Przeładowywanie funkcji
Język C++ umożliwia określenie więcej niż jednej funkcji o tej samej nazwie w tym samym zakresie. Te funkcje są nazywane przeciążeniami lub przeciążeniami. Przeciążone funkcje umożliwiają dostarczanie różnych semantyki dla funkcji w zależności od typów i liczby jej argumentów.
Rozważmy na przykład funkcję, print która przyjmuje std::string argument. Ta funkcja może wykonywać bardzo różne zadania niż funkcja, która przyjmuje argument typu double. Przeciążenie zapobiega konieczności używania nazw, takich jak print_string lub print_double. W czasie kompilacji kompilator wybiera przeciążenie, które ma być używane na podstawie typów i liczby argumentów przekazywanych przez obiekt wywołujący. Jeśli wywołasz metodę print(42.0)void print(double d) , wywołana jest funkcja . Jeśli wywołasz metodę print("hello world")void print(std::string) , zostanie wywołane przeciążenie.
Można przeciążyć zarówno funkcje składowe, jak i funkcje bezpłatne. W poniższej tabeli przedstawiono, które części deklaracji funkcji języka C++ używają do rozróżniania grup funkcji o tej samej nazwie w tym samym zakresie.
Zagadnienia przeciążania
| Element deklaracji funkcji | Używane do przeciążenia? |
|---|---|
| Typ zwracany przez funkcję | Nie. |
| Liczba argumentów | Tak |
| Typ argumentów | Tak |
| Obecność lub brak wielokropka | Tak |
typedef Używanie nazw |
Nie. |
| Nieokreślone granice tablic | Nie. |
const lub volatile |
Tak, po zastosowaniu do całej funkcji |
Kwalifikatory odwołań (& i &&) |
Tak |
Przykład
W poniższym przykładzie pokazano, jak można używać przeciążeń funkcji:
// function_overloading.cpp
// compile with: /EHsc
#include <iostream>
#include <math.h>
#include <string>
// Prototype three print functions.
int print(std::string s); // Print a string.
int print(double dvalue); // Print a double.
int print(double dvalue, int prec); // Print a double with a
// given precision.
using namespace std;
int main(int argc, char *argv[])
{
const double d = 893094.2987;
if (argc < 2)
{
// These calls to print invoke print( char *s ).
print("This program requires one argument.");
print("The argument specifies the number of");
print("digits precision for the second number");
print("printed.");
exit(0);
}
// Invoke print( double dvalue ).
print(d);
// Invoke print( double dvalue, int prec ).
print(d, atoi(argv[1]));
}
// Print a string.
int print(string s)
{
cout << s << endl;
return cout.good();
}
// Print a double in default precision.
int print(double dvalue)
{
cout << dvalue << endl;
return cout.good();
}
// Print a double in specified precision.
// Positive numbers for precision indicate how many digits
// precision after the decimal point to show. Negative
// numbers for precision indicate where to round the number
// to the left of the decimal point.
int print(double dvalue, int prec)
{
// Use table-lookup for rounding/truncation.
static const double rgPow10[] = {
10E-7, 10E-6, 10E-5, 10E-4, 10E-3, 10E-2, 10E-1,
10E0, 10E1, 10E2, 10E3, 10E4, 10E5, 10E6 };
const int iPowZero = 6;
// If precision out of range, just print the number.
if (prec < -6 || prec > 7)
{
return print(dvalue);
}
// Scale, truncate, then rescale.
dvalue = floor(dvalue / rgPow10[iPowZero - prec]) *
rgPow10[iPowZero - prec];
cout << dvalue << endl;
return cout.good();
}
Powyższy kod przedstawia przeciążenia print funkcji w zakresie pliku.
Argument domyślny nie jest traktowany jako część typu funkcji. W związku z tym nie jest używany do wybierania przeciążonych funkcji. Dwie funkcje, które różnią się tylko w ich argumentach domyślnych, są traktowane jako wiele definicji, a nie przeciążonych funkcji.
Nie można podać argumentów domyślnych dla przeciążonych operatorów.
Dopasowywanie argumentów
Kompilator wybiera, która przeciążona funkcja ma być wywoływana na podstawie najlepszego dopasowania między deklaracjami funkcji w bieżącym zakresie do argumentów podanych w wywołaniu funkcji. Jeśli zostanie znaleziona odpowiednia funkcja, wywoływana jest ta funkcja. "Odpowiednie" w tym kontekście oznacza:
Znaleziono dokładne dopasowanie.
Wykonano trywialną konwersję.
Wykonano całkową promocję.
Istnieje standardowa konwersja na żądany typ argumentu.
Istnieje konwersja zdefiniowana przez użytkownika (operator konwersji lub konstruktor) do żądanego typu argumentu.
Znaleziono argumenty reprezentowane przez wielokropek.
Kompilator tworzy zestaw funkcji kandydatów dla każdego argumentu. Funkcje kandydata to funkcje, w których rzeczywisty argument w tej pozycji można przekonwertować na typ argumentu formalnego.
Zestaw "najlepszych funkcji pasujących" jest tworzony dla każdego argumentu, a wybrana funkcja jest przecięciem wszystkich zestawów. Jeśli przecięcie zawiera więcej niż jedną funkcję, przeciążenie jest niejednoznaczne i generuje błąd. Ostatecznie wybrana funkcja jest zawsze lepszym dopasowaniem niż każda inna funkcja w grupie dla co najmniej jednego argumentu. Jeśli nie ma wyraźnego zwycięzcy, wywołanie funkcji generuje błąd kompilatora.
Rozważ następujące deklaracje (funkcje są oznaczone jako Variant 1, Variant 2i Variant 3, do identyfikacji w następującej dyskusji):
Fraction &Add( Fraction &f, long l ); // Variant 1
Fraction &Add( long l, Fraction &f ); // Variant 2
Fraction &Add( Fraction &f, Fraction &f ); // Variant 3
Fraction F1, F2;
Rozważmy następującą instrukcję:
F1 = Add( F2, 23 );
Poprzednia instrukcja kompiluje dwa zestawy:
Ustaw 1: Funkcje kandydata, które mają pierwszy argument typu Fraction |
Set 2: Funkcje kandydata, których drugi argument można przekonwertować na typ int |
|---|---|
| Wariant 1 | Wariant 1 (int można przekonwertować na long przy użyciu konwersji standardowej) |
| Wariant 3 |
Funkcje w zestawie 2 to funkcje, które mają niejawne konwersje z rzeczywistego typu parametru na typ parametru formalnego. Jedna z tych funkcji ma najmniejszy "koszt", aby przekonwertować rzeczywisty typ parametru na odpowiadający mu typ parametru formalnego.
Przecięcie tych dwóch zestawów to wariant 1. Przykładem niejednoznacznego wywołania funkcji jest:
F1 = Add( 3, 6 );
Poprzednie wywołanie funkcji tworzy następujące zestawy:
Zestaw 1: Funkcje kandydata, które mają pierwszy argument typu int |
Zestaw 2: Funkcje kandydata, które mają drugi argument typu int |
|---|---|
Wariant 2 (int można przekonwertować na long przy użyciu konwersji standardowej) |
Wariant 1 (int można przekonwertować na long przy użyciu konwersji standardowej) |
Ponieważ przecięcie tych dwóch zestawów jest puste, kompilator generuje komunikat o błędzie.
W przypadku dopasowywania argumentów funkcja z n argumentami domyślnymi jest traktowana jako n+1 oddzielne funkcje, z których każda ma inną liczbę argumentów.
Wielokropek (...) działa jako symbol wieloznaczny; pasuje do dowolnego rzeczywistego argumentu. Może to prowadzić do wielu niejednoznacznych zestawów, jeśli nie projektujesz przeciążonych zestawów funkcji z ekstremalną starannością.
Uwaga
Nie można określić niejednoznaczności przeciążonych funkcji do momentu napotkania wywołania funkcji. W tym momencie zestawy są tworzone dla każdego argumentu w wywołaniu funkcji i można określić, czy istnieje jednoznaczne przeciążenie. Oznacza to, że niejednoznaczności mogą pozostać w kodzie do momentu ich wywołania przez określone wywołanie funkcji.
Różnice typu argumentów
Przeciążone funkcje rozróżniają typy argumentów, które przyjmują różne inicjatory. W związku z tym argument danego typu i odwołanie do tego typu są uznawane za takie same dla celów przeciążenia. Są one uważane za takie same, ponieważ przyjmują te same inicjatory. Na przykład max( double, double ) element jest uznawany za taki sam jak max( double &, double & ). Deklarowanie dwóch takich funkcji powoduje błąd.
Z tego samego powodu argumenty funkcji typu zmodyfikowanego przez const lub volatile nie są traktowane inaczej niż typ podstawowy na potrzeby przeciążenia.
Jednak mechanizm przeciążania funkcji może rozróżniać odwołania, które są kwalifikowane przez const i volatile i odwołania do typu podstawowego. Dzięki temu kod jest taki jak następujący:
// argument_type_differences.cpp
// compile with: /EHsc /W3
// C4521 expected
#include <iostream>
using namespace std;
class Over {
public:
Over() { cout << "Over default constructor\n"; }
Over( Over &o ) { cout << "Over&\n"; }
Over( const Over &co ) { cout << "const Over&\n"; }
Over( volatile Over &vo ) { cout << "volatile Over&\n"; }
};
int main() {
Over o1; // Calls default constructor.
Over o2( o1 ); // Calls Over( Over& ).
const Over o3; // Calls default constructor.
Over o4( o3 ); // Calls Over( const Over& ).
volatile Over o5; // Calls default constructor.
Over o6( o5 ); // Calls Over( volatile Over& ).
}
Dane wyjściowe
Over default constructor
Over&
Over default constructor
const Over&
Over default constructor
volatile Over&
Wskaźniki do const obiektów i volatile są również uznawane za różne od wskaźników do typu podstawowego na potrzeby przeciążenia.
Dopasowywanie argumentów i konwersje
Gdy kompilator próbuje dopasować rzeczywiste argumenty do argumentów w deklaracjach funkcji, może dostarczyć konwersje standardowe lub zdefiniowane przez użytkownika, aby uzyskać poprawny typ, jeśli nie można odnaleźć dokładnego dopasowania. Stosowanie konwersji podlega następującym regułom:
Nie są brane pod uwagę sekwencje konwersji zawierające więcej niż jedną konwersję zdefiniowaną przez użytkownika.
Sekwencje konwersji, które można skrócić przez usunięcie konwersji pośrednich, nie są brane pod uwagę.
Wynikowa sekwencja konwersji, jeśli istnieje, jest nazywana najlepszą sekwencją dopasowania. Istnieje kilka sposobów konwertowania obiektu typu na typ intunsigned long przy użyciu konwersji standardowych (opisanych w temacie Konwersje standardowe):
Przekonwertuj z
intnalong, a następnie zlongnaunsigned long.Przekonwertuj z
intnaunsigned long.
Chociaż pierwsza sekwencja osiąga żądany cel, nie jest to najlepsza sekwencja dopasowania, ponieważ istnieje krótsza sekwencja.
W poniższej tabeli przedstawiono grupę konwersji nazywanych konwersjami trywialnymi. Konwersje trywialne mają ograniczony wpływ na sekwencję wybieraną przez kompilator jako najlepszą zgodność. Efekt trywialnych konwersji jest opisany po tabeli.
Konwersje trywialne
| Typ argumentu | Przekonwertowany typ |
|---|---|
type-name |
type-name& |
type-name& |
type-name |
type-name[] |
type-name* |
type-name(argument-list) |
(*type-name)(argument-list) |
type-name |
const type-name |
type-name |
volatile type-name |
type-name* |
const type-name* |
type-name* |
volatile type-name* |
Sekwencja, w której są podejmowane próby konwersji, jest następująca:
Dokładne dopasowanie. Dokładne dopasowanie między typami, z którymi jest wywoływana funkcja, a typy zadeklarowane w prototypie funkcji są zawsze najlepszym dopasowaniem. Sekwencje konwersji trywialnych są klasyfikowane jako dokładne dopasowania. Jednak sekwencje, które nie tworzą żadnej z tych konwersji, są uważane za lepsze niż sekwencje konwertujące:
Od wskaźnika do wskaźnika do
const(type-name*doconst type-name*).Od wskaźnika do wskaźnika do
volatile(type-name*dovolatile type-name*).Od odwołania do odwołania do
constelementu (type-name&doconst type-name&).Od odwołania do odwołania do
volatileelementu (type-name&dovolatile type&).
Dopasuj przy użyciu promocji. Każda sekwencja nie sklasyfikowana jako dokładna dopasowanie, która zawiera tylko promocje całkowite, konwersje z
floatdodoublei trywialne konwersje są klasyfikowane jako dopasowanie przy użyciu promocji. Chociaż dopasowanie nie jest tak dobre jak dokładne dopasowanie, dopasowanie przy użyciu promocji jest lepsze niż dopasowanie przy użyciu konwersji standardowych.Dopasuj przy użyciu konwersji standardowych. Każda sekwencja nie sklasyfikowana jako dokładne dopasowanie lub dopasowanie przy użyciu promocji zawierających tylko konwersje standardowe i konwersje trywialne jest klasyfikowana jako dopasowanie przy użyciu konwersji standardowych. W tej kategorii są stosowane następujące reguły:
Konwersja ze wskaźnika na klasę pochodną do wskaźnika do wskaźnika do bezpośredniej lub pośredniej klasy bazowej jest preferowana do konwersji na
void *lubconst void *.Konwersja ze wskaźnika do klasy pochodnej do wskaźnika do wskaźnika do klasy bazowej daje lepsze dopasowanie bliżej klasy bazowej jest bezpośrednią klasą bazową. Załóżmy, że hierarchia klas jest pokazana na poniższym rysunku:

Wykres przedstawiający preferowane konwersje.
Konwersja z typu na typ D*C* jest preferowana do konwersji z typu D* na typ B*. Podobnie konwersja z typu na typ D*B* jest preferowana do konwersji z typu D* na typ A*.
Ta sama reguła dotyczy konwersji odwołań. Konwersja z typu na typ D&C& jest preferowana do konwersji z typu D& na typ B&itd.
Ta sama reguła ma zastosowanie do konwersji wskaźników do składowych. Konwersja z typu na typ T C::*T D::* jest preferowana do konwersji z typu T D::* na typ T B::*itd. (gdzie T jest typem elementu członkowskiego).
Poprzednia reguła ma zastosowanie tylko wzdłuż danej ścieżki wyprowadzania. Rozważmy wykres przedstawiony na poniższej ilustracji.
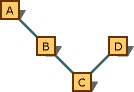
Wykres wielokrotnego dziedziczenia przedstawiający preferowane konwersje.
Konwersja z typu na typ C*B* jest preferowana do konwersji z typu C* na typ A*. Powodem jest to, że znajdują się one na tej samej ścieżce i B* jest bliżej. Jednak konwersja z typu na typ C*D* nie jest preferowana do konwersji na typ A*; nie ma preferencji, ponieważ konwersje są zgodne z różnymi ścieżkami.
Dopasuj do konwersji zdefiniowanych przez użytkownika. Tej sekwencji nie można sklasyfikować jako dokładnego dopasowania, dopasowania przy użyciu promocji lub dopasowania przy użyciu konwersji standardowych. Aby klasyfikować jako dopasowanie do konwersji zdefiniowanych przez użytkownika, sekwencja musi zawierać tylko konwersje zdefiniowane przez użytkownika, konwersje standardowe lub konwersje trywialne. Dopasowanie do konwersji zdefiniowanych przez użytkownika jest uznawane za lepsze dopasowanie niż dopasowanie z wielokropkiem (
...), ale nie tak dobre dopasowanie jak dopasowanie standardowe konwersji.Dopasuj do wielokropka. Każda sekwencja zgodna z wielokropkiem w deklaracji jest klasyfikowana jako zgodna z wielokropkiem. Jest uważany za najsłabszy mecz.
Konwersje zdefiniowane przez użytkownika są stosowane, jeśli nie istnieje wbudowana promocja lub konwersja. Te konwersje są wybierane na podstawie typu dopasowywanego argumentu. Rozważ następujący kod:
// argument_matching1.cpp
class UDC
{
public:
operator int()
{
return 0;
}
operator long();
};
void Print( int i )
{
};
UDC udc;
int main()
{
Print( udc );
}
Dostępne konwersje zdefiniowane przez użytkownika dla klasy UDC pochodzą z typu int i typu long. W związku z tym kompilator uwzględnia konwersje dla typu zgodnego obiektu: UDC. Konwersja na int istnieje i jest wybrana.
Podczas procesu dopasowywania argumentów można zastosować konwersje standardowe zarówno do argumentu, jak i wyniku konwersji zdefiniowanej przez użytkownika. W związku z tym działa następujący kod:
void LogToFile( long l );
...
UDC udc;
LogToFile( udc );
W tym przykładzie kompilator wywołuje konwersję zdefiniowaną przez użytkownika, operator long, aby przekonwertować udc na typ long. Jeśli nie zdefiniowano konwersji zdefiniowanej przez użytkownika na typ long , kompilator najpierw przekonwertuje typ na typ UDCint przy użyciu konwersji zdefiniowanej przez operator int użytkownika. Następnie zastosuje standardową konwersję z typu do typu intlong , aby dopasować argument w deklaracji.
Jeśli jakiekolwiek konwersje zdefiniowane przez użytkownika są wymagane do dopasowania argumentu, konwersje standardowe nie są używane podczas oceniania najlepszego dopasowania. Nawet jeśli więcej niż jedna funkcja kandydata wymaga konwersji zdefiniowanej przez użytkownika, funkcje są traktowane jako równe. Przykład:
// argument_matching2.cpp
// C2668 expected
class UDC1
{
public:
UDC1( int ); // User-defined conversion from int.
};
class UDC2
{
public:
UDC2( long ); // User-defined conversion from long.
};
void Func( UDC1 );
void Func( UDC2 );
int main()
{
Func( 1 );
}
Obie wersje Func programu wymagają konwersji zdefiniowanej przez użytkownika w celu przekonwertowania typu int na argument typu klasy. Możliwe konwersje to:
Konwertuj z typu na typ
intUDC1(konwersja zdefiniowana przez użytkownika).Przekonwertuj typ na typ
intlong; a następnie przekonwertuj na typUDC2(konwersja dwuetapowa).
Mimo że druga wymaga zarówno konwersji standardowej, jak i konwersji zdefiniowanej przez użytkownika, dwie konwersje są nadal traktowane jako równe.
Uwaga
Konwersje zdefiniowane przez użytkownika są uznawane za konwersję przez konstrukcję lub konwersję przez inicjację. Kompilator uwzględnia obie metody równe, gdy określa najlepsze dopasowanie.
Dopasowywanie argumentów this i wskaźnik
Funkcje składowe klasy są traktowane inaczej, w zależności od tego, czy są deklarowane jako static. static funkcje nie mają niejawnego argumentu dostarczającego this wskaźnik, więc są uważane za jeden argument mniejszy niż zwykłe funkcje składowe. W przeciwnym razie są one deklarowane identycznie.
Funkcje składowe, które nie static wymagają dorozumianego this wskaźnika, aby dopasować typ obiektu, za pomocą którego jest wywoływana funkcja. Lub w przypadku przeciążonych operatorów wymagają pierwszego argumentu, aby dopasować obiekt, do którego jest stosowany operator. Aby uzyskać więcej informacji na temat przeciążonych operatorów, zobacz Przeciążone operatory.
W przeciwieństwie do innych argumentów w przeciążonych funkcjach kompilator nie wprowadza żadnych obiektów tymczasowych i nie podejmuje żadnych konwersji podczas próby dopasowania argumentu this wskaźnika.
-> Gdy operator wyboru elementu członkowskiego jest używany do uzyskiwania dostępu do funkcji składowej klasy class_name, this argument wskaźnika ma typ class_name * const. Jeśli składowe są deklarowane jako const lub volatile, typy to const class_name * const i volatile class_name * const, odpowiednio.
. Operator wyboru elementu członkowskiego działa dokładnie tak samo, z tą różnicą, że niejawny & (adres-of) operator jest poprzedzony nazwą obiektu. W poniższym przykładzie pokazano, jak to działa:
// Expression encountered in code
obj.name
// How the compiler treats it
(&obj)->name
Lewy operand operatorów ->* i .* (wskaźnik do elementu członkowskiego) jest traktowany tak samo jak . operatory i -> (wybór elementu członkowskiego) w odniesieniu do dopasowywania argumentów.
Kwalifikatory odwołań w funkcjach składowych
Kwalifikatory odwołań umożliwiają przeciążenie funkcji składowej na podstawie tego, czy obiekt wskazywany przez this jest rvalue, czy lvalue. Użyj tej funkcji, aby uniknąć niepotrzebnych operacji kopiowania w scenariuszach, w których nie chcesz zapewniać dostępu wskaźnika do danych. Załóżmy na przykład, że klasa C inicjuje niektóre dane w konstruktorze i zwraca kopię tych danych w funkcji get_data()składowej . Jeśli obiekt typu C jest wartością rvalue, która ma zostać zniszczona, kompilator wybiera get_data() && przeciążenie, które przenosi zamiast kopiować dane.
#include <iostream>
#include <vector>
using namespace std;
class C
{
public:
C() {/*expensive initialization*/}
vector<unsigned> get_data() &
{
cout << "lvalue\n";
return _data;
}
vector<unsigned> get_data() &&
{
cout << "rvalue\n";
return std::move(_data);
}
private:
vector<unsigned> _data;
};
int main()
{
C c;
auto v = c.get_data(); // get a copy. prints "lvalue".
auto v2 = C().get_data(); // get the original. prints "rvalue"
return 0;
}
Ograniczenia przeciążenia
Kilka ograniczeń rządzi akceptowalnym zestawem przeciążonych funkcji:
Wszystkie dwie funkcje w zestawie przeciążonych funkcji muszą mieć różne listy argumentów.
Przeciążenie funkcji, które mają listy argumentów tego samego typu, w oparciu o sam typ zwracany, jest błędem.
Specyficzne dla firmy Microsoft
Można przeciążyć
operator newna podstawie typu zwracanego, w szczególności na podstawie określonego modyfikatora modelu pamięci.END Microsoft Specific
Nie można przeciążyć funkcji składowych wyłącznie dlatego, że jedna z nich jest
statici druga niestaticjest .typedefdeklaracje nie definiują nowych typów; wprowadzają synonimy istniejących typów. Nie wpływają one na mechanizm przeciążania. Rozważ następujący kod:typedef char * PSTR; void Print( char *szToPrint ); void Print( PSTR szToPrint );Poprzednie dwie funkcje mają identyczne listy argumentów.
PSTRjest synonimem typuchar *. W zakresie elementu członkowskiego ten kod generuje błąd.Typy wyliczane są odrębnymi typami i mogą służyć do rozróżniania przeciążonych funkcji.
Typy "tablica" i "wskaźnik do" są uważane za identyczne do celów rozróżnienia między przeciążonych funkcji, ale tylko dla tablic jednowymiarowych. Te przeciążone funkcje powodują konflikt i generują komunikat o błędzie:
void Print( char *szToPrint ); void Print( char szToPrint[] );W przypadku tablic o wyższych wymiarach drugie i późniejsze wymiary są traktowane jako część typu. Są one używane w odróżnieniu od przeciążonych funkcji:
void Print( char szToPrint[] ); void Print( char szToPrint[][7] ); void Print( char szToPrint[][9][42] );
Przeciążanie, zastępowanie i ukrywanie
Dowolne dwie deklaracje funkcji o tej samej nazwie w tym samym zakresie mogą odwoływać się do tej samej funkcji lub do dwóch dyskretnych przeciążonych funkcji. Jeśli wykazy argumentów deklaracji zawierają równoważne typy argumentów (zgodnie z opisem w poprzedniej sekcji), deklaracje funkcji odnoszą się do tej samej funkcji. W przeciwnym razie, odnoszą się do dwóch różnych funkcji, które są wybrane za pomocą przeciążenia.
Zakres klas jest ściśle przestrzegany. Funkcja zadeklarowana w klasie bazowej nie znajduje się w tym samym zakresie co funkcja zadeklarowana w klasie pochodnej. Jeśli funkcja w klasie pochodnej jest deklarowana o takiej samej nazwie jak virtual funkcja w klasie bazowej, funkcja klasy pochodnej zastępuje funkcję klasy bazowej. Aby uzyskać więcej informacji, zobacz Funkcje wirtualne.
Jeśli funkcja klasy bazowej nie jest zadeklarowana jako virtual, mówi się, że funkcja klasy pochodnej ukrywa ją. Zarówno przesłonięcia, jak i ukrycia różnią się od przeciążenia.
Zakres bloków jest ściśle przestrzegany. Funkcja zadeklarowana w zakresie pliku nie znajduje się w tym samym zakresie co funkcja zadeklarowana lokalnie. Jeśli funkcja zadeklarowana lokalnie ma taką samą nazwę, co funkcja zadeklarowana w zakresie pliku, funkcja zadeklarowana lokalnie ukrywa funkcje należącą do zakresu pliku, zamiast powodować przeciążenie. Przykład:
// declaration_matching1.cpp
// compile with: /EHsc
#include <iostream>
using namespace std;
void func( int i )
{
cout << "Called file-scoped func : " << i << endl;
}
void func( char *sz )
{
cout << "Called locally declared func : " << sz << endl;
}
int main()
{
// Declare func local to main.
extern void func( char *sz );
func( 3 ); // C2664 Error. func( int ) is hidden.
func( "s" );
}
Poprzedni kod pokazuje dwie definicje funkcji func. Definicja, która przyjmuje argument typu char * , jest lokalna main ze względu na instrukcję extern . W związku z tym definicja, która przyjmuje argument typu int , jest ukryta, a pierwsze wywołanie func metody jest błędem.
Dla przeciążonych funkcji członkowskich, różne wersje funkcji mogą mieć różne przywileje dostępu. Są one nadal uważane za w zakresie otaczającej klasy, a tym samym są przeciążone funkcje. Rozważmy poniższy kod, w którym funkcja członkowska Deposit jest przeciążona; jedna wersja jest publiczna, inne są prywatne.
Zamiarem tego przykładu jest dostarczenie klasy Account, w której wymagane jest poprawne hasło, aby wykonać depozyty. Odbywa się to przy użyciu przeciążenia.
Wywołanie metody Deposit w metodzie wywołuje Account::Deposit funkcję prywatnego elementu członkowskiego. To wywołanie jest poprawne, ponieważ Account::Deposit jest funkcją składową i ma dostęp do prywatnych składowych klasy.
// declaration_matching2.cpp
class Account
{
public:
Account()
{
}
double Deposit( double dAmount, char *szPassword );
private:
double Deposit( double dAmount )
{
return 0.0;
}
int Validate( char *szPassword )
{
return 0;
}
};
int main()
{
// Allocate a new object of type Account.
Account *pAcct = new Account;
// Deposit $57.22. Error: calls a private function.
// pAcct->Deposit( 57.22 );
// Deposit $57.22 and supply a password. OK: calls a
// public function.
pAcct->Deposit( 52.77, "pswd" );
}
double Account::Deposit( double dAmount, char *szPassword )
{
if ( Validate( szPassword ) )
return Deposit( dAmount );
else
return 0.0;
}
Zobacz też
Opinia
Dostępne już wkrótce: W 2024 r. będziemy stopniowo wycofywać zgłoszenia z serwisu GitHub jako mechanizm przesyłania opinii na temat zawartości i zastępować go nowym systemem opinii. Aby uzyskać więcej informacji, sprawdź: https://aka.ms/ContentUserFeedback.
Prześlij i wyświetl opinię dla