Wzbogacanie sztucznej inteligencji w usłudze Azure AI Search
W usłudze Azure AI Search wzbogacanie sztucznej inteligencji odnosi się do integracji z usługami Azure AI w celu przetwarzania zawartości, która nie jest wyszukiwana w postaci pierwotnej. Dzięki wzbogaceniu analiza i wnioskowanie są używane do tworzenia zawartości i struktury z możliwością wyszukiwania, w której żadna wcześniej nie istniała.
Ponieważ usługa Azure AI Search jest rozwiązaniem do wyszukiwania tekstu i wektorów, celem wzbogacania sztucznej inteligencji jest ulepszenie narzędzia zawartości w scenariuszach związanych z wyszukiwaniem. Zawartość źródłowa musi być tekstowa (nie można wzbogacić wektorów), ale zawartość utworzona przez potok wzbogacania może być wektoryzowana i indeksowana w indeksie wektorowym przy użyciu umiejętności takich jak umiejętność dzielenia tekstu na potrzeby fragmentowania i umiejętności azureOpenAIEmbedding na potrzeby kodowania.
Wzbogacanie sztucznej inteligencji opiera się na umiejętnościach.
Wbudowane umiejętności pozwalają korzystać z usług Azure AI. Stosują one następujące przekształcenia i przetwarzanie do nieprzetworzonej zawartości:
- Wykrywanie tłumaczenia i języka na potrzeby wyszukiwania wielojęzycznego
- Rozpoznawanie jednostek w celu wyodrębnienia nazw osób, miejsc i innych jednostek z dużych fragmentów tekstu
- Wyodrębnianie kluczowych fraz w celu zidentyfikowania i wyprowadzenia ważnych terminów
- Optyczne rozpoznawanie znaków (OCR) do rozpoznawania tekstu drukowanego i odręcznego w plikach binarnych
- Analiza obrazów w celu opisania zawartości obrazu i wyprowadzania opisów jako pól tekstowych z możliwością wyszukiwania
Niestandardowe umiejętności uruchamiają kod zewnętrzny. Umiejętności niestandardowe mogą służyć do dowolnego niestandardowego przetwarzania, które chcesz uwzględnić w potoku.
Wzbogacanie sztucznej inteligencji to rozszerzenie potoku indeksatora łączącego się ze źródłami danych platformy Azure. Potok wzbogacania zawiera wszystkie składniki potoku indeksatora (indeksator, źródło danych, indeks) oraz zestaw umiejętności określający niepodzielne kroki wzbogacania.
Na poniższym diagramie przedstawiono postęp wzbogacania sztucznej inteligencji:
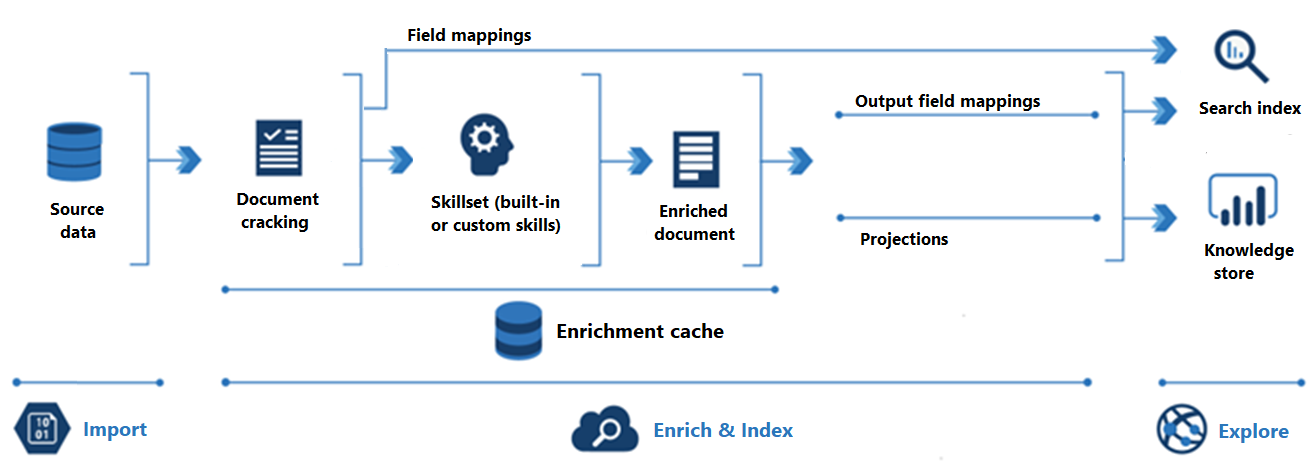
Importowanie to pierwszy krok. W tym miejscu indeksator łączy się ze źródłem danych i pobiera zawartość (dokumenty) do usługi wyszukiwania. Usługa Azure Blob Storage jest najczęstszym zasobem używanym w scenariuszach wzbogacania sztucznej inteligencji, ale każde obsługiwane źródło danych może udostępniać zawartość.
Wzbogacanie i indeks obejmuje większość potoku wzbogacania sztucznej inteligencji:
Wzbogacanie rozpoczyna się, gdy indeksator "pęka dokumenty" i wyodrębnia obrazy i tekst. Rodzaj przetwarzania, który następuje dalej, zależy od danych i umiejętności dodanych do zestawu umiejętności. Jeśli masz obrazy, mogą być przekazywane do umiejętności, które wykonują przetwarzanie obrazów. Zawartość tekstowa jest kolejkowana do przetwarzania tekstu i języka naturalnego. Wewnętrznie umiejętności tworzą "wzbogacony dokument" , który zbiera przekształcenia w miarę ich występowania.
Wzbogacona zawartość jest generowana podczas wykonywania zestawu umiejętności i jest tymczasowa, chyba że zostanie zapisana. Możesz włączyć pamięć podręczną wzbogacania w celu utrwalania pękniętych dokumentów i danych wyjściowych umiejętności w celu późniejszego ponownego użycia podczas przyszłych wykonań zestawu umiejętności.
Aby uzyskać zawartość do indeksu wyszukiwania, indeksator musi mieć informacje o mapowaniu służące do wysyłania wzbogaconej zawartości do pola docelowego. Mapowania pól (jawne lub niejawne) ustawiają ścieżkę danych z danych źródłowych na indeks wyszukiwania. Mapowania pól wyjściowych ustawiają ścieżkę danych z wzbogaconych dokumentów na indeks.
Indeksowanie to proces, w którym zawartość nieprzetworzona i wzbogacona jest pozyskiwana do fizycznych struktur danych indeksu wyszukiwania (jego plików i folderów). Analiza leksykalna i tokenizacja są wykonywane w tym kroku.
Eksploracja to ostatni krok. Dane wyjściowe są zawsze indeksem wyszukiwania, który można wykonywać zapytania z poziomu aplikacji klienckiej. Dane wyjściowe mogą być opcjonalnie magazynem wiedzy składającym się z obiektów blob i tabel w usłudze Azure Storage, które są dostępne za pośrednictwem narzędzi do eksploracji danych lub procesów podrzędnych. Jeśli tworzysz magazyn wiedzy, projekcje określają ścieżkę danych dla wzbogaconej zawartości. Ta sama wzbogacona zawartość może być wyświetlana zarówno w indeksach, jak i w magazynach wiedzy.
Kiedy należy używać wzbogacania sztucznej inteligencji
Wzbogacanie jest przydatne, jeśli nieprzetworzona zawartość jest tekstem bez struktury, zawartością obrazu lub zawartością, która wymaga wykrywania i tłumaczenia języka. Zastosowanie sztucznej inteligencji za pomocą wbudowanych umiejętności może odblokować tę zawartość dla aplikacji do wyszukiwania pełnotekstowego i nauki o danych.
Możesz również tworzyć niestandardowe umiejętności w celu zapewnienia przetwarzania zewnętrznego. Kod typu open source, innej firmy lub kodu innej firmy można zintegrować z potokiem jako umiejętności niestandardowe. Modele klasyfikacji identyfikujące istotne cechy różnych typów dokumentów należą do tej kategorii, ale można użyć dowolnego pakietu zewnętrznego, który dodaje wartość do zawartości.
Przypadki użycia wbudowanych umiejętności
Wbudowane umiejętności są oparte na interfejsach API usług Azure AI: Azure AI przetwarzanie obrazów i Language Service. Jeśli dane wejściowe zawartości nie są małe, należy spodziewać się dołączenia rozliczanego zasobu usług Azure AI w celu uruchomienia większych obciążeń.
Zestaw umiejętności utworzony przy użyciu wbudowanych umiejętności jest odpowiedni dla następujących scenariuszy aplikacji:
Umiejętności przetwarzania obrazów obejmują optyczne rozpoznawanie znaków (OCR) i identyfikację cech wizualnych, takich jak wykrywanie twarzy, interpretacja obrazu, rozpoznawanie obrazów (znane osoby i punkty orientacyjne) lub atrybuty, takie jak orientacja obrazu. Te umiejętności umożliwiają tworzenie reprezentacji tekstowych zawartości obrazu na potrzeby wyszukiwania pełnotekstowego w usłudze Azure AI Search.
Tłumaczenie maszynowe jest dostarczane przez umiejętności tłumaczenia tekstu, często sparowane z wykrywaniemjęzyka dla rozwiązań wielojęzycznych.
Przetwarzanie języka naturalnego analizuje fragmenty tekstu. Umiejętności w tej kategorii obejmują rozpoznawanie jednostek, wykrywanie tonacji (w tym wyszukiwanie opinii) i wykrywanie danych osobowych. Dzięki tym umiejętnościom tekst bez struktury jest mapowany jako pola z możliwością wyszukiwania i filtrowania w indeksie.
Przypadki użycia dla umiejętności niestandardowych
Niestandardowe umiejętności wykonują kod zewnętrzny, który udostępniasz i opakowujesz w niestandardowy interfejs internetowy umiejętności. Kilka przykładów umiejętności niestandardowych można znaleźć w repozytorium GitHub azure-search-power-skills .
Umiejętności niestandardowe nie zawsze są złożone. Jeśli na przykład masz istniejący pakiet, który zapewnia dopasowywanie wzorców lub model klasyfikacji dokumentów, możesz opakowować go w umiejętności niestandardowe.
Przechowywanie danych wyjściowych
W usłudze Azure AI Search indeksator zapisuje utworzone dane wyjściowe. Uruchomienie pojedynczego indeksatora może utworzyć maksymalnie trzy struktury danych zawierające wzbogacone i indeksowane dane wyjściowe.
| Magazyn danych | Wymagania | Lokalizacja | opis |
|---|---|---|---|
| indeks z możliwością wyszukiwania | Wymagania | Search Service | Służy do wyszukiwania pełnotekstowego i innych formularzy zapytań. Określanie indeksu jest wymaganiem indeksatora. Zawartość indeksu jest wypełniana z danych wyjściowych umiejętności oraz wszystkich pól źródłowych mapowanych bezpośrednio na pola w indeksie. |
| magazyn wiedzy | Opcjonalnie | Azure Storage | Używane w przypadku aplikacji podrzędnych, takich jak wyszukiwanie wiedzy lub nauka o danych. Magazyn wiedzy jest definiowany w zestawie umiejętności. Jego definicja określa, czy wzbogacone dokumenty są projektowane jako tabele lub obiekty (pliki lub obiekty blob) w usłudze Azure Storage. |
| pamięć podręczna wzbogacania | Opcjonalnie | Azure Storage | Służy do buforowania wzbogacania w celu ponownego użycia w kolejnych wykonaniach zestawu umiejętności. Pamięć podręczna przechowuje importowaną, nieprzetworzoną zawartość (pęknięte dokumenty). Przechowuje również wzbogacone dokumenty utworzone podczas wykonywania zestawu umiejętności. Buforowanie jest przydatna, jeśli używasz analizy obrazów lub OCR i chcesz uniknąć czasu i wydatków na ponowne przetwarzanie plików obrazów. |
Indeksy i magazyny wiedzy są w pełni niezależne od siebie. Mimo że należy dołączyć indeks w celu spełnienia wymagań indeksatora, jeśli jedynym celem jest magazyn wiedzy, możesz zignorować indeks po jego wypełnieniu.
Eksplorowanie zawartości
Po zdefiniowaniu i załadowaniu indeksu wyszukiwania lub magazynu wiedzy możesz eksplorować jego dane.
Wykonywanie zapytań względem indeksu wyszukiwania
Uruchom zapytania , aby uzyskać dostęp do wzbogaconej zawartości wygenerowanej przez potok. Indeks jest podobny do innych, które można utworzyć dla usługi Azure AI Search: możesz uzupełnić analizę tekstu za pomocą analizatorów niestandardowych, wywoływać zapytania wyszukiwania rozmyte, dodawać filtry lub eksperymentować z profilami oceniania w celu dostosowania istotności wyszukiwania.
Korzystanie z narzędzi do eksploracji danych w magazynie wiedzy
W usłudze Azure Storage magazyn wiedzy może przyjąć następujące formy: kontener obiektów blob dokumentów JSON, kontener obiektów blob obiektów obrazów lub tabel w usłudze Table Storage. Aby uzyskać dostęp do zawartości, możesz użyć Eksplorator usługi Storage, usługi Power BI lub dowolnej aplikacji łączącej się z usługą Azure Storage.
Kontener obiektów blob przechwytuje wzbogacone dokumenty w całości, co jest przydatne, jeśli tworzysz źródło danych w innych procesach.
Tabela jest przydatna, jeśli potrzebujesz wycinków wzbogaconych dokumentów lub chcesz dołączyć lub wykluczyć określone części danych wyjściowych. W przypadku analizy w usłudze Power BI tabele są zalecanym źródłem danych na potrzeby eksploracji i wizualizacji danych w usłudze Power BI.
Dostępność i cennik
Wzbogacanie jest dostępne w regionach, w których są dostępne usługi Azure AI. Dostępność wzbogacania można sprawdzić na stronie produktów platformy Azure dostępnych według regionów .
Rozliczenia są zgodne z modelem cen płatności zgodnie z rzeczywistym użyciem. Koszty korzystania z wbudowanych umiejętności są przekazywane, gdy klucz usług Azure AI w wielu regionach jest określony w zestawie umiejętności. Istnieją również koszty związane z wyodrębnianiem obrazów zgodnie z pomiarami usługi Azure AI Search. Jednak wyodrębnianie tekstu i umiejętności użyteczności nie są rozliczane. Aby uzyskać więcej informacji, zobacz Jak są naliczane opłaty za usługę Azure AI Search.
Lista kontrolna: Typowy przepływ pracy
Potok wzbogacania składa się z indeksatorów , które mają zestawy umiejętności. Po indeksowaniu możesz wykonać zapytanie względem indeksu, aby zweryfikować wyniki.
Zacznij od podzbioru danych w obsługiwanym źródle danych. Projektowanie indeksatora i zestawu umiejętności jest procesem iteracyjnym. Praca przebiega szybciej z małym reprezentatywnym zestawem danych.
Utwórz źródło danych, które określa połączenie z danymi.
Tworzenie zestawu umiejętności. Jeśli projekt nie jest mały, należy dołączyć zasób wielosłużytowy usługi Azure AI. Jeśli tworzysz magazyn wiedzy, zdefiniuj go w zestawie umiejętności.
Utwórz schemat indeksu , który definiuje indeks wyszukiwania.
Utwórz i uruchom indeksator , aby połączyć wszystkie powyższe składniki. Ten krok pobiera dane, uruchamia zestaw umiejętności i ładuje indeks.
Indeksator służy również do określania mapowań pól i mapowań pól wyjściowych, które konfigurują ścieżkę danych do indeksu wyszukiwania.
Opcjonalnie włącz buforowanie wzbogacania w konfiguracji indeksatora. Ten krok umożliwia późniejsze ponowne użycie istniejących wzbogacenia.
Uruchom zapytania , aby ocenić wyniki lub rozpocząć sesję debugowania, aby pracować z dowolnymi problemami z zestawem umiejętności.
Aby powtórzyć dowolny z powyższych kroków, zresetuj indeksator przed jego uruchomieniem. Możesz też usunąć i ponownie utworzyć obiekty w każdym uruchomieniu (zalecane, jeśli używasz warstwy Bezpłatna). Jeśli włączono buforowanie indeksatora ściąga z pamięci podręcznej, jeśli dane są niezmienione w źródle, a zmiany w potoku nie unieważniają pamięci podręcznej.
Następne kroki
- Szybki start: tworzenie zestawu umiejętności na potrzeby wzbogacania sztucznej inteligencji
- Samouczek: informacje o interfejsach API REST wzbogacania sztucznej inteligencji
- Pojęcia dotyczące zestawu umiejętności
- Pojęcia dotyczące magazynu wiedzy
- Tworzenie zestawu umiejętności
- Tworzenie magazynu wiedzy