Monitorowanie usługi Site Recovery przy użyciu dzienników usługi Azure Monitor
W tym artykule opisano sposób monitorowania maszyn replikowanych przez usługę Azure Site Recovery przy użyciu dzienników usługi Azure Monitor i usługi Log Analytics.
Dzienniki usługi Azure Monitor udostępniają platformę danych dziennika, która zbiera dzienniki aktywności i dzienniki zasobów oraz inne dane monitorowania. W dziennikach usługi Azure Monitor używasz usługi Log Analytics do pisania i testowania zapytań dziennika oraz interaktywnego analizowania danych dziennika. Możesz wizualizować wyniki dziennika i wykonywać zapytania oraz konfigurować alerty w celu wykonywania akcji na podstawie monitorowanych danych.
W przypadku Site Recovery możesz użyć dzienników usługi Azure Monitor, aby ułatwić wykonanie następujących czynności:
- Monitorowanie Site Recovery kondycji i stanu. Można na przykład monitorować kondycję replikacji, testować stan trybu failover, zdarzenia Site Recovery, cele punktu odzyskiwania (RPO) dla chronionych maszyn oraz współczynniki zmian dysku/danych.
- Skonfiguruj alerty dla Site Recovery. Można na przykład skonfigurować alerty dotyczące kondycji maszyny, stanu testowania trybu failover lub stanu zadania Site Recovery.
Korzystanie z dzienników usługi Azure Monitor z Site Recovery jest obsługiwane w przypadku replikacji platformy Azure do platformy Azure i replikacji maszyny wirtualnej/serwera fizycznego VMware do platformy Azure.
Uwaga
Aby uzyskać dzienniki danych zmian i przekazać dzienniki szybkości dla oprogramowania VMware i maszyn fizycznych, należy zainstalować agenta monitorowania firmy Microsoft na serwerze przetwarzania. Ten agent wysyła dzienniki maszyn replikujących do obszaru roboczego. Ta funkcja jest dostępna tylko dla nowszej wersji agenta mobilności w wersji 9.30.
Wymagania wstępne
Oto, co jest potrzebne:
- Co najmniej jedna maszyna jest chroniona w magazynie usługi Recovery Services.
- Obszar roboczy usługi Log Analytics do przechowywania dzienników Site Recovery. Dowiedz się więcej o konfigurowaniu obszaru roboczego.
- Podstawowa wiedza na temat pisania, uruchamiania i analizowania zapytań dzienników w usłudze Log Analytics. Dowiedz się więcej.
Przed rozpoczęciem zalecamy przejrzenie typowych pytań dotyczących monitorowania .
Konfigurowanie Site Recovery do wysyłania dzienników
W magazynie wybierz pozycję Ustawienia> diagnostyczneDodaj ustawienie diagnostyczne.
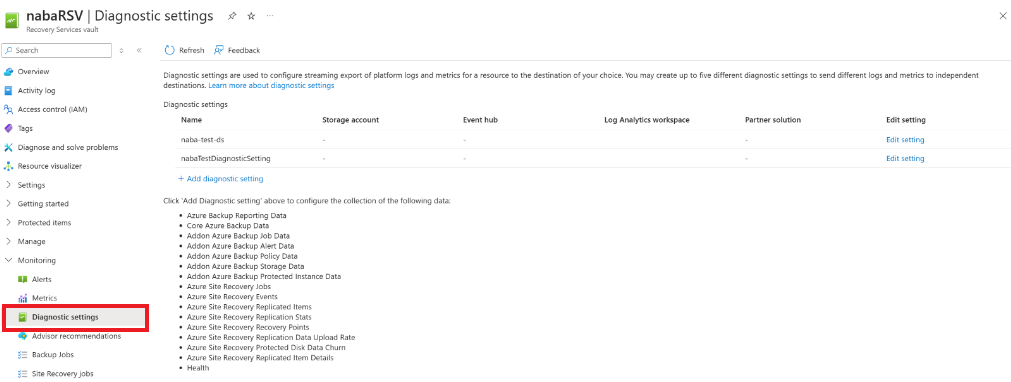
W obszarze Ustawienia diagnostyczne określ nazwę i zaznacz pole Wyboru Wyślij do usługi Log Analytics.
Wybierz subskrypcję dzienników usługi Azure Monitor i obszar roboczy usługi Log Analytics.
Wybierz pozycję Diagnostyka Azure w przełączniku.
Z listy dzienników wybierz wszystkie dzienniki z prefiksem AzureSiteRecovery. Następnie wybierz przycisk OK.

Dzienniki Site Recovery zaczynają być wprowadzane do tabeli (AzureDiagnostics) w wybranym obszarze roboczym.
Konfigurowanie agenta monitorowania firmy Microsoft na serwerze przetwarzania w celu wysyłania dzienników współczynnika zmian i przekazywania
Możesz przechwycić informacje o współczynniku zmian danych i informacje o szybkości przekazywania danych źródłowych dla maszyn wirtualnych VMware/fizycznych w środowisku lokalnym. Aby to włączyć, agent monitorowania firmy Microsoft jest wymagany do zainstalowania na serwerze przetwarzania.
Przejdź do obszaru roboczego usługi Log Analytics i wybierz pozycję Ustawienia zaawansowane.
Wybierz stronę Połączone źródła , a następnie wybierz pozycję Serwery z systemem Windows.
Pobierz agenta systemu Windows (64-bitowego) na serwerze przetwarzania.
Ukończ instalację agenta , podając uzyskany identyfikator i klucz obszaru roboczego.
Po zakończeniu instalacji przejdź do obszaru roboczego usługi Log Analytics i wybierz pozycję Zarządzanie starszymi agentami. Przejdź do strony Dane i wybierz pozycję Liczniki wydajności systemu Windows.
Wybierz pozycję "+", aby dodać następujące dwa liczniki z przykładowym interwałem wynoszącym 300 sekund:
- ASRAnalytics(*)\SourceVmChurnRate
- ASRAnalytics(*)\SourceVmThrpRate
Dane współczynnika zmian i przekazywania zaczną przekazywać dane do obszaru roboczego.
Wykonywanie zapytań dotyczących dzienników — przykłady
Dane są pobierane z dzienników przy użyciu zapytań dziennika napisanych za pomocą języka zapytań Kusto. Ta sekcja zawiera kilka przykładów typowych zapytań, których można użyć do monitorowania Site Recovery.
Uwaga
W niektórych przykładach użyto replicationProviderName_s ustawionej na wartość A2A. Spowoduje to pobranie maszyn wirtualnych platformy Azure replikowanych do pomocniczego regionu platformy Azure przy użyciu Site Recovery. W tych przykładach możesz zastąpić usługę A2Amaszyną wirtualną InMageRcm, jeśli chcesz pobrać lokalne maszyny wirtualne VMware lub serwery fizyczne replikowane na platformę Azure przy użyciu Site Recovery.
Kondycja replikacji zapytań
To zapytanie wykreśli wykres kołowy dla bieżącej kondycji replikacji wszystkich chronionych maszyn wirtualnych platformy Azure podzielonych na trzy stany: Normalny, Ostrzegawczy lub Krytyczny.
AzureDiagnostics
| where replicationProviderName_s == "A2A"
| where isnotempty(name_s) and isnotnull(name_s)
| summarize hint.strategy=partitioned arg_max(TimeGenerated, *) by name_s
| project name_s , replicationHealth_s
| summarize count() by replicationHealth_s
| render piechart
Wykonywanie zapytań o wersję usługa mobilności
To zapytanie wykreśla wykres kołowy dla maszyn wirtualnych platformy Azure replikowanych przy użyciu Site Recovery, podzielonego na wersję uruchomionego agenta mobilności.
AzureDiagnostics
| where replicationProviderName_s == "A2A"
| where isnotempty(name_s) and isnotnull(name_s)
| summarize hint.strategy=partitioned arg_max(TimeGenerated, *) by name_s
| project name_s , agentVersion_s
| summarize count() by agentVersion_s
| render piechart
Czas wykonywania zapytań o cel punktu odzyskiwania
To zapytanie wykreśla wykres słupkowy maszyn wirtualnych platformy Azure replikowanych przy użyciu Site Recovery, podzielonego na cel punktu odzyskiwania (RPO): mniej niż 15 minut z zakresu od 15 do 30 minut, ponad 30 minut.
AzureDiagnostics
| where replicationProviderName_s == "A2A"
| where isnotempty(name_s) and isnotnull(name_s)
| extend RPO = case(rpoInSeconds_d <= 900, "<15Min",
rpoInSeconds_d <= 1800, "15-30Min", ">30Min")
| summarize hint.strategy=partitioned arg_max(TimeGenerated, *) by name_s
| project name_s , RPO
| summarize Count = count() by RPO
| render barchart

Wykonywanie zapytań dotyczących zadań Site Recovery
To zapytanie pobiera wszystkie zadania Site Recovery (dla wszystkich scenariuszy odzyskiwania po awarii), wyzwalane w ciągu ostatnich 72 godzin i ich stan ukończenia.
AzureDiagnostics
| where Category == "AzureSiteRecoveryJobs"
| where TimeGenerated >= ago(72h)
| project JobName = OperationName , VaultName = Resource , TargetName = affectedResourceName_s, State = ResultType
Wykonywanie zapytań o zdarzenia Site Recovery
To zapytanie pobiera wszystkie zdarzenia Site Recovery (dla wszystkich scenariuszy odzyskiwania po awarii) zgłoszone w ciągu ostatnich 72 godzin wraz z ich ważnością.
AzureDiagnostics
| where Category == "AzureSiteRecoveryEvents"
| where TimeGenerated >= ago(72h)
| project AffectedObject=affectedResourceName_s , VaultName = Resource, Description_s = healthErrors_s , Severity = Level
Testowy stan pracy w trybie failover zapytania (wykres kołowy)
To zapytanie wykreśla wykres kołowy dla stanu testowego trybu failover maszyn wirtualnych platformy Azure replikowanych przy użyciu Site Recovery.
AzureDiagnostics
| where replicationProviderName_s == "A2A"
| where isnotempty(name_s) and isnotnull(name_s)
| where isnotempty(failoverHealth_s) and isnotnull(failoverHealth_s)
| summarize hint.strategy=partitioned arg_max(TimeGenerated, *) by name_s
| project name_s , Resource, failoverHealth_s
| summarize count() by failoverHealth_s
| render piechart
Testowy stan pracy w trybie failover zapytania (tabela)
To zapytanie wykreśla tabelę stanu testowego trybu failover maszyn wirtualnych platformy Azure replikowanych przy użyciu Site Recovery.
AzureDiagnostics
| where replicationProviderName_s == "A2A"
| where isnotempty(name_s) and isnotnull(name_s)
| where isnotempty(failoverHealth_s) and isnotnull(failoverHealth_s)
| summarize hint.strategy=partitioned arg_max(TimeGenerated, *) by name_s
| project VirtualMachine = name_s , VaultName = Resource , TestFailoverStatus = failoverHealth_s
Wykonywanie zapytań o cel punktu odzyskiwania maszyny
To zapytanie wykreśli wykres trendu, który śledzi cel punktu odzyskiwania określonej maszyny wirtualnej platformy Azure (ContosoVM123) w ciągu ostatnich 72 godzin.
AzureDiagnostics
| where replicationProviderName_s == "A2A"
| where TimeGenerated > ago(72h)
| where isnotempty(name_s) and isnotnull(name_s)
| where name_s == "ContosoVM123"
| project TimeGenerated, name_s , RPO_in_seconds = rpoInSeconds_d
| render timechart

Wykonywanie zapytań dotyczących współczynnika zmian danych (współczynnik zmian) i szybkość przekazywania dla maszyny wirtualnej platformy Azure
To zapytanie wykreśli wykres trendu dla określonej maszyny wirtualnej platformy Azure (ContosoVM123), która reprezentuje współczynnik zmian danych (bajty zapisu na sekundę) i szybkość przekazywania danych.
AzureDiagnostics
| where Category in ("AzureSiteRecoveryProtectedDiskDataChurn", "AzureSiteRecoveryReplicationDataUploadRate")
| extend CategoryS = case(Category contains "Churn", "DataChurn",
Category contains "Upload", "UploadRate", "none")
| extend InstanceWithType=strcat(CategoryS, "_", InstanceName_s)
| where TimeGenerated > ago(24h)
| where InstanceName_s startswith "ContosoVM123"
| project TimeGenerated , InstanceWithType , Churn_MBps = todouble(Value_s)/1048576
| render timechart
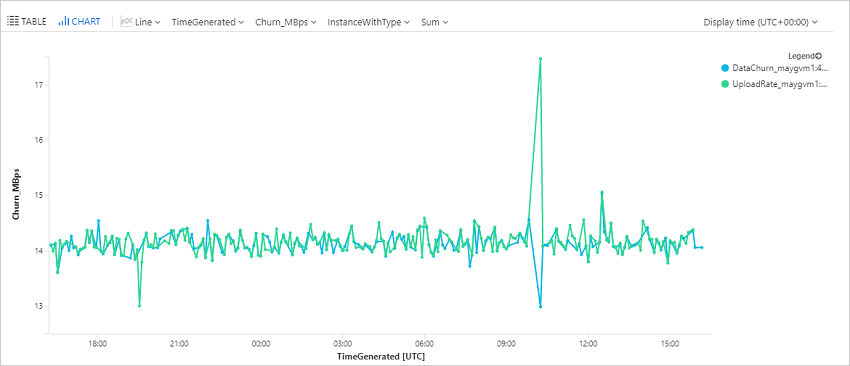
Wykonywanie zapytań dotyczących współczynnika zmian danych (współczynnik zmian) i szybkość przekazywania dla maszyny wirtualnej lub fizycznej
Uwaga
Upewnij się, że skonfigurowaliśmy agenta monitorowania na serwerze przetwarzania, aby pobrać te dzienniki. Zapoznaj się z krokami konfigurowania agenta monitorowania.
To zapytanie przedstawia wykres trendu dla określonego dysku, dysku0, z replikowanego elementu, win-9r7sfh9qlru, który reprezentuje współczynnik zmian danych (bajty zapisu na sekundę) i szybkość przekazywania danych. Nazwę dysku można znaleźć w bloku Dyski zreplikowanego elementu w magazynie usługi Recovery Services. Nazwa wystąpienia do użycia w zapytaniu to nazwa DNS maszyny, po której następuje _ i nazwa dysku, jak w tym przykładzie.
Perf
| where ObjectName == "ASRAnalytics"
| where InstanceName contains "win-9r7sfh9qlru_disk0"
| where TimeGenerated >= ago(4h)
| project TimeGenerated ,CounterName, Churn_MBps = todouble(CounterValue)/5242880
| render timechart
Serwer przetwarzania wypycha te dane co 5 minut do obszaru roboczego usługi Log Analytics. Te punkty danych reprezentują średnią obliczoną przez 5 minut.
Podsumowanie odzyskiwania po awarii (platforma Azure do platformy Azure)
To zapytanie wykreśla tabelę podsumowania dla maszyn wirtualnych platformy Azure replikowanych do pomocniczego regionu świadczenia usługi Azure. Przedstawia ona nazwę, replikację i stan ochrony maszyny wirtualnej, cel punktu odzyskiwania, stan testu pracy w trybie failover, wersję agenta mobilności, wszelkie aktywne błędy replikacji i lokalizację źródłową.
AzureDiagnostics
| where replicationProviderName_s == "A2A"
| where isnotempty(name_s) and isnotnull(name_s)
| summarize hint.strategy=partitioned arg_max(TimeGenerated, *) by name_s
| project VirtualMachine = name_s , Vault = Resource , ReplicationHealth = replicationHealth_s, Status = protectionState_s, RPO_in_seconds = rpoInSeconds_d, TestFailoverStatus = failoverHealth_s, AgentVersion = agentVersion_s, ReplicationError = replicationHealthErrors_s, SourceLocation = primaryFabricName_s
Podsumowanie odzyskiwania po awarii zapytań (serwery VMware/fizyczne)
To zapytanie wykreśla tabelę podsumowania maszyn wirtualnych VMware i serwerów fizycznych replikowanych na platformę Azure. Przedstawia ona nazwę maszyny, stan replikacji i ochrony, cel punktu odzyskiwania, stan testu pracy w trybie failover, wersję agenta mobilności, wszelkie aktywne błędy replikacji i odpowiedni serwer przetwarzania.
AzureDiagnostics
| where replicationProviderName_s == "InMageRcm"
| where isnotempty(name_s) and isnotnull(name_s)
| summarize hint.strategy=partitioned arg_max(TimeGenerated, *) by name_s
| project VirtualMachine = name_s , Vault = Resource , ReplicationHealth = replicationHealth_s, Status = protectionState_s, RPO_in_seconds = rpoInSeconds_d, TestFailoverStatus = failoverHealth_s, AgentVersion = agentVersion_s, ReplicationError = replicationHealthErrors_s, ProcessServer = processServerName_g
Konfigurowanie alertów — przykłady
Alerty Site Recovery można skonfigurować na podstawie danych usługi Azure Monitor. Dowiedz się więcej na temat konfigurowania alertów dzienników.
Uwaga
W niektórych przykładach użyto replicationProviderName_s ustawionej na wartość A2A. Spowoduje to ustawienie alertów dla maszyn wirtualnych platformy Azure replikowanych do pomocniczego regionu świadczenia usługi Azure. W tych przykładach możesz zastąpić usługę A2A maszyną wirtualną InMageRcm , jeśli chcesz ustawić alerty dla lokalnych maszyn wirtualnych VMware lub serwerów fizycznych replikowanych na platformę Azure.
Wiele maszyn w stanie krytycznym
Skonfiguruj alert, jeśli więcej niż 20 replikowanych maszyn wirtualnych platformy Azure przejdzie w stan krytyczny.
AzureDiagnostics
| where replicationProviderName_s == "A2A"
| where replicationHealth_s == "Critical"
| where isnotempty(name_s) and isnotnull(name_s)
| summarize hint.strategy=partitioned arg_max(TimeGenerated, *) by name_s
| summarize count()
W przypadku alertu ustaw wartość progu na 20wartość .
Pojedyncza maszyna w stanie krytycznym
Skonfiguruj alert, jeśli określona zreplikowana maszyna wirtualna platformy Azure przechodzi w stan krytyczny.
AzureDiagnostics
| where replicationProviderName_s == "A2A"
| where replicationHealth_s == "Critical"
| where name_s == "ContosoVM123"
| where isnotempty(name_s) and isnotnull(name_s)
| summarize hint.strategy=partitioned arg_max(TimeGenerated, *) by name_s
| summarize count()
W przypadku alertu ustaw wartość progu na 1wartość .
Wiele maszyn przekracza cel punktu odzyskiwania
Skonfiguruj alert, jeśli cel punktu odzyskiwania dla ponad 20 maszyn wirtualnych platformy Azure przekracza 30 minut.
AzureDiagnostics
| where replicationProviderName_s == "A2A"
| where isnotempty(name_s) and isnotnull(name_s)
| where rpoInSeconds_d > 1800
| summarize hint.strategy=partitioned arg_max(TimeGenerated, *) by name_s
| project name_s , rpoInSeconds_d
| summarize count()
W przypadku alertu ustaw wartość progu na 20wartość .
Pojedyncza maszyna przekracza cel punktu odzyskiwania
Skonfiguruj alert, jeśli cel punktu odzyskiwania dla pojedynczej maszyny wirtualnej platformy Azure przekracza 30 minut.
AzureDiagnostics
| where replicationProviderName_s == "A2A"
| where isnotempty(name_s) and isnotnull(name_s)
| where name_s == "ContosoVM123"
| where rpoInSeconds_d > 1800
| summarize hint.strategy=partitioned arg_max(TimeGenerated, *) by name_s
| project name_s , rpoInSeconds_d
| summarize count()
W przypadku alertu ustaw wartość progu na 1wartość .
Test pracy w trybie failover dla wielu maszyn przekracza 90 dni
Skonfiguruj alert, jeśli ostatni pomyślny test pracy w trybie failover wynosił ponad 90 dni, dla ponad 20 maszyn wirtualnych.
AzureDiagnostics
| where replicationProviderName_s == "A2A"
| where Category == "AzureSiteRecoveryReplicatedItems"
| where isnotempty(name_s) and isnotnull(name_s)
| where lastSuccessfulTestFailoverTime_t <= ago(90d)
| summarize hint.strategy=partitioned arg_max(TimeGenerated, *) by name_s
| summarize count()
W przypadku alertu ustaw wartość progu na 20wartość .
Testowanie pracy w trybie failover dla pojedynczej maszyny przekracza 90 dni
Skonfiguruj alert, jeśli ostatnio pomyślny test pracy w trybie failover dla określonej maszyny wirtualnej wynosił ponad 90 dni temu.
AzureDiagnostics
| where replicationProviderName_s == "A2A"
| where Category == "AzureSiteRecoveryReplicatedItems"
| where isnotempty(name_s) and isnotnull(name_s)
| where lastSuccessfulTestFailoverTime_t <= ago(90d)
| where name_s == "ContosoVM123"
| summarize hint.strategy=partitioned arg_max(TimeGenerated, *) by name_s
| summarize count()
W przypadku alertu ustaw wartość progu na 1wartość .
zadanie Site Recovery kończy się niepowodzeniem
Skonfiguruj alert, jeśli zadanie Site Recovery (w tym przypadku zadanie ponownego włączania ochrony) zakończy się niepowodzeniem dla dowolnego scenariusza Site Recovery w ciągu ostatniego dnia.
AzureDiagnostics
| where Category == "AzureSiteRecoveryJobs"
| where OperationName == "Reprotect"
| where ResultType == "Failed"
| summarize count()
W przypadku alertu ustaw wartość progu na 1, a wartość Okres na 1440 minut, aby sprawdzić błędy w ciągu ostatniego dnia.
Następne kroki
Dowiedz się więcej o wbudowanym monitorowaniu Site Recovery.