Publikowanie i śledzenie potoków uczenia maszynowego
DOTYCZY: Zestaw SDK języka Python azureml w wersji 1
Zestaw SDK języka Python azureml w wersji 1
W tym artykule pokazano, jak udostępnić potok uczenia maszynowego współpracownikom lub klientom.
Potoki uczenia maszynowego to przepływy pracy wielokrotnego użytku dla zadań uczenia maszynowego. Jedną z zalet potoków jest zwiększona współpraca. Potoki wersji umożliwiają również klientom korzystanie z bieżącego modelu podczas pracy nad nową wersją.
Wymagania wstępne
Tworzenie obszaru roboczego usługi Azure Machine Edukacja do przechowywania wszystkich zasobów potoku
Skonfiguruj środowisko programistyczne, aby zainstalować zestaw SDK usługi Azure Machine Edukacja lub użyć wystąpienia obliczeniowego usługi Azure Machine Edukacja z już zainstalowanym zestawem SDK
Utwórz i uruchom potok uczenia maszynowego, taki jak następujący samouczek: tworzenie potoku usługi Azure Machine Edukacja na potrzeby oceniania wsadowego. Aby uzyskać inne opcje, zobacz Tworzenie i uruchamianie potoków uczenia maszynowego za pomocą zestawu SDK usługi Azure Machine Edukacja
Publikowanie potoku
Po uruchomieniu potoku możesz opublikować potok, aby był uruchamiany z różnymi danymi wejściowymi. Aby punkt końcowy REST już opublikowanego potoku akceptował parametry, należy skonfigurować potok tak, aby używał PipelineParameter obiektów dla argumentów, które będą się różnić.
Aby utworzyć parametr potoku, użyj obiektu PipelineParameter z wartością domyślną.
from azureml.pipeline.core.graph import PipelineParameter pipeline_param = PipelineParameter( name="pipeline_arg", default_value=10)Dodaj ten
PipelineParameterobiekt jako parametr do dowolnego z kroków potoku w następujący sposób:compareStep = PythonScriptStep( script_name="compare.py", arguments=["--comp_data1", comp_data1, "--comp_data2", comp_data2, "--output_data", out_data3, "--param1", pipeline_param], inputs=[ comp_data1, comp_data2], outputs=[out_data3], compute_target=compute_target, source_directory=project_folder)Opublikuj ten potok, który będzie akceptował parametr podczas wywoływania.
published_pipeline1 = pipeline_run1.publish_pipeline( name="My_Published_Pipeline", description="My Published Pipeline Description", version="1.0")Po opublikowaniu potoku możesz go zaewidencjonować w interfejsie użytkownika. Identyfikator potoku to unikatowy identyfikator opublikowanego potoku.
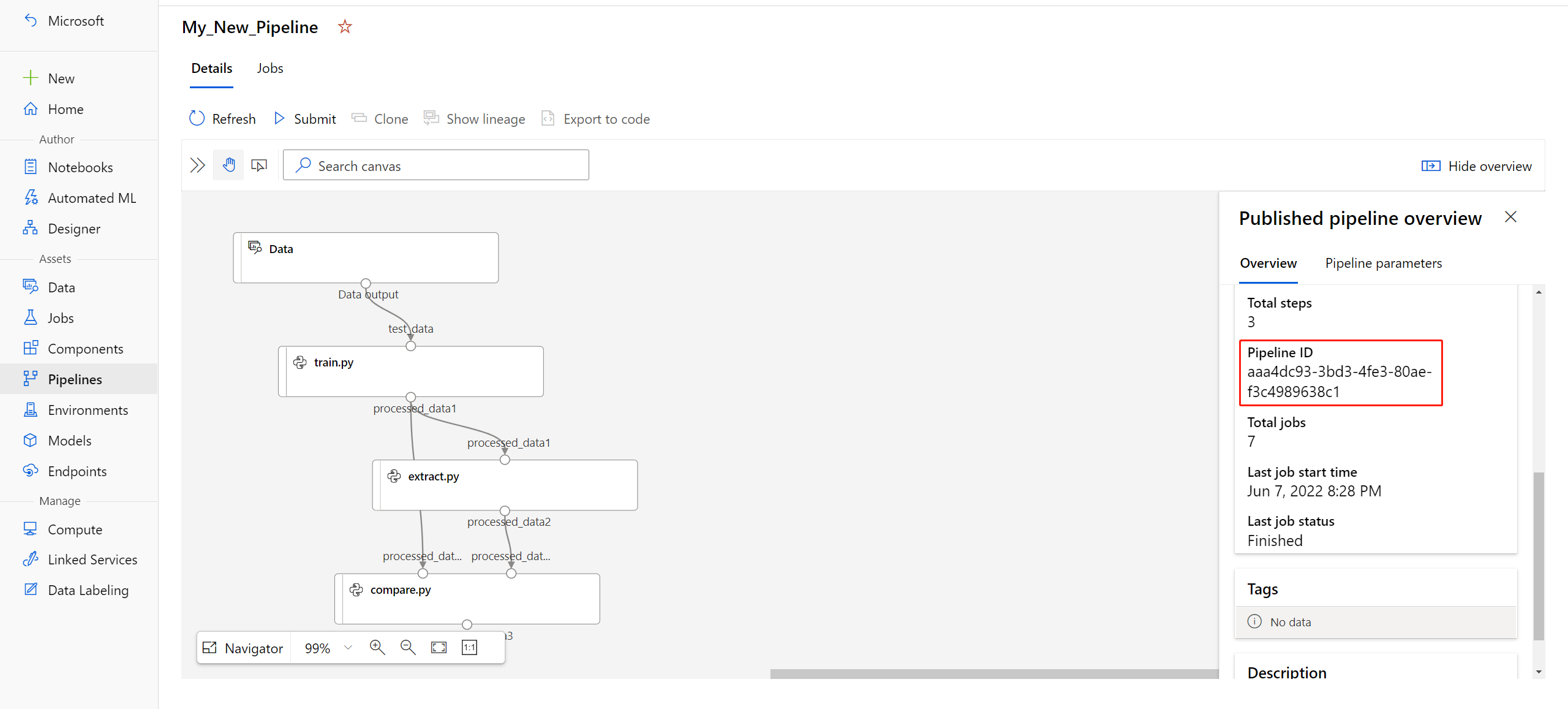

Uruchamianie opublikowanego potoku
Wszystkie opublikowane potoki mają punkt końcowy REST. Za pomocą punktu końcowego potoku można wyzwolić uruchomienie potoku z dowolnego systemu zewnętrznego, w tym klientów innych niż Python. Ten punkt końcowy umożliwia "zarządzaną powtarzalność" w scenariuszach oceniania wsadowego i ponownego trenowania.
Ważne
Jeśli używasz kontroli dostępu opartej na rolach (RBAC) platformy Azure do zarządzania dostępem do potoku, ustaw uprawnienia dla scenariusza potoku (trenowanie lub ocenianie).
Aby wywołać przebieg poprzedniego potoku, potrzebujesz tokenu nagłówka uwierzytelniania entra firmy Microsoft. Uzyskiwanie takiego tokenu zostało opisane w dokumentacji klasy AzureCliAuthentication i w notesie Uwierzytelnianie w usłudze Azure Machine Edukacja.
from azureml.pipeline.core import PublishedPipeline
import requests
response = requests.post(published_pipeline1.endpoint,
headers=aad_token,
json={"ExperimentName": "My_Pipeline",
"ParameterAssignments": {"pipeline_arg": 20}})
Argument json żądania POST musi zawierać dla ParameterAssignments klucza słownik zawierający parametry potoku i ich wartości. Ponadto json argument może zawierać następujące klucze:
| Key | opis |
|---|---|
ExperimentName |
Nazwa eksperymentu skojarzonego z tym punktem końcowym |
Description |
Dowolny tekst opisujący punkt końcowy |
Tags |
Pary freeform klucz-wartość, których można użyć do etykietowania i dodawania adnotacji do żądań |
DataSetDefinitionValueAssignments |
Słownik używany do zmieniania zestawów danych bez ponownego trenowania (zobacz dyskusję poniżej) |
DataPathAssignments |
Słownik używany do zmieniania ścieżek danych bez ponownego trenowania (zobacz dyskusję poniżej) |
Uruchamianie opublikowanego potoku przy użyciu języka C#
Poniższy kod pokazuje, jak wywołać potok asynchronicznie z języka C#. Fragment fragmentu kodu pokazuje tylko strukturę wywołań i nie jest częścią przykładu firmy Microsoft. Nie pokazuje kompletnych klas ani obsługi błędów.
[DataContract]
public class SubmitPipelineRunRequest
{
[DataMember]
public string ExperimentName { get; set; }
[DataMember]
public string Description { get; set; }
[DataMember(IsRequired = false)]
public IDictionary<string, string> ParameterAssignments { get; set; }
}
// ... in its own class and method ...
const string RestEndpoint = "your-pipeline-endpoint";
using (HttpClient client = new HttpClient())
{
var submitPipelineRunRequest = new SubmitPipelineRunRequest()
{
ExperimentName = "YourExperimentName",
Description = "Asynchronous C# REST api call",
ParameterAssignments = new Dictionary<string, string>
{
{
// Replace with your pipeline parameter keys and values
"your-pipeline-parameter", "default-value"
}
}
};
string auth_key = "your-auth-key";
client.DefaultRequestHeaders.Authorization = new AuthenticationHeaderValue("Bearer", auth_key);
// submit the job
var requestPayload = JsonConvert.SerializeObject(submitPipelineRunRequest);
var httpContent = new StringContent(requestPayload, Encoding.UTF8, "application/json");
var submitResponse = await client.PostAsync(RestEndpoint, httpContent).ConfigureAwait(false);
if (!submitResponse.IsSuccessStatusCode)
{
await WriteFailedResponse(submitResponse); // ... method not shown ...
return;
}
var result = await submitResponse.Content.ReadAsStringAsync().ConfigureAwait(false);
var obj = JObject.Parse(result);
// ... use `obj` dictionary to access results
}
Uruchamianie opublikowanego potoku przy użyciu języka Java
Poniższy kod przedstawia wywołanie potoku wymagającego uwierzytelniania (zobacz Konfigurowanie uwierzytelniania dla usługi Azure Machine Edukacja zasobów i przepływów pracy). Jeśli potok jest wdrażany publicznie, nie potrzebujesz wywołań, które generują authKeyelement . Fragment częściowego fragmentu kodu nie pokazuje klas Języka Java i standardowego przetwarzania wyjątków. Kod używa Optional.flatMap do łączenia w łańcuchy funkcji, które mogą zwracać pusty Optionalelement . Użycie flatMap skrócić i wyjaśnić kod, ale należy pamiętać, że getRequestBody() połyka wyjątki.
import java.net.URI;
import java.net.http.HttpClient;
import java.net.http.HttpRequest;
import java.net.http.HttpResponse;
import java.util.Optional;
// JSON library
import com.google.gson.Gson;
String scoringUri = "scoring-endpoint";
String tenantId = "your-tenant-id";
String clientId = "your-client-id";
String clientSecret = "your-client-secret";
String resourceManagerUrl = "https://management.azure.com";
String dataToBeScored = "{ \"ExperimentName\" : \"My_Pipeline\", \"ParameterAssignments\" : { \"pipeline_arg\" : \"20\" }}";
HttpClient client = HttpClient.newBuilder().build();
Gson gson = new Gson();
HttpRequest tokenAuthenticationRequest = tokenAuthenticationRequest(tenantId, clientId, clientSecret, resourceManagerUrl);
Optional<String> authBody = getRequestBody(client, tokenAuthenticationRequest);
Optional<String> authKey = authBody.flatMap(body -> Optional.of(gson.fromJson(body, AuthenticationBody.class).access_token);;
Optional<HttpRequest> scoringRequest = authKey.flatMap(key -> Optional.of(scoringRequest(key, scoringUri, dataToBeScored)));
Optional<String> scoringResult = scoringRequest.flatMap(req -> getRequestBody(client, req));
// ... etc (`scoringResult.orElse()`) ...
static HttpRequest tokenAuthenticationRequest(String tenantId, String clientId, String clientSecret, String resourceManagerUrl)
{
String authUrl = String.format("https://login.microsoftonline.com/%s/oauth2/token", tenantId);
String clientIdParam = String.format("client_id=%s", clientId);
String resourceParam = String.format("resource=%s", resourceManagerUrl);
String clientSecretParam = String.format("client_secret=%s", clientSecret);
String bodyString = String.format("grant_type=client_credentials&%s&%s&%s", clientIdParam, resourceParam, clientSecretParam);
HttpRequest request = HttpRequest.newBuilder()
.uri(URI.create(authUrl))
.POST(HttpRequest.BodyPublishers.ofString(bodyString))
.build();
return request;
}
static HttpRequest scoringRequest(String authKey, String scoringUri, String dataToBeScored)
{
HttpRequest request = HttpRequest.newBuilder()
.uri(URI.create(scoringUri))
.header("Authorization", String.format("Token %s", authKey))
.POST(HttpRequest.BodyPublishers.ofString(dataToBeScored))
.build();
return request;
}
static Optional<String> getRequestBody(HttpClient client, HttpRequest request) {
try {
HttpResponse<String> response = client.send(request, HttpResponse.BodyHandlers.ofString());
if (response.statusCode() != 200) {
System.out.println(String.format("Unexpected server response %d", response.statusCode()));
return Optional.empty();
}
return Optional.of(response.body());
}catch(Exception x)
{
System.out.println(x.toString());
return Optional.empty();
}
}
class AuthenticationBody {
String access_token;
String token_type;
int expires_in;
String scope;
String refresh_token;
String id_token;
AuthenticationBody() {}
}
Zmienianie zestawów danych i ścieżek danych bez ponownego trenowania
Możesz trenować i wnioskować na różnych zestawach danych i ścieżkach danych. Na przykład możesz chcieć trenować na mniejszym zestawie danych, ale wnioskować o kompletnym zestawie danych. Zestawy danych można przełączać przy użyciu DataSetDefinitionValueAssignments klucza w argumencie żądania json . Ścieżki danych można przełączać za pomocą polecenia DataPathAssignments. Technika obu tych metod jest podobna:
W skrypsie definicji potoku utwórz element
PipelineParameterdla zestawu danych. Utwórz elementDatasetConsumptionConfiglubDataPathna podstawie elementuPipelineParameter:tabular_dataset = Dataset.Tabular.from_delimited_files('https://dprepdata.blob.core.windows.net/demo/Titanic.csv') tabular_pipeline_param = PipelineParameter(name="tabular_ds_param", default_value=tabular_dataset) tabular_ds_consumption = DatasetConsumptionConfig("tabular_dataset", tabular_pipeline_param)W skryscie uczenia maszynowego uzyskaj dostęp do dynamicznie określonego zestawu danych przy użyciu polecenia
Run.get_context().input_datasets:from azureml.core import Run input_tabular_ds = Run.get_context().input_datasets['tabular_dataset'] dataframe = input_tabular_ds.to_pandas_dataframe() # ... etc ...Zwróć uwagę, że skrypt uczenia maszynowego uzyskuje dostęp do wartości określonej dla
DatasetConsumptionConfigwartości (tabular_dataset), a nie wartościPipelineParameter(tabular_ds_param).W skrypsie definicji potoku ustaw
DatasetConsumptionConfigparametr jako parametr na wartośćPipelineScriptStep:train_step = PythonScriptStep( name="train_step", script_name="train_with_dataset.py", arguments=["--param1", tabular_ds_consumption], inputs=[tabular_ds_consumption], compute_target=compute_target, source_directory=source_directory) pipeline = Pipeline(workspace=ws, steps=[train_step])Aby dynamicznie przełączać zestawy danych w wywołaniu REST wnioskowania, użyj polecenia
DataSetDefinitionValueAssignments:tabular_ds1 = Dataset.Tabular.from_delimited_files('path_to_training_dataset') tabular_ds2 = Dataset.Tabular.from_delimited_files('path_to_inference_dataset') ds1_id = tabular_ds1.id d22_id = tabular_ds2.id response = requests.post(rest_endpoint, headers=aad_token, json={ "ExperimentName": "MyRestPipeline", "DataSetDefinitionValueAssignments": { "tabular_ds_param": { "SavedDataSetReference": {"Id": ds1_id #or ds2_id }}}})
Notesy Showcasing Dataset and PipelineParameter i Showcasing DataPath i PipelineParameter zawierają kompletne przykłady tej techniki.
Tworzenie punktu końcowego potoku w wersji
Punkt końcowy potoku można utworzyć z wieloma opublikowanymi potokami. Ta technika zapewnia stały punkt końcowy REST podczas iteracji i aktualizowania potoków uczenia maszynowego.
from azureml.pipeline.core import PipelineEndpoint
published_pipeline = PublishedPipeline.get(workspace=ws, id="My_Published_Pipeline_id")
pipeline_endpoint = PipelineEndpoint.publish(workspace=ws, name="PipelineEndpointTest",
pipeline=published_pipeline, description="Test description Notebook")
Przesyłanie zadania do punktu końcowego potoku
Zadanie można przesłać do domyślnej wersji punktu końcowego potoku:
pipeline_endpoint_by_name = PipelineEndpoint.get(workspace=ws, name="PipelineEndpointTest")
run_id = pipeline_endpoint_by_name.submit("PipelineEndpointExperiment")
print(run_id)
Zadanie można również przesłać do określonej wersji:
run_id = pipeline_endpoint_by_name.submit("PipelineEndpointExperiment", pipeline_version="0")
print(run_id)
Można to zrobić przy użyciu interfejsu API REST:
rest_endpoint = pipeline_endpoint_by_name.endpoint
response = requests.post(rest_endpoint,
headers=aad_token,
json={"ExperimentName": "PipelineEndpointExperiment",
"RunSource": "API",
"ParameterAssignments": {"1": "united", "2":"city"}})
Używanie opublikowanych potoków w programie Studio
Możesz również uruchomić opublikowany potok z poziomu programu Studio:
Zaloguj się do usługi Azure Machine Edukacja Studio.
Po lewej stronie wybierz pozycję Punkty końcowe.
W górnej części wybierz pozycję Punkty końcowe potoku.
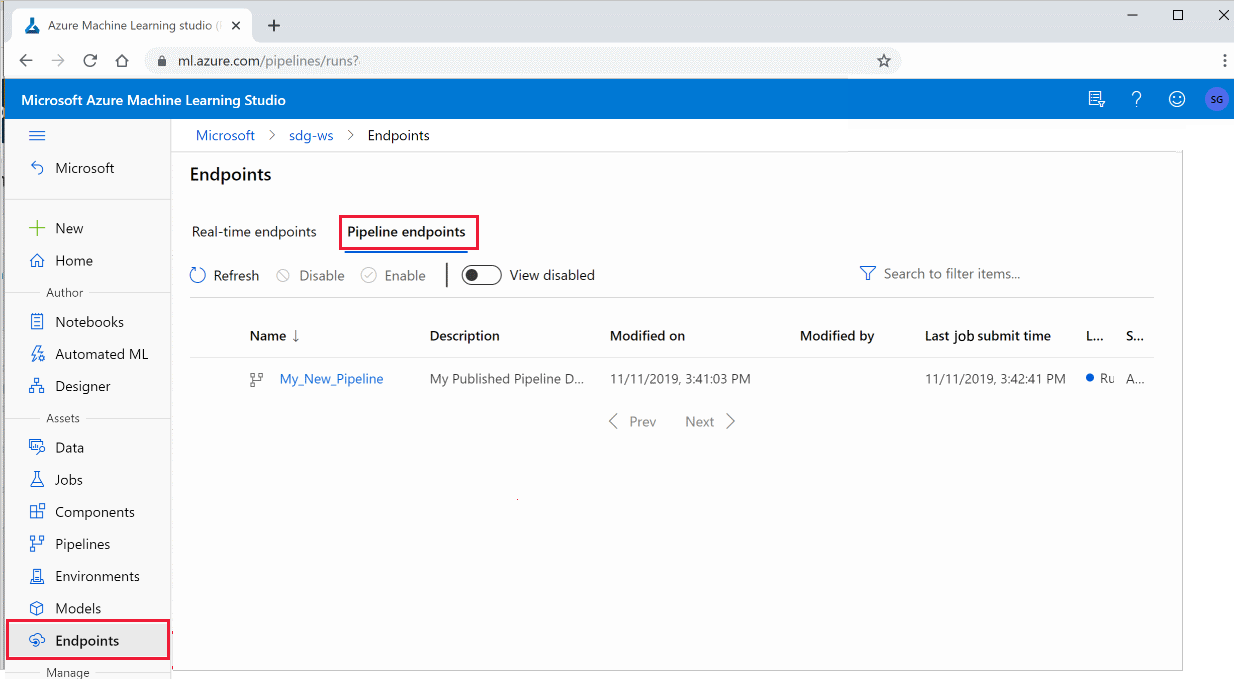
Wybierz określony potok do uruchamiania, korzystania lub przeglądania wyników poprzednich przebiegów punktu końcowego potoku.
Wyłączanie opublikowanego potoku
Aby ukryć potok z listy opublikowanych potoków, należy go wyłączyć w programie Studio lub w zestawie SDK:
# Get the pipeline by using its ID from Azure Machine Learning studio
p = PublishedPipeline.get(ws, id="068f4885-7088-424b-8ce2-eeb9ba5381a6")
p.disable()
Można ją ponownie włączyć za pomocą polecenia p.enable(). Aby uzyskać więcej informacji, zobacz PublishedPipeline class reference (Dokumentacja klasy PublishedPipeline).
Następne kroki
- Użyj tych notesów Jupyter w usłudze GitHub , aby dokładniej eksplorować potoki uczenia maszynowego.
- Zobacz pomoc dotyczącą zestawu SDK dla pakietu azureml-pipelines-core i pakietu azureml-pipelines-steps .
- Zapoznaj się z instrukcjami, aby uzyskać porady dotyczące debugowania i rozwiązywania problemów z potokami.