Rozwiązywanie problemów z systemem HDFS usługi Apache Hadoop za pomocą usługi Azure HDInsight
Poznaj najważniejsze problemy i sposoby ich rozwiązania podczas pracy z rozproszonym systemem plików Hadoop (HDFS). Aby uzyskać pełną listę poleceń, zobacz Przewodnik po poleceniach systemu plików HDFS i Przewodnik powłoki systemu plików.
Jak mogę uzyskać dostęp do lokalnego systemu plików HDFS z poziomu klastra?
Problem
Uzyskaj dostęp do lokalnego systemu plików HDFS z poziomu wiersza polecenia i kodu aplikacji zamiast przy użyciu usługi Azure Blob Storage lub Azure Data Lake Storage z poziomu klastra usługi HDInsight.
Kroki umożliwiające rozwiązanie problemów
W wierszu polecenia użyj
hdfs dfs -D "fs.default.name=hdfs://mycluster/" ...dosłownie, jak w poniższym poleceniu:hdfs dfs -D "fs.default.name=hdfs://mycluster/" -ls / Found 3 items drwxr-xr-x - hdiuser hdfs 0 2017-03-24 14:12 /EventCheckpoint-30-8-24-11102016-01 drwx-wx-wx - hive hdfs 0 2016-11-10 18:42 /tmp drwx------ - hdiuser hdfs 0 2016-11-10 22:22 /userZ kodu źródłowego użyj identyfikatora URI
hdfs://mycluster/dosłownie, jak w następującej przykładowej aplikacji:import java.io.IOException; import java.net.URI; import org.apache.commons.io.IOUtils; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.*; public class JavaUnitTests { public static void main(String[] args) throws Exception { Configuration conf = new Configuration(); String hdfsUri = "hdfs://mycluster/"; conf.set("fs.defaultFS", hdfsUri); FileSystem fileSystem = FileSystem.get(URI.create(hdfsUri), conf); RemoteIterator<LocatedFileStatus> fileStatusIterator = fileSystem.listFiles(new Path("/tmp"), true); while(fileStatusIterator.hasNext()) { System.out.println(fileStatusIterator.next().getPath().toString()); } } }Uruchom skompilowany plik .jar (na przykład plik o nazwie
java-unit-tests-1.0.jar) w klastrze usługi HDInsight za pomocą następującego polecenia:hadoop jar java-unit-tests-1.0.jar JavaUnitTests hdfs://mycluster/tmp/hive/hive/5d9cf301-2503-48c7-9963-923fb5ef79a7/inuse.info hdfs://mycluster/tmp/hive/hive/5d9cf301-2503-48c7-9963-923fb5ef79a7/inuse.lck hdfs://mycluster/tmp/hive/hive/a0be04ea-ae01-4cc4-b56d-f263baf2e314/inuse.info hdfs://mycluster/tmp/hive/hive/a0be04ea-ae01-4cc4-b56d-f263baf2e314/inuse.lck
Wyjątek magazynu dla zapisu w obiekcie blob
Problem
W przypadku używania hadoop poleceń lub hdfs dfs do zapisywania plików o rozmiarze ok. 12 GB lub większym w klastrze HBase może wystąpić następujący błąd:
ERROR azure.NativeAzureFileSystem: Encountered Storage Exception for write on Blob : example/test_large_file.bin._COPYING_ Exception details: null Error Code : RequestBodyTooLarge
copyFromLocal: java.io.IOException
at com.microsoft.azure.storage.core.Utility.initIOException(Utility.java:661)
at com.microsoft.azure.storage.blob.BlobOutputStream$1.call(BlobOutputStream.java:366)
at com.microsoft.azure.storage.blob.BlobOutputStream$1.call(BlobOutputStream.java:350)
at java.util.concurrent.FutureTask.run(FutureTask.java:262)
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:471)
at java.util.concurrent.FutureTask.run(FutureTask.java:262)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1145)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:615)
at java.lang.Thread.run(Thread.java:745)
Caused by: com.microsoft.azure.storage.StorageException: The request body is too large and exceeds the maximum permissible limit.
at com.microsoft.azure.storage.StorageException.translateException(StorageException.java:89)
at com.microsoft.azure.storage.core.StorageRequest.materializeException(StorageRequest.java:307)
at com.microsoft.azure.storage.core.ExecutionEngine.executeWithRetry(ExecutionEngine.java:182)
at com.microsoft.azure.storage.blob.CloudBlockBlob.uploadBlockInternal(CloudBlockBlob.java:816)
at com.microsoft.azure.storage.blob.CloudBlockBlob.uploadBlock(CloudBlockBlob.java:788)
at com.microsoft.azure.storage.blob.BlobOutputStream$1.call(BlobOutputStream.java:354)
... 7 more
Przyczyna
Baza HBase w klastrach usługi HDInsight domyślnie ma rozmiar bloku wynoszący 256 KB podczas zapisywania w usłudze Azure Storage. Mimo że działa on dla interfejsów API bazy danych HBase lub interfejsów API REST, powoduje błąd podczas korzystania z hadoop narzędzi wiersza polecenia lub hdfs dfs .
Rozwiązanie
Użyj fs.azure.write.request.size polecenia , aby określić większy rozmiar bloku. Tę modyfikację można wykonać dla poszczególnych zastosowań przy użyciu parametru -D . Następujące polecenie jest przykładem użycia tego parametru z poleceniem hadoop :
hadoop -fs -D fs.azure.write.request.size=4194304 -copyFromLocal test_large_file.bin /example/data
Możesz również zwiększyć wartość fs.azure.write.request.size globalnie przy użyciu narzędzia Apache Ambari. Następujące kroki mogą służyć do zmiany wartości w internetowym interfejsie użytkownika systemu Ambari:
W przeglądarce przejdź do internetowego interfejsu użytkownika systemu Ambari dla klastra. Adres URL to
https://CLUSTERNAME.azurehdinsight.net, gdzieCLUSTERNAMEto nazwa klastra. Po wyświetleniu monitu wprowadź nazwę administratora i hasło dla klastra.Po lewej stronie ekranu wybierz pozycję HDFS, a następnie wybierz kartę Configs (Konfiguracje ).
W polu Filtr... wprowadź wartość
fs.azure.write.request.size.Zmień wartość z 262144 (256 KB) na nową wartość. Na przykład 4194304 (4 MB).
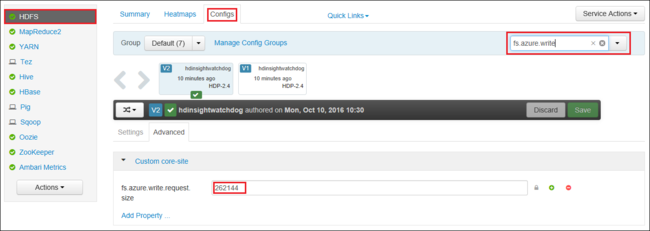
Aby uzyskać więcej informacji na temat korzystania z systemu Ambari, zobacz Manage HDInsight clusters using the Apache Ambari Web UI (Zarządzanie klastrami usługi HDInsight przy użyciu internetowego interfejsu użytkownika platformy Apache Ambari).
Du
Polecenie -du wyświetla rozmiary plików i katalogów zawartych w danym katalogu lub długość pliku w przypadku, gdy jest to tylko plik.
Opcja -s tworzy zagregowane podsumowanie wyświetlanych długości plików.
Opcja -h formatuje rozmiary plików.
Przykład:
hdfs dfs -du -s -h hdfs://mycluster/
hdfs dfs -du -s -h hdfs://mycluster/tmp
Rm
Polecenie -rm usuwa pliki określone jako argumenty.
Przykład:
hdfs dfs -rm hdfs://mycluster/tmp/testfile
Następne kroki
Jeśli problem nie został wyświetlony lub nie możesz go rozwiązać, odwiedź jeden z następujących kanałów, aby uzyskać więcej pomocy technicznej:
Uzyskaj odpowiedzi od ekspertów platformy Azure za pośrednictwem pomocy technicznej społeczności platformy Azure.
Połączenie za pomocą @AzureSupport — oficjalne konto platformy Microsoft Azure w celu poprawy jakości obsługi klienta. Połączenie społeczności platformy Azure do odpowiednich zasobów: odpowiedzi, pomocy technicznej i ekspertów.
Jeśli potrzebujesz dodatkowej pomocy, możesz przesłać wniosek o pomoc techniczną w witrynie Azure Portal. Wybierz pozycję Pomoc techniczna na pasku menu lub otwórz centrum Pomoc i obsługa techniczna . Aby uzyskać bardziej szczegółowe informacje, zobacz How to create an pomoc techniczna platformy Azure request (Jak utworzyć żądanie pomoc techniczna platformy Azure). Dostęp do pomocy technicznej dotyczącej zarządzania subskrypcjami i rozliczeniami jest oferowany w ramach subskrypcji platformy Microsoft Azure, a pomoc techniczna jest świadczona w ramach jednego z planów pomocy technicznej platformy Azure.