Instalowanie notesu Jupyter Notebook na komputerze i nawiązywanie połączenia z platformą Apache Spark w usłudze HDInsight
Z tego artykułu dowiesz się, jak zainstalować notes Jupyter Notebook za pomocą niestandardowego programu PySpark (dla języka Python) i jądra platformy Apache Spark (dla języka Scala) za pomocą magii platformy Spark. Następnie połączysz notes z klastrem usługi HDInsight.
Istnieją cztery kluczowe kroki związane z instalowaniem programu Jupyter i nawiązywaniem połączenia z platformą Apache Spark w usłudze HDInsight.
- Konfigurowanie klastra Spark.
- Zainstaluj notes Jupyter Notebook.
- Zainstaluj jądra PySpark i Spark za pomocą magii platformy Spark.
- Konfigurowanie funkcji Magic platformy Spark w celu uzyskania dostępu do klastra Spark w usłudze HDInsight.
Aby uzyskać więcej informacji o niestandardowych jądrach i magii platformy Spark, zobacz Jądra dostępne dla notesów Jupyter Notebooks with Apache Spark Linux clusters on HDInsight (Jądra dostępne dla notesów Jupyter Notebooks with Apache Spark Linux clusters on HDInsight).
Wymagania wstępne
Klaster Apache Spark w usłudze HDInsight. Aby uzyskać instrukcje, zobacz Tworzenie klastra platformy Apache Spark w usłudze Azure HDInsight. Notes lokalny łączy się z klastrem usługi HDInsight.
Znajomość zagadnień dotyczących używania notesów Jupyter za pomocą platformy Spark w usłudze HDInsight.
Instalowanie notesu Jupyter Notebook na komputerze
Zainstaluj język Python przed zainstalowaniem notesów Jupyter Notebook. Dystrybucja anaconda zainstaluje zarówno środowisko Python, jak i notes Jupyter Notebook.
Pobierz instalatora narzędzia Anaconda dla swojej platformy i uruchom instalatora. Podczas uruchamiania kreatora instalacji upewnij się, że wybrano opcję dodania środowiska Anaconda do zmiennej PATH. Zobacz również Instalowanie programu Jupyter przy użyciu programu Anaconda.
Instalowanie magii platformy Spark
Wprowadź polecenie
pip install sparkmagic==0.13.1, aby zainstalować program Magic platformy Spark dla klastrów usługi HDInsight w wersji 3.6 i 4.0. Zobacz również dokumentację platformy Sparkmagic.Upewnij się, że
ipywidgetsjest poprawnie zainstalowana, uruchamiając następujące polecenie:jupyter nbextension enable --py --sys-prefix widgetsnbextension
Instalowanie jąder PySpark i Spark
Zidentyfikuj miejsce
sparkmagicinstalacji, wprowadzając następujące polecenie:pip show sparkmagicNastępnie zmień katalog roboczy na lokalizację zidentyfikowaną za pomocą powyższego polecenia.
W nowym katalogu roboczym wprowadź co najmniej jedno z poniższych poleceń, aby zainstalować żądane jądra:
Jądro Polecenie platforma Spark jupyter-kernelspec install sparkmagic/kernels/sparkkernelSparkR jupyter-kernelspec install sparkmagic/kernels/sparkrkernelPySpark jupyter-kernelspec install sparkmagic/kernels/pysparkkernelPySpark3 jupyter-kernelspec install sparkmagic/kernels/pyspark3kernelOpcjonalny. Wprowadź poniższe polecenie, aby włączyć rozszerzenie serwera:
jupyter serverextension enable --py sparkmagic
Konfigurowanie funkcji Magic platformy Spark w celu nawiązania połączenia z klastrem SPARK usługi HDInsight
W tej sekcji skonfigurujesz zainstalowaną wcześniej magię platformy Spark, aby nawiązać połączenie z klastrem Apache Spark.
Uruchom powłokę języka Python za pomocą następującego polecenia:
pythonInformacje o konfiguracji programu Jupyter są zwykle przechowywane w katalogu macierzystym użytkowników. Wprowadź następujące polecenie, aby zidentyfikować katalog macierzysty i utworzyć folder o nazwie .sparkmagic. Pełna ścieżka zostanie wyświetlona.
import os path = os.path.expanduser('~') + "\\.sparkmagic" os.makedirs(path) print(path) exit()W folderze
.sparkmagicutwórz plik o nazwie config.json i dodaj do niego następujący fragment kodu JSON.{ "kernel_python_credentials" : { "username": "{USERNAME}", "base64_password": "{BASE64ENCODEDPASSWORD}", "url": "https://{CLUSTERDNSNAME}.azurehdinsight.net/livy" }, "kernel_scala_credentials" : { "username": "{USERNAME}", "base64_password": "{BASE64ENCODEDPASSWORD}", "url": "https://{CLUSTERDNSNAME}.azurehdinsight.net/livy" }, "custom_headers" : { "X-Requested-By": "livy" }, "heartbeat_refresh_seconds": 5, "livy_server_heartbeat_timeout_seconds": 60, "heartbeat_retry_seconds": 1 }Wprowadź następujące zmiany w pliku:
Wartość szablonu Nowa wartość {USERNAME} Identyfikator logowania do klastra, wartość domyślna to admin.{CLUSTERDNSNAME} Nazwa klastra {BASE64ENCODEDPASSWORD} Hasło zakodowane w formacie base64 dla rzeczywistego hasła. Hasło base64 można wygenerować pod adresem https://www.url-encode-decode.com/base64-encode-decode/. "livy_server_heartbeat_timeout_seconds": 60Zachowaj, jeśli używasz sparkmagic 0.12.7(klastry w wersji 3.5 i 3.6). W przypadku użyciasparkmagic 0.2.3(klastry w wersji 3.4) zastąp ciąg ."should_heartbeat": truePełny przykładowy plik można zobaczyć na stronie przykładowej config.json.
Napiwek
Pulsy są wysyłane, aby upewnić się, że sesje nie wyciekają. Gdy komputer przejdzie w stan uśpienia lub zostanie zamknięty, puls nie jest wysyłany, co powoduje wyczyszczenie sesji. W przypadku klastrów w wersji 3.4, jeśli chcesz wyłączyć to zachowanie, możesz ustawić konfigurację
livy.server.interactive.heartbeat.timeoutusługi Livy na0z poziomu interfejsu użytkownika systemu Ambari. W przypadku klastrów w wersji 3.5, jeśli nie ustawiono powyższej konfiguracji 3.5, sesja nie zostanie usunięta.Uruchom program Jupyter. Użyj następującego polecenia w wierszu polecenia.
jupyter notebookSprawdź, czy możesz użyć magii platformy Spark dostępnej w jądrach. Wykonaj poniższe czynności.
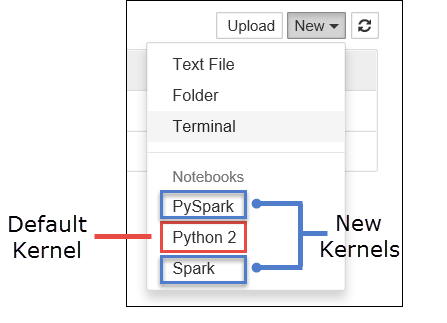
a. Utwórz nowy notes. W prawym rogu wybierz pozycję Nowy. Powinno zostać wyświetlone domyślne jądro Python 2 lub Python 3 i zainstalowane jądra. Rzeczywiste wartości mogą się różnić w zależności od wybranych opcji instalacji. Wybierz pozycję PySpark.
Ważne
Po wybraniu pozycji Nowy przejrzyj powłokę pod kątem błędów. Jeśli zostanie wyświetlony błąd
TypeError: __init__() got an unexpected keyword argument 'io_loop', może wystąpić znany problem z niektórymi wersjami Tornado. Jeśli tak, zatrzymaj jądro, a następnie obniż swoją instalację Tornado za pomocą następującego polecenia:pip install tornado==4.5.3.b. Uruchom poniższy fragment kodu.
%%sql SELECT * FROM hivesampletable LIMIT 5Jeśli możesz pomyślnie pobrać dane wyjściowe, połączenie z klastrem usługi HDInsight zostanie przetestowane.
Jeśli chcesz zaktualizować konfigurację notesu w celu nawiązania połączenia z innym klastrem, zaktualizuj config.json przy użyciu nowego zestawu wartości, jak pokazano w kroku 3 powyżej.
Dlaczego należy zainstalować program Jupyter na moim komputerze?
Powody instalowania programu Jupyter na komputerze, a następnie łączenia go z klastrem Apache Spark w usłudze HDInsight:
- Udostępnia opcję tworzenia notesów lokalnie, testowania aplikacji w uruchomionym klastrze, a następnie przekazywania notesów do klastra. Aby przekazać notesy do klastra, możesz przekazać je przy użyciu uruchomionego notesu Jupyter Notebook lub klastra albo zapisać je w
/HdiNotebooksfolderze na koncie magazynu skojarzonym z klastrem. Aby uzyskać więcej informacji na temat sposobu przechowywania notesów w klastrze, zobacz Gdzie są przechowywane notesy Jupyter Notebook? - Dzięki dostępnym lokalnie notesom można nawiązać połączenie z różnymi klastrami Spark na podstawie wymagań aplikacji.
- Za pomocą usługi GitHub można zaimplementować system kontroli źródła i mieć kontrolę wersji dla notesów. Możesz również mieć środowisko współpracy, w którym wielu użytkowników może pracować z tym samym notesem.
- Notesy można pracować lokalnie bez konieczności tworzenia klastra. Aby przetestować notesy, wystarczy tylko klaster, a nie ręcznie zarządzać notesami ani środowiskiem projektowym.
- Skonfigurowanie własnego lokalnego środowiska programistycznego może być łatwiejsze niż skonfigurowanie instalacji programu Jupyter w klastrze. Możesz skorzystać ze wszystkich zainstalowanych lokalnie oprogramowania bez konfigurowania co najmniej jednego klastra zdalnego.
Ostrzeżenie
W programie Jupyter zainstalowanym na komputerze lokalnym wielu użytkowników może jednocześnie uruchamiać ten sam notes w tym samym klastrze Spark. W takiej sytuacji jest tworzonych wiele sesji usługi Livy. Jeśli wystąpi problem i chcesz go debugować, będzie to złożone zadanie do śledzenia, która sesja usługi Livy należy do tego użytkownika.