Konfigurowanie środowiska programistycznego przy użyciu usługi Azure Databricks i rozwiązania AutoML w usłudze Azure Machine Learning
Dowiedz się, jak skonfigurować środowisko programistyczne w usłudze Azure Machine Learning, które korzysta z usługi Azure Databricks i zautomatyzowanego uczenia maszynowego.
Usługa Azure Databricks jest idealna do uruchamiania przepływów pracy uczenia maszynowego na dużą skalę na skalowalnej platformie Apache Spark w chmurze platformy Azure. Zapewnia środowisko oparte na notesie współpracy z klastrem obliczeniowym opartym na procesorze CPU lub procesorze GPU.
Aby uzyskać informacje na temat innych środowisk programistycznych uczenia maszynowego, zobacz Konfigurowanie środowiska projektowego języka Python.
Wymaganie wstępne
Obszar roboczy usługi Azure Machine Learning. Aby je utworzyć, wykonaj kroki opisane w artykule Tworzenie zasobów obszaru roboczego .
Usługa Azure Databricks z usługą Azure Machine Learning i rozwiązaniem AutoML
Usługa Azure Databricks integruje się z usługą Azure Machine Learning i jej możliwościami rozwiązania AutoML.
Możesz użyć usługi Azure Databricks:
- Aby wytrenować model przy użyciu biblioteki MLlib platformy Spark i wdrożyć model w usłudze ACI/AKS.
- Dzięki możliwościom zautomatyzowanego uczenia maszynowego przy użyciu zestawu Azure Machine Learning SDK.
- Jako obiekt docelowy obliczeniowy z potoku usługi Azure Machine Learning.
Konfigurowanie klastra usługi Databricks
Utwórz klaster usługi Databricks. Niektóre ustawienia mają zastosowanie tylko w przypadku zainstalowania zestawu SDK na potrzeby zautomatyzowanego uczenia maszynowego w usłudze Databricks.
Utworzenie klastra trwa kilka minut.
Użyj następujących ustawień:
| Ustawienie | Dotyczy | Wartość |
|---|---|---|
| Nazwa klastra | zawsze | yourclustername |
| Wersja środowiska uruchomieniowego usługi Databricks | zawsze | 9.1 LTS |
| Wersja języka Python | zawsze | 3 |
| Typ procesu roboczego (określa maksymalną liczbę współbieżnych iteracji) |
Zautomatyzowane uczenie maszynowe Tylko |
Preferowana maszyna wirtualna zoptymalizowana pod kątem pamięci |
| Pracowników | zawsze | 2 lub nowsze |
| Włączanie skalowania automatycznego | Zautomatyzowane uczenie maszynowe Tylko |
Usuń zaznaczenie |
Przed kontynuowaniem poczekaj na uruchomienie klastra.
Dodawanie zestawu SDK usługi Azure Machine Learning do usługi Databricks
Po uruchomieniu klastra utwórz bibliotekę , aby dołączyć odpowiedni pakiet zestawu SDK usługi Azure Machine Learning do klastra.
Aby użyć zautomatyzowanego uczenia maszynowego, przejdź do sekcji Dodawanie zestawu AZURE Machine Learning SDK z rozwiązaniem AutoML.
Kliknij prawym przyciskiem myszy bieżący folder Obszaru roboczego, w którym chcesz przechowywać bibliotekę. Wybierz pozycję Utwórz>bibliotekę.
Porada
Jeśli masz starą wersję zestawu SDK, usuń jej zaznaczenie z zainstalowanych bibliotek klastra i przejdź do kosza. Zainstaluj nową wersję zestawu SDK i uruchom ponownie klaster. Jeśli po ponownym uruchomieniu wystąpi problem, odłącz i ponownie dołącz klaster.
Wybierz następującą opcję (nie są obsługiwane żadne inne instalacje zestawu SDK)
Dodatki pakietu SDK Element źródłowy Nazwa PyPi W przypadku usługi Databricks Przekazywanie języka Python Egg lub PyPI azureml-sdk[databricks] Ostrzeżenie
Nie można zainstalować żadnych innych dodatków zestawu SDK. Wybierz tylko opcję [
databricks] .- Nie wybieraj opcji Dołącz automatycznie do wszystkich klastrów.
- Wybierz pozycję Dołącz obok nazwy klastra.
Monitoruj błędy, dopóki stan nie zmieni się na Dołączony, co może potrwać kilka minut. Jeśli ten krok zakończy się niepowodzeniem:
Spróbuj ponownie uruchomić klaster, wykonując następujące czynności:
- W okienku po lewej stronie wybierz pozycję Klastry.
- W tabeli wybierz nazwę klastra.
- Na karcie Biblioteki wybierz pozycję Uruchom ponownie.
Pomyślna instalacja wygląda następująco:
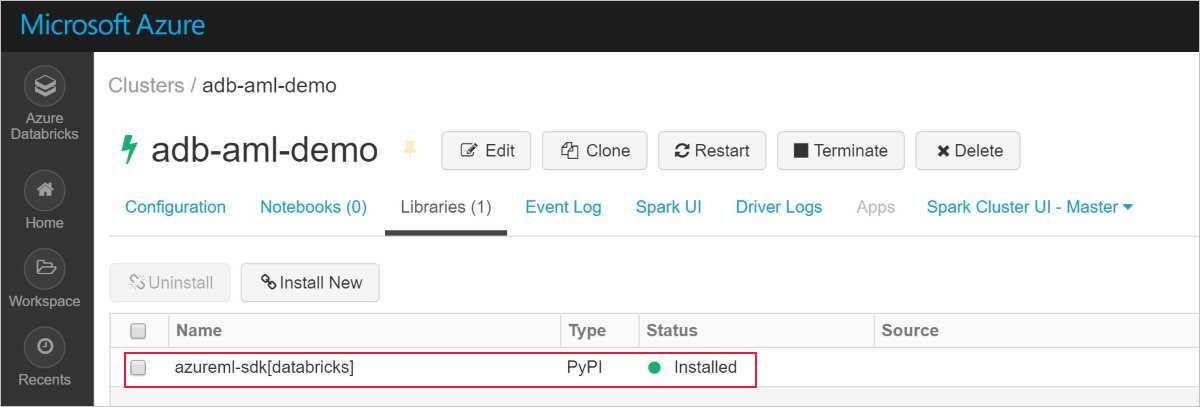
Dodawanie zestawu SDK usługi Azure Machine Learning z rozwiązaniem AutoML do usługi Databricks
Jeśli klaster został utworzony za pomocą środowiska Databricks Runtime 7.3 LTS (a nie uczenia maszynowego), uruchom następujące polecenie w pierwszej komórce notesu, aby zainstalować zestaw SDK usługi Azure Machine Learning.
%pip install --upgrade --force-reinstall -r https://aka.ms/automl_linux_requirements.txt
Ustawienia konfiguracji automatycznego uczenia maszynowego
W konfiguracji rozwiązania AutoML podczas korzystania z usługi Azure Databricks dodaj następujące parametry:
max_concurrent_iterationsjest oparta na liczbie węzłów roboczych w klastrze.spark_context=scjest oparty na domyślnym kontekście platformy Spark.
Notesy uczenia maszynowego, które współpracują z usługą Azure Databricks
Wypróbuj:
Chociaż dostępnych jest wiele przykładowych notesów, tylko te przykładowe notesy współpracują z usługą Azure Databricks.
Zaimportuj te przykłady bezpośrednio z obszaru roboczego. Zobacz poniżej:
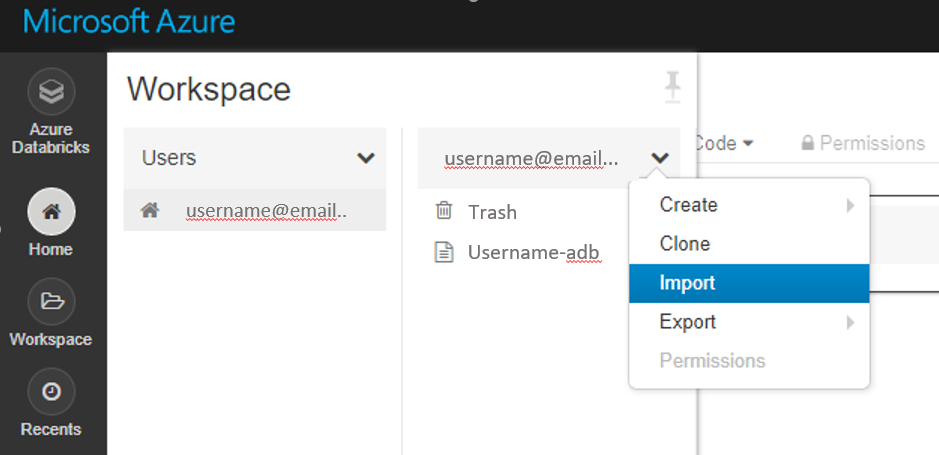
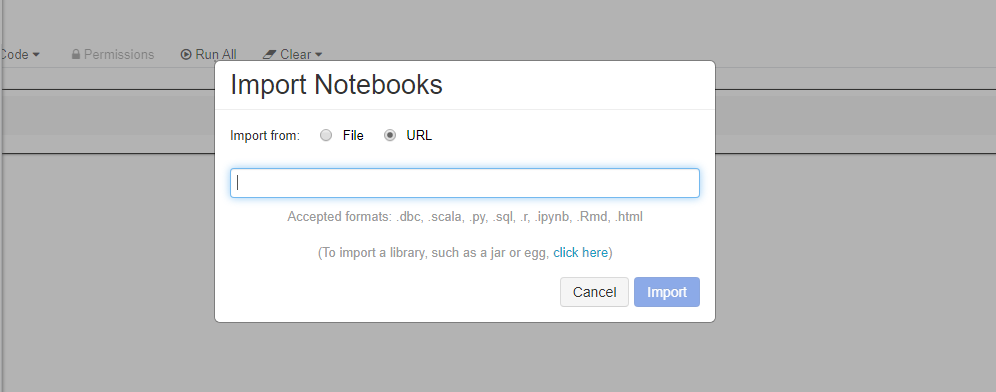
Dowiedz się, jak utworzyć potok przy użyciu usługi Databricks jako zasobów obliczeniowych trenowania.
Rozwiązywanie problemów
Usługa Databricks anuluje przebieg zautomatyzowanego uczenia maszynowego: jeśli używasz funkcji zautomatyzowanego uczenia maszynowego w usłudze Azure Databricks, aby anulować przebieg i uruchomić nowy przebieg eksperymentu, uruchom ponownie klaster usługi Azure Databricks.
Iteracji usługi Databricks >10 dla zautomatyzowanego uczenia maszynowego: w ustawieniach zautomatyzowanego uczenia maszynowego, jeśli masz więcej niż 10 iteracji, ustaw wartość na
show_outputFalsepo przesłaniu przebiegu.Widżet usługi Databricks dla zestawu Azure Machine Learning SDK i zautomatyzowanego uczenia maszynowego: widżet zestawu SDK usługi Azure Machine Learning nie jest obsługiwany w notesie usługi Databricks, ponieważ notesy nie mogą analizować widżetów HTML. Widżet można wyświetlić w portalu przy użyciu tego kodu języka Python w komórce notesu usługi Azure Databricks:
displayHTML("<a href={} target='_blank'>Azure Portal: {}</a>".format(local_run.get_portal_url(), local_run.id))Błąd podczas instalowania pakietów
Instalacja zestawu SDK usługi Azure Machine Learning kończy się niepowodzeniem w usłudze Azure Databricks po zainstalowaniu większej liczby pakietów. Niektóre pakiety, takie jak
psutil, mogą powodować konflikty. Aby uniknąć błędów instalacji, zainstaluj pakiety przez zamrożenie wersji biblioteki. Ten problem jest związany z usługą Databricks, a nie z zestawem AZURE Machine Learning SDK. Ten problem może wystąpić również z innymi bibliotekami. Przykład:psutil cryptography==1.5 pyopenssl==16.0.0 ipython==2.2.0Alternatywnie możesz użyć skryptów inicjowania, jeśli występują problemy z instalacją bibliotek języka Python. To podejście nie jest oficjalnie obsługiwane. Aby uzyskać więcej informacji, zobacz Skrypty inicjowania o zakresie klastra.
Błąd importu: nie można zaimportować nazwy
Timedeltazpandas._libs.tslibs: Jeśli ten błąd zostanie wyświetlony podczas korzystania z zautomatyzowanego uczenia maszynowego, uruchom dwa następujące wiersze w notesie:%sh rm -rf /databricks/python/lib/python3.7/site-packages/pandas-0.23.4.dist-info /databricks/python/lib/python3.7/site-packages/pandas %sh /databricks/python/bin/pip install pandas==0.23.4Błąd importu: Brak modułu o nazwie "pandas.core.indexes": Jeśli ten błąd zostanie wyświetlony podczas korzystania z zautomatyzowanego uczenia maszynowego:
Uruchom to polecenie, aby zainstalować dwa pakiety w klastrze usługi Azure Databricks:
scikit-learn==0.19.1 pandas==0.22.0Odłącz, a następnie ponownie dołącz klaster do notesu.
Jeśli te kroki nie rozwiążą problemu, spróbuj ponownie uruchomić klaster.
FailToSendFeather: Jeśli podczas odczytywania danych w klastrze usługi Azure Databricks wystąpi
FailToSendFeatherbłąd, zapoznaj się z następującymi rozwiązaniami:- Uaktualnij
azureml-sdk[automl]pakiet do najnowszej wersji. - Dodaj
azureml-dataprepwersję 1.1.8 lub nowszą. - Dodaj
pyarrowwersję 0.11 lub nowszą.
- Uaktualnij
Następne kroki
- Trenowanie i wdrażanie modelu w usłudze Azure Machine Learning przy użyciu zestawu danych MNIST.
- Zobacz dokumentację zestawu Azure Machine Learning SDK dla języka Python.