Projektowanie warstwy trwałości infrastruktury
Napiwek
Ta zawartość jest fragmentem książki eBook, architektury mikrousług platformy .NET dla konteneryzowanych aplikacji platformy .NET dostępnych na platformie .NET Docs lub jako bezpłatnego pliku PDF, który można odczytać w trybie offline.

Składniki trwałości danych zapewniają dostęp do danych hostowanych w granicach mikrousługi (czyli bazy danych mikrousługi). Zawierają one rzeczywistą implementację składników, takich jak repozytoria i klasy Unit of Work , takie jak niestandardowe obiekty programu Entity Framework (EF DbContext ). Program EF DbContext implementuje wzorce repozytorium i jednostki pracy.
Wzorzec repozytorium
Wzorzec repozytorium jest wzorcem projektowania opartego na domenie, który ma na celu zachowanie trwałości poza modelem domeny systemu. Co najmniej jedna abstrakcja trwałości — interfejsy — są zdefiniowane w modelu domeny, a te abstrakcji mają implementacje w postaci kart specyficznych dla trwałości zdefiniowanych gdzie indziej w aplikacji.
Implementacje repozytorium to klasy, które hermetyzują logikę wymaganą do uzyskiwania dostępu do źródeł danych. Centralizują one typowe funkcje dostępu do danych, zapewniając lepszą konserwację i oddzielenie infrastruktury lub technologii używanej do uzyskiwania dostępu do baz danych z modelu domeny. Jeśli używasz mapera obiektowo-relacyjnego (ORM), takiego jak Entity Framework, kod, który należy zaimplementować, jest uproszczony dzięki LINQ i silnemu wpisywaniu. Pozwala to skupić się na logice trwałości danych, a nie na kanalizacji dostępu do danych.
Wzorzec repozytorium to dobrze udokumentowany sposób pracy ze źródłem danych. W książce Patterns of Enterprise Application Architecture (Wzorce architektury aplikacji dla przedsiębiorstw) Martin Fowler opisuje repozytorium w następujący sposób:
Repozytorium wykonuje zadania pośredniczące między warstwami modelu domeny i mapowaniem danych, działając w podobny sposób do zestawu obiektów domeny w pamięci. Obiekty klienta deklaratywnie kompilują zapytania i wysyłają je do repozytoriów w celu uzyskania odpowiedzi. Koncepcyjnie repozytorium hermetyzuje zestaw obiektów przechowywanych w bazie danych i operacjach, które można na nich wykonać, zapewniając sposób bliżej warstwy trwałości. Repozytoria, również, obsługują cel oddzielenia, wyraźnie i w jednym kierunku, zależności między domeną pracy a alokacją lub mapowaniem danych.
Definiowanie jednego repozytorium na agregację
Dla każdego zagregowanego lub agregowanego katalogu głównego należy utworzyć jedną klasę repozytorium. Możesz wykorzystać typy ogólne języka C#, aby zmniejszyć łączną liczbę klas betonowych, które należy zachować (jak pokazano w dalszej części tego rozdziału). W mikrousłudze opartej na wzorcach projektowania opartego na domenie (DDD) jedynym kanałem, którego należy użyć do zaktualizowania bazy danych, powinny być repozytoria. Jest to spowodowane tym, że mają relację jeden do jednego z zagregowanym elementem głównym, który kontroluje niezmienne i transakcyjne spójność agregacji. Można wykonywać zapytania dotyczące bazy danych za pośrednictwem innych kanałów (jak można wykonać zgodnie z podejściem CQRS), ponieważ zapytania nie zmieniają stanu bazy danych. Jednak obszar transakcyjny (czyli aktualizacje) musi być zawsze kontrolowany przez repozytoria i zagregowane korzenie.
Zasadniczo repozytorium umożliwia wypełnianie danych w pamięci pochodzącej z bazy danych w postaci jednostek domeny. Gdy jednostki są w pamięci, można je zmienić, a następnie utrwalić z powrotem do bazy danych za pośrednictwem transakcji.
Jak wspomniano wcześniej, jeśli używasz wzorca architektury CQS/CQRS, początkowe zapytania są wykonywane przez zapytania równoległe z modelu domeny, wykonywane przez proste instrukcje SQL przy użyciu języka Dapper. Takie podejście jest o wiele bardziej elastyczne niż repozytoria, ponieważ można wykonywać zapytania i łączyć wszystkie potrzebne tabele, a te zapytania nie są ograniczone przez reguły z agregacji. Te dane przechodzą do warstwy prezentacji lub aplikacji klienckiej.
Jeśli użytkownik wprowadza zmiany, dane, które mają zostać zaktualizowane, pochodzą z aplikacji klienckiej lub warstwy prezentacji do warstwy aplikacji (takiej jak usługa internetowego interfejsu API). Po otrzymaniu polecenia w procedurze obsługi poleceń użyjesz repozytoriów, aby pobrać dane, które chcesz zaktualizować z bazy danych. Zaktualizujesz ją w pamięci przy użyciu danych przekazanych za pomocą poleceń, a następnie dodasz lub zaktualizujesz dane (jednostki domeny) w bazie danych za pośrednictwem transakcji.
Należy ponownie podkreślić, że należy zdefiniować tylko jedno repozytorium dla każdego zagregowanego katalogu głównego, jak pokazano na rysunku 7–17. Aby osiągnąć cel zagregowanego katalogu głównego w celu zachowania spójności transakcyjnej między wszystkimi obiektami w agregacji, nigdy nie należy tworzyć repozytorium dla każdej tabeli w bazie danych.
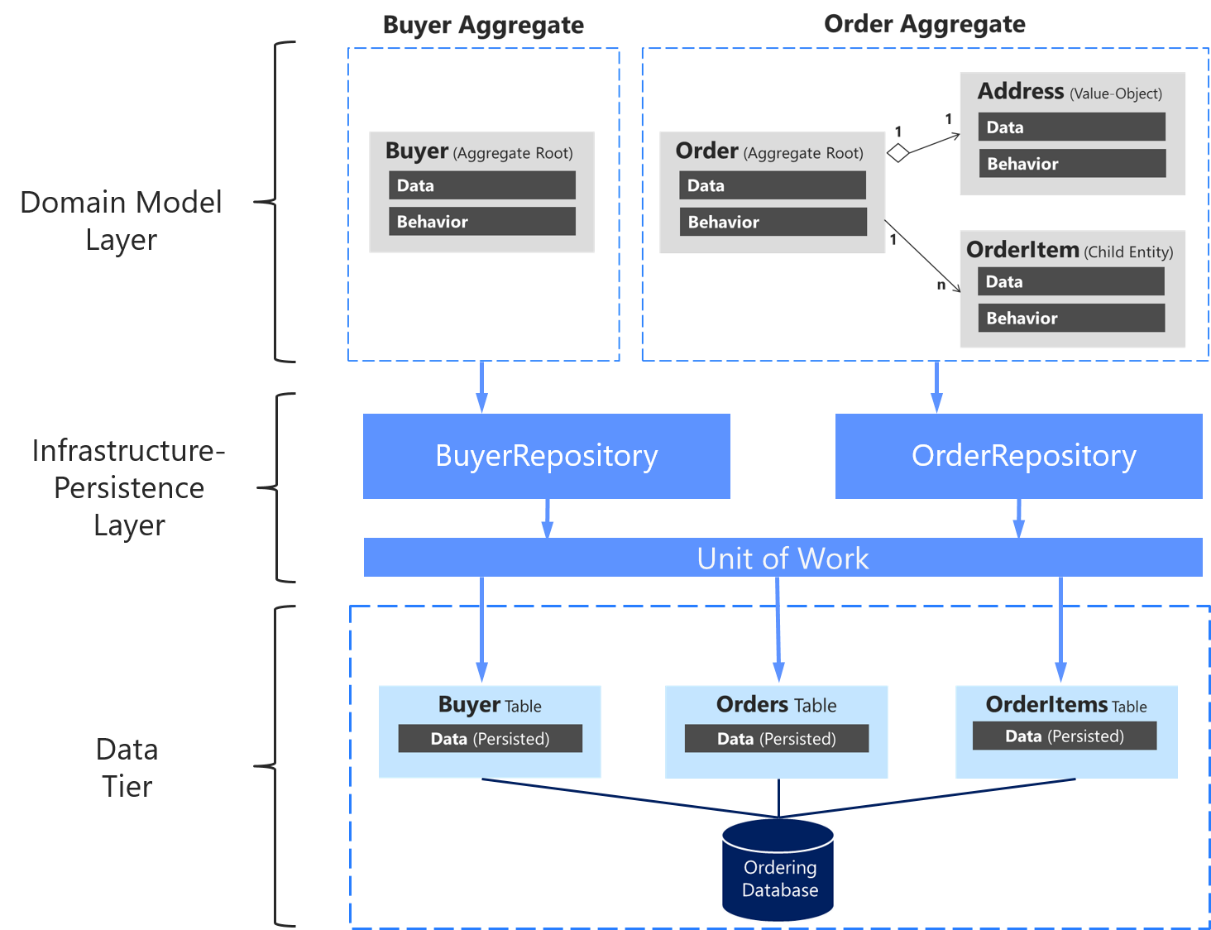
Rysunek 7–17. Relacja między repozytoriami, agregacjami i tabelami bazy danych
Na powyższym diagramie przedstawiono relacje między warstwami Domena i Infrastruktura: Agregacja nabywcy zależy od repozytorium IBuyerRepository i agregacji zamówień zależy od interfejsów IOrderRepository, te interfejsy są implementowane w warstwie infrastruktury przez odpowiednie repozytoria, które zależą od unitOfWork, również zaimplementowane tam, które uzyskują dostęp do tabel w warstwie Danych.
Wymuszanie jednego zagregowanego katalogu głównego na repozytorium
Warto zaimplementować projekt repozytorium w taki sposób, aby wymuszał regułę, że tylko zagregowane katalogi głównych powinny mieć repozytoria. Możesz utworzyć ogólny lub podstawowy typ repozytorium, który ogranicza typ jednostek, z którymi współpracuje, aby upewnić się, że mają interfejs znacznika IAggregateRoot .
W związku z tym każda klasa repozytorium zaimplementowana w warstwie infrastruktury implementuje własny kontrakt lub interfejs, jak pokazano w poniższym kodzie:
namespace Microsoft.eShopOnContainers.Services.Ordering.Infrastructure.Repositories
{
public class OrderRepository : IOrderRepository
{
// ...
}
}
Każdy interfejs repozytorium implementuje ogólny interfejs IRepository:
public interface IOrderRepository : IRepository<Order>
{
Order Add(Order order);
// ...
}
Jednak lepszym sposobem, aby kod wymuszał konwencję, że każde repozytorium jest związane z pojedynczą agregację, polega na zaimplementowaniu typu repozytorium ogólnego. W ten sposób jawnie używasz repozytorium do kierowania określonej agregacji. Można to łatwo zrobić, implementując ogólny IRepository interfejs podstawowy, jak w poniższym kodzie:
public interface IRepository<T> where T : IAggregateRoot
{
//....
}
Wzorzec repozytorium ułatwia testowanie logiki aplikacji
Wzorzec repozytorium umożliwia łatwe testowanie aplikacji przy użyciu testów jednostkowych. Pamiętaj, że testy jednostkowe testuje tylko kod, a nie infrastrukturę, więc abstrakcje repozytorium ułatwiają osiągnięcie tego celu.
Jak wspomniano we wcześniejszej sekcji, zaleca się zdefiniowanie i umieszczenie interfejsów repozytorium w warstwie modelu domeny, aby warstwa aplikacji, taka jak mikrousługę internetowego interfejsu API, nie zależała bezpośrednio od warstwy infrastruktury, w której zaimplementowano rzeczywiste klasy repozytorium. W tym celu i przy użyciu wstrzykiwania zależności na kontrolerach internetowego interfejsu API można zaimplementować makiety repozytoriów, które zwracają fałszywe dane zamiast danych z bazy danych. To oddzielenie podejścia umożliwia tworzenie i uruchamianie testów jednostkowych, które koncentrują się na logice aplikacji bez konieczności łączności z bazą danych.
Połączenie do baz danych może zakończyć się niepowodzeniem i, co ważniejsze, uruchomienie setek testów względem bazy danych jest złe z dwóch powodów. Najpierw może upłynąć dużo czasu z powodu dużej liczby testów. Po drugie, rekordy bazy danych mogą ulec zmianie i wpłynąć na wyniki testów, zwłaszcza jeśli testy są uruchomione równolegle, dzięki czemu mogą nie być spójne. Testy jednostkowe zwykle mogą być uruchamiane równolegle; Testy integracji mogą nie obsługiwać równoległego wykonywania w zależności od ich implementacji. Testowanie bazy danych nie jest testem jednostkowym, ale testem integracji. Wiele testów jednostkowych powinno działać szybko, ale mniej testów integracji z bazami danych.
Jeśli chodzi o rozdzielenie problemów dotyczących testów jednostkowych, logika działa na jednostkach domeny w pamięci. Przyjęto założenie, że klasa repozytorium dostarczyła te elementy. Gdy logika modyfikuje jednostki domeny, zakłada, że klasa repozytorium będzie przechowywać je poprawnie. Ważnym punktem jest utworzenie testów jednostkowych względem modelu domeny i jego logiki domeny. Główne korzenie agregacji to główne granice spójności w DDD.
Repozytoria zaimplementowane w aplikacjach eShopOnContainers polegają na implementacji DbContext platformy EF Core wzorców repozytorium i jednostki pracy przy użyciu jej monitora zmian, więc nie duplikują tej funkcji.
Różnica między wzorcem repozytorium a starszym wzorcem klasy dostępu do danych (klasa DAL)
Typowy obiekt DAL bezpośrednio wykonuje operacje dostępu do danych i trwałości względem magazynu, często na poziomie pojedynczej tabeli i wiersza. Proste operacje CRUD implementowane przy użyciu zestawu klas DAL często nie obsługują transakcji (chociaż nie zawsze tak jest). Większość metod klasy DAL wykorzystuje abstrakcje, co powoduje ścisłe sprzężenie między klasami aplikacji lub warstwy logiki biznesowej (BLL), które nazywają obiekty DAL.
W przypadku korzystania z repozytorium szczegóły implementacji trwałości są hermetyzowane z dala od modelu domeny. Użycie abstrakcji zapewnia łatwość rozszerzania zachowania przez wzorce, takie jak dekoratory lub serwery proxy. Na przykład problemy związane z wycinaniem krzyżowym, takie jak buforowanie, rejestrowanie i obsługa błędów, można zastosować przy użyciu tych wzorców, a nie zakodowanych w samym kodzie dostępu do danych. Jest to również proste do obsługi wielu kart repozytorium, które mogą być używane w różnych środowiskach, od lokalnego programowania po współużytkowane środowiska przejściowe do środowiska produkcyjnego.
Implementowanie jednostki pracy
Jednostka pracy odnosi się do jednej transakcji, która obejmuje wiele operacji wstawiania, aktualizowania lub usuwania. Mówiąc prosto, oznacza to, że dla konkretnej akcji użytkownika, takiej jak rejestracja w witrynie internetowej, wszystkie operacje wstawiania, aktualizowania i usuwania są obsługiwane w jednej transakcji. Jest to bardziej wydajne niż obsługa wielu operacji bazy danych w sposób bardziej wydajny.
Te wiele operacji trwałości jest wykonywanych później w ramach jednej akcji, gdy kod z poziomu poleceń warstwy aplikacji. Decyzja o zastosowaniu zmian w pamięci do rzeczywistego magazynu bazy danych jest zwykle oparta na wzorcu Unit of Work. W programie EF wzorzec Unit of Work jest implementowany przez DbContext element i jest wykonywany po wywołaniu metody SaveChanges.
W wielu przypadkach ten wzorzec lub sposób stosowania operacji względem magazynu może zwiększyć wydajność aplikacji i zmniejszyć możliwość niespójności. Zmniejsza również blokowanie transakcji w tabelach bazy danych, ponieważ wszystkie zamierzone operacje są zatwierdzane w ramach jednej transakcji. Jest to bardziej wydajne w porównaniu z wykonywaniem wielu izolowanych operacji względem bazy danych. W związku z tym wybrany ORM może zoptymalizować wykonywanie względem bazy danych, grupując kilka akcji aktualizacji w ramach tej samej transakcji, w przeciwieństwie do wielu małych i oddzielnych wykonań transakcji.
Wzorzec Unit of Work można zaimplementować z wzorcem repozytorium lub bez użycia go.
Repozytoria nie powinny być obowiązkowe
Repozytoria niestandardowe są przydatne z powodów wymienionych wcześniej i jest to podejście do zamawiania mikrousługi w eShopOnContainers. Jednak nie jest to podstawowy wzorzec implementacji w projekcie DDD, a nawet w ogólnym tworzeniu platformy .NET.
Na przykład Jimmy Bogard, podczas przekazywania bezpośrednich opinii dla tego przewodnika, powiedział:
Prawdopodobnie będzie to moja największa opinia. Naprawdę nie jestem fanem repozytoriów, głównie dlatego, że ukrywają ważne szczegóły podstawowego mechanizmu trwałości. Dlatego też idę do MediatR dla poleceń. Mogę użyć pełnej mocy warstwy trwałości i wypchnąć całe to zachowanie domeny do moich zagregowanych korzeni. Zwykle nie chcę wyśmiewać moich repozytoriów — nadal muszę mieć ten test integracji z prawdziwą rzeczą. Przejście do CQRS oznaczało, że nie mieliśmy już potrzeby repozytoriów.
Repozytoria mogą być przydatne, ale nie są krytyczne dla projektu DDD w taki sposób, w jaki wzorzec agregacji i bogaty model domeny są. W związku z tym należy użyć wzorca repozytorium lub nie, jak widać.
Dodatkowe zasoby
Wzorzec repozytorium
Edward Hieatt i Rob me. Wzorzec repozytorium.
https://martinfowler.com/eaaCatalog/repository.htmlWzorzec repozytorium
https://learn.microsoft.com/previous-versions/msp-n-p/ff649690(v=pandp.10)Eric Evans. Projektowanie oparte na domenie: walka ze złożonością w samym sercu oprogramowania. (Książka; zawiera omówienie wzorca repozytorium)
https://www.amazon.com/Domain-Driven-Design-Tackling-Complexity-Software/dp/0321125215/
Wzorzec jednostkowy pracy
Martin Fowler. Jednostka wzorca pracy.
https://martinfowler.com/eaaCatalog/unitOfWork.htmlImplementowanie wzorców repozytorium i jednostki pracy w aplikacji MVC ASP.NET
https://learn.microsoft.com/aspnet/mvc/overview/older-versions/getting-started-with-ef-5-using-mvc-4/implementing-the-repository-and-unit-of-work-patterns-in-an-asp-net-mvc-application
Opinia
Dostępne już wkrótce: W 2024 r. będziemy stopniowo wycofywać zgłoszenia z serwisu GitHub jako mechanizm przesyłania opinii na temat zawartości i zastępować go nowym systemem opinii. Aby uzyskać więcej informacji, sprawdź: https://aka.ms/ContentUserFeedback.
Prześlij i wyświetl opinię dla