AWS S3, opiera się na właściwości LastModifiedTime w celu zidentyfikowania i skopiowania tylko nowych lub zaktualizowanych plików. Po zakończeniu dowolnego zadania kopiowania jest używane działanie Procedury składowanej w celu zaktualizowania stanu kopiowania każdej partycji w tabeli kontrolnej.
Szablon zawiera siedem działań:
- Odnośnik pobiera partycje z tabeli kontroli zewnętrznej. Nazwa tabeli jest s3_partition_delta_control_table, a zapytanie do ładowania danych z tabeli to "select distinct PartitionPrefix from s3_partition_delta_control_table".
- Program ForEach pobiera listę partycji z działania Lookup i iteruje każdą partycję do działania TriggerDeltaCopy . Możesz ustawić właściwość batchCount , aby jednocześnie uruchamiać wiele zadań kopiowania usługi ADF. Ustawiliśmy wartość 2 w tym szablonie.
- ExecutePipeline wykonuje potok DeltaCopyFolderPartitionFromS3 . Powodem utworzenia innego potoku w celu skopiowania każdego zadania kopiowania partycji jest to, że ułatwi ponowne uruchomienie zadania kopiowania, które zakończyło się niepowodzeniem, aby ponownie załadować tę konkretną partycję z usługi AWS S3. Nie będzie to miało wpływu na wszystkie inne zadania kopiowania ładujący inne partycje.
- Odnośnik pobiera czas wykonywania ostatniego zadania kopiowania z tabeli kontroli zewnętrznej, aby można było zidentyfikować nowe lub zaktualizowane pliki za pośrednictwem funkcji LastModifiedTime. Nazwa tabeli jest s3_partition_delta_control_table, a zapytanie do ładowania danych z tabeli to "select max(JobRunTime) as LastModifiedTime from s3_partition_delta_control_table where PartitionPrefix = '@{pipeline().parameters.prefixStr}" i SuccessOrFailure = 1".
- Kopiuje nowe lub zmienione pliki tylko dla każdej partycji z usługi AWS S3 do usługi Azure Data Lake Storage Gen2. Właściwość modifiedDatetimeStart jest ustawiona na czas wykonywania ostatniego zadania kopiowania. Właściwość modifiedDatetimeEnd jest ustawiona na bieżący czas wykonywania zadania kopiowania. Należy pamiętać, że czas jest stosowany do strefy czasowej UTC.
- SqlServerStoredProcedure zaktualizuj stan kopiowania każdej partycji i kopiowania czasu wykonywania w tabeli kontrolnej po pomyślnym zakończeniu. Kolumna SuccessOrFailure jest ustawiona na 1.
- SqlServerStoredProcedure zaktualizuj stan kopiowania każdej partycji i skopiuj czas wykonywania w tabeli kontrolnej, gdy zakończy się niepowodzeniem. Kolumna SuccessOrFailure jest ustawiona na 0.
Szablon zawiera dwa parametry:
- AWS_S3_bucketName to nazwa zasobnika na platformie AWS S3, z której chcesz przeprowadzić migrację danych. Jeśli chcesz przeprowadzić migrację danych z wielu zasobników na platformie AWS S3, możesz dodać jeszcze jedną kolumnę w tabeli kontroli zewnętrznej, aby zapisać nazwę zasobnika dla każdej partycji, a także zaktualizować potok w celu odpowiedniego pobrania danych z tej kolumny.
- Azure_Storage_fileSystem to nazwa systemu plików w usłudze Azure Data Lake Storage Gen2, do której chcesz przeprowadzić migrację danych.
Jak używać tych dwóch szablonów rozwiązań
Aby szablon migrować dane historyczne z usługi Amazon S3 do usługi Azure Data Lake Storage Gen2
Utwórz tabelę kontrolną w usłudze Azure SQL Database, aby przechowywać listę partycji usługi AWS S3.
Uwaga
Nazwa tabeli to s3_partition_control_table. Schemat tabeli sterowania to PartitionPrefix i SuccessOrFailure, gdzie PartitionPrefix jest ustawieniem prefiksu w usłudze S3 w celu filtrowania folderów i plików w usłudze Amazon S3 według nazwy, a SuccessOrFailure jest stanem kopiowania każdej partycji: 0 oznacza, że ta partycja nie została skopiowana na platformę Azure i 1 oznacza, że ta partycja została pomyślnie skopiowana na platformę Azure. W tabeli kontrolnej zdefiniowano 5 partycji, a domyślny stan kopiowania każdej partycji to 0.
CREATE TABLE [dbo].[s3_partition_control_table]( [PartitionPrefix] [varchar](255) NULL, [SuccessOrFailure] [bit] NULL ) INSERT INTO s3_partition_control_table (PartitionPrefix, SuccessOrFailure) VALUES ('a', 0), ('b', 0), ('c', 0), ('d', 0), ('e', 0);Utwórz procedurę składowaną w tej samej bazie danych Azure SQL Database dla tabeli sterowania.
Uwaga
Nazwa procedury składowanej jest sp_update_partition_success. Zostanie ona wywołana przez działanie SqlServerStoredProcedure w potoku usługi ADF.
CREATE PROCEDURE [dbo].[sp_update_partition_success] @PartPrefix varchar(255) AS BEGIN UPDATE s3_partition_control_table SET [SuccessOrFailure] = 1 WHERE [PartitionPrefix] = @PartPrefix END GOPrzejdź do szablonu Migrowanie danych historycznych z usługi AWS S3 do usługi Azure Data Lake Storage Gen2 . Wprowadź połączenia z zewnętrzną tabelą kontroli, usługą AWS S3 jako magazynem źródła danych i magazynem docelowym usługi Azure Data Lake Storage Gen2. Należy pamiętać, że tabela kontroli zewnętrznej i procedura składowana odwołują się do tego samego połączenia.
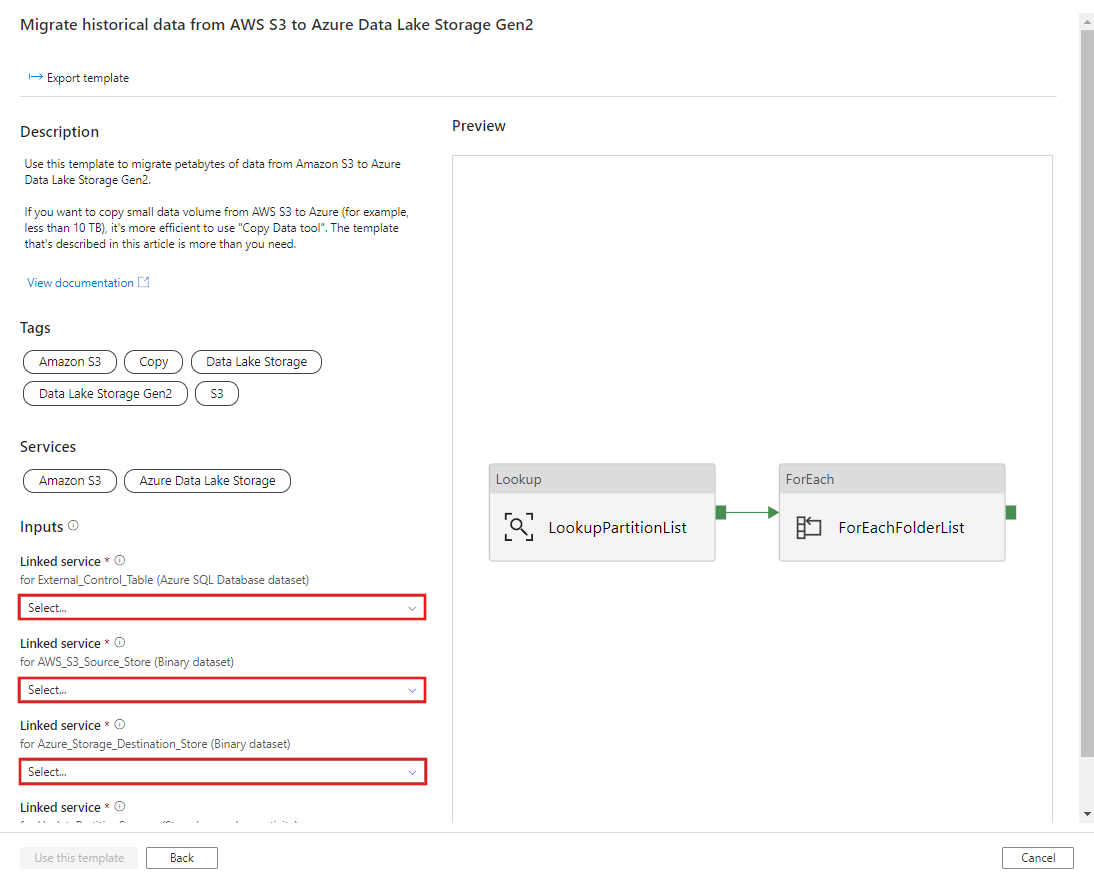
Wybierz Użyj tego szablonu.
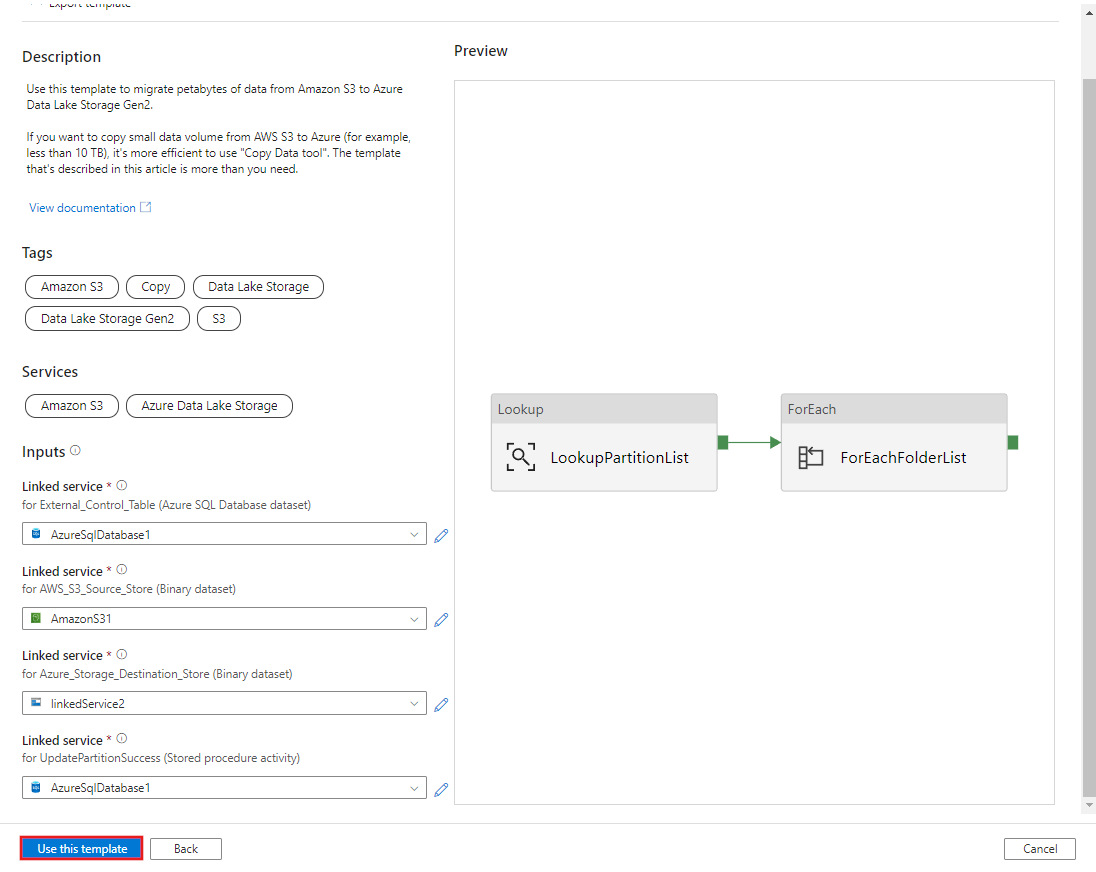
Zobaczysz, że zostały utworzone 2 potoki i 3 zestawy danych, jak pokazano w poniższym przykładzie:
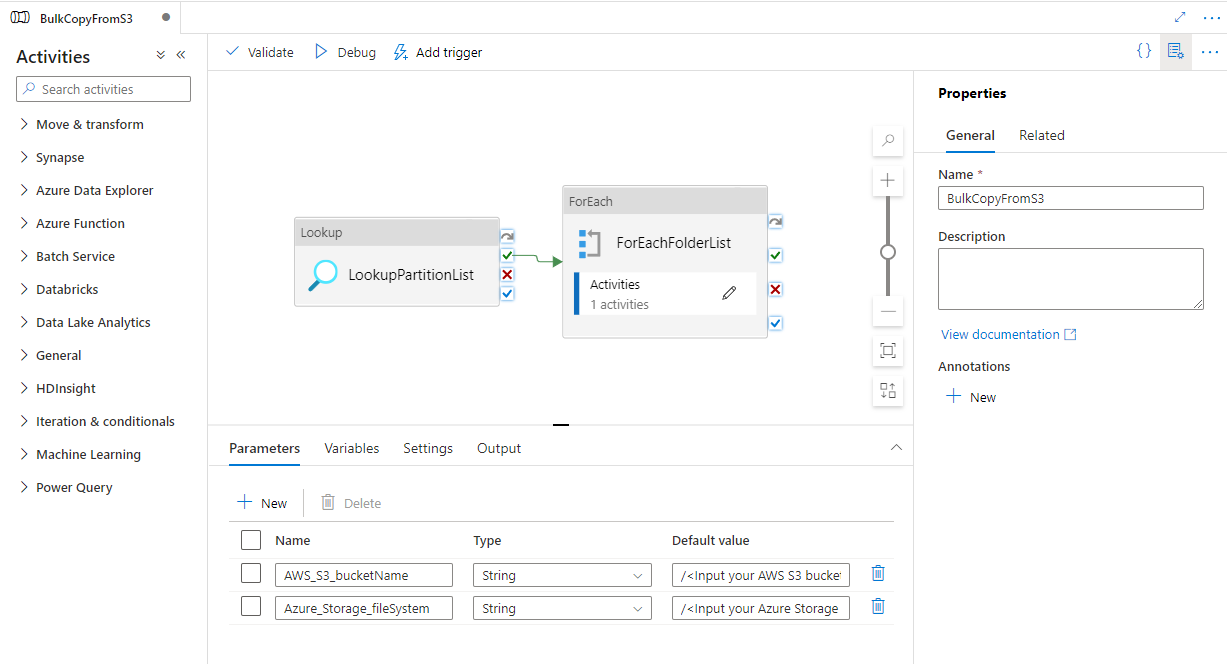
Przejdź do potoku "BulkCopyFromS3" i wybierz pozycję Debuguj, wprowadź parametry. Następnie wybierz pozycję Zakończ.
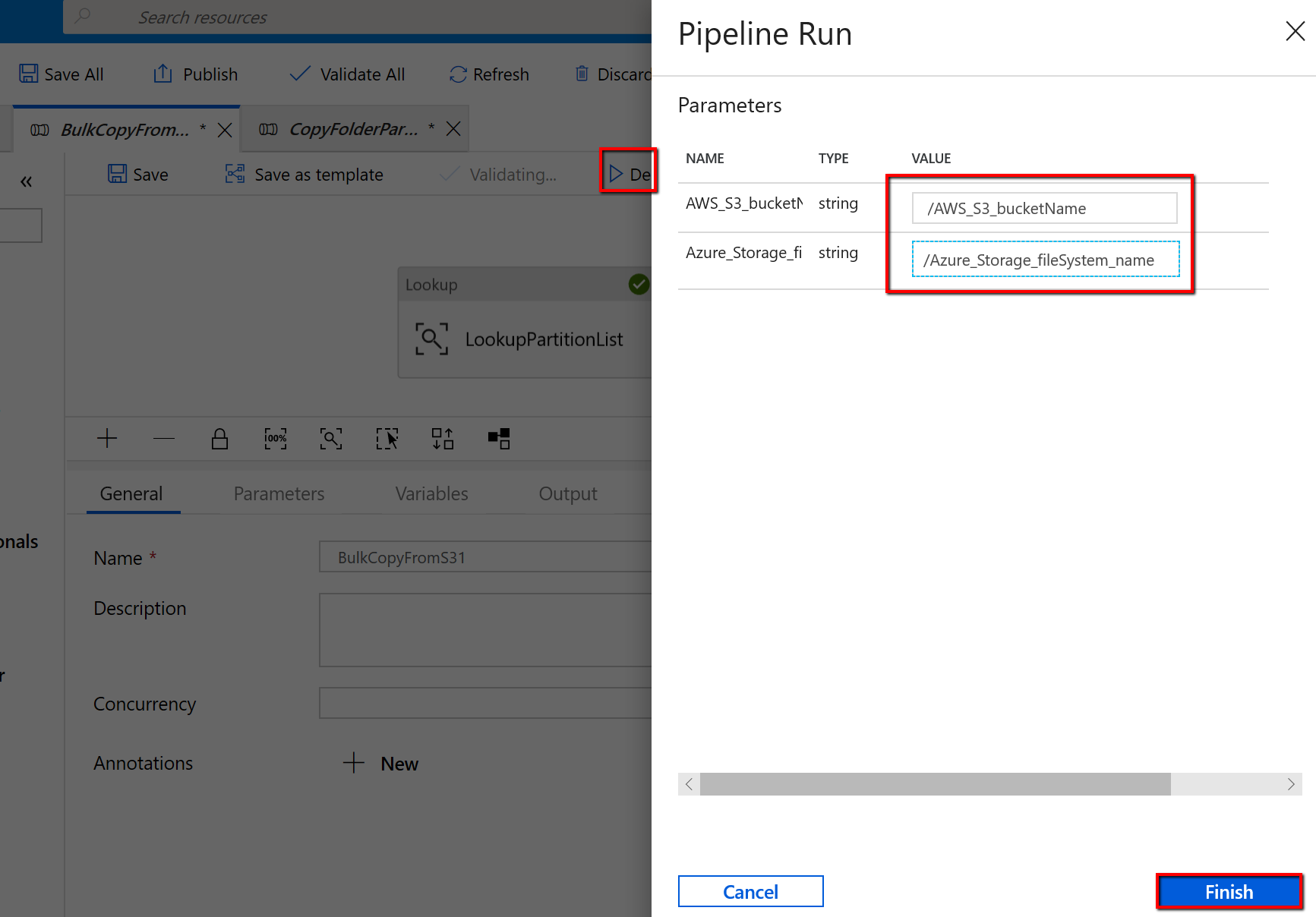
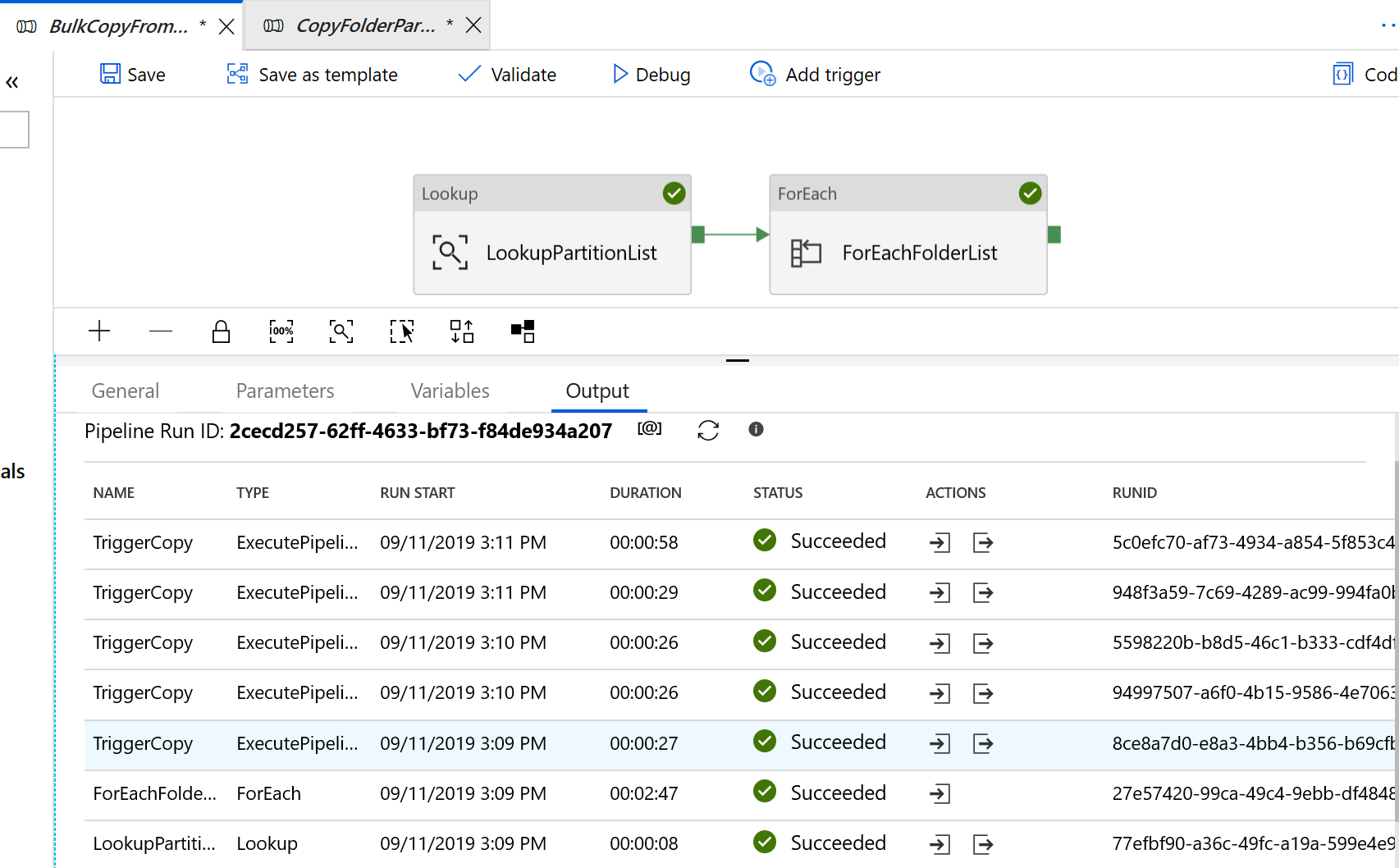
Zostaną wyświetlone wyniki podobne do następującego przykładu:
Aby szablon skopiował zmienione pliki tylko z usługi Amazon S3 do usługi Azure Data Lake Storage Gen2
Utwórz tabelę kontrolną w usłudze Azure SQL Database, aby przechowywać listę partycji usługi AWS S3.
Uwaga
Nazwa tabeli to s3_partition_delta_control_table. Schemat tabeli sterowania to PartitionPrefix, JobRunTime i SuccessOrFailure, gdzie PartitionPrefix jest ustawieniem prefiksu w S3, aby filtrować foldery i pliki w usłudze Amazon S3 według nazwy, JobRunTime jest wartością daty/godziny po uruchomieniu zadań kopiowania, a SuccessOrFailure jest stanem kopiowania każdej partycji: 0 oznacza, że ta partycja nie została pomyślnie skopiowana na platformę Azure i 1 oznacza, że ta partycja została pomyślnie skopiowana na platformę Azure. W tabeli sterowania zdefiniowano 5 partycji. Wartość domyślna jobRunTime może być czasem rozpoczęcia jednorazowej migracji danych historycznych. Działanie kopiowania usługi ADF spowoduje skopiowanie plików na platformie AWS S3, które zostały ostatnio zmodyfikowane po tym czasie. Domyślny stan kopiowania każdej partycji to 1.
CREATE TABLE [dbo].[s3_partition_delta_control_table]( [PartitionPrefix] [varchar](255) NULL, [JobRunTime] [datetime] NULL, [SuccessOrFailure] [bit] NULL ) INSERT INTO s3_partition_delta_control_table (PartitionPrefix, JobRunTime, SuccessOrFailure) VALUES ('a','1/1/2019 12:00:00 AM',1), ('b','1/1/2019 12:00:00 AM',1), ('c','1/1/2019 12:00:00 AM',1), ('d','1/1/2019 12:00:00 AM',1), ('e','1/1/2019 12:00:00 AM',1);Utwórz procedurę składowaną w tej samej bazie danych Azure SQL Database dla tabeli sterowania.
Uwaga
Nazwa procedury składowanej to sp_insert_partition_JobRunTime_success. Zostanie ona wywołana przez działanie SqlServerStoredProcedure w potoku usługi ADF.
CREATE PROCEDURE [dbo].[sp_insert_partition_JobRunTime_success] @PartPrefix varchar(255), @JobRunTime datetime, @SuccessOrFailure bit AS BEGIN INSERT INTO s3_partition_delta_control_table (PartitionPrefix, JobRunTime, SuccessOrFailure) VALUES (@PartPrefix,@JobRunTime,@SuccessOrFailure) END GOPrzejdź do szablonu Kopiowanie danych różnicowych z usługi AWS S3 do usługi Azure Data Lake Storage Gen2 . Wprowadź połączenia z zewnętrzną tabelą kontroli, usługą AWS S3 jako magazynem źródła danych i magazynem docelowym usługi Azure Data Lake Storage Gen2. Należy pamiętać, że tabela kontroli zewnętrznej i procedura składowana odwołują się do tego samego połączenia.
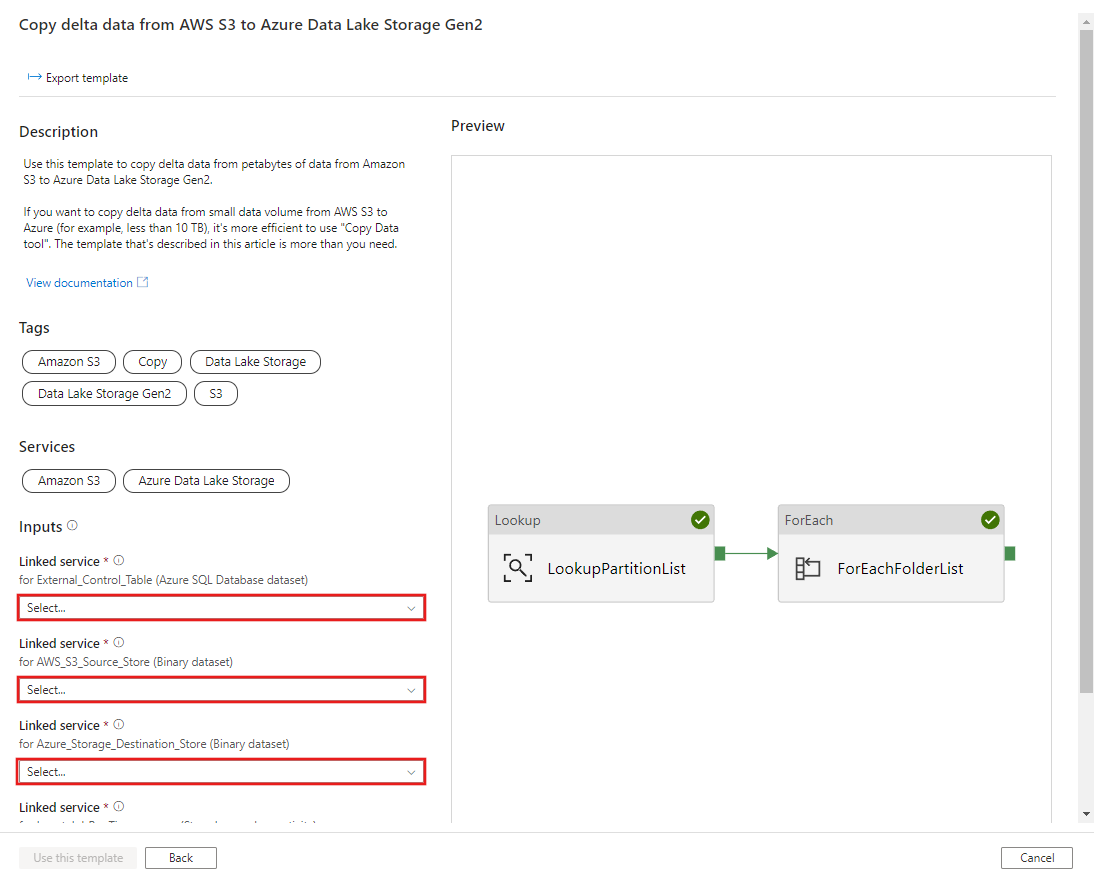
Wybierz Użyj tego szablonu.
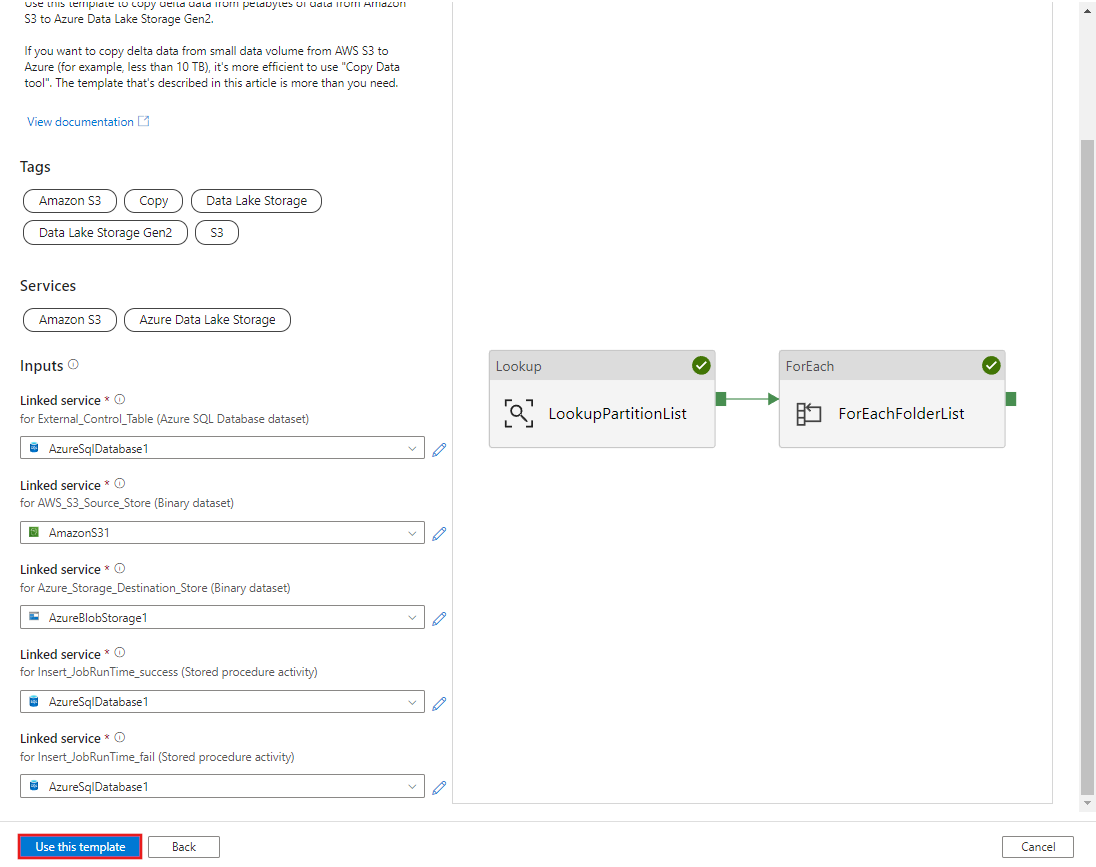
Zobaczysz, że zostały utworzone 2 potoki i 3 zestawy danych, jak pokazano w poniższym przykładzie:
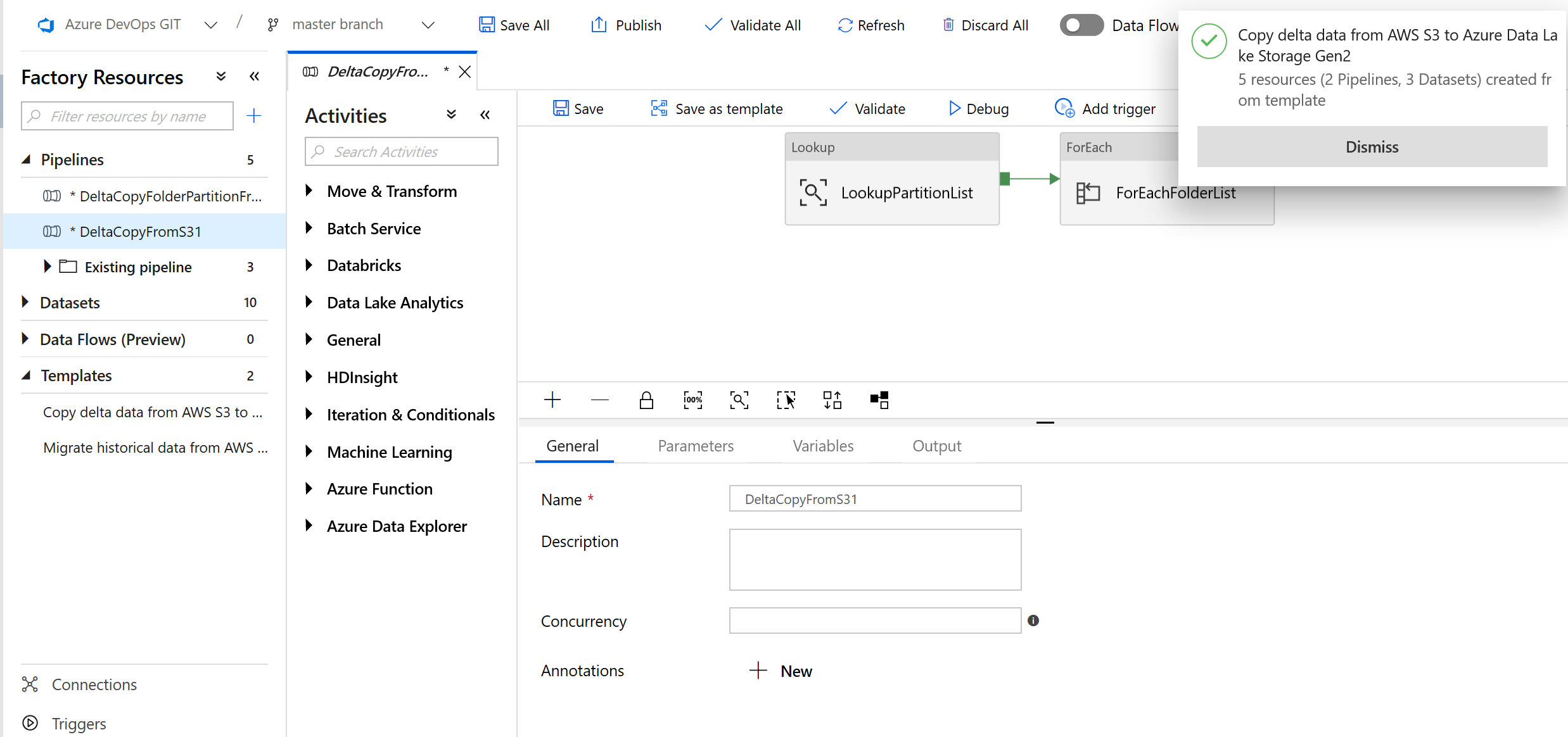
Przejdź do potoku "DeltaCopyFromS3" i wybierz pozycję Debuguj, a następnie wprowadź parametry. Następnie wybierz pozycję Zakończ.
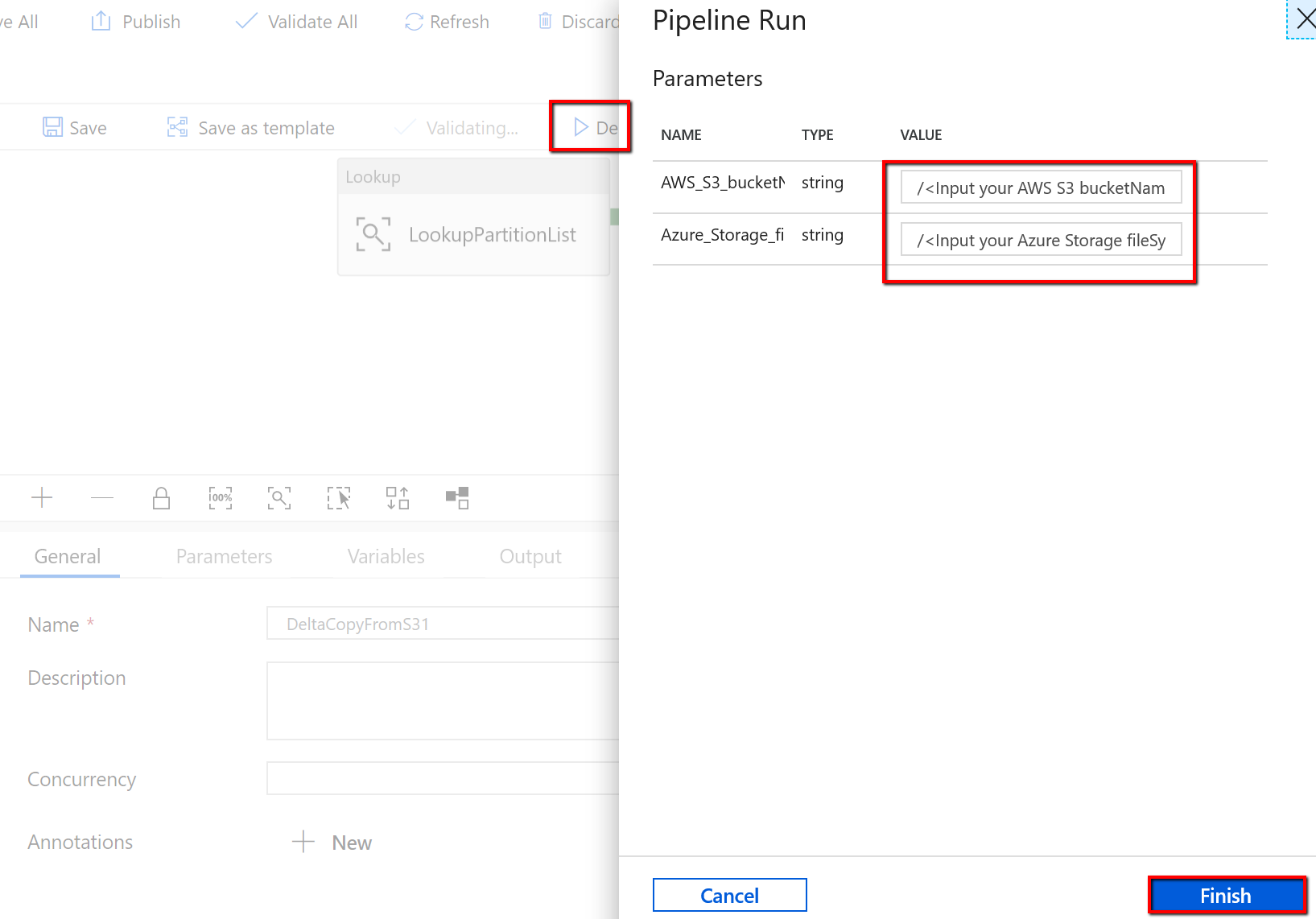
Zostaną wyświetlone wyniki podobne do następującego przykładu:
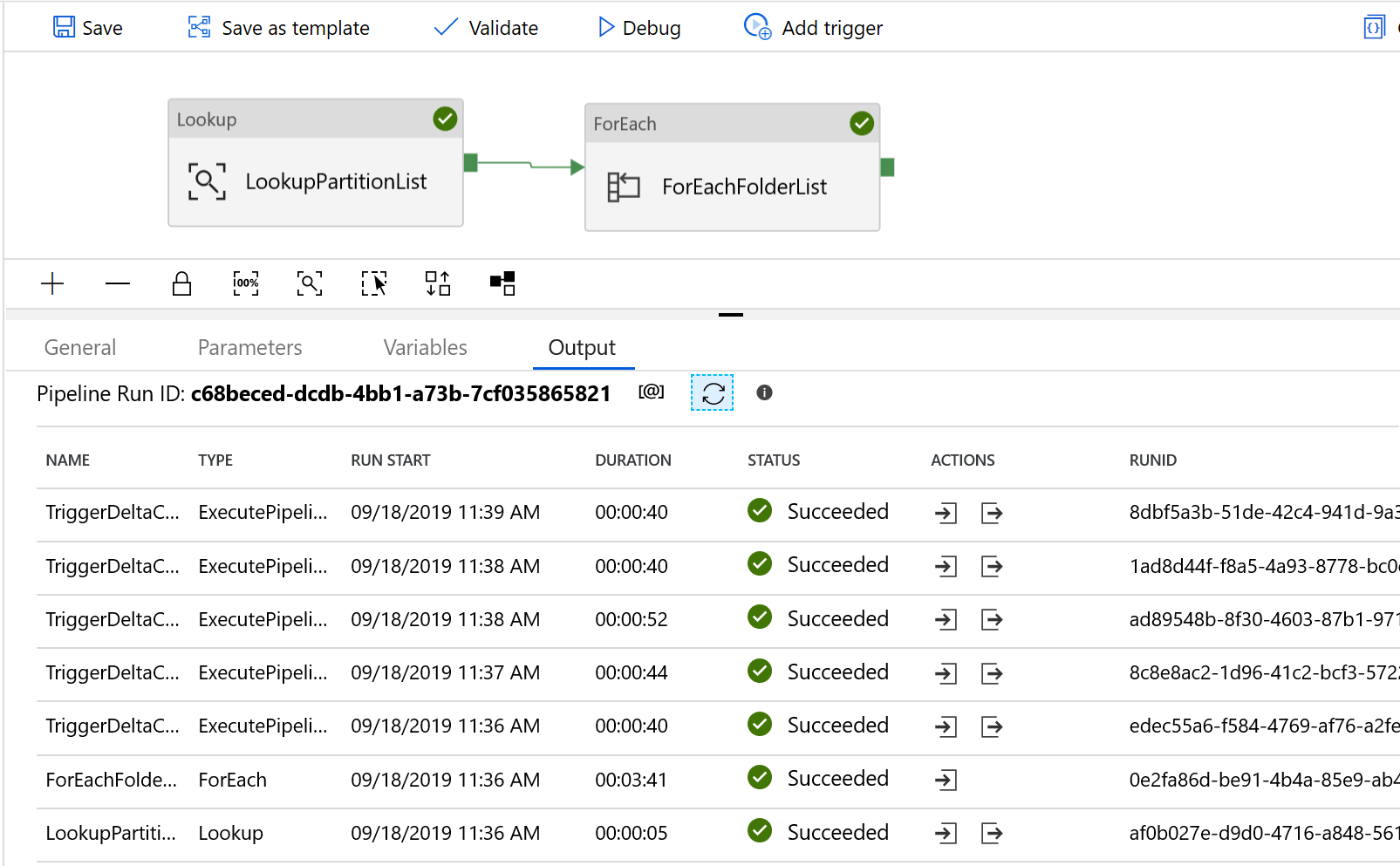
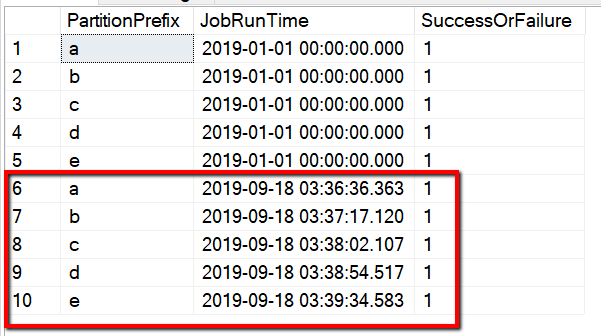
Możesz również sprawdzić wyniki z tabeli kontrolnej, wykonując zapytanie "select * from s3_partition_delta_control_table", zobaczysz dane wyjściowe podobne do poniższego przykładu: