Usługa Azure HDInsight — przyspieszone zapisy dla oprogramowania Apache HBase
Ten artykuł zawiera podstawowe informacje na temat funkcji przyspieszonych zapisów dla bazy danych Apache HBase w usłudze Azure HDInsight oraz sposobu jej efektywnego użycia w celu zwiększenia wydajności zapisu. Przyspieszone zapisy używają dysków zarządzanych SSD w warstwie Azure w warstwie Premium w celu zwiększenia wydajności dziennika zapisu bazy danych Apache HBase (WAL). Aby dowiedzieć się więcej na temat bazy danych Apache HBase, zobacz Co to jest baza danych Apache HBase w usłudze HDInsight.
Omówienie architektury bazy danych HBase
W bazie danych HBase wiersz składa się z co najmniej jednej kolumny i jest identyfikowany przez klucz wiersza. Wiele wierszy składa się z tabeli. Kolumny zawierają komórki, które są sygnaturami czasowymi wartości w tej kolumnie. Kolumny są grupowane w rodziny kolumn, a wszystkie kolumny w rodzinie kolumn są przechowywane razem w plikach magazynu o nazwie HFiles.
Regiony w bazie HBase służą do równoważenia obciążenia przetwarzania danych. Baza HBase najpierw przechowuje wiersze tabeli w jednym regionie. Wiersze są rozłożone w wielu regionach w miarę wzrostu ilości danych w tabeli. Serwery regionów mogą obsługiwać żądania dla wielu regionów.
Zapisywanie dziennika z wyprzedzeniem dla bazy danych Apache HBase
Baza HBase najpierw zapisuje aktualizacje danych do typu dziennika zatwierdzeń o nazwie Write Ahead Log (WAL). Po zapisaniu aktualizacji w pliku WAL jest zapisywana w magazynie MemStore w pamięci. Gdy dane w pamięci osiągną maksymalną pojemność, są zapisywane na dysku jako HFile.
Jeśli maszyna wirtualna RegionServer ulegnie awarii lub stanie się niedostępna przed opróżnieniu magazynu MemStore, można użyć dziennika write Ahead do ponownego odtwarzania aktualizacji. Bez pliku WAL, jeśli maszyna wirtualna RegionServer ulegnie awarii przed opróżnienie aktualizacji do HFileelementu , wszystkie te aktualizacje zostaną utracone.
Funkcja przyspieszonych zapisów w usłudze Azure HDInsight dla bazy danych Apache HBase
Funkcja przyspieszonych zapisów rozwiązuje problem z wyższymi opóźnieniami zapisu spowodowanymi użyciem dzienników zapisu z wyprzedzeniem, które znajdują się w magazynie w chmurze. Funkcja przyspieszonych zapisów dla klastrów Apache HBase usługi HDInsight dołącza dyski zarządzane SSD w warstwie Premium do każdego serwera regionserver (węzła roboczego). Dzienniki zapisu z wyprzedzeniem są następnie zapisywane w systemie plików Hadoop (HDFS) zainstalowanym na tych dyskach zarządzanych w warstwie Premium zamiast w magazynie w chmurze. Dyski zarządzane w warstwie Premium korzystają z dysków półprzewodnikowych (SSD) i oferują doskonałą wydajność operacji we/wy z odpornością na uszkodzenia. W przeciwieństwie do dysków niezarządzanych, jeśli jedna jednostka magazynu ulegnie awarii, nie wpłynie to na inne jednostki magazynu w tym samym zestawie dostępności. W związku z tym dyski zarządzane zapewniają małe opóźnienia zapisu i lepszą odporność aplikacji. Aby dowiedzieć się więcej na temat dysków zarządzanych platformy Azure, zobacz Wprowadzenie do dysków zarządzanych platformy Azure.
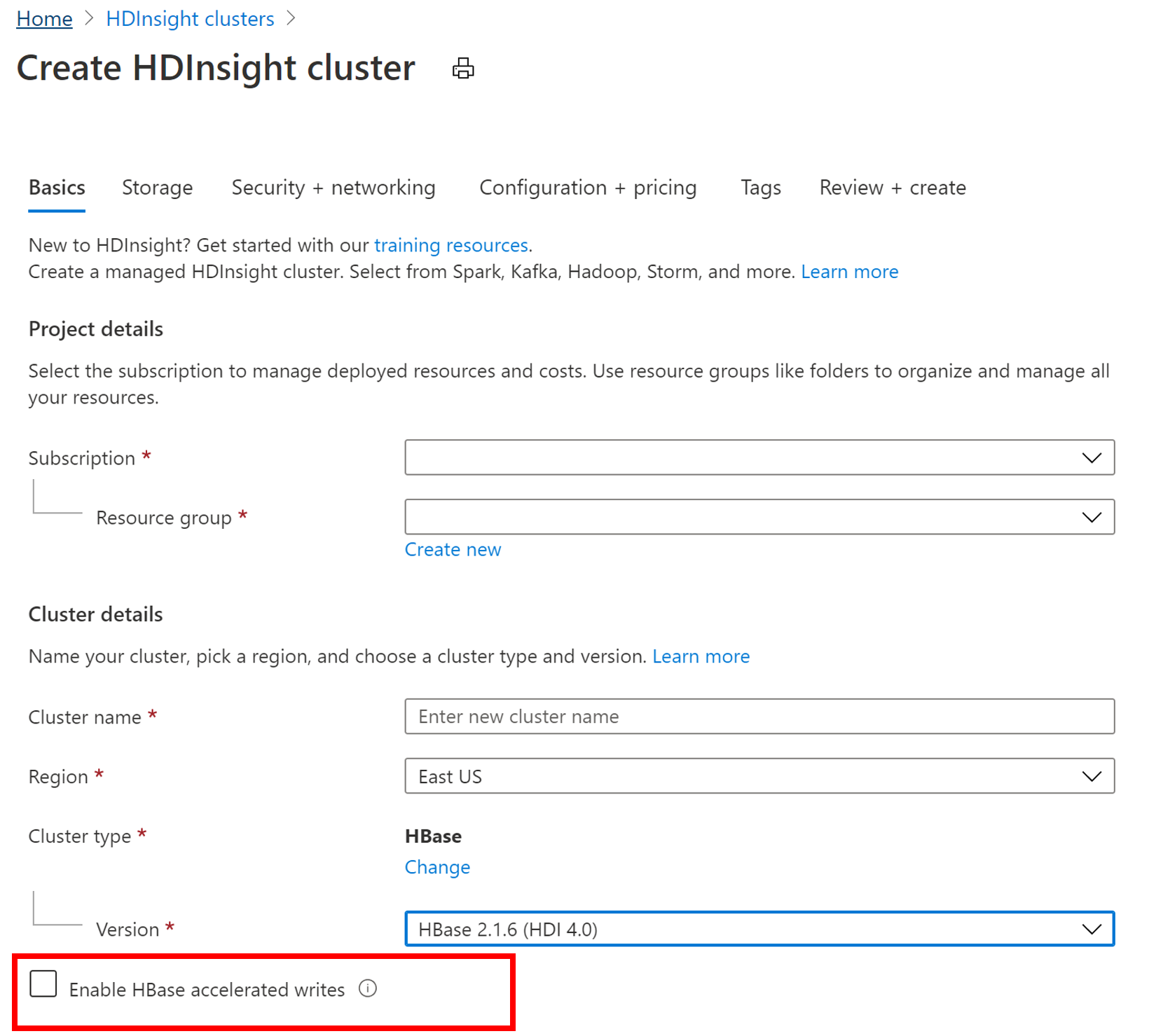
Jak włączyć przyspieszone zapisy dla bazy danych HBase w usłudze HDInsight
Aby utworzyć nowy klaster HBase z funkcją Przyspieszone zapisy, wykonaj kroki opisane w temacie Konfigurowanie klastrów w usłudze HDInsight. Na karcie Podstawy wybierz typ klastra jako HBase, określ wersję składnika, a następnie kliknij pole wyboru obok pozycji Włącz przyspieszone zapisy bazy danych HBase. Następnie przejdź do pozostałych kroków tworzenia klastra.
Sprawdź, czy włączono funkcję przyspieszonych zapisów
Możesz użyć witryny Azure Portal, aby sprawdzić, czy funkcja przyspieszonych zapisów jest włączona w klastrze HBASE.
- Wyszukaj klaster HBASE w witrynie Azure Portal.
- Wybierz blok Rozmiar klastra.
- Zostaną wyświetlone dyski w warstwie Premium na węzeł roboczy.
Skalowanie klastrów HBASE
Aby zachować trwałość danych, utwórz klaster z co najmniej trzema węzłami roboczymi. Po utworzeniu klastra nie można skalować w dół do mniej niż trzech węzłów roboczych.
Opróżnij lub wyłącz tabele HBase przed usunięciem klastra, aby nie utracić danych dziennika zapisu z wyprzedzeniem.
flush 'mytable'
disable 'mytable'
Wykonaj podobne kroki podczas skalowania klastra w dół: opróżnij tabele i wyłącz tabele, aby zatrzymać dane przychodzące. Nie można skalować klastra w dół do mniej niż trzech węzłów.
Wykonanie tych kroków zapewni pomyślne skalowanie w dół i zapobiegnie możliwości przejścia węzła nazw w tryb awaryjny z powodu niezreplikowanych lub tymczasowych plików.
Jeśli węzeł namenode przechodzi w tryb awaryjny po skalowaniu w dół, użyj poleceń hdfs, aby ponownie replikować podreplikowane bloki i wyprowadzić hdfs z trybu bezpiecznego. Ta ponowna replikacja umożliwi pomyślne ponowne uruchomienie bazy danych HBase.
Następne kroki
- Oficjalna dokumentacja bazy danych Apache HBase dotycząca funkcji write Ahead Log
- Aby uaktualnić klaster apache HBase usługi HDInsight do korzystania z przyspieszonych zapisów, zobacz Migrowanie klastra Apache HBase do nowej wersji.