Starsza wersja obsługi modeli MLflow w usłudze Azure Databricks
Ważne
Ta funkcja jest dostępna w publicznej wersji zapoznawczej.
Ważne
- Ta dokumentacja została wycofana i może nie zostać zaktualizowana. Produkty, usługi lub technologie wymienione w tej zawartości nie są już obsługiwane.
- Wskazówki zawarte w tym artykule dotyczą obsługi starszych modeli MLflow. Usługa Databricks zaleca migrowanie przepływów pracy obsługujących przepływy pracy do usługi Model Serving w celu zapewnienia rozszerzonego wdrożenia i skalowalności punktu końcowego modelu. Aby uzyskać więcej informacji, zobacz Obsługa modelu w usłudze Azure Databricks.
Starsza wersja usługi MLflow Model Serving umożliwia hostowanie modeli uczenia maszynowego z rejestru modeli jako punktów końcowych REST, które są aktualizowane automatycznie na podstawie dostępności wersji modelu i ich etapów. Używa on klastra z jednym węzłem, który działa na własnym koncie w ramach tego, co jest teraz nazywane klasyczną płaszczyzną obliczeniową. Ta płaszczyzna obliczeniowa obejmuje sieć wirtualną i skojarzone z nią zasoby obliczeniowe, takie jak klastry dla notesów i zadań, pro i klasyczne magazyny SQL oraz starsze modele obsługujące punkty końcowe.
Po włączeniu obsługi modelu dla danego zarejestrowanego modelu usługa Azure Databricks automatycznie tworzy unikatowy klaster dla modelu i wdraża wszystkie niezarchiwizowane wersje modelu w tym klastrze. Usługa Azure Databricks ponownie uruchamia klaster, jeśli wystąpi błąd i zakończy działanie klastra po wyłączeniu obsługi modelu. Obsługa modelu automatycznie synchronizuje się z rejestrem modeli i wdraża wszystkie nowe zarejestrowane wersje modelu. Wdrożone wersje modelu można wysyłać do zapytań przy użyciu standardowego żądania interfejsu API REST. Usługa Azure Databricks uwierzytelnia żądania do modelu przy użyciu standardowego uwierzytelniania.
Chociaż ta usługa jest w wersji zapoznawczej, usługa Databricks zaleca użycie jej do aplikacji o niskiej przepływności i niekrytycznych. Docelowa przepływność to 200 qps, a docelowa dostępność wynosi 99,5%, chociaż żadna gwarancja nie jest gwarantowana. Ponadto istnieje limit rozmiaru ładunku wynoszący 16 MB na żądanie.
Każda wersja modelu jest wdrażana przy użyciu wdrożenia modelu MLflow i działa w środowisku Conda określonym przez jego zależności.
Uwaga
- Klaster jest utrzymywany tak długo, jak jest włączona, nawet jeśli nie istnieje aktywna wersja modelu. Aby zakończyć działanie klastra obsługującego, wyłącz obsługę modelu dla zarejestrowanego modelu.
- Klaster jest uważany za klaster all-purpose, z zastrzeżeniem cennika obciążenia ogólnego przeznaczenia.
- Globalne skrypty inicjowania nie są uruchamiane w klastrach obsługujących model.
Ważne
Anaconda Inc. zaktualizowała swoje warunki świadczenia usług dla kanałów anaconda.org. Na podstawie nowych warunków świadczenia usług możesz wymagać licencji komercyjnej, jeśli korzystasz z opakowania i dystrybucji anaconda. Aby uzyskać więcej informacji, zobacz Często zadawane pytania dotyczące wersji komercyjnej Anaconda. Korzystanie z jakichkolwiek kanałów Anaconda podlega warunkom świadczenia usług.
Modele MLflow zarejestrowane przed wersją 1.18 (Databricks Runtime 8.3 ML lub starsze) były domyślnie rejestrowane przy użyciu kanału Conda defaults (https://repo.anaconda.com/pkgs/) jako zależności. Ze względu na tę zmianę licencji usługa Databricks zatrzymała korzystanie z kanału defaults dla modeli zarejestrowanych przy użyciu platformy MLflow w wersji 1.18 lub nowszej. Zarejestrowany kanał domyślny to teraz conda-forge, co wskazuje na zarządzaną https://conda-forge.org/przez społeczność.
Jeśli zarejestrowano model przed MLflow w wersji 1.18 bez wykluczania defaults kanału ze środowiska conda dla modelu, ten model może mieć zależność od kanału defaults , którego być może nie zamierzasz.
Aby ręcznie potwierdzić, czy model ma tę zależność, możesz sprawdzić channel wartość w conda.yaml pliku spakowanym przy użyciu zarejestrowanego modelu. Na przykład model conda.yaml z zależnością kanału defaults może wyglądać następująco:
channels:
- defaults
dependencies:
- python=3.8.8
- pip
- pip:
- mlflow
- scikit-learn==0.23.2
- cloudpickle==1.6.0
name: mlflow-env
Ponieważ usługa Databricks nie może określić, czy korzystanie z repozytorium Anaconda do interakcji z modelami jest dozwolone w ramach relacji z platformą Anaconda, usługa Databricks nie zmusza swoich klientów do wprowadzania żadnych zmian. Jeśli korzystanie z repozytorium Anaconda.com za pośrednictwem korzystania z usługi Databricks jest dozwolone zgodnie z warunkami platformy Anaconda, nie musisz podejmować żadnych działań.
Jeśli chcesz zmienić kanał używany w środowisku modelu, możesz ponownie zarejestrować model w rejestrze modeli przy użyciu nowego conda.yamlelementu . Można to zrobić, określając kanał w parametrze conda_envlog_model().
Aby uzyskać więcej informacji na temat interfejsu log_model() API, zobacz dokumentację platformy MLflow dotyczącą odmiany modelu, z którą pracujesz, na przykład log_model dla biblioteki scikit-learn.
Aby uzyskać więcej informacji na conda.yaml temat plików, zobacz dokumentację platformy MLflow.
Wymagania
- Starsza wersja usługi MLflow Model Serving jest dostępna dla modeli języka Python MLflow. Należy zadeklarować wszystkie zależności modelu w środowisku conda. Zobacz Zależności modelu dzienników.
- Aby włączyć obsługę modelu, musisz mieć uprawnienie do tworzenia klastra.
Obsługa modelu z rejestru modeli
Obsługa modeli jest dostępna w usłudze Azure Databricks z rejestru modeli.
Włączanie i wyłączanie obsługi modelu
Model można włączyć na stronie zarejestrowanego modelu.
Kliknij kartę Obsługa. Jeśli model nie jest jeszcze włączony do obsługi, zostanie wyświetlony przycisk Włącz obsługę.
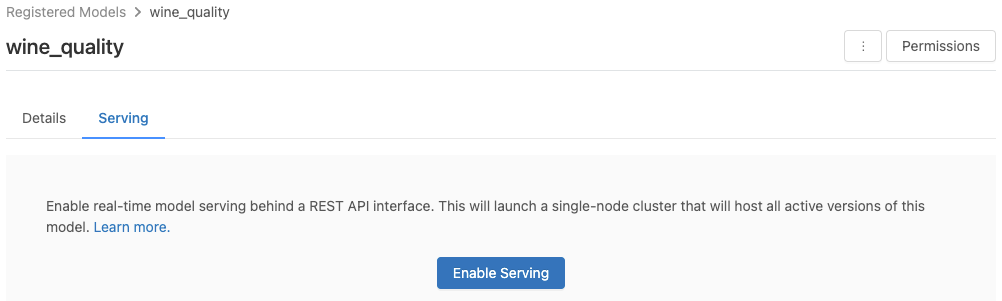
Kliknij pozycję Włącz obsługę. Karta Obsługa zostanie wyświetlona z stanem wyświetlanym jako Oczekujące. Po kilku minutach stan zmieni się na Gotowy.
Aby wyłączyć model obsługi, kliknij przycisk Zatrzymaj.
Weryfikowanie obsługi modelu
Na karcie Obsługa możesz wysłać żądanie do obsługiwanego modelu i wyświetlić odpowiedź.
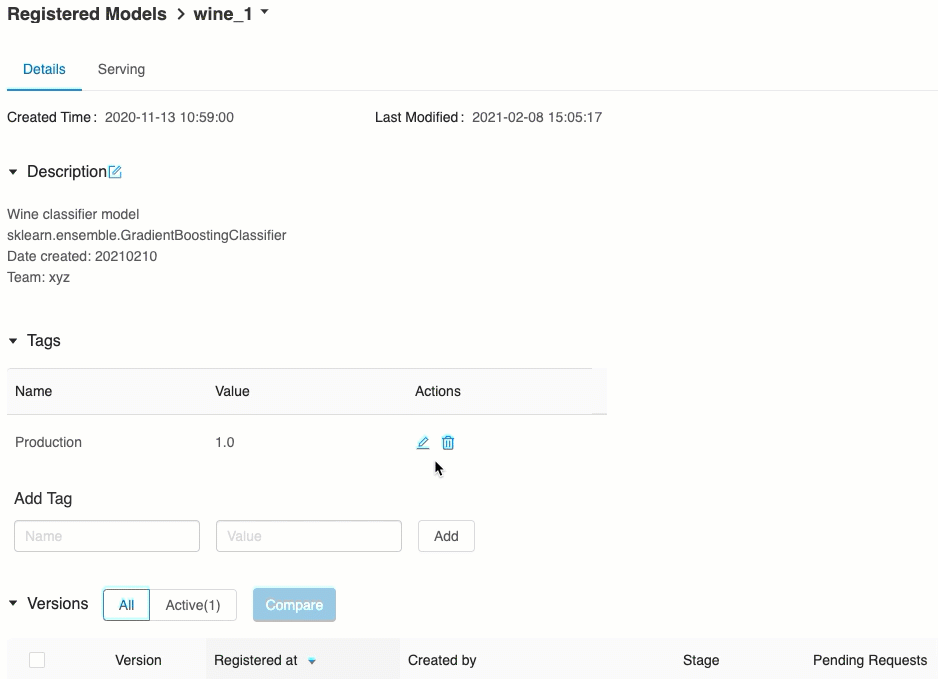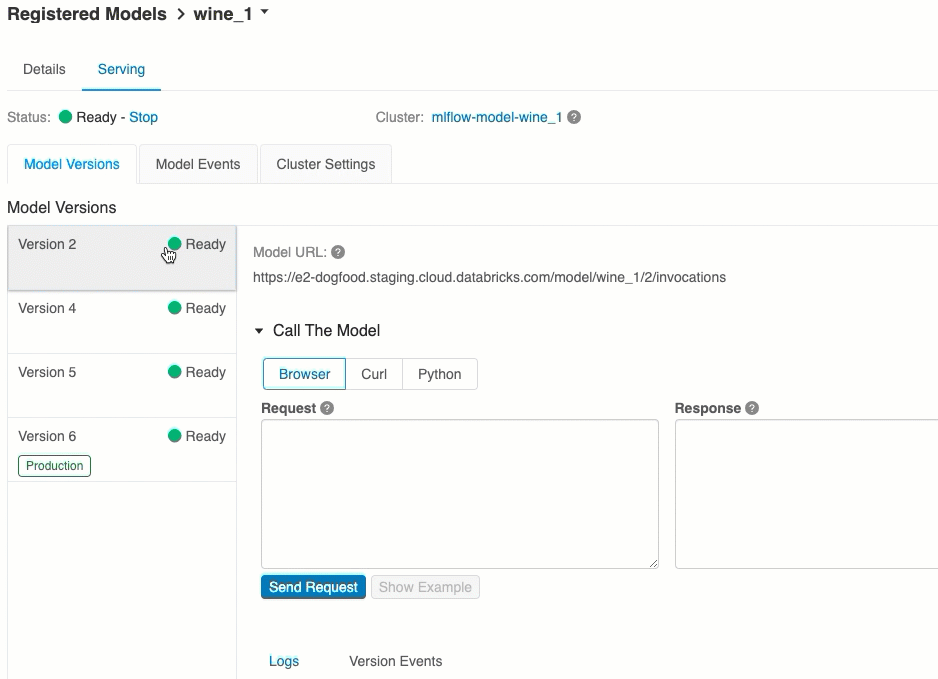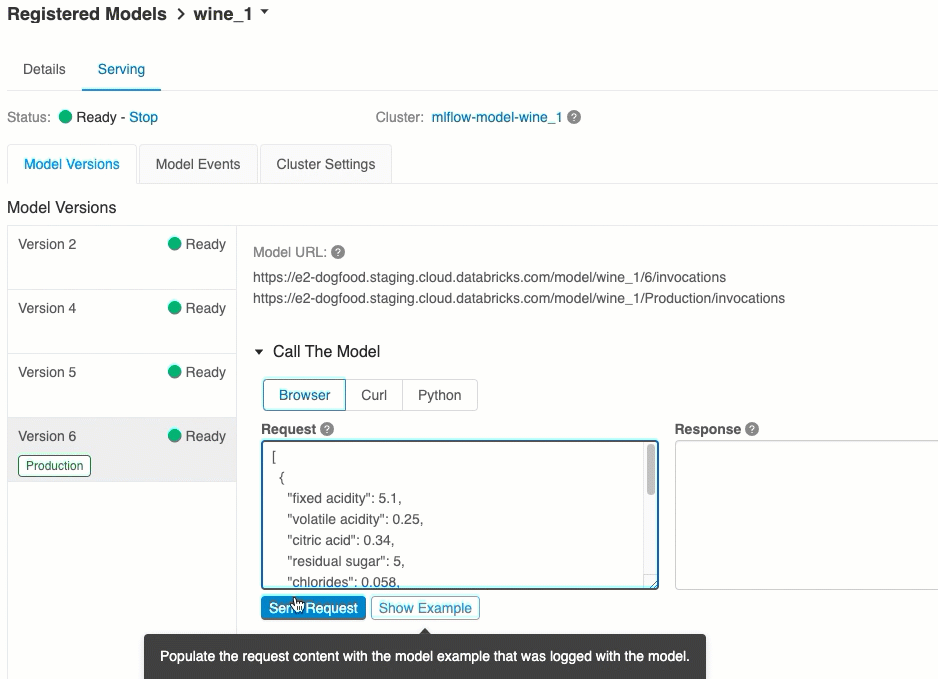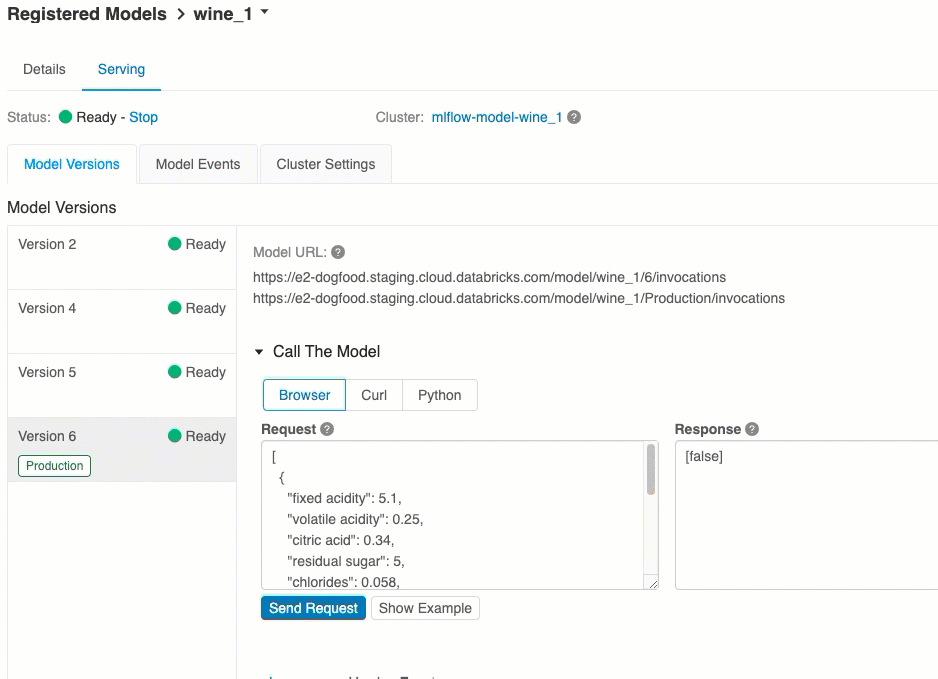
Identyfikatory URI wersji modelu
Każda wdrożona wersja modelu ma przypisany jeden lub kilka unikatowych identyfikatorów URI. Co najmniej każda wersja modelu ma przypisany identyfikator URI skonstruowany w następujący sposób:
<databricks-instance>/model/<registered-model-name>/<model-version>/invocations
Aby na przykład wywołać wersję 1 modelu zarejestrowanego jako iris-classifier, użyj tego identyfikatora URI:
https://<databricks-instance>/model/iris-classifier/1/invocations
Możesz również wywołać wersję modelu według jej etapu. Jeśli na przykład wersja 1 znajduje się na etapie produkcji , można ją również ocenić przy użyciu tego identyfikatora URI:
https://<databricks-instance>/model/iris-classifier/Production/invocations
Lista dostępnych identyfikatorów URI modelu jest wyświetlana w górnej części karty Wersje modelu na stronie obsługi.
Zarządzanie obsługiwanymi wersjami
Wszystkie aktywne (niezarchiwizowane) wersje modelu są wdrażane i można wykonywać zapytania za pomocą identyfikatorów URI. Usługa Azure Databricks automatycznie wdraża nowe wersje modelu po ich zarejestrowaniu i automatycznie usuwa stare wersje podczas ich archiwizowania.
Uwaga
Wszystkie wdrożone wersje zarejestrowanego modelu współużytkuje ten sam klaster.
Zarządzanie prawami dostępu do modelu
Prawa dostępu do modelu są dziedziczone z rejestru modeli. Włączenie lub wyłączenie funkcji obsługującej wymaga uprawnienia "zarządzaj" dla zarejestrowanego modelu. Każda osoba z prawami do odczytu może ocenić dowolną wdrożonych wersji.
Ocenianie wdrożonych wersji modelu
Aby ocenić wdrożony model, możesz użyć interfejsu użytkownika lub wysłać żądanie interfejsu API REST do identyfikatora URI modelu.
Generowanie wyników za pośrednictwem interfejsu użytkownika
Jest to najprostszy i najszybszy sposób testowania modelu. Możesz wstawić dane wejściowe modelu w formacie JSON i kliknąć pozycję Wyślij żądanie. Jeśli model został zarejestrowany przy użyciu przykładu danych wejściowych (jak pokazano na powyższej ilustracji), kliknij pozycję Załaduj przykład , aby załadować przykład danych wejściowych.
Generowanie wyników za pośrednictwem żądania interfejsu API REST
Żądanie oceniania można wysłać za pośrednictwem interfejsu API REST przy użyciu standardowego uwierzytelniania usługi Databricks. W poniższych przykładach pokazano uwierzytelnianie przy użyciu osobistego tokenu dostępu z platformą MLflow 1.x.
Uwaga
Najlepszym rozwiązaniem w zakresie zabezpieczeń w przypadku uwierzytelniania za pomocą zautomatyzowanych narzędzi, systemów, skryptów i aplikacji usługa Databricks zaleca używanie osobistych tokenów dostępu należących do jednostek usługi zamiast użytkowników obszaru roboczego. Aby utworzyć tokeny dla jednostek usługi, zobacz Zarządzanie tokenami dla jednostki usługi.
MODEL_VERSION_URIhttps://<databricks-instance>/model/iris-classifier/Production/invocations Na przykład (gdzie <databricks-instance> jest nazwą wystąpienia usługi Databricks) i tokenem interfejsu API REST usługi Databricks o nazwie DATABRICKS_API_TOKEN, w poniższych przykładach pokazano, jak wykonywać zapytania dotyczące obsługiwanego modelu:
Poniższe przykłady odzwierciedlają format oceniania modeli utworzonych za pomocą biblioteki MLflow 1.x. Jeśli wolisz używać biblioteki MLflow 2.0, musisz zaktualizować format ładunku żądania.
Bash
Fragment kodu umożliwiający wykonywanie zapytań dotyczących modelu akceptującego dane wejściowe ramki danych.
curl -X POST -u token:$DATABRICKS_API_TOKEN $MODEL_VERSION_URI \
-H 'Content-Type: application/json' \
-d '[
{
"sepal_length": 5.1,
"sepal_width": 3.5,
"petal_length": 1.4,
"petal_width": 0.2
}
]'
Fragment kodu w celu wysyłania zapytań do modelu akceptującego dane wejściowe tensor. Dane wejściowe tensor powinny być sformatowane zgodnie z opisem w dokumentacji interfejsu API usługi TensorFlow.
curl -X POST -u token:$DATABRICKS_API_TOKEN $MODEL_VERSION_URI \
-H 'Content-Type: application/json' \
-d '{"inputs": [[5.1, 3.5, 1.4, 0.2]]}'
Python
import numpy as np
import pandas as pd
import requests
def create_tf_serving_json(data):
return {'inputs': {name: data[name].tolist() for name in data.keys()} if isinstance(data, dict) else data.tolist()}
def score_model(model_uri, databricks_token, data):
headers = {
"Authorization": f"Bearer {databricks_token}",
"Content-Type": "application/json",
}
data_json = data.to_dict(orient='records') if isinstance(data, pd.DataFrame) else create_tf_serving_json(data)
response = requests.request(method='POST', headers=headers, url=model_uri, json=data_json)
if response.status_code != 200:
raise Exception(f"Request failed with status {response.status_code}, {response.text}")
return response.json()
# Scoring a model that accepts pandas DataFrames
data = pd.DataFrame([{
"sepal_length": 5.1,
"sepal_width": 3.5,
"petal_length": 1.4,
"petal_width": 0.2
}])
score_model(MODEL_VERSION_URI, DATABRICKS_API_TOKEN, data)
# Scoring a model that accepts tensors
data = np.asarray([[5.1, 3.5, 1.4, 0.2]])
score_model(MODEL_VERSION_URI, DATABRICKS_API_TOKEN, data)
Powerbi
Zestaw danych można ocenić w programie Power BI Desktop, wykonując następujące kroki:
Otwórz zestaw danych, który chcesz ocenić.
Przejdź do pozycji Przekształć dane.
Kliknij prawym przyciskiem myszy w panelu po lewej stronie i wybierz pozycję Utwórz nowe zapytanie.
Przejdź do pozycji Wyświetl > Edytor zaawansowany.
Zastąp treść zapytania poniższym fragmentem kodu po wypełnieniu odpowiedniego
DATABRICKS_API_TOKENelementu iMODEL_VERSION_URI.(dataset as table ) as table => let call_predict = (dataset as table ) as list => let apiToken = DATABRICKS_API_TOKEN, modelUri = MODEL_VERSION_URI, responseList = Json.Document(Web.Contents(modelUri, [ Headers = [ #"Content-Type" = "application/json", #"Authorization" = Text.Format("Bearer #{0}", {apiToken}) ], Content = Json.FromValue(dataset) ] )) in responseList, predictionList = List.Combine(List.Transform(Table.Split(dataset, 256), (x) => call_predict(x))), predictionsTable = Table.FromList(predictionList, (x) => {x}, {"Prediction"}), datasetWithPrediction = Table.Join( Table.AddIndexColumn(predictionsTable, "index"), "index", Table.AddIndexColumn(dataset, "index"), "index") in datasetWithPredictionNadaj kwerendzie nazwę żądanego modelu.
Otwórz zaawansowany edytor zapytań dla zestawu danych i zastosuj funkcję modelu.
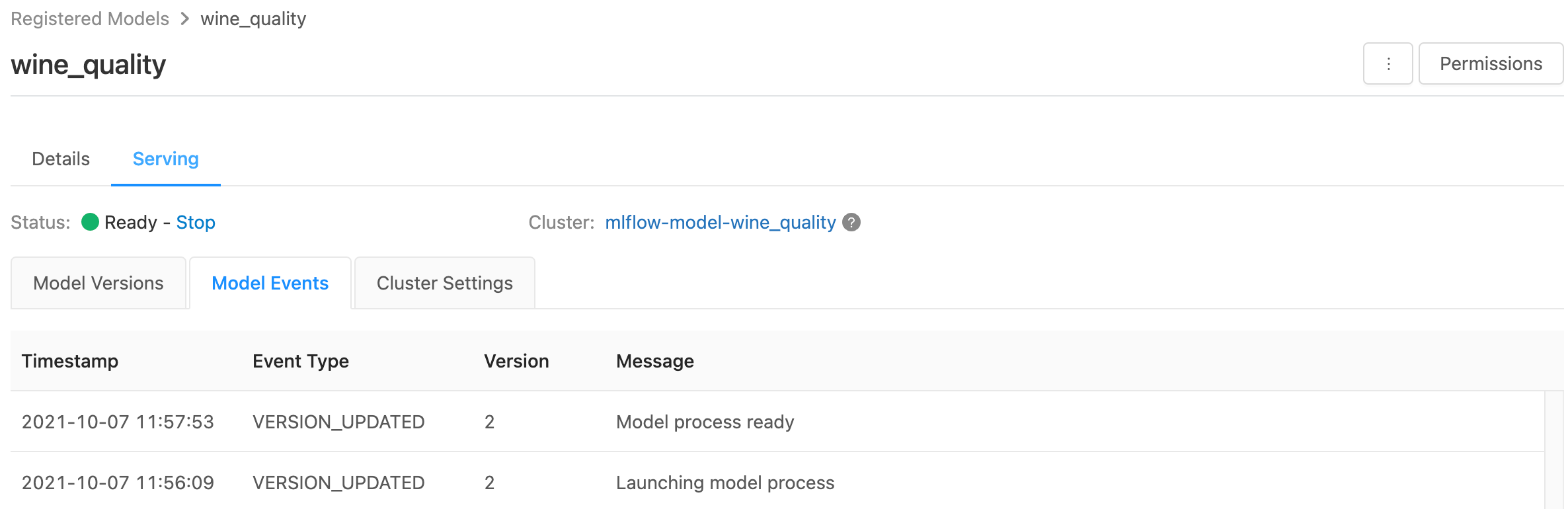
Monitorowanie obsługiwanych modeli
Na stronie obsługującej są wyświetlane wskaźniki stanu dla klastra obsługującego, a także poszczególne wersje modelu.
- Aby sprawdzić stan klastra obsługującego, użyj karty Zdarzenia modelu, która wyświetla listę wszystkich zdarzeń obsługujących dla tego modelu.
- Aby sprawdzić stan pojedynczej wersji modelu, kliknij kartę Wersje modelu i przewiń, aby wyświetlić karty Dzienniki lub Zdarzenia wersji.
Dostosowywanie klastra obsługującego
Aby dostosować klaster obsługujący, użyj karty Klaster Ustawienia na karcie Obsługa .
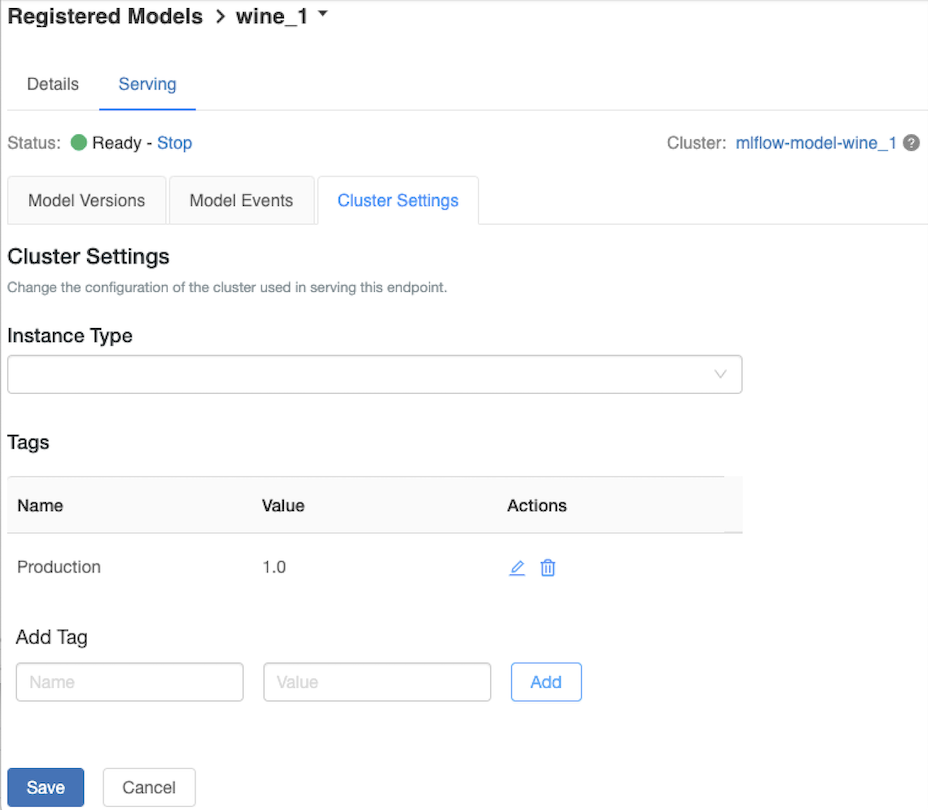
- Aby zmodyfikować rozmiar pamięci i liczbę rdzeni klastra obsługującego, użyj menu rozwijanego Typ wystąpienia, aby wybrać żądaną konfigurację klastra. Po kliknięciu przycisku Zapisz istniejący klaster zostanie zakończony i zostanie utworzony nowy klaster z określonymi ustawieniami.
- Aby dodać tag, wpisz nazwę i wartość w polach Dodaj tag , a następnie kliknij przycisk Dodaj.
- Aby edytować lub usunąć istniejący tag, kliknij jedną z ikon w kolumnie Akcje tabeli Tagi.
Integracja magazynu funkcji
Obsługa starszych modeli może automatycznie wyszukać wartości funkcji z opublikowanych sklepów online.
.. Aws:
Databricks Legacy MLflow Model Serving supports automatic feature lookup from these online stores:
- Amazon DynamoDB (v0.3.8 and above)
- Amazon Aurora (MySQL-compatible)
- Amazon RDS MySQL
.. azure::
Databricks Legacy MLflow Model Serving supports automatic feature lookup from these online stores:
- Azure Cosmos DB (v0.5.0 and above)
- Azure Database for MySQL
Znane błędy
ResolvePackageNotFound: pyspark=3.1.0
Ten błąd może wystąpić, jeśli model zależy od pyspark modelu i jest rejestrowany przy użyciu środowiska Databricks Runtime 8.x.
Jeśli ten błąd zostanie wyświetlony, określ pyspark wersję jawnie podczas rejestrowania modelu przy użyciu parametru conda_env.
Unrecognized content type parameters: format
Ten błąd może wystąpić w wyniku nowego formatu protokołu oceniania MLflow 2.0. Jeśli widzisz ten błąd, prawdopodobnie używasz nieaktualnego formatu żądania oceniania. Aby rozwiązać ten problem, możesz wykonać następujące czynności:
Zaktualizuj format żądania oceniania do najnowszego protokołu.
Uwaga
W poniższych przykładach przedstawiono format oceniania wprowadzony w rozwiązaniu MLflow 2.0. Jeśli wolisz używać biblioteki MLflow 1.x, możesz zmodyfikować
log_model()wywołania interfejsu API, aby uwzględnić żądaną zależność wersji biblioteki MLflow w parametrzeextra_pip_requirements. Zapewnia to zastosowanie odpowiedniego formatu oceniania.mlflow.<flavor>.log_model(..., extra_pip_requirements=["mlflow==1.*"])Bash
Wykonywanie zapytań względem modelu akceptującego dane wejściowe ramki danych pandas.
curl -X POST -u token:$DATABRICKS_API_TOKEN $MODEL_VERSION_URI \ -H 'Content-Type: application/json' \ -d '{ "dataframe_records": [{"sepal_length (cm)": 5.1, "sepal_width (cm)": 3.5, "petal_length (cm)": 1.4, "petal_width": 0.2}, {"sepal_length (cm)": 4.2, "sepal_width (cm)": 5.0, "petal_length (cm)": 0.8, "petal_width": 0.5}] }'Wykonywanie zapytań względem modelu akceptującego dane wejściowe tensor. Dane wejściowe tensor powinny być sformatowane zgodnie z opisem w dokumentacji interfejsu API usługi TensorFlow.
curl -X POST -u token:$DATABRICKS_API_TOKEN $MODEL_VERSION_URI \ -H 'Content-Type: application/json' \ -d '{"inputs": [[5.1, 3.5, 1.4, 0.2]]}'Python
import numpy as np import pandas as pd import requests def create_tf_serving_json(data): return {'inputs': {name: data[name].tolist() for name in data.keys()} if isinstance(data, dict) else data.tolist()} def score_model(model_uri, databricks_token, data): headers = { "Authorization": f"Bearer {databricks_token}", "Content-Type": "application/json", } data_dict = {'dataframe_split': data.to_dict(orient='split')} if isinstance(data, pd.DataFrame) else create_tf_serving_json(data) data_json = json.dumps(data_dict) response = requests.request(method='POST', headers=headers, url=model_uri, json=data_json) if response.status_code != 200: raise Exception(f"Request failed with status {response.status_code}, {response.text}") return response.json() # Scoring a model that accepts pandas DataFrames data = pd.DataFrame([{ "sepal_length": 5.1, "sepal_width": 3.5, "petal_length": 1.4, "petal_width": 0.2 }]) score_model(MODEL_VERSION_URI, DATABRICKS_API_TOKEN, data) # Scoring a model that accepts tensors data = np.asarray([[5.1, 3.5, 1.4, 0.2]]) score_model(MODEL_VERSION_URI, DATABRICKS_API_TOKEN, data)Powerbi
Zestaw danych można ocenić w programie Power BI Desktop, wykonując następujące kroki:
Otwórz zestaw danych, który chcesz ocenić.
Przejdź do pozycji Przekształć dane.
Kliknij prawym przyciskiem myszy w panelu po lewej stronie i wybierz pozycję Utwórz nowe zapytanie.
Przejdź do pozycji Wyświetl > Edytor zaawansowany.
Zastąp treść zapytania poniższym fragmentem kodu po wypełnieniu odpowiedniego
DATABRICKS_API_TOKENelementu iMODEL_VERSION_URI.(dataset as table ) as table => let call_predict = (dataset as table ) as list => let apiToken = DATABRICKS_API_TOKEN, modelUri = MODEL_VERSION_URI, responseList = Json.Document(Web.Contents(modelUri, [ Headers = [ #"Content-Type" = "application/json", #"Authorization" = Text.Format("Bearer #{0}", {apiToken}) ], Content = Json.FromValue(dataset) ] )) in responseList, predictionList = List.Combine(List.Transform(Table.Split(dataset, 256), (x) => call_predict(x))), predictionsTable = Table.FromList(predictionList, (x) => {x}, {"Prediction"}), datasetWithPrediction = Table.Join( Table.AddIndexColumn(predictionsTable, "index"), "index", Table.AddIndexColumn(dataset, "index"), "index") in datasetWithPredictionNadaj kwerendzie nazwę żądanego modelu.
Otwórz zaawansowany edytor zapytań dla zestawu danych i zastosuj funkcję modelu.
Jeśli żądanie oceniania używa klienta MLflow, takiego jak
mlflow.pyfunc.spark_udf(), uaktualnij klienta MLflow do wersji 2.0 lub nowszej, aby użyć najnowszego formatu. Dowiedz się więcej o zaktualizowanym protokole oceniania modelu MLflow w usłudze MLflow 2.0.
Aby uzyskać więcej informacji na temat formatów danych wejściowych akceptowanych przez serwer (na przykład format podzielony zorientowany na bibliotekę pandas), zobacz dokumentację platformy MLflow.
Opinia
Dostępne już wkrótce: W 2024 r. będziemy stopniowo wycofywać zgłoszenia z serwisu GitHub jako mechanizm przesyłania opinii na temat zawartości i zastępować go nowym systemem opinii. Aby uzyskać więcej informacji, sprawdź: https://aka.ms/ContentUserFeedback.
Prześlij i wyświetl opinię dla