Wstępne przetwarzanie tekstu
W tym artykule opisano składnik w projektancie usługi Azure Machine Learning.
Użyj składnika Preprocess Text , aby wyczyścić i uprościć tekst. Obsługuje te typowe operacje przetwarzania tekstu:
- Usuwanie słów zatrzymania
- Wyszukiwanie i zastępowanie określonych ciągów docelowych przy użyciu wyrażeń regularnych
- Lemmatyzacja, która konwertuje wiele powiązanych wyrazów na jedną formę kanoniczną
- Normalizacja przypadku
- Usuwanie niektórych klas znaków, takich jak liczby, znaki specjalne i sekwencje powtarzających się znaków, takich jak "aaaa"
- Identyfikacja i usuwanie wiadomości e-mail i adresów URL
Składnik Preprocess Text obecnie obsługuje tylko język angielski.
Konfigurowanie przetwarzania wstępnego tekstu
Dodaj składnik Preprocess Text do potoku w usłudze Azure Machine Learning. Ten składnik można znaleźć w analiza tekstu.
Połącz zestaw danych z co najmniej jedną kolumną zawierającą tekst.
Wybierz język z listy rozwijanej Język .
Kolumna tekstowa do oczyszczenia: wybierz kolumnę, którą chcesz wstępnie przetworzyć.
Usuń słowa zatrzymania: wybierz tę opcję, jeśli chcesz zastosować wstępnie zdefiniowaną listę stopwordów do kolumny tekstowej.
Listy stopwordów są zależne od języka i można je dostosowywać.
Lemmatization: wybierz tę opcję, jeśli chcesz, aby wyrazy mogły być reprezentowane w formie kanonicznej. Ta opcja jest przydatna do zmniejszenia liczby unikatowych wystąpień innych podobnych tokenów tekstowych.
Proces lemmatyzacji jest bardzo zależny od języka.
Wykryj zdania: wybierz tę opcję, jeśli składnik ma wstawić znak granicy zdania podczas przeprowadzania analizy.
Ten składnik używa serii trzech znaków
|||potoku do reprezentowania terminatora zdań.Wykonaj opcjonalne operacje znajdowania i zastępowania przy użyciu wyrażeń regularnych. Wyrażenie regularne będzie przetwarzane na początku przed wszystkimi innymi wbudowanymi opcjami.
- Niestandardowe wyrażenie regularne: zdefiniuj wyszukiwany tekst.
- Niestandardowy ciąg zastępczy: zdefiniuj pojedynczą wartość zastępczą.
Normalizuj wielkość liter do małych liter: wybierz tę opcję, jeśli chcesz przekonwertować wielkie litery ASCII na małe formularze.
Jeśli znaki nie są znormalizowane, to samo słowo w wielkich i małych literach jest uznawane za dwa różne wyrazy.
Można również usunąć następujące typy znaków lub sekwencji znaków z przetworzonego tekstu wyjściowego:
Usuń liczby: wybierz tę opcję, aby usunąć wszystkie znaki liczbowe dla określonego języka. Numery identyfikacyjne są zależne od domeny i zależne od języka. Jeśli znaki liczbowe są integralną częścią znanego słowa, liczba może nie zostać usunięta. Dowiedz się więcej w temacie Uwagi techniczne.
Usuń znaki specjalne: użyj tej opcji, aby usunąć wszystkie znaki specjalne inne niż alfanumeryczne.
Usuń zduplikowane znaki: wybierz tę opcję, aby usunąć dodatkowe znaki w dowolnych sekwencjach powtarzanych przez więcej niż dwa razy. Na przykład sekwencja podobna do "aaaaa" zostanie zmniejszona do "aa".
Usuń adresy e-mail: wybierz tę opcję, aby usunąć dowolną sekwencję formatu
<string>@<string>.Usuń adresy URL: wybierz tę opcję, aby usunąć dowolną sekwencję zawierającą następujące prefiksy adresów URL:
http, ,https,ftpwww
Rozwiń kontrakty czasowników: ta opcja dotyczy tylko języków korzystających z kontraktów czasowników; obecnie tylko angielski.
Na przykład po wybraniu tej opcji można zastąpić frazę "nie pozostanie tam" ciągiem "nie pozostanie tam".
Normalizuj ukośniki odwrotne do ukośników: wybierz tę opcję, aby zamapować wszystkie wystąpienia na
\\/.Podziel tokeny na znaki specjalne: wybierz tę opcję, jeśli chcesz podzielić wyrazy na znaki, takie jak
&,-i tak dalej. Ta opcja może również zmniejszyć znaki specjalne, gdy powtarza się więcej niż dwa razy.Na przykład ciąg
MS---WORDzostanie rozdzielony na trzy tokeny,MS,-iWORD.Prześlij potok.
Uwagi techniczne
Składnik wstępnego przetwarzania tekstu w programie Studio (wersja klasyczna) i projektant używają różnych modeli językowych. Projektant używa wielodaniowego wytrenowanego modelu CNN ze spaCy. Różne modele dają różne tokenizery i moduł tagger części mowy, co prowadzi do różnych wyników.
Poniżej przedstawiono kilka przykładów:
| Konfigurowanie | Wynik wyjściowy |
|---|---|
| Po wybraniu wszystkich opcji Wyjaśnienie: w przypadku przypadków takich jak "3test" w teście "WC-3 3test 4test", projektant usunie całe słowo "3test", ponieważ w tym kontekście część mowy tagger określa ten token "3test" jako liczbowy, a zgodnie z częścią mowy składnik go usuwa. |
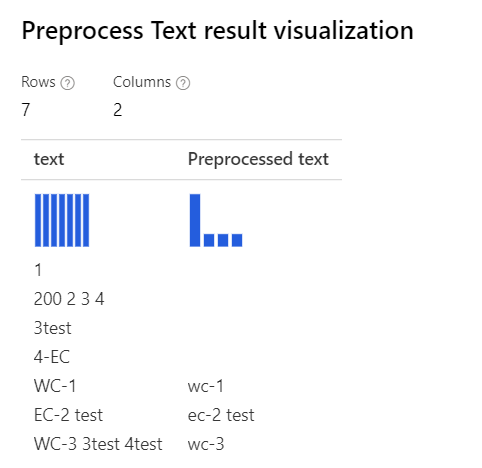
|
Removing number Tylko z wybranym wyjaśnieniem: w przypadku przypadków takich jak "3test", "4-EC", dawka tokenizatora projektanta nie dzieli tych przypadków i traktuje je jako całe tokeny. Nie spowoduje to usunięcia liczb w tych słowach. |

|
Możesz również użyć wyrażenia regularnego do danych wyjściowych dostosowanych wyników:
| Konfigurowanie | Wynik wyjściowy |
|---|---|
| Po wybraniu opcji Niestandardowe wyrażenie regularne: (\s+)*(-|\d+)(\s+)*Niestandardowy ciąg zastępczy: \1 \2 \3 |

|
Removing number Tylko z wybranym niestandardowym wyrażeniem regularnym: (\s+)*(-|\d+)(\s+)*Niestandardowy ciąg zastępczy: \1 \2 \3 |
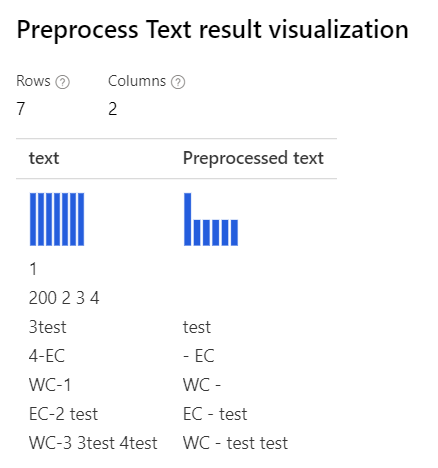
|
Następne kroki
Zobacz zestaw składników dostępnych dla usługi Azure Machine Learning.