Konfigurowanie trenowania automatycznego uczenia maszynowego bez kodu dla danych tabelarycznych przy użyciu interfejsu użytkownika programu Studio
Z tego artykułu dowiesz się, jak skonfigurować zadania trenowania automatycznego uczenia maszynowego bez jednego wiersza kodu przy użyciu usługi Azure Machine Edukacja zautomatyzowanego uczenia maszynowego w usłudze Azure Machine Edukacja Studio.
Zautomatyzowane uczenie maszynowe, AutoML, to proces, w którym wybierany jest najlepszy algorytm uczenia maszynowego do użycia dla konkretnych danych. Ten proces umożliwia szybkie generowanie modeli uczenia maszynowego. Dowiedz się więcej o tym, jak usługa Azure Machine Edukacja implementuje zautomatyzowane uczenie maszynowe.
Aby uzyskać pełny przykład, wypróbuj samouczek: AutoML — trenowanie modeli klasyfikacji bez kodu.
W przypadku środowiska opartego na kodzie w języku Python skonfiguruj eksperymenty zautomatyzowanego uczenia maszynowego za pomocą zestawu Azure Machine Edukacja SDK.
Wymagania wstępne
Subskrypcja platformy Azure. Jeśli nie masz subskrypcji platformy Azure, przed rozpoczęciem utwórz bezpłatne konto. Wypróbuj bezpłatną lub płatną wersję usługi Azure Machine Edukacja dzisiaj.
Obszar roboczy usługi Azure Machine Learning. Zobacz Tworzenie zasobów obszaru roboczego.
Rozpocznij
Zaloguj się do usługi Azure Machine Edukacja Studio.
Wybierz swoją subskrypcję i obszar roboczy.
Przejdź do okienka po lewej stronie. Wybierz pozycję Zautomatyzowane uczenie maszynowe w sekcji Tworzenie .

Jeśli po raz pierwszy wykonujesz jakiekolwiek eksperymenty, zostanie wyświetlona pusta lista i linki do dokumentacji.
W przeciwnym razie zostanie wyświetlona lista ostatnich eksperymentów zautomatyzowanego uczenia maszynowego, w tym utworzonych za pomocą zestawu SDK.
Tworzenie i uruchamianie eksperymentu
Wybierz pozycję + Nowe zadanie zautomatyzowanego uczenia maszynowego i wypełnij formularz.
Wybierz zasób danych z kontenera magazynu lub utwórz nowy zasób danych. Zasób danych można tworzyć na podstawie plików lokalnych, internetowych adresów URL, magazynów danych lub otwartych zestawów danych platformy Azure. Dowiedz się więcej o tworzeniu zasobów danych.
Ważne
Wymagania dotyczące danych szkoleniowych:
- Dane muszą być w formie tabelarycznej.
- Wartość, którą chcesz przewidzieć (kolumna docelowa), musi być obecna w danych.
Aby utworzyć nowy zestaw danych z pliku na komputerze lokalnym, wybierz pozycję +Utwórz zestaw danych , a następnie wybierz pozycję Z pliku lokalnego.
Wybierz przycisk Dalej , aby otworzyć formularz wyboru magazynu danych i pliku. , należy wybrać miejsce przekazania zestawu danych; domyślny kontener magazynu, który jest automatycznie tworzony za pomocą obszaru roboczego, lub wybierz kontener magazynu, którego chcesz użyć do eksperymentu.
- Jeśli dane stoją za siecią wirtualną, należy włączyć funkcję pomijania walidacji , aby upewnić się, że obszar roboczy będzie mógł uzyskiwać dostęp do danych. Aby uzyskać więcej informacji, zobacz Korzystanie z usługi Azure Machine Edukacja Studio w sieci wirtualnej platformy Azure.
Wybierz pozycję Przeglądaj , aby przekazać plik danych dla zestawu danych.
Przejrzyj formularz Ustawienia i podgląd, aby uzyskać dokładność. Formularz jest inteligentnie wypełniany na podstawie typu pliku.
Pole opis File format Definiuje układ i typ danych przechowywanych w pliku. Ogranicznik Co najmniej jeden znak określający granicę między oddzielnymi, niezależnymi regionami w postaci zwykłego tekstu lub innych strumieni danych. Kodowanie Określa, jakiego bitu do tabeli schematów znaków używać do odczytywania zestawu danych. Nagłówki kolumn Wskazuje, jak będą traktowane nagłówki zestawu danych, jeśli istnieją. Pomiń wiersze Wskazuje, ile wierszy zostanie pominiętych w zestawie danych, jeśli istnieje. Wybierz Dalej.
Formularz schematu jest inteligentnie wypełniany na podstawie wyborów w formularzu Ustawienia i podglądu. W tym miejscu skonfiguruj typ danych dla każdej kolumny, przejrzyj nazwy kolumn i wybierz kolumny, które mają nie uwzględniać w eksperymencie.
Wybierz Dalej.
Formularz Potwierdź szczegóły jest podsumowaniem informacji wcześniej wypełnionych w formularzach Podstawowe informacje i Ustawienia i podglądu. Istnieje również możliwość utworzenia profilu danych dla zestawu danych przy użyciu profilu obliczeniowego z włączoną obsługą profilowania.
Wybierz Dalej.
Wybierz nowo utworzony zestaw danych po jego pojawieniu się. Możesz również wyświetlić podgląd zestawu danych i przykładowych statystyk.
W formularzu Konfigurowanie zadania wybierz pozycję Utwórz nowe i wprowadź ciąg Tutorial-automl-deploy jako nazwę eksperymentu.
Wybierz kolumnę docelową; jest to kolumna, na której chcesz wykonać przewidywania.
Wybierz typ obliczeniowy dla zadania profilowania i trenowania danych. Możesz wybrać klaster obliczeniowy lub wystąpienie obliczeniowe.
Wybierz obliczenia z listy rozwijanej istniejących obliczeń. Aby utworzyć nowe środowisko obliczeniowe, postępuj zgodnie z instrukcjami w kroku 8.
Wybierz pozycję Utwórz nowe środowisko obliczeniowe , aby skonfigurować kontekst obliczeniowy dla tego eksperymentu.
Pole opis Nazwa obiektu obliczeniowego Wprowadź unikatową nazwę identyfikującą kontekst obliczeniowy. Priorytet maszyny wirtualnej Maszyny wirtualne o niskim priorytcie są tańsze, ale nie gwarantują węzłów obliczeniowych. Typ maszyny wirtualnej Wybierz procesor CPU lub procesor GPU dla typu maszyny wirtualnej. Rozmiar maszyny wirtualnej Wybierz rozmiar maszyny wirtualnej dla obliczeń. Minimalna/maksymalna liczba węzłów Aby profilować dane, należy określić co najmniej jeden węzeł. Wprowadź maksymalną liczbę węzłów dla obliczeń. Wartość domyślna to sześć węzłów dla usługi Azure Machine Edukacja Compute. Ustawienia zaawansowane Te ustawienia umożliwiają skonfigurowanie konta użytkownika i istniejącej sieci wirtualnej na potrzeby eksperymentu. Wybierz pozycję Utwórz. Tworzenie nowego środowiska obliczeniowego może potrwać kilka minut.
Wybierz Dalej.
W formularzu Typ zadania i ustawienia wybierz typ zadania: klasyfikacja, regresja lub prognozowanie. Aby uzyskać więcej informacji, zobacz obsługiwane typy zadań.
W przypadku klasyfikacji można również włączyć uczenie głębokie.
W przypadku prognozowania można:
Włącz uczenie głębokie.
Wybierz kolumnę czasu: ta kolumna zawiera dane czasu do użycia.
Wybierz horyzont prognozy: określ, ile jednostek czasu (minuty/godziny/dni/tygodnie/miesiące/lata) będzie w stanie przewidzieć przyszłość. Aby przewidzieć, tym bardziej dokładny staje się model, tym bardziej dokładny staje się model. Dowiedz się więcej o prognozowaniu i horyzoncie prognozy.
(Opcjonalnie) Wyświetlanie ustawień konfiguracji dodawania: dodatkowe ustawienia, których można użyć, aby lepiej kontrolować zadanie trenowania. W przeciwnym razie wartości domyślne są stosowane na podstawie wyboru eksperymentu i danych.
Dodatkowe konfiguracje opis Metryka podstawowa Główna metryka używana do oceniania modelu. Dowiedz się więcej o metrykach modelu. Włączanie stosu zespołu Uczenie zespołowe poprawia wyniki uczenia maszynowego i wydajność predykcyjną, łącząc wiele modeli, a nie przy użyciu pojedynczych modeli. Dowiedz się więcej o modelach grupowych. Zablokowane modele Wybierz modele, które chcesz wykluczyć z zadania szkoleniowego.
Zezwalanie na modele jest dostępne tylko dla eksperymentów zestawu SDK.
Zobacz obsługiwane algorytmy dla każdego typu zadania.Wyjaśnienie najlepszego modelu Automatycznie pokazuje możliwość wyjaśnienia najlepszego modelu utworzonego przez zautomatyzowane uczenie maszynowe. Etykieta klasy dodatniej Etykieta używana przez zautomatyzowane uczenie maszynowe do obliczania metryk binarnych. (Opcjonalnie) Wyświetlanie ustawień cech: jeśli zdecydujesz się włączyć automatyczną cechowanie w formularzu Dodatkowe ustawienia konfiguracji, stosowane są domyślne techniki cechowania. W ustawieniach funkcji Wyświetlanie cech można zmienić te wartości domyślne i odpowiednio dostosować je. Dowiedz się, jak dostosować cechowanie.
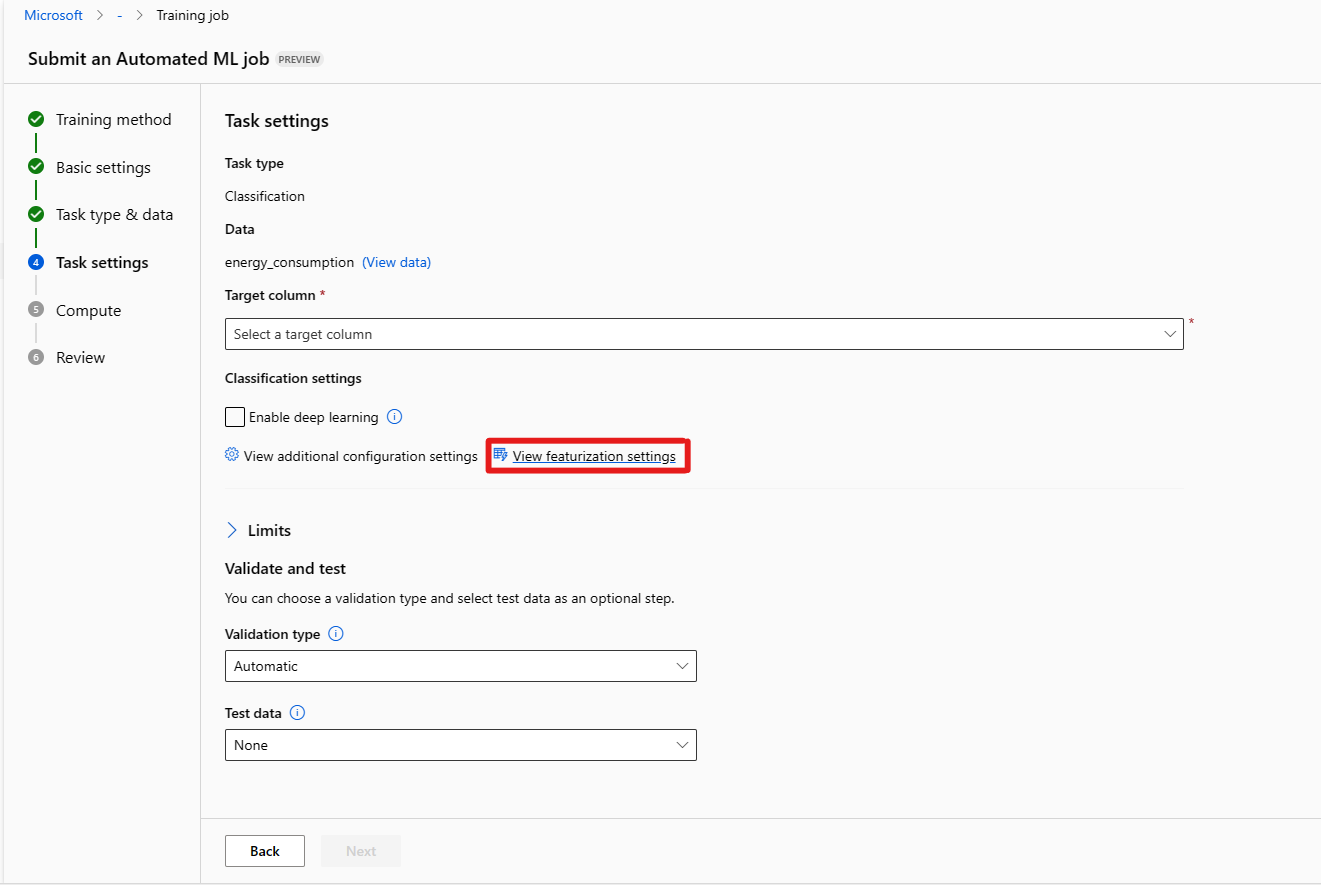
Formularz [Opcjonalne] Limity umożliwia wykonanie następujących czynności.
Opcja Opis Maksymalna liczba prób Maksymalna liczba prób, z których każda ma inną kombinację algorytmów i hiperparametrów do wypróbowania podczas zadania rozwiązania AutoML. Musi być liczbą całkowitą z zakresu od 1 do 1000. Maksymalna liczba współbieżnych prób Maksymalna liczba zadań próbnych, które można wykonać równolegle. Musi być liczbą całkowitą z zakresu od 1 do 1000. Maksymalna liczba węzłów Maksymalna liczba węzłów, których to zadanie może używać z wybranego celu obliczeniowego. Próg wyniku metryki Gdy ta wartość progowa zostanie osiągnięta dla metryki iteracji, zadanie trenowania zostanie zakończone. Należy pamiętać, że znaczące modele mają korelację > 0. W przeciwnym razie są one tak dobre, jak odgadywanie średniego progu metryki powinno należeć do granic [0, 10]. Limit czasu eksperymentu (w minutach) Maksymalny czas w minutach, przez jaki cały eksperyment może zostać uruchomiony. Po osiągnięciu tego limitu system anuluje zadanie rozwiązania AutoML, w tym wszystkie wersje próbne (zadania podrzędne). Limit czasu iteracji (w minutach) Maksymalny czas w minutach każdego zadania w wersji próbnej może zostać uruchomiony. Po osiągnięciu tego limitu system anuluje okres próbny. Włączanie wczesnego kończenia Wybierz, aby zakończyć zadanie, jeśli wynik nie poprawia się w krótkim okresie. Formularz weryfikacji i testowania [opcjonalnie] umożliwia wykonanie następujących czynności.
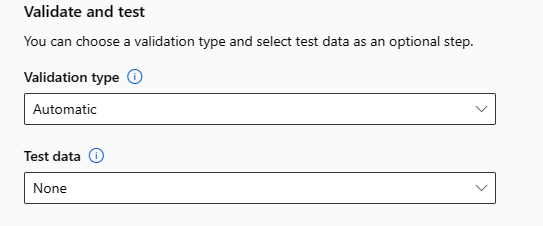
a. Określ typ weryfikacji, który ma być używany dla zadania szkoleniowego. Jeśli nie określisz jawnie parametru validation_data lub n_cross_validations , zautomatyzowane uczenie maszynowe stosuje techniki domyślne w zależności od liczby wierszy podanych w pojedynczym zestawie danych training_data.
| Rozmiar danych treningowych | Technika walidacji |
|---|---|
| Więcej niż 20 000 wierszy | Zastosowano podział danych trenowania/walidacji. Wartość domyślna to 10% początkowego zestawu danych treningowych jako zestawu weryfikacji. Z kolei ten zestaw weryfikacji jest używany do obliczania metryk. |
| Mniejsze niż 20 000 wierszy | Zastosowano podejście do krzyżowego sprawdzania poprawności. Domyślna liczba składań zależy od liczby wierszy. Jeśli zestaw danych jest mniejszy niż 1000 wierszy, używane jest 10 razy. Jeśli wiersze mają od 1000 do 20 000, używane są trzy razy. |
b. Podaj testowy zestaw danych (wersja zapoznawcza), aby ocenić zalecany model generowany przez zautomatyzowane uczenie maszynowe na końcu eksperymentu. Po podaniu danych testowych zadanie testowe zostanie automatycznie wyzwolone na końcu eksperymentu. To zadanie testowe jest zadaniem tylko w przypadku najlepszego modelu zalecanego przez zautomatyzowane uczenie maszynowe. Dowiedz się, jak uzyskać wyniki zadania testu zdalnego.
Ważne
Udostępnianie testowego zestawu danych do oceny wygenerowanych modeli jest funkcją w wersji zapoznawczej. Ta funkcja jest eksperymentalną funkcją w wersji zapoznawczej i może ulec zmianie w dowolnym momencie.
* Dane testowe są uznawane za oddzielone od trenowania i walidacji, tak aby nie stronniczy od wyników zadania testowego zalecanego modelu. Dowiedz się więcej o stronniczy sposób sprawdzania poprawności modelu.
* Możesz podać własny zestaw danych testowych lub zdecydować się na użycie procentu zestawu danych treningowych. Dane testowe muszą być w postaci zestawu danych tabelarycznych Edukacja Azure Machine.
* Schemat zestawu danych testowego powinien być zgodny z zestawem danych trenowania. Kolumna docelowa jest opcjonalna, ale jeśli żadna kolumna docelowa nie wskazuje, że nie są obliczane żadne metryki testowe.
* Zestaw danych testowych nie powinien być taki sam jak zestaw danych trenowania ani zestaw danych weryfikacji.
* Zadania prognozowania nie obsługują podziału trenowania/testowania.
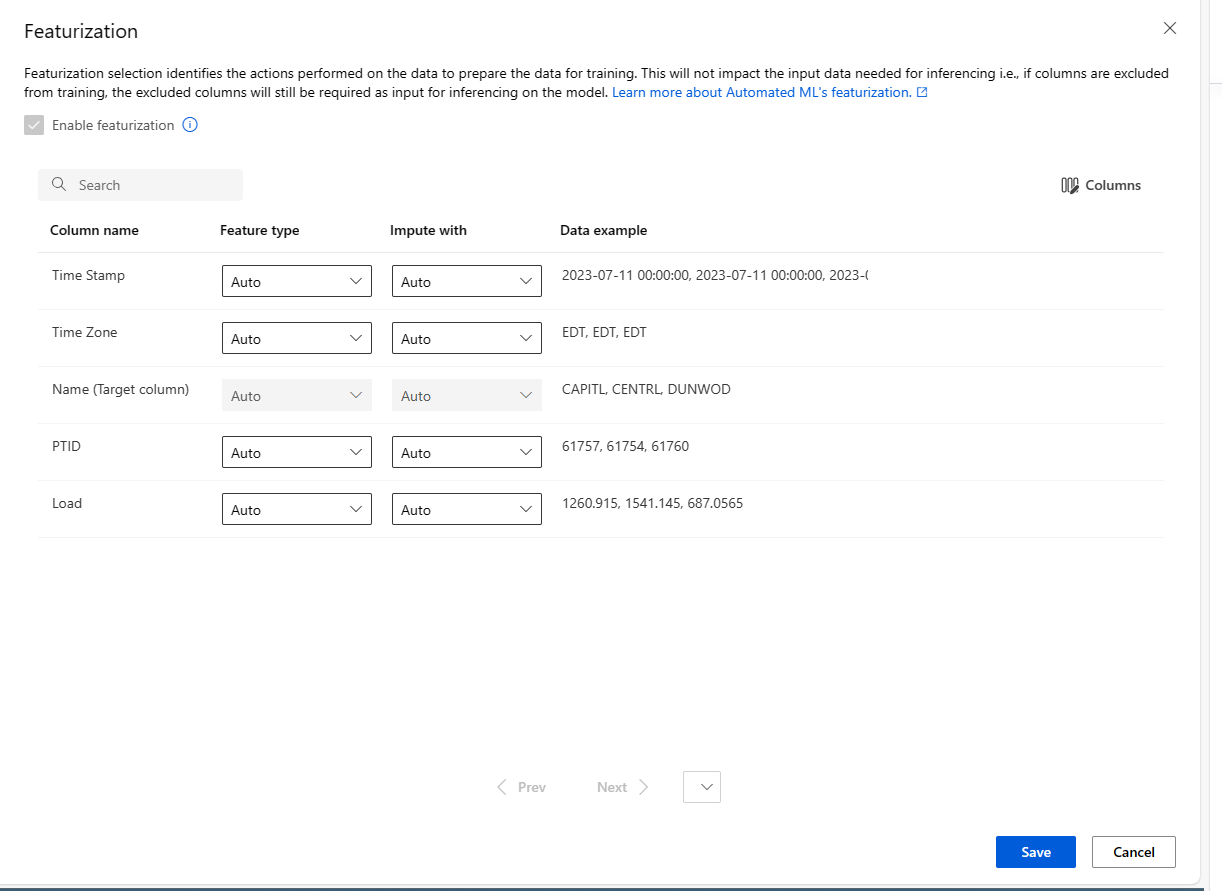
Dostosowywanie cechowania
W formularzu cechowania można włączyć/wyłączyć automatyczne cechowanie i dostosować ustawienia automatycznego cechowania dla eksperymentu. Aby otworzyć ten formularz, zobacz krok 10 w sekcji Tworzenie i uruchamianie eksperymentu .
Poniższa tabela zawiera podsumowanie dostosowań dostępnych obecnie za pośrednictwem programu Studio.
| Kolumna | Dostosowanie |
|---|---|
| Typ funkcji | Zmień typ wartości dla wybranej kolumny. |
| Impute z | Wybierz wartość do imputowania brakujących wartości w danych. |
Uruchamianie eksperymentu i wyświetlanie wyników
Wybierz pozycję Zakończ , aby uruchomić eksperyment. Proces przygotowywania eksperymentu może potrwać do 10 minut. Zadania trenowania mogą zająć kolejne 2–3 minuty dla każdego potoku. Jeśli określono generowanie pulpitu nawigacyjnego RAI dla najlepszego zalecanego modelu, może upłynąć do 40 minut.
Uwaga
Algorytmy zautomatyzowanego uczenia maszynowego mają nieodłączną losowość, która może spowodować niewielkie różnice w końcowym wyniku metryk zalecanego modelu, na przykład dokładność. Zautomatyzowane uczenie maszynowe wykonuje również operacje na danych, takich jak podział trenowania testu, podział weryfikacji pociągu lub krzyżowa walidacja w razie potrzeby. Dlatego jeśli wielokrotnie uruchamiasz eksperyment z tymi samymi ustawieniami konfiguracji i metrykami podstawowymi, prawdopodobnie zobaczysz różnice w poszczególnych eksperymentach końcowych wyników metryk ze względu na te czynniki.
Wyświetlanie szczegółów eksperymentu
Zostanie otwarty ekran Szczegóły zadania na karcie Szczegóły . Na tym ekranie przedstawiono podsumowanie zadania eksperymentu, w tym pasek stanu u góry obok numeru zadania.
Karta Modele zawiera listę utworzonych modeli uporządkowaną według wyników metryk. Domyślnie model, który dla wybranej metryki uzyska najlepszy wynik, znajduje się na początku listy. Gdy zadanie szkoleniowe próbuje uzyskać więcej modeli, są one dodawane do listy. Umożliwia ona szybkie porównanie metryk modeli wyprodukowanych do tej pory.
Wyświetlanie szczegółów zadania trenowania
Przejdź do szczegółów dowolnego z ukończonych modeli, aby wyświetlić szczegóły zadania trenowania.
Wykresy metryk wydajności specyficzne dla modelu można wyświetlić na karcie Metryki . Dowiedz się więcej o wykresach.
W tym miejscu można również znaleźć szczegółowe informacje o wszystkich właściwościach modelu wraz ze skojarzonym kodem, zadaniami podrzędnymi i obrazami.
Wyświetlanie wyników zadania testu zdalnego (wersja zapoznawcza)
Jeśli podczas konfigurowania eksperymentu określono zestaw danych testowych lub wybrano podział trenowania/testu — w formularzu Weryfikowanie i testowanie automatyczne uczenie maszynowe domyślnie testuje zalecany model. W rezultacie zautomatyzowane uczenie maszynowe oblicza metryki testów w celu określenia jakości zalecanego modelu i jego przewidywań.
Ważne
Testowanie modeli przy użyciu zestawu danych testowych w celu oceny wygenerowanych modeli jest funkcją w wersji zapoznawczej. Ta funkcja jest eksperymentalną funkcją w wersji zapoznawczej i może ulec zmianie w dowolnym momencie.
Ostrzeżenie
Ta funkcja nie jest dostępna w następujących scenariuszach zautomatyzowanego uczenia maszynowego
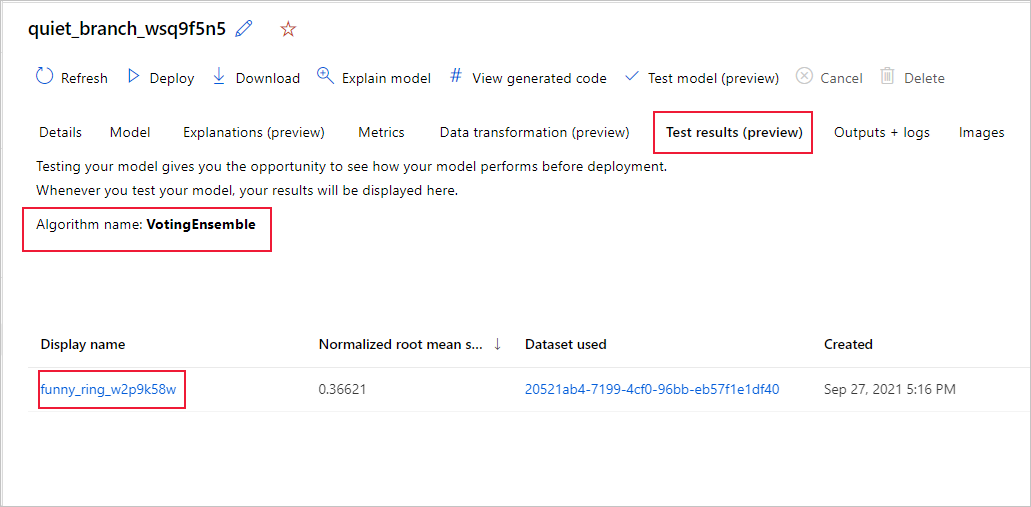
Aby wyświetlić metryki zadania testowego zalecanego modelu,
- Przejdź do strony Modele , wybierz najlepszy model.
- Wybierz kartę Wyniki testu (wersja zapoznawcza).
- Wybierz żądane zadanie i wyświetl kartę Metryki .
Aby wyświetlić przewidywania testów używane do obliczania metryk testów,
- Przejdź do dołu strony i wybierz link w obszarze Dane wyjściowe zestawu danych , aby otworzyć zestaw danych.
- Na stronie Zestawy danych wybierz kartę Eksploruj, aby wyświetlić przewidywania z zadania testowego.
- Alternatywnie plik przewidywania można również wyświetlić/pobrać z karty Dane wyjściowe i dzienniki , rozwiń folder Predictions (Przewidywania), aby zlokalizować
predicted.csvplik.
- Alternatywnie plik przewidywania można również wyświetlić/pobrać z karty Dane wyjściowe i dzienniki , rozwiń folder Predictions (Przewidywania), aby zlokalizować
Alternatywnie plik przewidywania można również wyświetlić/pobrać z karty Dane wyjściowe i dzienniki, rozwiń folder Predictions (Przewidywania), aby zlokalizować plik predictions.csv.
Zadanie testowania modelu generuje plik predictions.csv przechowywany w domyślnym magazynie danych utworzonym za pomocą obszaru roboczego. Ten magazyn danych jest widoczny dla wszystkich użytkowników z tą samą subskrypcją. Zadania testowe nie są zalecane w scenariuszach, jeśli którekolwiek z informacji używanych w ramach zadania testowego lub utworzone przez zadanie testowe musi pozostać prywatne.
Testowanie istniejącego zautomatyzowanego modelu uczenia maszynowego (wersja zapoznawcza)
Ważne
Testowanie modeli przy użyciu zestawu danych testowych w celu oceny wygenerowanych modeli jest funkcją w wersji zapoznawczej. Ta funkcja jest eksperymentalną funkcją w wersji zapoznawczej i może ulec zmianie w dowolnym momencie.
Ostrzeżenie
Ta funkcja nie jest dostępna w następujących scenariuszach zautomatyzowanego uczenia maszynowego
Po zakończeniu eksperymentu możesz przetestować modele generowane przez zautomatyzowane uczenie maszynowe. Jeśli chcesz przetestować inny zautomatyzowany model generowany przez uczenie maszynowe, a nie zalecany model, możesz to zrobić, wykonując następujące kroki.
Wybierz istniejące zadanie eksperymentu zautomatyzowanego uczenia maszynowego.
Przejdź do karty Modele zadania i wybierz ukończony model, który chcesz przetestować.
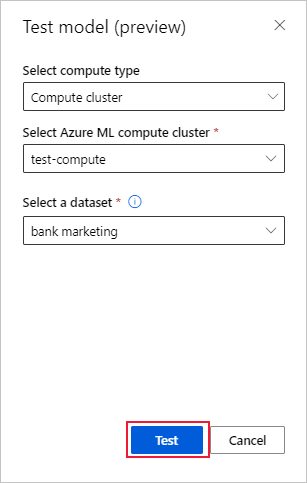
Na stronie Szczegóły modelu wybierz przycisk Test model (wersja zapoznawcza), aby otworzyć okienko Model testowy.
W okienku Model testowy wybierz klaster obliczeniowy i testowy zestaw danych, którego chcesz użyć dla zadania testowego.
Wybierz przycisk Testuj. Schemat zestawu danych testowego powinien być zgodny z zestawem danych trenowania, ale kolumna docelowa jest opcjonalna.
Po pomyślnym utworzeniu zadania testu modelu na stronie Szczegóły zostanie wyświetlony komunikat o powodzeniu. Wybierz kartę Wyniki testu, aby wyświetlić postęp zadania.
Aby wyświetlić wyniki zadania testowego, otwórz stronę Szczegóły i wykonaj kroki opisane w sekcji Wyświetl wyniki zadania testu zdalnego.
Pulpit nawigacyjny odpowiedzialnej sztucznej inteligencji (wersja zapoznawcza)
Aby lepiej zrozumieć model, możesz zobaczyć różne szczegółowe informacje o modelu przy użyciu pulpitu nawigacyjnego Odpowiedzialne użycie sztucznej inteligencji. Umożliwia ona ocenę i debugowanie najlepszego modelu zautomatyzowanego uczenia maszynowego. Pulpit nawigacyjny odpowiedzialnej sztucznej inteligencji oceni błędy modelu i problemy z sprawiedliwością, zdiagnozuje, dlaczego te błędy występują, oceniając dane trenowania i/lub testowania oraz obserwując wyjaśnienia modelu. Te szczegółowe informacje mogą pomóc w budowaniu zaufania z modelem i przekazaniu procesów inspekcji. Nie można wygenerować pulpitów nawigacyjnych odpowiedzialnej sztucznej inteligencji dla istniejącego modelu zautomatyzowanego uczenia maszynowego. Jest on tworzony tylko dla najlepszego zalecanego modelu podczas tworzenia nowego zadania rozwiązania AutoML. Użytkownicy powinni nadal używać wyjaśnień modelu (wersja zapoznawcza), dopóki nie zostanie udostępniona obsługa istniejących modeli.
Aby wygenerować pulpit nawigacyjny odpowiedzialnej sztucznej inteligencji dla określonego modelu,
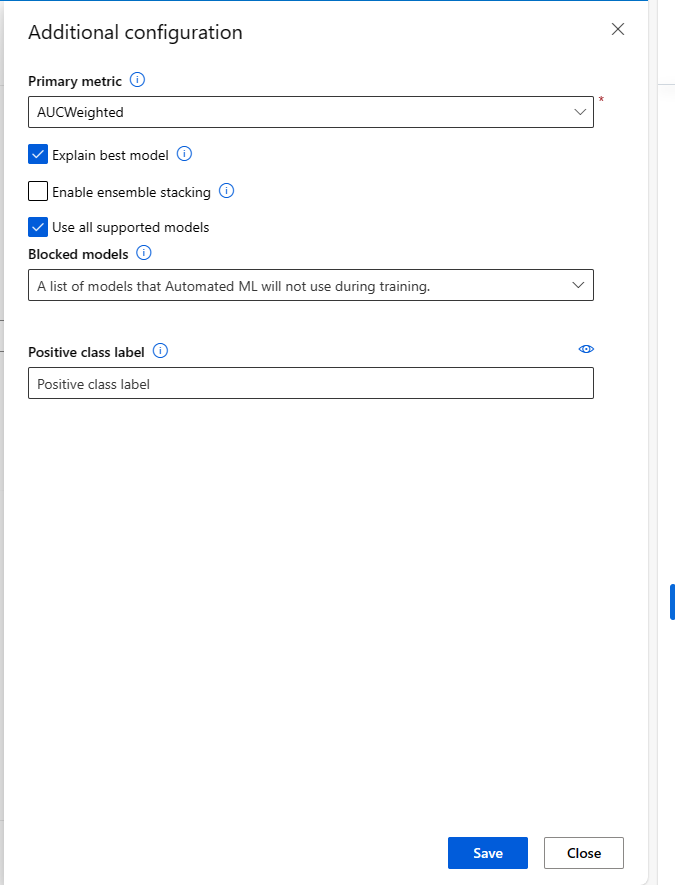
Podczas przesyłania zadania zautomatyzowanego uczenia maszynowego przejdź do sekcji Ustawienia zadania na lewym pasku nawigacyjnym i wybierz opcję Wyświetl dodatkowe ustawienia konfiguracji.
W nowym formularzu wyświetlanym po zaznaczeniu zaznacz pole wyboru Wyjaśnij najlepszy model .
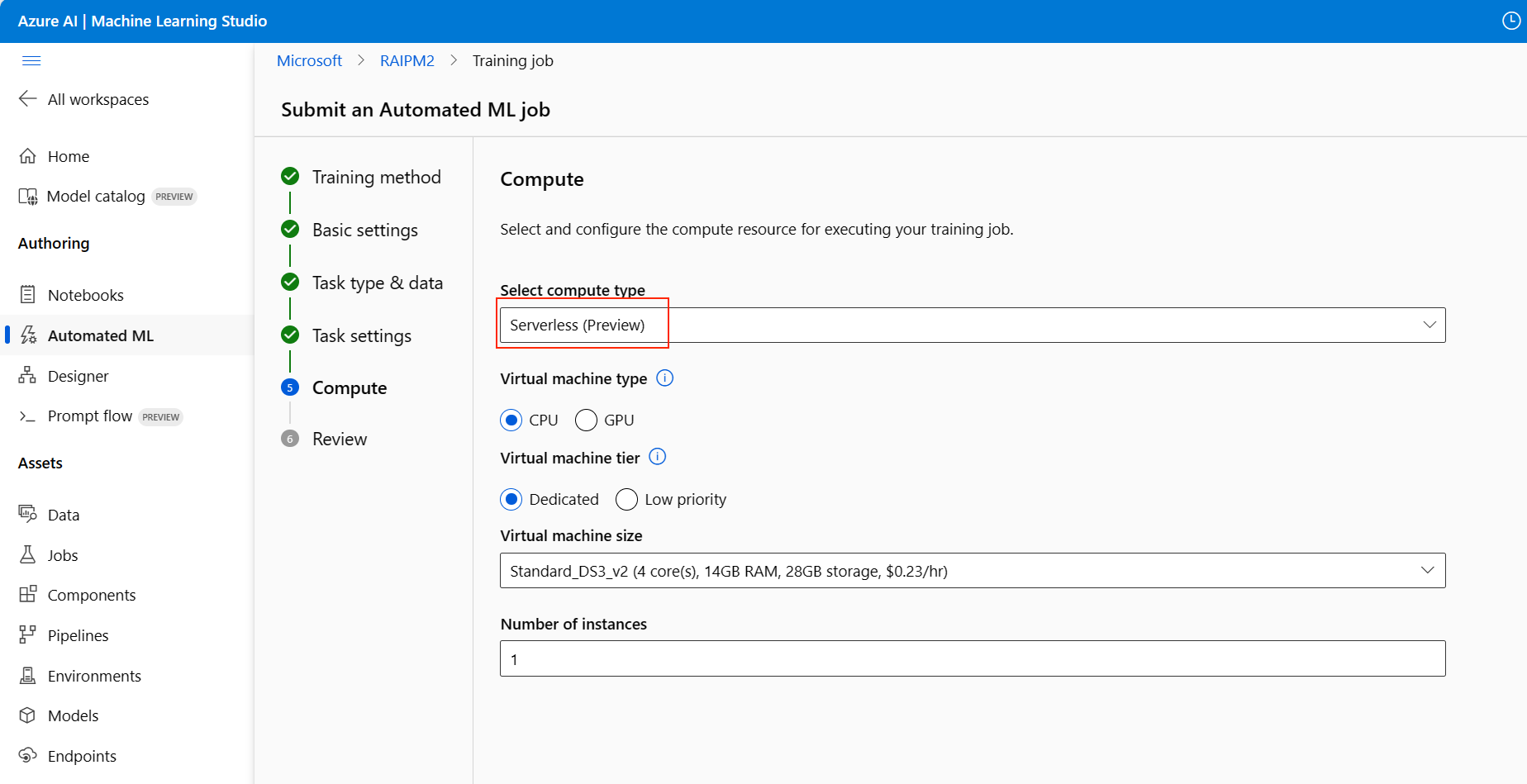
Przejdź do strony Obliczenia formularza konfiguracji i wybierz opcję Bezserwerowa dla obliczeń.
Po zakończeniu przejdź do strony Modele zadania zautomatyzowanego uczenia maszynowego, która zawiera listę wytrenowanych modeli. Wybierz link Wyświetl pulpit nawigacyjny odpowiedzialnej sztucznej inteligencji:
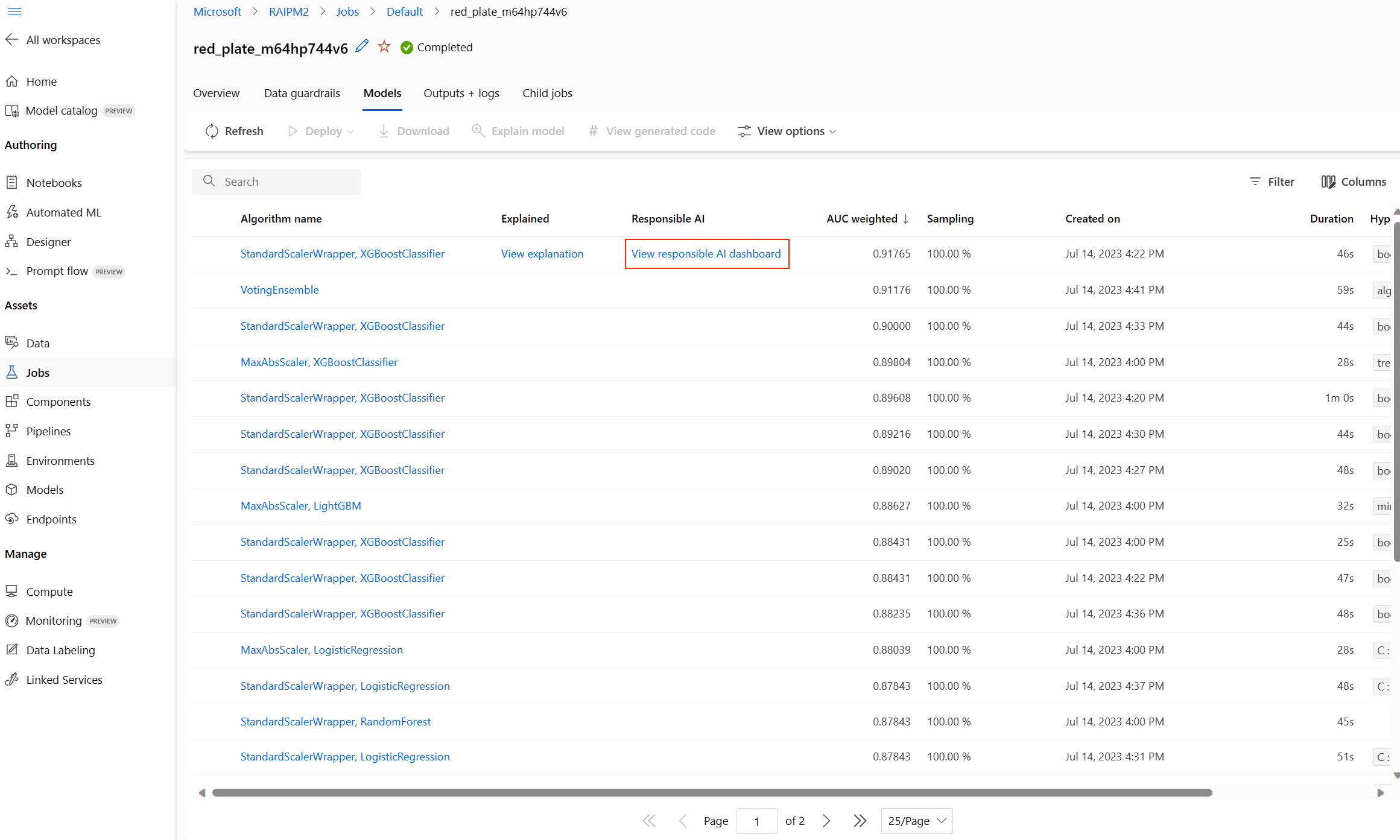
Pulpit nawigacyjny odpowiedzialnej sztucznej inteligencji zostanie wyświetlony dla tego modelu, jak pokazano na poniższej ilustracji:

Na pulpicie nawigacyjnym znajdziesz cztery składniki aktywowane dla najlepszego modelu zautomatyzowanego uczenia maszynowego:
| Składnik | Co pokazuje składnik? | Jak odczytać wykres? |
|---|---|---|
| Analiza błędów | Użyj analizy błędów, jeśli musisz: Dowiedz się, jak awarie modelu są dystrybuowane w zestawie danych oraz w kilku wymiarach danych wejściowych i cech. Podziel zagregowane metryki wydajności, aby automatycznie odnaleźć błędną kohortę w celu poinformowania o ukierunkowanych krokach ograniczania ryzyka. |
Wykresy analizy błędów |
| Omówienie modelu i sprawiedliwość | Użyj tego składnika, aby: Uzyskaj szczegółowe informacje na temat wydajności modelu w różnych kohortach danych. Zapoznaj się z problemami dotyczącymi sprawiedliwości modelu, przeglądając metryki różnic. Te metryki mogą oceniać i porównywać zachowanie modelu w podgrupach określonych pod kątem funkcji poufnych (lub niewrażliwych). |
Omówienie modelu i wykresy sprawiedliwości |
| Wyjaśnienia modelu | Użyj składnika wyjaśnienia modelu, aby wygenerować zrozumiałe dla człowieka opisy przewidywań modelu uczenia maszynowego, patrząc na: Wyjaśnienia globalne: na przykład jakie funkcje wpływają na ogólne zachowanie modelu alokacji pożyczek? Wyjaśnienia lokalne: na przykład dlaczego wniosek o pożyczkę klienta został zatwierdzony lub odrzucony? |
Wykresy objaśnienia modelu |
| Analiza danych | Użyj analizy danych, gdy musisz: Eksploruj statystyki zestawu danych, wybierając różne filtry, aby podzielić dane na różne wymiary (nazywane również kohortami). Omówienie dystrybucji zestawu danych w różnych kohortach i grupach funkcji. Ustal, czy wyniki związane z uczciwością, analizą błędów i przyczynowością (pochodzące z innych składników pulpitu nawigacyjnego) są wynikiem dystrybucji zestawu danych. Zdecyduj, w których obszarach zebrać więcej danych, aby wyeliminować błędy wynikające z problemów z reprezentacją, szum etykiet, szum funkcji, stronniczość etykiet i podobne czynniki. |
Wykresy eksploratora danych |
- Możesz dalej tworzyć kohorty (podgrupy punktów danych, które mają określone cechy), aby skoncentrować analizę poszczególnych składników na różnych kohortach. Nazwa kohorty, która jest obecnie stosowana do pulpitu nawigacyjnego, jest zawsze wyświetlana w lewym górnym rogu pulpitu nawigacyjnego. Domyślny widok na pulpicie nawigacyjnym to cały zestaw danych o nazwie "Wszystkie dane" (domyślnie). Dowiedz się więcej o globalnej kontroli pulpitu nawigacyjnego tutaj.
Edytowanie i przesyłanie zadań (wersja zapoznawcza)
Ważne
Możliwość kopiowania, edytowania i przesyłania nowego eksperymentu na podstawie istniejącego eksperymentu jest funkcją w wersji zapoznawczej. Ta funkcja jest eksperymentalną funkcją w wersji zapoznawczej i może ulec zmianie w dowolnym momencie.
W scenariuszach, w których chcesz utworzyć nowy eksperyment na podstawie ustawień istniejącego eksperymentu, zautomatyzowane uczenie maszynowe udostępnia opcję wykonania tej czynności za pomocą przycisku Edytuj i prześlij w interfejsie użytkownika programu Studio.
Ta funkcja jest ograniczona do eksperymentów zainicjowanych z interfejsu użytkownika studio i wymaga schematu danych dla nowego eksperymentu, aby był zgodny z oryginalnym eksperymentem.
Przycisk Edytuj i prześlij otwiera kreatora Tworzenie nowego zadania zautomatyzowanego uczenia maszynowego ze wstępnie wypełnionymi danymi, obliczeniami i ustawieniami eksperymentu. Możesz przejść przez każdy formularz i edytować wybrane opcje zgodnie z potrzebami dla nowego eksperymentu.
Wdrażanie modelu
Gdy masz najlepszy model, nadszedł czas, aby wdrożyć go jako usługę internetową, aby przewidzieć nowe dane.
Napiwek
Jeśli chcesz wdrożyć model, który został wygenerowany za pośrednictwem pakietu przy użyciu automl zestawu SDK języka Python, musisz zarejestrować model) w obszarze roboczym.
Po zarejestrowaniu modelu znajdź go w studio, wybierając pozycję Modele w okienku po lewej stronie. Po otwarciu modelu możesz wybrać przycisk Wdróż w górnej części ekranu, a następnie postępować zgodnie z instrukcjami opisanymi w kroku 2sekcji Wdrażanie modelu.
Zautomatyzowane uczenie maszynowe ułatwia wdrażanie modelu bez pisania kodu:
Masz kilka opcji wdrażania.
Opcja 1: Wdróż najlepszy model zgodnie z zdefiniowanymi kryteriami metryki.
- Po zakończeniu eksperymentu przejdź do strony nadrzędnego zadania, wybierając pozycję Zadanie 1 w górnej części ekranu.
- Wybierz model wymieniony w sekcji Podsumowanie najlepszego modelu.
- Wybierz pozycję Wdróż w lewym górnym rogu okna.
Opcja 2. Aby wdrożyć określoną iterację modelu z tego eksperymentu.
- Wybierz odpowiedni model z karty Modele
- Wybierz pozycję Wdróż w lewym górnym rogu okna.
Wypełnij okienko Wdrażanie modelu.
Pole Wartość Nazwisko Wprowadź unikatową nazwę wdrożenia. opis Wprowadź opis, aby lepiej zidentyfikować to wdrożenie. Typ środowiska obliczeniowego Wybierz typ punktu końcowego, który chcesz wdrożyć: Azure Kubernetes Service (AKS) lub Azure Container Instance (ACI). Nazwa obiektu obliczeniowego Dotyczy tylko usługi AKS: wybierz nazwę klastra usługi AKS, do którego chcesz wdrożyć. Włącz uwierzytelnianie Wybierz, aby zezwolić na uwierzytelnianie oparte na tokenach lub oparte na kluczach. Korzystanie z niestandardowych zasobów wdrażania Włącz tę funkcję, jeśli chcesz przekazać własny skrypt oceniania i plik środowiska. W przeciwnym razie zautomatyzowane uczenie maszynowe domyślnie udostępnia te zasoby. Dowiedz się więcej o skryptach oceniania. Ważne
Nazwa pliku musi zawierać mniej niż 32 znaki oraz zaczynać się i kończyć znakiem alfanumerycznym. Pomiędzy nimi mogą znajdować się łączniki, podkreślenia, kropki i znaki alfanumeryczne. Spacje są niedozwolone.
W menu Zaawansowane znajdują się domyślne funkcje wdrażania takie jak zbieranie danych i ustawienia wykorzystania zasobów. Jeśli chcesz zastąpić te ustawienia domyślne, skorzystaj z tego menu.
Wybierz Wdróż. Wdrażanie może potrwać około 20 minut. Po rozpoczęciu wdrażania zostanie wyświetlona karta Podsumowanie modelu. Postęp wdrażania jest widoczny w sekcji Stan wdrożenia.
Masz teraz działającą usługę internetową umożliwiającą generowanie przewidywań. Możesz przetestować przewidywania, wykonując zapytania do usługi za pomocą wbudowanej obsługi usługi Azure Machine Learning w usłudze Power BI.
Następne kroki
- Omówienie wyników zautomatyzowanego uczenia maszynowego.
- Dowiedz się więcej na temat zautomatyzowanego uczenia maszynowego i usługi Azure Machine Edukacja.