Konfigurowanie rozwiązania AutoML do trenowania modelu prognozowania szeregów czasowych przy użyciu zestawu SDK i interfejsu wiersza polecenia
DOTYCZY: Rozszerzenie interfejsu wiersza polecenia platformy Azure w wersji 2 (current)Zestaw PYTHON SDK azure-ai-ml v2 (bieżąca)
Rozszerzenie interfejsu wiersza polecenia platformy Azure w wersji 2 (current)Zestaw PYTHON SDK azure-ai-ml v2 (bieżąca)
W tym artykule dowiesz się, jak skonfigurować rozwiązanie AutoML na potrzeby prognozowania szeregów czasowych przy użyciu usługi Azure Machine Edukacja zautomatyzowanego uczenia maszynowego w zestawie SDK języka Python Edukacja azure Machine.
W tym celu wykonasz następujące czynności:
Aby uzyskać małe środowisko kodu, zobacz Samouczek: prognozowanie zapotrzebowania za pomocą zautomatyzowanego uczenia maszynowego dla przykładu prognozowania szeregów czasowych przy użyciu zautomatyzowanego uczenia maszynowego w usłudze Azure Machine Edukacja Studio.
Rozwiązanie AutoML używa standardowych modeli uczenia maszynowego wraz z dobrze znanymi modelami szeregów czasowych do tworzenia prognoz. Nasze podejście obejmuje historyczne informacje o zmiennej docelowej, funkcjach udostępnianych przez użytkownika w danych wejściowych i automatycznie zaprojektowanych funkcjach. Następnie algorytmy wyszukiwania modelu działają, aby znaleźć model z najlepszą dokładnością predykcyjną. Aby uzyskać więcej informacji, zobacz nasze artykuły dotyczące metodologii prognozowania i wyszukiwania modeli.
Wymagania wstępne
Na potrzeby tego artykułu potrzebne są następujące elementy:
Obszar roboczy usługi Azure Machine Learning. Aby utworzyć obszar roboczy, zobacz Tworzenie zasobów obszaru roboczego.
Możliwość uruchamiania zadań trenowania automatycznego uczenia maszynowego. Aby uzyskać szczegółowe informacje, postępuj zgodnie z przewodnikiem z instrukcjami dotyczącymi konfigurowania rozwiązania AutoML .
Dane trenowania i walidacji
Dane wejściowe prognozowania automatycznego uczenia maszynowego muszą zawierać prawidłowe serie czasowe w formacie tabelarycznym. Każda zmienna musi mieć własną odpowiednią kolumnę w tabeli danych. Rozwiązanie AutoML wymaga co najmniej dwóch kolumn: kolumny czasu reprezentującej oś czasu i kolumnę docelową, która jest ilością do prognozowania. Inne kolumny mogą służyć jako predyktory. Aby uzyskać więcej informacji, zobacz , jak rozwiązanie AutoML używa danych.
Ważne
Podczas trenowania modelu prognozowania przyszłych wartości upewnij się, że wszystkie funkcje używane w trenowaniu mogą być używane podczas uruchamiania przewidywań dla zamierzonego horyzontu.
Na przykład funkcja bieżącej ceny akcji może znacznie zwiększyć dokładność trenowania. Jeśli jednak zamierzasz prognozować z długim horyzontem, może nie być w stanie dokładnie przewidzieć przyszłych wartości zapasów odpowiadających przyszłym punktom szeregów czasowych, a dokładność modelu może cierpieć.
Zadania prognozowania automatycznego uczenia maszynowego wymagają, aby dane szkoleniowe były reprezentowane jako obiekt MLTable . Tabela MLTable określa źródło danych i kroki ładowania danych. Aby uzyskać więcej informacji i przypadków użycia, zobacz przewodnik z instrukcjami w tabeli MLTable. W prostym przykładzie załóżmy, że dane szkoleniowe znajdują się w pliku CSV w katalogu ./train_data/timeseries_train.csvlokalnym .
Tabelę MLTable można utworzyć przy użyciu zestawu MLTable Python SDK , jak pokazano w poniższym przykładzie:
import mltable
paths = [
{'file': './train_data/timeseries_train.csv'}
]
train_table = mltable.from_delimited_files(paths)
train_table.save('./train_data')
Ten kod tworzy nowy plik , ./train_data/MLTablektóry zawiera format pliku i instrukcje ładowania.
Teraz zdefiniuj obiekt danych wejściowych, który jest wymagany do uruchomienia zadania szkoleniowego przy użyciu zestawu SDK języka Python Edukacja azure Machine w następujący sposób:
from azure.ai.ml.constants import AssetTypes
from azure.ai.ml import Input
# Training MLTable defined locally, with local data to be uploaded
my_training_data_input = Input(
type=AssetTypes.MLTABLE, path="./train_data"
)
Dane weryfikacji można określić w podobny sposób, tworząc tabelę MLTable i określając dane wejściowe danych walidacji. Alternatywnie, jeśli nie podasz danych walidacji, rozwiązanie AutoML automatycznie tworzy podziały krzyżowe weryfikacji z danych treningowych do użycia na potrzeby wyboru modelu. Aby uzyskać więcej informacji, zobacz nasz artykuł na temat wyboru modelu prognozowania. Zobacz również wymagania dotyczące długości danych treningowych, aby uzyskać szczegółowe informacje na temat ilości danych treningowych, które należy pomyślnie wytrenować model prognozowania.
Dowiedz się więcej o tym, jak rozwiązanie AutoML stosuje krzyżową walidację, aby zapobiec nadmiernemu dopasowaniu.
Obliczenia w celu uruchomienia eksperymentu
Rozwiązanie AutoML używa usługi Azure Machine Edukacja Compute, która jest w pełni zarządzanym zasobem obliczeniowym, aby uruchomić zadanie trenowania. W poniższym przykładzie tworzony jest klaster obliczeniowy o nazwie cpu-compute :
from azure.ai.ml.entities import AmlCompute
# specify aml compute name.
cpu_compute_target = "cpu-cluster"
try:
ml_client.compute.get(cpu_compute_target)
except Exception:
print("Creating a new cpu compute target...")
compute = AmlCompute(
name=cpu_compute_target, size="STANDARD_D2_V2", min_instances=0, max_instances=4
)
ml_client.compute.begin_create_or_update(compute).result()Konfigurowanie eksperymentu
Funkcje fabryki automatycznego uczenia maszynowego służą do konfigurowania zadań prognozowania w zestawie SDK języka Python. W poniższym przykładzie pokazano, jak utworzyć zadanie prognozowania, ustawiając metrykę podstawową i ustawiając limity w przebiegu trenowania:
from azure.ai.ml import automl
# note that the below is a code snippet -- you might have to modify the variable values to run it successfully
forecasting_job = automl.forecasting(
compute="cpu-compute",
experiment_name="sdk-v2-automl-forecasting-job",
training_data=my_training_data_input,
target_column_name=target_column_name,
primary_metric="normalized_root_mean_squared_error",
n_cross_validations="auto",
)
# Limits are all optional
forecasting_job.set_limits(
timeout_minutes=120,
trial_timeout_minutes=30,
max_concurrent_trials=4,
)
Ustawienia zadania prognozowania
Zadania prognozowania mają wiele ustawień specyficznych dla prognozowania. Najbardziej podstawowe z tych ustawień są nazwa kolumny czasu w danych treningowych i horyzoncie prognozy.
Użyj metod ForecastingJob, aby skonfigurować następujące ustawienia:
# Forecasting specific configuration
forecasting_job.set_forecast_settings(
time_column_name=time_column_name,
forecast_horizon=24
)
Nazwa kolumny czasowej jest wymaganym ustawieniem i zazwyczaj należy ustawić horyzont prognozy zgodnie ze scenariuszem przewidywania. Jeśli dane zawierają wiele szeregów czasowych, możesz określić nazwy kolumn identyfikatorów szeregów czasowych. Te kolumny po zgrupowaniu definiują pojedynczą serię. Załóżmy na przykład, że masz dane składające się z godzinowej sprzedaży z różnych sklepów i marek. W poniższym przykładzie pokazano, jak ustawić kolumny identyfikatorów szeregów czasowych przy założeniu, że dane zawierają kolumny o nazwach "store" i "brand":
# Forecasting specific configuration
# Add time series IDs for store and brand
forecasting_job.set_forecast_settings(
..., # other settings
time_series_id_column_names=['store', 'brand']
)
Rozwiązanie AutoML próbuje automatycznie wykrywać kolumny identyfikatorów szeregów czasowych w danych, jeśli nie zostały określone.
Inne ustawienia są opcjonalne i przeglądane w następnej sekcji.
Opcjonalne ustawienia zadania prognozowania
Opcjonalne konfiguracje są dostępne dla zadań prognozowania, takich jak włączanie uczenia głębokiego i określanie docelowej agregacji okien kroczących. Pełna lista parametrów jest dostępna w dokumentacji dokumentacji referencyjnej prognozowania.
Ustawienia wyszukiwania modelu
Istnieją dwa opcjonalne ustawienia, które kontrolują przestrzeń modelu, w której rozwiązanie AutoML wyszukuje najlepszy model i allowed_training_algorithmsblocked_training_algorithms. Aby ograniczyć przestrzeń wyszukiwania do danego zestawu klas modelu, użyj parametru allowed_training_algorithms , jak w poniższym przykładzie:
# Only search ExponentialSmoothing and ElasticNet models
forecasting_job.set_training(
allowed_training_algorithms=["ExponentialSmoothing", "ElasticNet"]
)
W tym przypadku zadanie prognozowania wyszukuje tylko klasy modelu Exponential Smoothing i Elastic Net. Aby usunąć dany zestaw klas modelu z obszaru wyszukiwania, użyj blocked_training_algorithms jak w poniższym przykładzie:
# Search over all model classes except Prophet
forecasting_job.set_training(
blocked_training_algorithms=["Prophet"]
)
Teraz zadanie wyszukuje wszystkie klasy modeli z wyjątkiem Proroka. Aby uzyskać listę nazw modeli prognozowania akceptowanych w allowed_training_algorithms systemach i blocked_training_algorithms, zobacz dokumentację referencyjną właściwości trenowania. Albo, ale nie oba, i allowed_training_algorithmsblocked_training_algorithms można zastosować do przebiegu treningowego.
Włączanie uczenia głębokiego
Rozwiązanie AutoML jest dostarczane z niestandardowym modelem głębokiej sieci neuronowej (DNN) o nazwie TCNForecaster. Ten model to tymczasowa sieć konwolucyjna lub TCN, która stosuje typowe metody zadań obrazowania do modelowania szeregów czasowych. Mianowicie jednowymiarowe "przyczynowe" sploty tworzą szkielet sieci i umożliwiają modelowi uczenie się złożonych wzorców przez długi czas w historii trenowania. Aby uzyskać więcej informacji, zobacz nasz artykuł TCNForecaster.
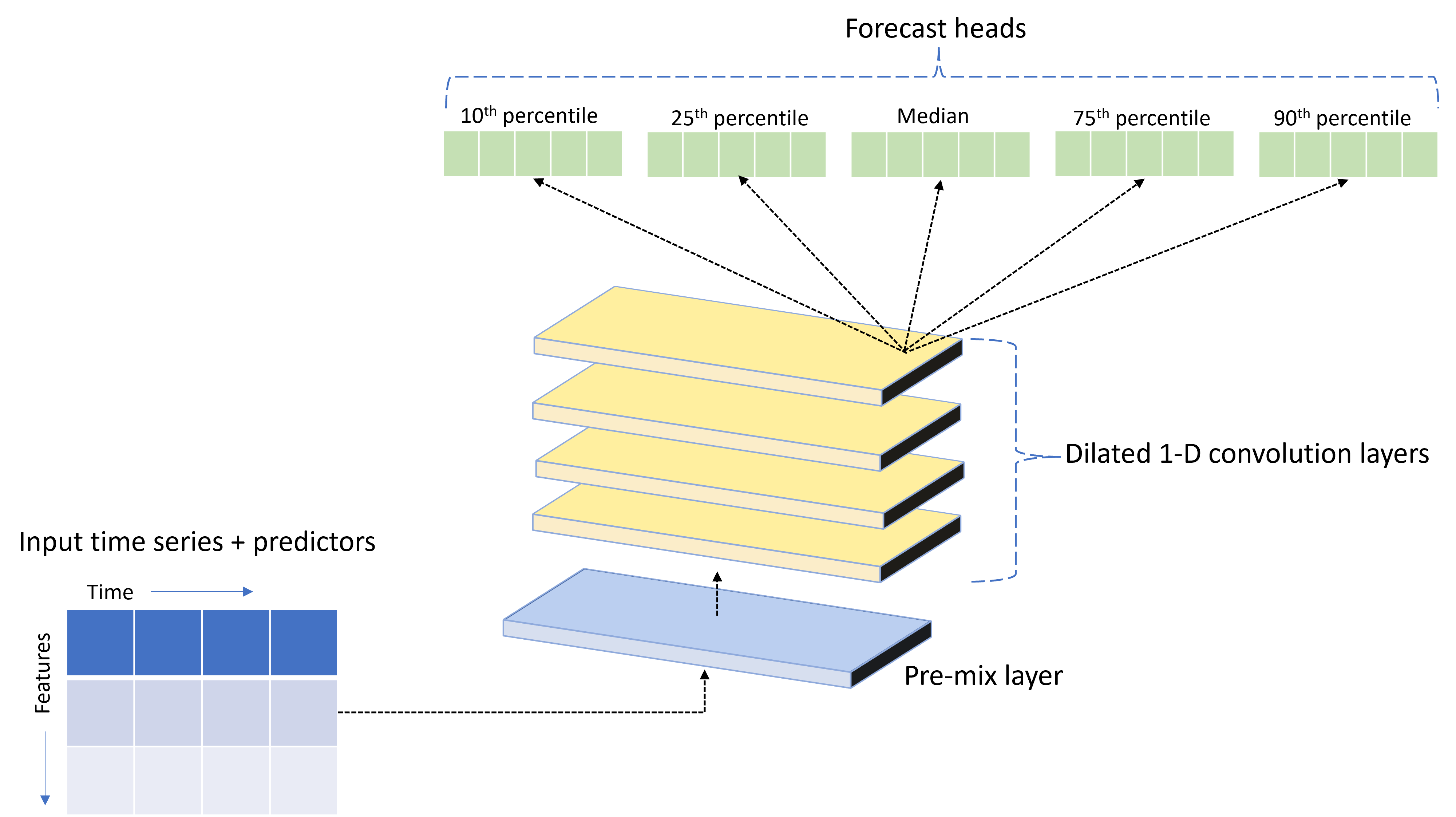
TCNForecaster często osiąga większą dokładność niż standardowe modele szeregów czasowych, gdy istnieje tysiące lub więcej obserwacji w historii trenowania. Jednak trenowanie i zamiatanie modeli TCNForecaster z powodu ich wyższej pojemności trwa dłużej.
Funkcję TCNForecaster można włączyć w rozwiązaniu AutoML, ustawiając flagę enable_dnn_training w konfiguracji trenowania w następujący sposób:
# Include TCNForecaster models in the model search
forecasting_job.set_training(
enable_dnn_training=True
)
Domyślnie trenowanie TCNForecaster jest ograniczone do jednego węzła obliczeniowego i pojedynczego procesora GPU, jeśli jest dostępny, na wersję próbną modelu. W przypadku scenariuszy dużych danych zalecamy dystrybucję każdej wersji próbnej TCNForecaster na wiele rdzeni/procesorów GPU i węzłów. Aby uzyskać więcej informacji i przykładów kodu, zobacz sekcję artykułu dotyczącego trenowania rozproszonego.
Aby włączyć nazwę sieci rozproszonej dla eksperymentu automatycznego uczenia maszynowego utworzonego w narzędziu Azure Machine Edukacja Studio, zobacz ustawienia typu zadania w interfejsie użytkownika programu Studio.
Uwaga
- Po włączeniu nazwy sieci rozproszonej dla eksperymentów utworzonych za pomocą zestawu SDK najlepsze wyjaśnienia modelu są wyłączone.
- Obsługa sieci rozproszonej na potrzeby prognozowania w usłudze Automated Machine Edukacja nie jest obsługiwana w przypadku przebiegów zainicjowanych w usłudze Databricks.
- Typy obliczeniowe procesora GPU są zalecane w przypadku włączenia trenowania sieci rozproszonej
Funkcje opóźnień i okien kroczenia
Ostatnie wartości celu często mają wpływ na funkcje w modelu prognozowania. W związku z tym rozwiązanie AutoML może tworzyć funkcje agregacji okien czasowych i kroczenia, aby potencjalnie zwiększyć dokładność modelu.
Rozważmy scenariusz prognozowania zapotrzebowania na energię, w którym są dostępne dane pogodowe i historyczne zapotrzebowanie. W tabeli przedstawiono wynikowe inżynierii cech, które występują, gdy agregacja okien jest stosowana w ciągu ostatnich trzech godzin. Kolumny dla wartości minimalnej, maksymalnej i sumy są generowane w oknie przewijania wynoszącym trzy godziny na podstawie zdefiniowanych ustawień. Na przykład dla obserwacji ważnej 8 września 2017 4:00, wartości maksymalne, minimalne i sum są obliczane przy użyciu wartości zapotrzebowania dla 8 września 2017 r. 1:00–3:00. To okno z trzema godzinami zmienia się, aby wypełnić dane pozostałych wierszy. Aby uzyskać więcej szczegółów i przykładów, zobacz artykuł dotyczący funkcji opóźnienia.

Funkcje agregacji opóźnień i okien kroczenia dla elementu docelowego można włączyć, ustawiając rozmiar okna kroczącego, który był trzy w poprzednim przykładzie, oraz zamówienia opóźnień, które chcesz utworzyć. Można również włączyć opóźnienia dla funkcji za pomocą feature_lags ustawienia . W poniższym przykładzie ustawiliśmy wszystkie te ustawienia tak auto , aby rozwiązanie AutoML automatycznie określało ustawienia, analizując strukturę korelacji danych:
forecasting_job.set_forecast_settings(
..., # other settings
target_lags='auto',
target_rolling_window_size='auto',
feature_lags='auto'
)
Obsługa serii krótkiej
Zautomatyzowane uczenie maszynowe uwzględnia szereg czasowy serii krótkiej, jeśli nie ma wystarczającej liczby punktów danych, aby przeprowadzić fazy trenowania i walidacji tworzenia modelu. Zobacz wymagania dotyczące długości danych treningowych, aby uzyskać więcej informacji na temat wymagań dotyczących długości.
Rozwiązanie AutoML ma kilka akcji, które można wykonać w krótkiej serii. Te akcje można konfigurować za pomocą short_series_handling_config ustawienia. Wartość domyślna to "auto". W poniższej tabeli opisano ustawienia:
| Ustawienie | opis |
|---|---|
auto |
Wartość domyślna obsługi serii krótkich. - Jeśli wszystkie serie są krótkie, dodaj dane. - Jeśli nie wszystkie serie są krótkie, upuść krótką serię. |
pad |
Jeśli short_series_handling_config = padwartość , zautomatyzowane uczenie maszynowe dodaje losowe wartości do każdej znalezionej serii krótkiej. Poniżej wymieniono typy kolumn i ich zawartość: - Kolumny obiektów z siecią NaNs - Kolumny liczbowe z 0 - Kolumny logiczne/logiczne z fałszem - Kolumna docelowa jest dopełniona białym szumem. |
drop |
W przypadku short_series_handling_config = drop, zautomatyzowane uczenie maszynowe pominie serię krótką i nie będzie używane do trenowania ani przewidywania. Przewidywania dla tych serii będą zwracać wartości NaN. |
None |
Żadna seria nie jest wypełniona lub porzucona |
W poniższym przykładzie ustawiliśmy obsługę serii krótkiej tak, aby wszystkie serie krótkie zostały dopełnione do minimalnej długości:
forecasting_job.set_forecast_settings(
..., # other settings
short_series_handling_config='pad'
)
Ostrzeżenie
Wypełnienie może mieć wpływ na dokładność wynikowego modelu, ponieważ wprowadzamy sztuczne dane, aby uniknąć niepowodzeń trenowania. Jeśli wiele serii jest krótkich, może być również widoczny wpływ na wyniki objaśnienia
Częstotliwość i docelowa agregacja danych
Użyj opcji częstotliwości i agregacji danych, aby uniknąć błędów spowodowanych nieregularnymi danymi. Dane są nieregularne, jeśli nie są zgodne z określonym okresem czasu, na przykład godzinowo lub codziennie. Dane dotyczące punktów sprzedaży są dobrym przykładem nieregularnych danych. W takich przypadkach rozwiązanie AutoML może agregować dane do żądanej częstotliwości, a następnie utworzyć model prognozowania na podstawie agregacji.
Należy ustawić frequency ustawienia i target_aggregate_function , aby obsługiwać nieregularne dane. Ustawienie częstotliwości akceptuje ciągi DateOffset biblioteki Pandas jako dane wejściowe. Obsługiwane wartości funkcji agregacji to:
| Function | opis |
|---|---|
sum |
Suma wartości docelowych |
mean |
Średnia lub średnia wartości docelowych |
min |
Minimalna wartość elementu docelowego |
max |
Maksymalna wartość elementu docelowego |
- Wartości kolumny docelowej są agregowane zgodnie z określoną operacją. Zazwyczaj suma jest odpowiednia dla większości scenariuszy.
- Kolumny predyktora liczbowego w danych są agregowane według sumy, średniej, wartości minimalnej i wartości maksymalnej. W rezultacie zautomatyzowane uczenie maszynowe generuje nowe kolumny z sufiksem nazwy funkcji agregacji i stosuje wybraną operację agregacji.
- W przypadku kolumn predyktora kategorii dane są agregowane według trybu, najbardziej widocznej kategorii w oknie.
- Kolumny predyktora dat są agregowane według wartości minimalnej, wartości maksymalnej i trybu.
W poniższym przykładzie ustawiono częstotliwość na wartość godzinową, a funkcja agregacji na sumację:
# Aggregate the data to hourly frequency
forecasting_job.set_forecast_settings(
..., # other settings
frequency='H',
target_aggregate_function='sum'
)
Niestandardowe ustawienia krzyżowego sprawdzania poprawności
Istnieją dwa dostosowywalne ustawienia, które kontrolują krzyżową walidację zadań prognozowania: liczbę składań, n_cross_validationsi rozmiar kroku definiujący przesunięcie czasu między fałdami, cv_step_size. Aby uzyskać więcej informacji na temat znaczenia tych parametrów, zobacz wybór modelu prognozowania. Domyślnie rozwiązanie AutoML automatycznie ustawia oba ustawienia na podstawie cech danych, ale zaawansowani użytkownicy mogą chcieć ustawić je ręcznie. Załóżmy na przykład, że masz dzienne dane sprzedaży i chcesz, aby konfiguracja walidacji składała się z pięciu składa się z siedmiodniowego przesunięcia między sąsiednimi fałdami. Poniższy przykładowy kod pokazuje, jak ustawić następujące elementy:
from azure.ai.ml import automl
# Create a job with five CV folds
forecasting_job = automl.forecasting(
..., # other training parameters
n_cross_validations=5,
)
# Set the step size between folds to seven days
forecasting_job.set_forecast_settings(
..., # other settings
cv_step_size=7
)
Cechowanie niestandardowe
Domyślnie rozwiązanie AutoML rozszerza dane szkoleniowe o funkcje zaprojektowane w celu zwiększenia dokładności modeli. Aby uzyskać więcej informacji, zobacz automatyczną inżynierię cech. Niektóre kroki przetwarzania wstępnego można dostosować przy użyciu konfiguracji cech zadania prognozowania.
Obsługiwane dostosowania do prognozowania znajdują się w poniższej tabeli:
| Dostosowanie | opis | Opcje |
|---|---|---|
| Aktualizacja celu kolumny | Zastąpij automatycznie wykryty typ funkcji dla określonej kolumny. | "Kategoria", "DateTime", "Numeryczne" |
| Aktualizacja parametrów transformatora | Zaktualizuj parametry dla określonego imputera. | {"strategy": "constant", "fill_value": <value>}, , {"strategy": "median"}{"strategy": "ffill"} |
Załóżmy na przykład, że masz scenariusz popytu detalicznego, w którym dane obejmują ceny, flagę "sprzedaży" i typ produktu. W poniższym przykładzie pokazano, jak ustawić dostosowane typy i imputery dla tych funkcji:
from azure.ai.ml.automl import ColumnTransformer
# Customize imputation methods for price and is_on_sale features
# Median value imputation for price, constant value of zero for is_on_sale
transformer_params = {
"imputer": [
ColumnTransformer(fields=["price"], parameters={"strategy": "median"}),
ColumnTransformer(fields=["is_on_sale"], parameters={"strategy": "constant", "fill_value": 0}),
],
}
# Set the featurization
# Ensure that product_type feature is interpreted as categorical
forecasting_job.set_featurization(
mode="custom",
transformer_params=transformer_params,
column_name_and_types={"product_type": "Categorical"},
)
Jeśli używasz programu Azure Machine Edukacja Studio na potrzeby eksperymentu, zobacz, jak dostosować cechowanie w studio.
Przesyłanie zadania prognozowania
Po skonfigurowaniu wszystkich ustawień uruchamiasz zadanie prognozowania w następujący sposób:
# Submit the AutoML job
returned_job = ml_client.jobs.create_or_update(
forecasting_job
)
print(f"Created job: {returned_job}")
# Get a URL for the job in the AML studio user interface
returned_job.services["Studio"].endpoint
Po przesłaniu zadania rozwiązanie AutoML będzie aprowizować zasoby obliczeniowe, zastosować cechowanie i inne kroki przygotowania do danych wejściowych, a następnie rozpocząć zamiatanie modeli prognozowania. Aby uzyskać więcej informacji, zobacz nasze artykuły dotyczące metodologii prognozowania i wyszukiwania modeli.
Organizowanie trenowania, wnioskowania i oceny przy użyciu składników i potoków
Ważne
Ta funkcja jest obecnie w publicznej wersji zapoznawczej. Ta wersja zapoznawcza jest udostępniana bez umowy dotyczącej poziomu usług i nie zalecamy korzystania z niej w przypadku obciążeń produkcyjnych. Niektóre funkcje mogą być nieobsługiwane lub ograniczone.
Aby uzyskać więcej informacji, zobacz Uzupełniające warunki korzystania z wersji zapoznawczych platformy Microsoft Azure.
Przepływ pracy uczenia maszynowego prawdopodobnie wymaga więcej niż tylko trenowania. Wnioskowanie lub pobieranie przewidywań modelu na nowszych danych oraz ocena dokładności modelu w zestawie testowym ze znanymi wartościami docelowymi to inne typowe zadania, które można organizować w usłudze AzureML wraz z zadaniami treningowymi. Aby obsługiwać zadania wnioskowania i oceny, usługa AzureML udostępnia składniki, które są samodzielnymi fragmentami kodu, które wykonują jeden krok w potoku usługi AzureML.
W poniższym przykładzie pobieramy kod składnika z rejestru klienta:
from azure.ai.ml import MLClient
from azure.identity import DefaultAzureCredential, InteractiveBrowserCredential
# Get a credential for access to the AzureML registry
try:
credential = DefaultAzureCredential()
# Check if we can get token successfully.
credential.get_token("https://management.azure.com/.default")
except Exception as ex:
# Fall back to InteractiveBrowserCredential in case DefaultAzureCredential fails
credential = InteractiveBrowserCredential()
# Create a client for accessing assets in the AzureML preview registry
ml_client_registry = MLClient(
credential=credential,
registry_name="azureml-preview"
)
# Create a client for accessing assets in the AzureML preview registry
ml_client_metrics_registry = MLClient(
credential=credential,
registry_name="azureml"
)
# Get an inference component from the registry
inference_component = ml_client_registry.components.get(
name="automl_forecasting_inference",
label="latest"
)
# Get a component for computing evaluation metrics from the registry
compute_metrics_component = ml_client_metrics_registry.components.get(
name="compute_metrics",
label="latest"
)
Następnie zdefiniujemy funkcję fabryki, która tworzy potoki organizujące trenowanie, wnioskowanie i obliczanie metryk. Aby uzyskać więcej informacji na temat ustawień trenowania, zobacz sekcję konfiguracja trenowania.
from azure.ai.ml import automl
from azure.ai.ml.constants import AssetTypes
from azure.ai.ml.dsl import pipeline
@pipeline(description="AutoML Forecasting Pipeline")
def forecasting_train_and_evaluate_factory(
train_data_input,
test_data_input,
target_column_name,
time_column_name,
forecast_horizon,
primary_metric='normalized_root_mean_squared_error',
cv_folds='auto'
):
# Configure the training node of the pipeline
training_node = automl.forecasting(
training_data=train_data_input,
target_column_name=target_column_name,
primary_metric=primary_metric,
n_cross_validations=cv_folds,
outputs={"best_model": Output(type=AssetTypes.MLFLOW_MODEL)},
)
training_node.set_forecasting_settings(
time_column_name=time_column_name,
forecast_horizon=max_horizon,
frequency=frequency,
# other settings
...
)
training_node.set_training(
# training parameters
...
)
training_node.set_limits(
# limit settings
...
)
# Configure the inference node to make rolling forecasts on the test set
inference_node = inference_component(
test_data=test_data_input,
model_path=training_node.outputs.best_model,
target_column_name=target_column_name,
forecast_mode='rolling',
forecast_step=1
)
# Configure the metrics calculation node
compute_metrics_node = compute_metrics_component(
task="tabular-forecasting",
ground_truth=inference_node.outputs.inference_output_file,
prediction=inference_node.outputs.inference_output_file,
evaluation_config=inference_node.outputs.evaluation_config_output_file
)
# return a dictionary with the evaluation metrics and the raw test set forecasts
return {
"metrics_result": compute_metrics_node.outputs.evaluation_result,
"rolling_fcst_result": inference_node.outputs.inference_output_file
}
Teraz definiujemy dane wejściowe trenowania i testowania przy założeniu, że znajdują się one w folderach lokalnych i ./train_data./test_data:
my_train_data_input = Input(
type=AssetTypes.MLTABLE,
path="./train_data"
)
my_test_data_input = Input(
type=AssetTypes.URI_FOLDER,
path='./test_data',
)
Na koniec skonstruujemy potok, ustawiamy jego domyślne obliczenia i przesyłamy zadanie:
pipeline_job = forecasting_train_and_evaluate_factory(
my_train_data_input,
my_test_data_input,
target_column_name,
time_column_name,
forecast_horizon
)
# set pipeline level compute
pipeline_job.settings.default_compute = compute_name
# submit the pipeline job
returned_pipeline_job = ml_client.jobs.create_or_update(
pipeline_job,
experiment_name=experiment_name
)
returned_pipeline_job
Po przesłaniu potok uruchamia trenowanie automatycznego uczenia maszynowego, wnioskowanie oceny stopniowej i obliczanie metryk w sekwencji. Możesz monitorować i sprawdzać przebieg w interfejsie użytkownika programu Studio. Po zakończeniu przebiegu prognozy stopniowe i metryki oceny można pobrać do lokalnego katalogu roboczego:
# Download the metrics json
ml_client.jobs.download(returned_pipeline_job.name, download_path=".", output_name='metrics_result')
# Download the rolling forecasts
ml_client.jobs.download(returned_pipeline_job.name, download_path=".", output_name='rolling_fcst_result')
Następnie możesz znaleźć wyniki metryk i ./named-outputs/metrics_results/evaluationResult/metrics.json prognozy w formacie wierszy JSON w pliku ./named-outputs/rolling_fcst_result/inference_output_file.
Aby uzyskać więcej informacji na temat oceny stopniowej, zobacz nasz artykuł dotyczący oceny modelu prognozowania.
Prognozowanie na dużą skalę: wiele modeli
Ważne
Ta funkcja jest obecnie w publicznej wersji zapoznawczej. Ta wersja zapoznawcza jest udostępniana bez umowy dotyczącej poziomu usług i nie zalecamy korzystania z niej w przypadku obciążeń produkcyjnych. Niektóre funkcje mogą być nieobsługiwane lub ograniczone.
Aby uzyskać więcej informacji, zobacz Uzupełniające warunki korzystania z wersji zapoznawczych platformy Microsoft Azure.
Wiele składników modeli w rozwiązaniu AutoML umożliwia równoległe trenowanie milionów modeli i zarządzanie nimi. Aby uzyskać więcej informacji na temat wielu pojęć dotyczących modeli, zobacz sekcję artykułu wiele modeli.
Konfiguracja trenowania wielu modeli
Składnik trenowania wielu modeli akceptuje plik konfiguracji formatu YAML ustawień trenowania rozwiązania AutoML. Składnik stosuje te ustawienia do każdego uruchomionego wystąpienia rozwiązania AutoML. Ten plik YAML ma taką samą specyfikację jak zadanie prognozowania oraz dodatkowe parametry partition_column_names i allow_multi_partitions.
| Parametr | Opis |
|---|---|
| partition_column_names | Nazwy kolumn w danych, które po zgrupowaniu definiują partycje danych. Składnik trenowania wielu modeli uruchamia niezależne zadanie szkoleniowe na każdej partycji. |
| allow_multi_partitions | Opcjonalna flaga umożliwiająca trenowanie jednego modelu na partycję, gdy każda partycja zawiera więcej niż jeden unikatowy szereg czasowy. Wartość domyślna to False. |
Poniższy przykład zawiera szablon konfiguracji:
$schema: https://azuremlsdk2.blob.core.windows.net/preview/0.0.1/autoMLJob.schema.json
type: automl
description: A time series forecasting job config
compute: azureml:<cluster-name>
task: forecasting
primary_metric: normalized_root_mean_squared_error
target_column_name: sales
n_cross_validations: 3
forecasting:
time_column_name: date
time_series_id_column_names: ["state", "store"]
forecast_horizon: 28
training:
blocked_training_algorithms: ["ExtremeRandomTrees"]
limits:
timeout_minutes: 15
max_trials: 10
max_concurrent_trials: 4
max_cores_per_trial: -1
trial_timeout_minutes: 15
enable_early_termination: true
partition_column_names: ["state", "store"]
allow_multi_partitions: false
W kolejnych przykładach przyjęto założenie, że konfiguracja jest przechowywana w ścieżce ./automl_settings_mm.yml.
Potok wielu modeli
Następnie zdefiniujemy funkcję fabryki, która tworzy potoki do orkiestracji wielu modeli trenowania, wnioskowania i obliczania metryk. Parametry tej funkcji fabryki zostały szczegółowo opisane w poniższej tabeli:
| Parametr | Opis |
|---|---|
| max_nodes | Liczba węzłów obliczeniowych do użycia w zadaniu trenowania |
| max_concurrency_per_node | Liczba procesów automatycznego uczenia maszynowego do uruchomienia w każdym węźle. W związku z tym całkowita współbieżność wielu zadań modeli to max_nodes * max_concurrency_per_node. |
| parallel_step_timeout_in_seconds | Wiele modeli limitu czasu składników podane w liczbie sekund. |
| retrain_failed_models | Flaga umożliwiająca ponowne trenowanie modeli, które zakończyły się niepowodzeniem. Jest to przydatne, jeśli wykonano poprzednie wiele przebiegów modeli, które spowodowały niepowodzenie zadań automatycznego uczenia maszynowego na niektórych partycjach danych. Po włączeniu tej flagi wiele modeli uruchamia tylko zadania szkoleniowe dla wcześniej nieudanych partycji. |
| forecast_mode | Tryb wnioskowania na potrzeby oceny modelu. Prawidłowe wartości to "recursive" i "rolling". Aby uzyskać więcej informacji, zobacz artykuł dotyczący oceny modelu. |
| forecast_step | Rozmiar kroku dla prognozy stopniowej. Aby uzyskać więcej informacji, zobacz artykuł dotyczący oceny modelu. |
Poniższy przykład ilustruje metodę fabryki do konstruowania wielu modeli trenowania i potoków oceny modelu:
from azure.ai.ml import MLClient
from azure.identity import DefaultAzureCredential, InteractiveBrowserCredential
# Get a credential for access to the AzureML registry
try:
credential = DefaultAzureCredential()
# Check if we can get token successfully.
credential.get_token("https://management.azure.com/.default")
except Exception as ex:
# Fall back to InteractiveBrowserCredential in case DefaultAzureCredential fails
credential = InteractiveBrowserCredential()
# Get a many models training component
mm_train_component = ml_client_registry.components.get(
name='automl_many_models_training',
version='latest'
)
# Get a many models inference component
mm_inference_component = ml_client_registry.components.get(
name='automl_many_models_inference',
version='latest'
)
# Get a component for computing evaluation metrics
compute_metrics_component = ml_client_metrics_registry.components.get(
name="compute_metrics",
label="latest"
)
@pipeline(description="AutoML Many Models Forecasting Pipeline")
def many_models_train_evaluate_factory(
train_data_input,
test_data_input,
automl_config_input,
compute_name,
max_concurrency_per_node=4,
parallel_step_timeout_in_seconds=3700,
max_nodes=4,
retrain_failed_model=False,
forecast_mode="rolling",
forecast_step=1
):
mm_train_node = mm_train_component(
raw_data=train_data_input,
automl_config=automl_config_input,
max_nodes=max_nodes,
max_concurrency_per_node=max_concurrency_per_node,
parallel_step_timeout_in_seconds=parallel_step_timeout_in_seconds,
retrain_failed_model=retrain_failed_model,
compute_name=compute_name
)
mm_inference_node = mm_inference_component(
raw_data=test_data_input,
max_nodes=max_nodes,
max_concurrency_per_node=max_concurrency_per_node,
parallel_step_timeout_in_seconds=parallel_step_timeout_in_seconds,
optional_train_metadata=mm_train_node.outputs.run_output,
forecast_mode=forecast_mode,
forecast_step=forecast_step,
compute_name=compute_name
)
compute_metrics_node = compute_metrics_component(
task="tabular-forecasting",
prediction=mm_inference_node.outputs.evaluation_data,
ground_truth=mm_inference_node.outputs.evaluation_data,
evaluation_config=mm_inference_node.outputs.evaluation_configs
)
# Return the metrics results from the rolling evaluation
return {
"metrics_result": compute_metrics_node.outputs.evaluation_result
}
Teraz skonstruujemy potok za pomocą funkcji fabryki, zakładając, że dane treningowe i testowe znajdują się odpowiednio w folderach ./data/train lokalnych i ./data/test, . Na koniec ustawiliśmy domyślne obliczenia i przesyłamy zadanie tak jak w poniższym przykładzie:
pipeline_job = many_models_train_evaluate_factory(
train_data_input=Input(
type="uri_folder",
path="./data/train"
),
test_data_input=Input(
type="uri_folder",
path="./data/test"
),
automl_config=Input(
type="uri_file",
path="./automl_settings_mm.yml"
),
compute_name="<cluster name>"
)
pipeline_job.settings.default_compute = "<cluster name>"
returned_pipeline_job = ml_client.jobs.create_or_update(
pipeline_job,
experiment_name=experiment_name,
)
ml_client.jobs.stream(returned_pipeline_job.name)
Po zakończeniu zadania metryki oceny można pobrać lokalnie przy użyciu tej samej procedury co w jednym potoku przebiegu trenowania.
Zobacz również prognozowanie zapotrzebowania za pomocą wielu notesów modeli, aby uzyskać bardziej szczegółowy przykład.
Uwaga
Wiele modeli trenowania i wnioskowania składników warunkowo partycjonuje dane zgodnie z ustawieniem partition_column_names , tak aby każda partycja znajduje się we własnym pliku. Ten proces może być bardzo powolny lub ulegać awarii, gdy dane są bardzo duże. W takim przypadku zalecamy ręczne partycjonowanie danych przed uruchomieniem wielu modeli trenowania lub wnioskowania.
Prognozowanie na dużą skalę: hierarchiczne szeregi czasowe
Ważne
Ta funkcja jest obecnie w publicznej wersji zapoznawczej. Ta wersja zapoznawcza jest udostępniana bez umowy dotyczącej poziomu usług i nie zalecamy korzystania z niej w przypadku obciążeń produkcyjnych. Niektóre funkcje mogą być nieobsługiwane lub ograniczone.
Aby uzyskać więcej informacji, zobacz Uzupełniające warunki korzystania z wersji zapoznawczych platformy Microsoft Azure.
Składniki hierarchicznych szeregów czasowych (HTS) w rozwiązaniu AutoML umożliwiają trenowanie dużej liczby modeli na danych przy użyciu struktury hierarchicznej. Aby uzyskać więcej informacji, zobacz sekcję artykułu HTS.
Konfiguracja trenowania HTS
Składnik trenowania HTS akceptuje plik konfiguracji formatu YAML ustawień trenowania automatycznego uczenia maszynowego. Składnik stosuje te ustawienia do każdego uruchomionego wystąpienia rozwiązania AutoML. Ten plik YAML ma taką samą specyfikację jak zadanie prognozowania oraz dodatkowe parametry związane z informacjami o hierarchii:
| Parametr | Opis |
|---|---|
| hierarchy_column_names | Lista nazw kolumn w danych definiujących hierarchiczną strukturę danych. Kolejność kolumn na tej liście określa poziomy hierarchii; stopień agregacji zmniejsza się wraz z indeksem listy. Oznacza to, że ostatnia kolumna na liście definiuje poziom liścia (najbardziej rozagregowany) hierarchii. |
| hierarchy_training_level | Poziom hierarchii do użycia na potrzeby trenowania modelu prognozy. |
Poniżej przedstawiono przykładową konfigurację:
$schema: https://azuremlsdk2.blob.core.windows.net/preview/0.0.1/autoMLJob.schema.json
type: automl
description: A time series forecasting job config
compute: azureml:cluster-name
task: forecasting
primary_metric: normalized_root_mean_squared_error
log_verbosity: info
target_column_name: sales
n_cross_validations: 3
forecasting:
time_column_name: "date"
time_series_id_column_names: ["state", "store", "SKU"]
forecast_horizon: 28
training:
blocked_training_algorithms: ["ExtremeRandomTrees"]
limits:
timeout_minutes: 15
max_trials: 10
max_concurrent_trials: 4
max_cores_per_trial: -1
trial_timeout_minutes: 15
enable_early_termination: true
hierarchy_column_names: ["state", "store", "SKU"]
hierarchy_training_level: "store"
W kolejnych przykładach przyjęto założenie, że konfiguracja jest przechowywana w ścieżce ./automl_settings_hts.yml.
Potok HTS
Następnie zdefiniujemy funkcję fabryki, która tworzy potoki do orkiestracji trenowania, wnioskowania i obliczeń metryk HTS. Parametry tej funkcji fabryki zostały szczegółowo opisane w poniższej tabeli:
| Parametr | Opis |
|---|---|
| forecast_level | Poziom hierarchii do pobierania prognoz dla |
| allocation_method | Metoda alokacji do użycia, gdy prognozy są rozagregowane. Prawidłowe wartości to "proportions_of_historical_average" i "average_historical_proportions". |
| max_nodes | Liczba węzłów obliczeniowych do użycia w zadaniu trenowania |
| max_concurrency_per_node | Liczba procesów automatycznego uczenia maszynowego do uruchomienia w każdym węźle. W związku z tym łączna współbieżność zadania HTS to max_nodes * max_concurrency_per_node. |
| parallel_step_timeout_in_seconds | Wiele modeli limitu czasu składników podane w liczbie sekund. |
| forecast_mode | Tryb wnioskowania na potrzeby oceny modelu. Prawidłowe wartości to "recursive" i "rolling". Aby uzyskać więcej informacji, zobacz artykuł dotyczący oceny modelu. |
| forecast_step | Rozmiar kroku dla prognozy stopniowej. Aby uzyskać więcej informacji, zobacz artykuł dotyczący oceny modelu. |
from azure.ai.ml import MLClient
from azure.identity import DefaultAzureCredential, InteractiveBrowserCredential
# Get a credential for access to the AzureML registry
try:
credential = DefaultAzureCredential()
# Check if we can get token successfully.
credential.get_token("https://management.azure.com/.default")
except Exception as ex:
# Fall back to InteractiveBrowserCredential in case DefaultAzureCredential fails
credential = InteractiveBrowserCredential()
# Get a HTS training component
hts_train_component = ml_client_registry.components.get(
name='automl_hts_training',
version='latest'
)
# Get a HTS inference component
hts_inference_component = ml_client_registry.components.get(
name='automl_hts_inference',
version='latest'
)
# Get a component for computing evaluation metrics
compute_metrics_component = ml_client_metrics_registry.components.get(
name="compute_metrics",
label="latest"
)
@pipeline(description="AutoML HTS Forecasting Pipeline")
def hts_train_evaluate_factory(
train_data_input,
test_data_input,
automl_config_input,
max_concurrency_per_node=4,
parallel_step_timeout_in_seconds=3700,
max_nodes=4,
forecast_mode="rolling",
forecast_step=1,
forecast_level="SKU",
allocation_method='proportions_of_historical_average'
):
hts_train = hts_train_component(
raw_data=train_data_input,
automl_config=automl_config_input,
max_concurrency_per_node=max_concurrency_per_node,
parallel_step_timeout_in_seconds=parallel_step_timeout_in_seconds,
max_nodes=max_nodes
)
hts_inference = hts_inference_component(
raw_data=test_data_input,
max_nodes=max_nodes,
max_concurrency_per_node=max_concurrency_per_node,
parallel_step_timeout_in_seconds=parallel_step_timeout_in_seconds,
optional_train_metadata=hts_train.outputs.run_output,
forecast_level=forecast_level,
allocation_method=allocation_method,
forecast_mode=forecast_mode,
forecast_step=forecast_step
)
compute_metrics_node = compute_metrics_component(
task="tabular-forecasting",
prediction=hts_inference.outputs.evaluation_data,
ground_truth=hts_inference.outputs.evaluation_data,
evaluation_config=hts_inference.outputs.evaluation_configs
)
# Return the metrics results from the rolling evaluation
return {
"metrics_result": compute_metrics_node.outputs.evaluation_result
}
Teraz skonstruujemy potok za pomocą funkcji fabryki, zakładając, że dane treningowe i testowe znajdują się odpowiednio w folderach ./data/train lokalnych i ./data/test, . Na koniec ustawiliśmy domyślne obliczenia i przesyłamy zadanie tak jak w poniższym przykładzie:
pipeline_job = hts_train_evaluate_factory(
train_data_input=Input(
type="uri_folder",
path="./data/train"
),
test_data_input=Input(
type="uri_folder",
path="./data/test"
),
automl_config=Input(
type="uri_file",
path="./automl_settings_hts.yml"
)
)
pipeline_job.settings.default_compute = "cluster-name"
returned_pipeline_job = ml_client.jobs.create_or_update(
pipeline_job,
experiment_name=experiment_name,
)
ml_client.jobs.stream(returned_pipeline_job.name)
Po zakończeniu zadania metryki oceny można pobrać lokalnie przy użyciu tej samej procedury co w jednym potoku przebiegu trenowania.
Zobacz również prognozowanie zapotrzebowania za pomocą hierarchicznego notesu szeregów czasowych, aby uzyskać bardziej szczegółowy przykład.
Uwaga
Składniki trenowania i wnioskowania HTS warunkowo partycjonować dane zgodnie z ustawieniem hierarchy_column_names , tak aby każda partycja znajduje się we własnym pliku. Ten proces może być bardzo powolny lub ulegać awarii, gdy dane są bardzo duże. W takim przypadku zalecamy ręczne partycjonowanie danych przed uruchomieniem trenowania lub wnioskowania HTS.
Prognozowanie na dużą skalę: trenowanie rozproszonej sieci rozproszonej sieci rozproszonej
- Aby dowiedzieć się, jak działa trenowanie rozproszone na potrzeby zadań prognozowania, zobacz nasz artykuł dotyczący prognozowania na dużą skalę.
- Zobacz naszą sekcję dotyczącą trenowania rozproszonego konfiguracji dla danych tabelarycznych, aby zapoznać się z przykładami kodu.
Przykładowe notesy
Zobacz przykładowe notesy prognozowania, aby uzyskać szczegółowe przykłady kodu zaawansowanej konfiguracji prognozowania obejmujące następujące elementy:
- Przykłady potoków prognozowania zapotrzebowania
- Modele uczenia głębokiego
- Wykrywanie świąt i dobór cech
- Ręczna konfiguracja funkcji agregacji opóźnień i okien kroczenia
Następne kroki
- Dowiedz się więcej na temat wdrażania modelu AutoML w punkcie końcowym online.
- Dowiedz się więcej o możliwości interpretowania: wyjaśnienia modelu w zautomatyzowanym uczeniu maszynowym (wersja zapoznawcza).
- Dowiedz się, jak rozwiązanie AutoML tworzy modele prognozowania.
- Dowiedz się więcej o prognozowaniu na dużą skalę.
- Dowiedz się, jak skonfigurować rozwiązanie AutoML dla różnych scenariuszy prognozowania.
- Dowiedz się więcej o wnioskowaniu i ocenie modeli prognozowania.