Samouczek: tworzenie aplikacji uczenia maszynowego za pomocą biblioteki MLlib platformy Apache Spark i usługi Azure Synapse Analytics
W tym artykule dowiesz się, jak za pomocą biblioteki MLlib platformy Apache Spark utworzyć aplikację uczenia maszynowego, która wykonuje prostą analizę predykcyjną na otwartym zestawie danych platformy Azure. Platforma Spark udostępnia wbudowane biblioteki uczenia maszynowego. W tym przykładzie użyto klasyfikacji za pomocą regresji logistycznej.
SparkML i MLlib to podstawowe biblioteki Platformy Spark, które udostępniają wiele narzędzi, które są przydatne w przypadku zadań uczenia maszynowego, w tym narzędzi odpowiednich dla:
- Klasyfikacja
- Regresja
- Klastrowanie
- Modelowanie tematów
- Dekompozycja wartości pojedynczej (SVD) i analiza głównych składników (PCA)
- Testowanie hipotez i obliczanie przykładowych statystyk
Omówienie regresji klasyfikacji i logistyki
Klasyfikacja, popularne zadanie uczenia maszynowego, to proces sortowania danych wejściowych w kategorie. Jest to zadanie algorytmu klasyfikacji, aby dowiedzieć się, jak przypisać etykiety do danych wejściowych, które podajesz. Można na przykład myśleć o algorytmie uczenia maszynowego, który akceptuje informacje o zapasach jako dane wejściowe i dzieli akcje na dwie kategorie: zapasy, które należy sprzedawać i zapasy, które należy zachować.
Regresja logistyczna to algorytm, którego można użyć do klasyfikacji. Interfejs API regresji logistycznej platformy Spark jest przydatny do klasyfikacji binarnej lub klasyfikowania danych wejściowych w jedną z dwóch grup. Aby uzyskać więcej informacji na temat regresji logistycznej, zobacz Wikipedia.
Podsumowując, proces regresji logistycznej tworzy funkcję logistyczną , której można użyć do przewidywania prawdopodobieństwa, że wektor wejściowy należy do jednej grupy lub drugiej.
Przykład analizy predykcyjnej danych taksówek NYC
W tym przykładzie użyjesz platformy Spark do przeprowadzenia analizy predykcyjnej na podstawie danych porad dotyczących taksówek z Nowego Jorku. Dane są dostępne za pośrednictwem usługi Azure Open Datasets. Ten podzestaw zestawu danych zawiera informacje o żółtych przejazdach taksówką, w tym informacje o każdej podróży, czasie rozpoczęcia i zakończenia oraz lokalizacjach, kosztach i innych interesujących atrybutach.
Ważne
Mogą istnieć dodatkowe opłaty za ściąganie tych danych z lokalizacji przechowywania.
W poniższych krokach utworzysz model, aby przewidzieć, czy określona podróż zawiera poradę, czy nie.
Tworzenie modelu uczenia maszynowego platformy Apache Spark
Utwórz notes przy użyciu jądra PySpark. Aby uzyskać instrukcje, zobacz Tworzenie notesu.
Zaimportuj typy wymagane dla tej aplikacji. Skopiuj i wklej następujący kod do pustej komórki, a następnie naciśnij klawisze Shift+Enter. Możesz też uruchomić komórkę przy użyciu niebieskiej ikony odtwarzania po lewej stronie kodu.
import matplotlib.pyplot as plt from datetime import datetime from dateutil import parser from pyspark.sql.functions import unix_timestamp, date_format, col, when from pyspark.ml import Pipeline from pyspark.ml import PipelineModel from pyspark.ml.feature import RFormula from pyspark.ml.feature import OneHotEncoder, StringIndexer, VectorIndexer from pyspark.ml.classification import LogisticRegression from pyspark.mllib.evaluation import BinaryClassificationMetrics from pyspark.ml.evaluation import BinaryClassificationEvaluatorZe względu na jądro PySpark nie trzeba jawnie tworzyć żadnych kontekstów. Kontekst platformy Spark jest automatycznie tworzony podczas uruchamiania pierwszej komórki kodu.
Konstruowanie wejściowej ramki danych
Ponieważ nieprzetworzone dane są w formacie Parquet, możesz użyć kontekstu spark, aby ściągnąć plik do pamięci jako ramkę danych bezpośrednio. Mimo że kod w poniższych krokach używa opcji domyślnych, w razie potrzeby można wymusić mapowanie typów danych i innych atrybutów schematu.
Uruchom następujące wiersze, aby utworzyć ramkę danych Platformy Spark, wklejając kod do nowej komórki. Ten krok pobiera dane za pośrednictwem interfejsu API Open Datasets. Ściąganie wszystkich tych danych generuje około 1,5 miliarda wierszy.
W zależności od rozmiaru bezserwerowej puli platformy Apache Spark nieprzetworzone dane mogą być zbyt duże lub zbyt dużo czasu na działanie. Te dane można filtrować w dół do czegoś mniejszego. W poniższym przykładzie kodu użyto
start_datemetody iend_datezastosowano filtr, który zwraca jeden miesiąc danych.from azureml.opendatasets import NycTlcYellow from datetime import datetime from dateutil import parser end_date = parser.parse('2018-05-08 00:00:00') start_date = parser.parse('2018-05-01 00:00:00') nyc_tlc = NycTlcYellow(start_date=start_date, end_date=end_date) filtered_df = spark.createDataFrame(nyc_tlc.to_pandas_dataframe())Wadą prostego filtrowania jest to, że z perspektywy statystycznej może to spowodować odchylenie do danych. Innym podejściem jest użycie próbkowania wbudowanego w platformę Spark.
Poniższy kod zmniejsza zestaw danych do około 2000 wierszy, jeśli zostanie zastosowany po poprzednim kodzie. Ten krok próbkowania można użyć zamiast prostego filtru lub w połączeniu z prostym filtrem.
# To make development easier, faster, and less expensive, downsample for now sampled_taxi_df = filtered_df.sample(True, 0.001, seed=1234)Teraz można przyjrzeć się danym, aby zobaczyć, co zostało odczytane. Zwykle lepiej jest przeglądać dane z podzestawem, a nie pełnym zestawem, w zależności od rozmiaru zestawu danych.
Poniższy kod oferuje dwa sposoby wyświetlania danych. Pierwszy sposób jest podstawowy. Drugi sposób zapewnia znacznie bogatsze środowisko siatki wraz z możliwością graficznego wizualizowania danych.
#sampled_taxi_df.show(5) display(sampled_taxi_df)W zależności od rozmiaru wygenerowanego zestawu danych i konieczności wielokrotnego eksperymentowania lub uruchamiania notesu może być konieczne buforowanie zestawu danych lokalnie w obszarze roboczym. Istnieją trzy sposoby wykonywania jawnego buforowania:
- Zapisz obiekt DataFrame lokalnie jako plik.
- Zapisz ramkę danych jako tymczasową tabelę lub widok.
- Zapisz ramkę danych jako stałą tabelę.
Pierwsze dwa z tych podejść są uwzględnione w poniższych przykładach kodu.
Tworzenie tabeli tymczasowej lub widoku zapewnia różne ścieżki dostępu do danych, ale trwa tylko przez czas trwania sesji wystąpienia platformy Spark.
sampled_taxi_df.createOrReplaceTempView("nytaxi")
Przygotowywanie danych
Dane w postaci pierwotnej często nie nadają się do przekazywania bezpośrednio do modelu. Musisz wykonać serię akcji na danych, aby uzyskać je do stanu, w którym model może z niego korzystać.
W poniższym kodzie wykonasz cztery klasy operacji:
- Usunięcie wartości odstających lub nieprawidłowych przez filtrowanie.
- Usunięcie kolumn, które nie są potrzebne.
- Tworzenie nowych kolumn pochodzących z danych pierwotnych w celu zwiększenia efektywnej pracy modelu. Ta operacja jest czasami nazywana cechacją.
- Etykietowania. Ponieważ podejmujesz klasyfikację binarną (czy w danej podróży nie będzie porada), konieczne jest przekonwertowanie kwoty końcówki na wartość 0 lub 1.
taxi_df = sampled_taxi_df.select('totalAmount', 'fareAmount', 'tipAmount', 'paymentType', 'rateCodeId', 'passengerCount'\
, 'tripDistance', 'tpepPickupDateTime', 'tpepDropoffDateTime'\
, date_format('tpepPickupDateTime', 'hh').alias('pickupHour')\
, date_format('tpepPickupDateTime', 'EEEE').alias('weekdayString')\
, (unix_timestamp(col('tpepDropoffDateTime')) - unix_timestamp(col('tpepPickupDateTime'))).alias('tripTimeSecs')\
, (when(col('tipAmount') > 0, 1).otherwise(0)).alias('tipped')
)\
.filter((sampled_taxi_df.passengerCount > 0) & (sampled_taxi_df.passengerCount < 8)\
& (sampled_taxi_df.tipAmount >= 0) & (sampled_taxi_df.tipAmount <= 25)\
& (sampled_taxi_df.fareAmount >= 1) & (sampled_taxi_df.fareAmount <= 250)\
& (sampled_taxi_df.tipAmount < sampled_taxi_df.fareAmount)\
& (sampled_taxi_df.tripDistance > 0) & (sampled_taxi_df.tripDistance <= 100)\
& (sampled_taxi_df.rateCodeId <= 5)
& (sampled_taxi_df.paymentType.isin({"1", "2"}))
)
Następnie utworzysz drugie przekazanie danych, aby dodać końcowe funkcje.
taxi_featurised_df = taxi_df.select('totalAmount', 'fareAmount', 'tipAmount', 'paymentType', 'passengerCount'\
, 'tripDistance', 'weekdayString', 'pickupHour','tripTimeSecs','tipped'\
, when((taxi_df.pickupHour <= 6) | (taxi_df.pickupHour >= 20),"Night")\
.when((taxi_df.pickupHour >= 7) & (taxi_df.pickupHour <= 10), "AMRush")\
.when((taxi_df.pickupHour >= 11) & (taxi_df.pickupHour <= 15), "Afternoon")\
.when((taxi_df.pickupHour >= 16) & (taxi_df.pickupHour <= 19), "PMRush")\
.otherwise(0).alias('trafficTimeBins')
)\
.filter((taxi_df.tripTimeSecs >= 30) & (taxi_df.tripTimeSecs <= 7200))
Tworzenie modelu regresji logistycznej
Ostatnim zadaniem jest przekonwertowanie oznaczonych danych na format, który można analizować za pomocą regresji logistycznej. Dane wejściowe algorytmu regresji logistycznej muszą być zestawem par wektorów etykiet/cech, gdzie wektor funkcji jest wektorem liczb reprezentujących punkt wejściowy.
Dlatego należy przekonwertować kolumny kategorii na liczby. W szczególności należy przekonwertować trafficTimeBins kolumny i weekdayString na reprezentacje całkowite. Istnieje wiele metod przeprowadzania konwersji. Poniższy przykład przyjmuje OneHotEncoder podejście, które jest typowe.
# Because the sample uses an algorithm that works only with numeric features, convert them so they can be consumed
sI1 = StringIndexer(inputCol="trafficTimeBins", outputCol="trafficTimeBinsIndex")
en1 = OneHotEncoder(dropLast=False, inputCol="trafficTimeBinsIndex", outputCol="trafficTimeBinsVec")
sI2 = StringIndexer(inputCol="weekdayString", outputCol="weekdayIndex")
en2 = OneHotEncoder(dropLast=False, inputCol="weekdayIndex", outputCol="weekdayVec")
# Create a new DataFrame that has had the encodings applied
encoded_final_df = Pipeline(stages=[sI1, en1, sI2, en2]).fit(taxi_featurised_df).transform(taxi_featurised_df)
Ta akcja powoduje utworzenie nowej ramki danych ze wszystkimi kolumnami w odpowiednim formacie w celu wytrenowania modelu.
Trenowanie modelu regresji logistycznej
Pierwszym zadaniem jest podzielenie zestawu danych na zestaw treningowy i zestaw testowania lub walidacji. Podział w tym miejscu jest dowolny. Eksperymentuj z różnymi ustawieniami podziału, aby sprawdzić, czy mają wpływ na model.
# Decide on the split between training and testing data from the DataFrame
trainingFraction = 0.7
testingFraction = (1-trainingFraction)
seed = 1234
# Split the DataFrame into test and training DataFrames
train_data_df, test_data_df = encoded_final_df.randomSplit([trainingFraction, testingFraction], seed=seed)
Teraz, gdy istnieją dwie ramki danych, następnym zadaniem jest utworzenie formuły modelu i uruchomienie jej względem ramki danych trenowania. Następnie możesz sprawdzić poprawność względem testowej ramki danych. Eksperymentuj z różnymi wersjami formuły modelu, aby zobaczyć wpływ różnych kombinacji.
Uwaga
Aby zapisać model, przypisz rolę Współautor danych obiektu blob usługi Storage do zakresu zasobów serwera bazy danych Azure SQL. Aby uzyskać szczegółowe instrukcje, zobacz Przypisywanie ról platformy Azure przy użyciu witryny Azure Portal. Ten krok może wykonać tylko członkowie z uprawnieniami właściciela.
## Create a new logistic regression object for the model
logReg = LogisticRegression(maxIter=10, regParam=0.3, labelCol = 'tipped')
## The formula for the model
classFormula = RFormula(formula="tipped ~ pickupHour + weekdayVec + passengerCount + tripTimeSecs + tripDistance + fareAmount + paymentType+ trafficTimeBinsVec")
## Undertake training and create a logistic regression model
lrModel = Pipeline(stages=[classFormula, logReg]).fit(train_data_df)
## Saving the model is optional, but it's another form of inter-session cache
datestamp = datetime.now().strftime('%m-%d-%Y-%s')
fileName = "lrModel_" + datestamp
logRegDirfilename = fileName
lrModel.save(logRegDirfilename)
## Predict tip 1/0 (yes/no) on the test dataset; evaluation using area under ROC
predictions = lrModel.transform(test_data_df)
predictionAndLabels = predictions.select("label","prediction").rdd
metrics = BinaryClassificationMetrics(predictionAndLabels)
print("Area under ROC = %s" % metrics.areaUnderROC)
Dane wyjściowe z tej komórki to:
Area under ROC = 0.9779470729751403
Tworzenie wizualnej reprezentacji przewidywania
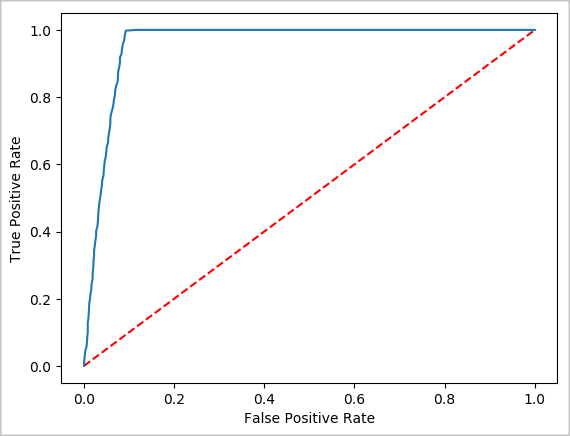
Teraz możesz utworzyć ostateczną wizualizację, aby ułatwić zapoznanie się z wynikami tego testu. Krzywa ROC jest jednym ze sposobów przeglądu wyniku.
## Plot the ROC curve; no need for pandas, because this uses the modelSummary object
modelSummary = lrModel.stages[-1].summary
plt.plot([0, 1], [0, 1], 'r--')
plt.plot(modelSummary.roc.select('FPR').collect(),
modelSummary.roc.select('TPR').collect())
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.show()
Zamykanie wystąpienia platformy Spark
Po zakończeniu uruchamiania aplikacji zamknij notes, aby zwolnić zasoby, zamykając kartę. Możesz też wybrać pozycję Zakończ sesję w panelu stanu w dolnej części notesu.