Szybki start: wykonywanie zapytań apache Hive w usłudze Azure HDInsight przy użyciu platformy Apache Zeppelin
Z tego przewodnika Szybki start dowiesz się, jak uruchamiać zapytania apache Hive w usłudze Azure HDInsight przy użyciu platformy Apache Zeppelin. Klastry zapytań interakcyjnych usługi HDInsight obejmują notesy Apache Zeppelin , których można użyć do uruchamiania interakcyjnych zapytań Hive.
Jeśli nie masz subskrypcji platformy Azure, przed rozpoczęciem utwórz bezpłatne konto.
Wymagania wstępne
Klaster zapytań interakcyjnych usługi HDInsight. Zobacz Tworzenie klastra, aby utworzyć klaster usługi HDInsight. Upewnij się, że wybrano typ klastra Interakcyjne zapytanie .
Tworzenie notatki platformy Apache Zeppelin
Zastąp
CLUSTERNAMEciąg nazwą klastra w następującym adresie URLhttps://CLUSTERNAME.azurehdinsight.net/zeppelin. Następnie wprowadź adres URL w przeglądarce internetowej.Wprowadź nazwę użytkownika i hasło logowania klastra. Na stronie Zeppelin możesz utworzyć nową notatkę lub otworzyć istniejące notatki. HiveSample zawiera przykładowe zapytania Hive.
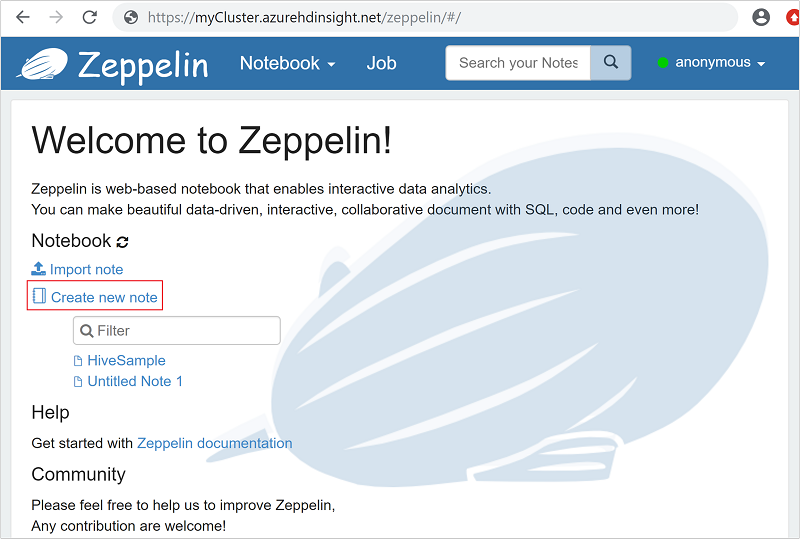
Wybierz pozycję Utwórz nową notatkę.
W oknie dialogowym Tworzenie nowej notatki wpisz lub wybierz następujące wartości:
- Nazwa notatki: wprowadź nazwę notatki.
- Interpreter domyślny: wybierz pozycję jdbc z listy rozwijanej.
Wybierz pozycję Utwórz notatkę.
Wprowadź następujące zapytanie Hive w sekcji kodu, a następnie naciśnij klawisze Shift + Enter:
%jdbc(hive) show tables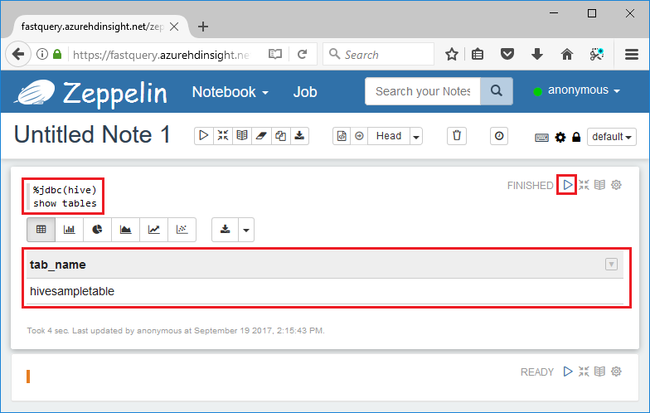
Instrukcja %jdbc(hive) w pierwszym wierszu informuje notes o użyciu interpretera JDBC programu Hive.
Zapytanie zwróci jedną tabelę Hive o nazwie hivesampletable.
Poniżej przedstawiono dwa dodatkowe zapytania Hive, które można uruchamiać względem elementu hivesampletable:
%jdbc(hive) select * from hivesampletable limit 10 %jdbc(hive) select ${group_name}, count(*) as total_count from hivesampletable group by ${group_name=market,market|deviceplatform|devicemake} limit ${total_count=10}W porównaniu z tradycyjną usługą Hive wyniki zapytania muszą wrócić szybciej.
Dodatkowe przykłady
Tworzenie tabeli. Wykonaj poniższy kod w notesie Zeppelin:
%jdbc(hive) CREATE EXTERNAL TABLE log4jLogs ( t1 string, t2 string, t3 string, t4 string, t5 string, t6 string, t7 string) ROW FORMAT DELIMITED FIELDS TERMINATED BY ' ' STORED AS TEXTFILE;Załaduj dane do nowej tabeli. Wykonaj poniższy kod w notesie Zeppelin:
%jdbc(hive) LOAD DATA INPATH 'wasbs:///example/data/sample.log' INTO TABLE log4jLogs;Wstaw pojedynczy rekord. Wykonaj poniższy kod w notesie Zeppelin:
%jdbc(hive) INSERT INTO TABLE log4jLogs2 VALUES ('A', 'B', 'C', 'D', 'E', 'F', 'G');
Przejrzyj podręcznik języka Hive, aby uzyskać dodatkową składnię.
Czyszczenie zasobów
Po zakończeniu pracy z przewodnikiem Szybki start możesz usunąć klaster. W usłudze HDInsight dane są przechowywane w usłudze Azure Storage, dzięki czemu można bezpiecznie usunąć klaster, gdy nie jest używany. Opłaty są również naliczane za klaster usługi HDInsight, nawet jeśli nie jest używany. Ponieważ opłaty za klaster są wielokrotnie większe niż opłaty za magazyn, warto usunąć klastry, gdy nie są używane.
Aby usunąć klaster, zobacz Usuwanie klastra usługi HDInsight przy użyciu przeglądarki, programu PowerShell lub interfejsu wiersza polecenia platformy Azure.
Następne kroki
W tym przewodniku Szybki start przedstawiono sposób uruchamiania zapytań Apache Hive w usłudze Azure HDInsight przy użyciu platformy Apache Zeppelin. Aby dowiedzieć się więcej na temat zapytań Hive, w następnym artykule przedstawiono sposób wykonywania zapytań za pomocą programu Visual Studio.