Klasyfikacja semantyczna w usłudze Azure AI Search
W usłudze Azure AI Search semantyczne klasyfikowanie w sposób zrozumiały zwiększa istotność wyszukiwania przy użyciu interpretacji języka w celu ponownego generowania wyników wyszukiwania. Ten artykuł jest ogólnym wprowadzeniem. Sekcja na końcu obejmuje dostępność i ceny.
Ranga semantyczna to funkcja premium rozliczana według użycia. Zalecamy, aby zapoznać się z tym artykułem w tle, ale jeśli wolisz rozpocząć pracę, wykonaj następujące kroki:
- Sprawdzanie dostępności regionalnej
- Zaloguj się do witryny Azure Portal , aby sprawdzić, czy usługa wyszukiwania ma wartość Podstawowa lub nowsza
- Włączanie klasyfikacji semantycznej i wybieranie planu cenowego
- Konfigurowanie konfiguracji semantycznej w indeksie wyszukiwania
- Konfigurowanie zapytań w celu zwrócenia semantycznych podpis i wyróżnień
- Opcjonalnie zwracaj odpowiedzi semantyczne
Uwaga
Klasyfikacja semantyczna nie używa generowania sztucznej inteligencji ani wektorów. Jeśli szukasz obsługi wektorów i wyszukiwania podobieństwa? Aby uzyskać szczegółowe informacje, zobacz Wyszukiwanie wektorów w usłudze Azure AI Search .
Co to jest klasyfikacja semantyczna?
Ranga semantyczna to kolekcja funkcji związanych z zapytaniami, które zwiększają jakość początkowej klasyfikacji BM25 lub wynik wyszukiwania w rankingu RRF dla zapytań tekstowych. Po włączeniu jej w usłudze wyszukiwania semantyczny ranking rozszerza potok wykonywania zapytania na dwa sposoby:
Najpierw dodaje pomocniczy ranking dla początkowego zestawu wyników, który został wygenerowany przy użyciu protokołu BM25 lub RRF. Ten pomocniczy ranking używa wielojęzycznych modeli uczenia głębokiego dostosowanych od usługi Microsoft Bing do promowania najbardziej odpowiednich wyników.
Po drugie wyodrębnia i zwraca podpis i odpowiedzi w odpowiedzi, które można renderować na stronie wyszukiwania, aby poprawić środowisko wyszukiwania użytkownika.
Poniżej przedstawiono możliwości semantycznego korbowania.
| Funkcja | opis |
|---|---|
| Ranking semantyczny | Używa kontekstu lub semantycznego znaczenia zapytania, aby obliczyć nowy wynik istotności względem wstępnie sklasyfikowanych wyników. |
| Semantyczne podpis i wyróżnienia | Wyodrębnia zdania i frazy z dokumentu, które najlepiej podsumowują zawartość, z wyróżnionymi fragmentami kluczowymi w celu łatwego skanowania. Podpisy, które podsumowują wynik, są przydatne, gdy poszczególne pola zawartości są zbyt gęste dla strony wyników wyszukiwania. Wyróżniony tekst podnosi poziom najbardziej odpowiednich terminów i fraz, dzięki czemu użytkownicy mogą szybko określić, dlaczego dopasowanie zostało uznane za istotne. |
| Odpowiedzi semantyczne | Opcjonalna i dodatkowa struktura podrzędna zwrócona z zapytania semantycznego. Zapewnia bezpośrednią odpowiedź na zapytanie, które wygląda jak pytanie. Wymaga to, aby dokument miał tekst z cechami odpowiedzi. |
Jak działa semantyczny ranger
Klasyfikacja semantyczna generuje zapytanie i wyniki dla modeli interpretacji języka hostowanych przez firmę Microsoft i skanuje w celu uzyskania lepszych dopasowań.
Na poniższej ilustracji wyjaśniono koncepcję. Rozważ termin "capital". Ma różne znaczenie w zależności od tego, czy kontekst to finanse, prawo, geografia czy gramatyka. Dzięki zrozumieniu języka semantyczny ranga może wykrywać kontekst i podwyższyć poziom wyników pasujących do intencji zapytania.
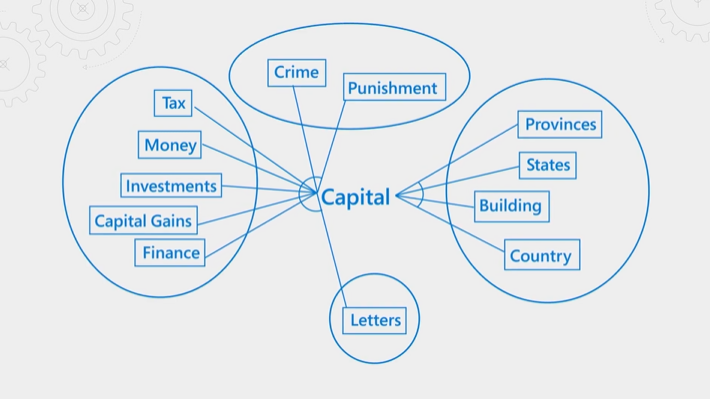
Klasyfikacja semantyczna jest zarówno zasobem, jak i czasochłonnym. Aby ukończyć przetwarzanie w oczekiwanym opóźnieniu operacji zapytania, dane wejściowe do semantycznego rangatora są konsolidowane i zmniejszane, aby można było wykonać krok ponownego korbowania tak szybko, jak to możliwe.
Klasyfikacja semantyczna to dwa kroki: podsumowanie i ocenianie. Dane wyjściowe składają się z wyników przesłonięć, podpis i odpowiedzi.
Jak są zbierane i podsumowane dane wejściowe
W klasyfikacji semantycznej podsystem zapytania przekazuje wyniki wyszukiwania jako dane wejściowe do modeli podsumowania i klasyfikowania. Ponieważ modele klasyfikacji mają ograniczenia rozmiaru danych wejściowych i intensywnie przetwarzają, wyniki wyszukiwania muszą mieć rozmiar i strukturę (podsumowaną) w celu wydajnej obsługi.
Klasyfikacja semantyczna rozpoczyna się od wyniku klasyfikacji BM25 z zapytania tekstowego lub wyniku klasyfikacji RRF z zapytania hybrydowego. Tylko pola tekstowe są używane w ćwiczeniu ponownego korekcyjnego, a tylko 50 pierwszych wyników postępuje do semantycznego rankingu, nawet jeśli wyniki zawierają więcej niż 50. Zazwyczaj pola używane w klasyfikacji semantycznej to informacje i opisowe.
Dla każdego dokumentu w wynikach wyszukiwania model podsumowania akceptuje maksymalnie 2000 tokenów, gdzie token ma około 10 znaków. Dane wejściowe są zbierane z pól "title", "keyword" i "content" wymienionych w konfiguracji semantycznej.
Zbyt długie ciągi są przycinane, aby zapewnić, że ogólna długość spełnia wymagania wejściowe kroku podsumowania. To ćwiczenie przycinania jest ważne, aby dodać pola do konfiguracji semantycznej w kolejności priorytetu. Jeśli masz bardzo duże dokumenty z polami z dużą ilością tekstu, wszystkie elementy po maksymalnym limicie są ignorowane.
Pole semantyczne Limit tokenu "title" 128 tokenów "słowa kluczowe 128 tokenów "zawartość" pozostałe tokeny Dane wyjściowe podsumowania to ciąg podsumowania dla każdego dokumentu składający się z najbardziej odpowiednich informacji z każdego pola. Ciągi sumaryczne są wysyłane do klasyfikatora oceniania oraz do modeli zrozumienia wyrozumiałość maszynowego dla podpis i odpowiedzi.
Maksymalna długość każdego wygenerowanego ciągu podsumowania przekazanego do semantycznego rankera to 256 tokenów.
Dane wyjściowe semantycznego rangatora
Z każdego ciągu podsumowania modele zrozumienia maszyny znajdują fragmenty, które są najbardziej reprezentatywne.
Dane wyjściowe to:
Semantyczny podpis dla dokumentu. Każda podpis jest dostępna w wersji zwykłego tekstu i wersji wyróżnienia i często jest mniejsza niż 200 wyrazów na dokument.
Opcjonalna odpowiedź semantyczna, przy założeniu
answers, że określono parametr, zapytanie zostało zadane jako pytanie, a fragment znajduje się w długim ciągu, który zapewnia prawdopodobną odpowiedź na pytanie.
Transkrypty i odpowiedzi są zawsze tekstem dosłowny z indeksu. W tym przepływie pracy nie ma generowania modelu sztucznej inteligencji, który tworzy lub komponuje nową zawartość.
Jak są oceniane podsumowania
Ocenianie odbywa się na podpis i dowolnej innej zawartości z ciągu podsumowania, który wypełnia długość tokenu 256.
Podpisy są oceniane pod kątem istotności koncepcyjnej i semantycznej względem podanego zapytania.
Element @search.rerankerScore jest przypisywany do każdego dokumentu na podstawie semantycznego istotności dokumentu dla danego zapytania. Wyniki wahają się od 4 do 0 (wysoki do niskich), gdzie wyższy wynik wskazuje na większe znaczenie.
Dopasowania są wyświetlane w kolejności malejącej według wyniku i uwzględnione w ładunku odpowiedzi zapytania. Ładunek zawiera odpowiedzi, zwykły tekst i wyróżnione podpis oraz wszystkie pola oznaczone jako możliwe do pobrania lub określone w klauzuli select.
Uwaga
Od 14 lipca 2023 r. zmienia się rozkład @search.rerankerScore . Nie można określić wpływu na wyniki z wyjątkiem testowania. Jeśli masz twardą zależność progową od tej właściwości odpowiedzi, uruchom ponownie testy, aby zrozumieć, jakie nowe wartości powinny być dla progu.
Możliwości i ograniczenia semantyczne
Semantyczny ranger to nowsza technologia, dlatego ważne jest, aby określić oczekiwania dotyczące tego, co może i nie może zrobić. Co może zrobić:
Podwyższanie poziomu dopasowań, które są semantycznie bliżej intencji oryginalnego zapytania.
Znajdź ciągi do użycia jako podpis i odpowiedzi. Podpisy i odpowiedzi są zwracane w odpowiedzi i mogą być renderowane na stronie wyników wyszukiwania.
Nie można wykonać klasyfikacji semantycznej, to ponowne uruchomienie zapytania w całym korpusie w celu znalezienia semantycznie odpowiednich wyników. Klasyfikacja semantyczna ponownie korbuje istniejący zestaw wyników, składający się z 50 najlepszych wyników według domyślnego algorytmu klasyfikacji. Ponadto semantyczny ranking nie może tworzyć nowych informacji ani ciągów. Transkrypty i odpowiedzi są wyodrębniane ze swojej zawartości, więc jeśli wyniki nie zawierają tekstu przypominającego odpowiedź, modele językowe nie będą je tworzyć.
Mimo że klasyfikacja semantyczna nie jest korzystna w każdym scenariuszu, niektóre treści mogą znacznie korzystać z jego możliwości. Modele językowe w klasyfikacji semantycznej najlepiej sprawdzają się w zawartości z możliwością wyszukiwania, która jest bogata w informacje i ustrukturyzowana jako proza. Baza wiedzy, dokumentacja online lub dokumenty zawierające opisową zawartość widzą największe korzyści z semantycznych możliwości klasyfikacji.
Podstawową technologią jest Bing i Microsoft Research oraz zintegrowana z infrastrukturą usługi Azure AI Search jako funkcja dodatku. Aby uzyskać więcej informacji na temat badań i inwestycji w sztuczną inteligencję na potrzeby klasyfikacji semantycznej, zobacz How AI from Bing is powering Azure AI Search (Microsoft Research Blog).
Poniższy film wideo zawiera omówienie możliwości.
Dostępność i cennik
Ranga semantyczna jest dostępna w usługach wyszukiwania w warstwach Podstawowa i wyższa, z zastrzeżeniem dostępności regionalnej.
Po włączeniu semantycznego rangatora wybierz plan cenowy dla funkcji:
- W przypadku mniejszych woluminów zapytań (poniżej 1000 miesięcznych) klasyfikacja semantyczna jest bezpłatna.
- W przypadku większych woluminów zapytań wybierz standardowy plan cenowy.
Na stronie cennika usługi Azure AI Search przedstawiono stawkę rozliczeniową dla różnych walut i interwałów.
Opłaty za klasyfikację semantyczną są naliczane, gdy żądania zapytania obejmują queryType=semantic , a ciąg wyszukiwania nie jest pusty (na przykład search=pet friendly hotels in New York). Jeśli ciąg wyszukiwania jest pusty (search=*), opłaty nie są naliczane, nawet jeśli właściwość queryType jest ustawiona na semantyczną.