Kolejki komunikatów: analiza przypadku
Wcześniej przyjrzeliśmy się ogólnie systemom kolejek komunikatów. Przekonaliśmy się, że już od jakiegoś czasu są używane systemy kolejek komunikatów ogólnego przeznaczenia do komunikacji międzyprocesowej oraz że powstały bardziej wyspecjalizowane kolejki komunikatów dla systemów typu klient-serwer lub architektur usług sieci Web. Chociaż istnieje kilka różnych systemów z unikatowymi projektami i funkcjami, przyjrzymy się systemowi, który został zbudowany od podstaw pod kątem skalowalności i elastyczności: Apache Kafka.
Apache Kafka
Platforma Kafka odpowiada za obsługę komunikatów pochodzących z zestawu programów (nazywanych producentami) i wysyłanie ich do zestawu maszyn, dla których te komunikaty mogą być istotne (nazywanych użytkownikami). Komunikaty są publikowane przez producentów w temacie platformy Kafka. Użytkownicy mogą nasłuchiwać określonych tematów po ich zasubskrybowaniu. Komunikaty będą dostarczane użytkownikom przez platformę Kafka. Zatem platformę Apache Kafka można nazwać rozproszonym systemem open-source do obsługi komunikatów typu publikuj-subskrybuj.

Rysunek 3. Klaster platformy Kafka
Tematy reprezentują kategorie zdefiniowane przez użytkownika, do których są publikowane komunikaty. Przykładem tematu, który mógłby być używany przez agencję reklamową jest AdClickEvents. Każdy użytkownik może odczytywać dane z jednego lub wielu tematów. Wewnętrznie każdy temat jest obsługiwany jako podzielony na partycje dziennik zatwierdzeń, jak pokazano na rysunku 4. Należy pamiętać, że temat może składać się z wielu partycji, a klaster platformy Kafka może obsługiwać wiele tematów.
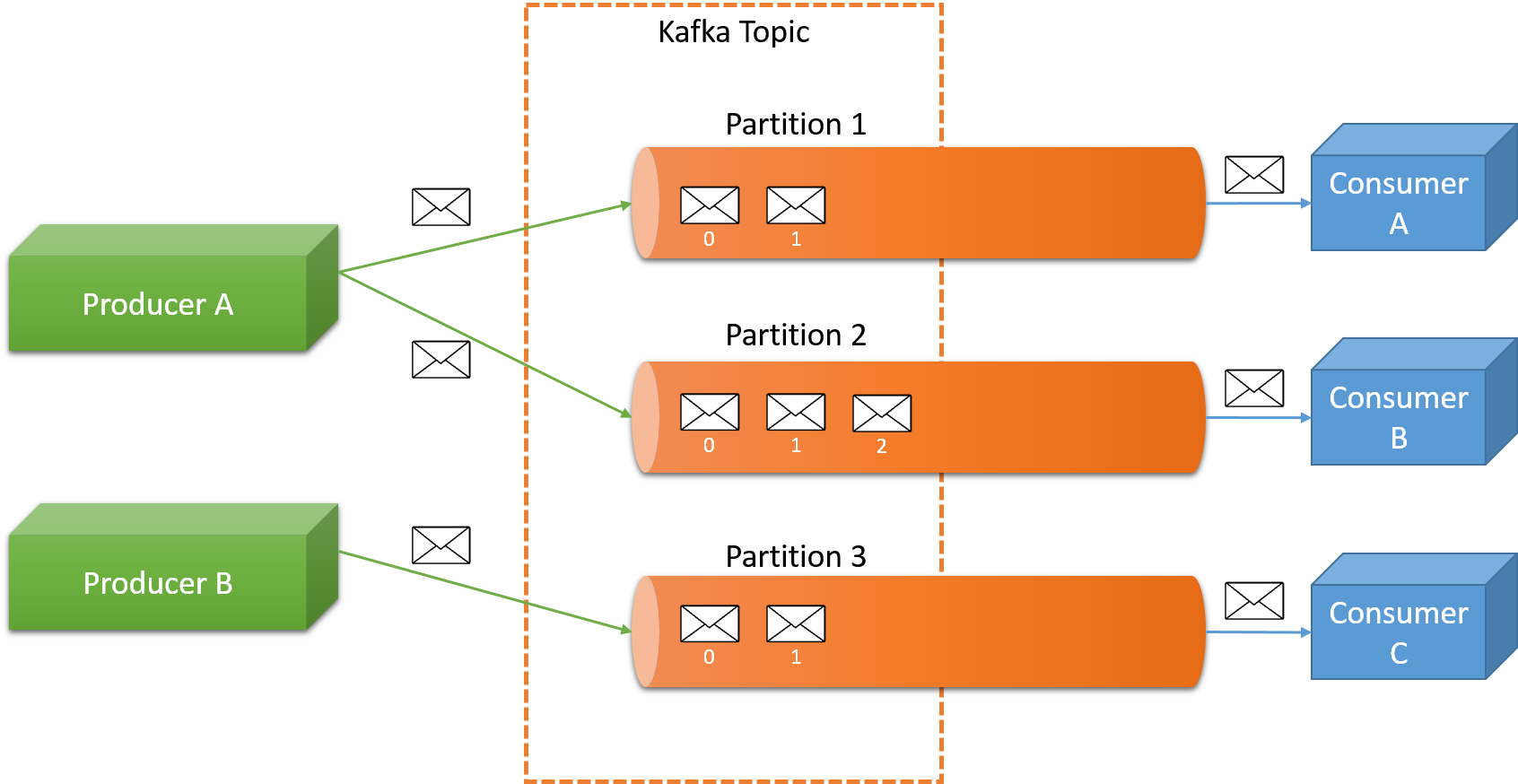
Rysunek 4. Kolejkowanie komunikatów na platformie Kafka
Oficjalnie każda partycja to uporządkowana, niezmienialna sekwencja komunikatów, która jest stale dołączana do dziennika zatwierdzeń. Do każdego z komunikatów w partycjach jest przypisany sekwencyjny numer identyfikacyjny nazywany przesunięciem. Jednoznacznie identyfikuje on każdy komunikat w partycji i nie może służyć do porządkowania komunikatów w temacie w różnych partycjach.
Partycje w dzienniku mają kilka zastosowań. Po pierwsze umożliwiają dziennikowi skalowanie poza rozmiar odpowiedni dla jednego serwera. Każda partycja musi być zgodna z serwerami, które ją obsługują, ale temat może mieć wiele partycji, dzięki czemu może obsługiwać dowolną ilość danych. Po drugie, partycje zachowują się jak jednostka równoległości, umożliwiając rozproszenie poszczególnych partycji dziennika między wieloma maszynami. Producenci kontrolują nie tylko temat komunikatu, mogą też jawnie kontrolować partycję, do której wysyłany jest komunikat, w razie potrzeby przy użyciu funkcji partycjonowania semantycznego (przypominającej funkcje partycjonowania używane w ramach usługi MapReduce). Domyślnie komunikaty w określonym temacie są rozpowszechniane okrężnie do partycji dla tego tematu.
Klaster platformy Kafka przechowuje wszystkie opublikowane komunikaty — niezależnie od tego, czy zostały odebrane przez użytkowników, czy nie — przez konfigurowalny okres (domyślnie przez 7 dni). Komunikaty, w przypadku których ten okres przechowywania upłynął, są automatycznie przeczyszczane przez platformę Kafka w celu utworzenia wolnego miejsca na nowe komunikaty.
Platforma Kafka śledzi również postęp każdego użytkownika w odczytywaniu komunikatów w pliku dziennika dotyczących określonego tematu, co nazywamy przesunięciem użytkownika. Większość użytkowników zwiększa tę wartość przesunięcia liniowo, gdy korzystają z komunikatów. Użytkownicy są w stanie kontrolować tę zmienną przesunięcia i w razie potrzeby mogą poruszać się do przodu lub do tyłu w celu odczytywania starszych lub nowszych komunikatów.
Ta kombinacja funkcji oznacza, że użytkownicy platformy Kafka generują bardzo niskie koszty. Ich obecność nie ma istotnego wpływu na klaster lub innych użytkowników.
Gwarancje zapewniane w ramach platformy Apache Kafka
W ramach platformy Kafka oferowany jest zestaw gwarancji wysokiego poziomu dla deweloperów aplikacji:
- Komunikaty wysyłane przez producenta do konkretnej partycji tematu będą dołączane w kolejności ich wysłania. Oznacza to, że jeśli komunikat M1 zostanie wysyłany przez tego samego producenta co komunikat M2, a komunikat M1 zostanie wysłany jako pierwszy, komunikat M1 będzie miał mniejsze przesunięcie niż M2 i zostanie pojawi się w dzienniku jako pierwszy.
- Wystąpienie użytkownika widzi komunikaty w kolejności, w której są przechowywane w dzienniku.
- W przypadku tematu o współczynniku replikacji $N$ będziemy tolerować maksymalnie $N - 1$ błędów serwera bez utraty komunikatów zatwierdzanych do dziennika.
Należy zauważyć, że gwarancje dostarczenia nie są bardzo rygorystyczne. Dotyczy to m.in. faktu, że użytkownicy mogą otrzymać ten sam komunikat dwukrotnie, choć dzieje się to rzadko.
Architektura platformy Apache Kafka

Rysunek 5. Architektura platformy Kafka
Serwery, które przesyłają komunikaty od wydawców (producentów) do subskrybentów (użytkowników), są nazywane brokerami platformy Kafka. Brokerzy platformy Kafka odpowiadają za trwałość i replikację komunikatów. Partycje poszczególnych tematów są rozpraszane do różnych brokerów, a każdy broker przechowuje co najmniej jedną partycję.
Brokerzy są uporządkowani w sposób zdecentralizowany, ponieważ nie ma stałego głównego brokera. Aby brokerzy mogli osiągnąć porozumienie w zakresie stanu systemu, została zastosowana usługa Apache ZooKeeper. ZooKeeper to łatwo dostępna usługa porozumienia kworum w formie interfejsu API przypominającego system plików. Usługa ZooKeeper jest używana na platformie Kafka do następujących zadań:
- Wykrywanie dodania i usunięcia brokerów oraz użytkowników w systemie
- Wyzwalanie ponownego równoważenia partycji w przypadku zmiany liczby brokerów lub użytkowników
- Utrzymywanie relacji używania i śledzenie zużytych przesunięć dla każdej partycji
Jak wspomniano wcześniej, najmniejszą jednostką równoległości na platformie Kafka jest partycja w temacie. Oznacza to, że wszystkie komunikaty partycji są w danym momencie używane przez jednego użytkownika. Dzięki temu platforma Kafka nie musi przeprowadzać drogiej koordynacji między wieloma brokerami, co byłoby konieczne jeśli miałaby zagwarantować kolejność w ramach wielu partycji.
Partycje są replikowane między wieloma brokerami w celu zapewnienia odporności na uszkodzenia. Jeden z brokerów zostaje wyznaczony na lidera dla określonej partycji, a wszystkie operacje odczytu i zapisu dla tej konkretnej partycji domyślnie przechodzą do repliki głównej. Komunikat można uznać za zatwierdzony tylko wtedy, gdy wszystkie repliki zatwierdziły komunikat w swoim dzienniku. Tylko zatwierdzone komunikaty są przekazywane użytkownikom. Producenci mogą zdecydować się na zablokowanie dopóki komunikat nie zostanie zatwierdzony przez platformę Kafka lub na ciągłe przesyłanie strumieniowe komunikatów bez blokowania. Istnieje wiele technik wykorzystywanych przez platformę Kafka do przyspieszania procesu replikacji dziennika. Szczegółowe informacje znajdują się w dokumentacji dotyczącej platformy Apache Kafka.
Ze względu na to, że brokerzy platformy Kafka mają przetwarzać duże ilości komunikatów, istnieją dwie właściwości związane z obsługą „na żywo”, które platforma Kafka monitoruje dla każdego węzła w klastrze:
- Każdy węzeł utrzymuje sesję z usługą ZooKeeper, korzystając z mechanizmu pulsu.
- Każdy węzeł podrzędny musi replikować aktualizacje węzła głównego i nie powinien pozostawać „zbyt daleko” w tyle. Zwłoka repliki jest właściwością konfigurowalną w klastrze platformy Kafka.
Interakcja z producentami
Producenci mogą wysyłać komunikaty do klastra platformy Kafka przy użyciu interfejsu API platformy Kafka. Producenci wiedzą, jakie tematy i partycje zostały skonfigurowane. Platforma Kafka i producent zazwyczaj kierują komunikaty do odpowiedniego brokera, który odpowiada za obsługę określonej partycji komunikatu. Interfejs API umożliwia również przesyłanie żądań metadanych. Dzięki temu producenci mogą wykonywać zapytania i znajdować brokera odpowiedniego do obsługi danego tematu i partycji. Jak wspomniano wcześniej, partycjonowanie tematu jest konfigurowalne i można w tym celu zastosować losowe równoważenie obciążenia lub partycjonowanie semantyczne uwzględniające treść.
Ponadto producenci korzystający z brokera platformy Kafka mają możliwość asynchronicznej komunikacji komunikatów oraz przetwarzania wsadowego żądań, które polega na gromadzeniu komunikatów i wysyłaniu ich w partiach. Przetwarzanie wsadowe jest również konfigurowalne pod względem liczby komunikatów w partii lub stałej granicy opóźnień, co pozwala aplikacji na ustalenie kompromisu między opóźnieniami i przepływnością.
Interakcja z użytkownikami
Użytkownicy platformy Kafka mogą wydawać żądania pobrania z brokerów dotyczące poszczególnych partycji, których chcą używać. Użytkownik może określić przesunięcie w dzienniku platformy Kafka przy każdym żądaniu, a następnie odebrać porcję komunikatów zaczynającą się od tej pozycji. Użytkownicy mogą wrócić do dowolnego przesunięcia i zażądać wcześniejszych komunikatów, pod warunkiem że te komunikaty znajdują się w oknie przechowywania klastra platformy Kafka.
Przypadki użycia platformy Kafka
Kolejka obsługi komunikatów: nic dziwnego, że platforma Kafka może służyć jako zamiennik tradycyjnych kolejek obsługi komunikatów, takich jak ActiveMQ lub RabbitMQ. Platforma Kafka jest szczególnie istotna, ponieważ zaprojektowano ją od podstaw w celu zapewnienia wysokiej dostępności i skalowalnego dostarczania komunikatów, z konfigurowalnymi opóźnieniami i wymaganiami dotyczącymi przepływności.
Śledzenie aktywności witryny internetowej: platforma Kafka została pierwotnie utworzona przez firmę LinkedIn w celu utworzenia potoku aktywności użytkownika i podejmowania decyzji w czasie rzeczywistym dotyczących zawartości i umieszczania reklam dla użytkowników serwisu LinkedIn. W tym scenariuszu tematy mogą być tworzone według typu interakcji z użytkownikiem (np. temat dotyczący wyświetlania stron i przewijania informacji, inny dotyczący wyszukiwanych terminów, a jeszcze inny kliknięć użytkownika). Różne usługi zaplecza, takie jak przetwarzanie w czasie rzeczywistym i monitorowanie aktywności użytkowników, mogą subskrybować odpowiednie tematy i przetwarzać strumienie w miarę ich pojawiania się.
Agregacja dzienników: platforma Kafka może służyć do agregowania dzienników z wielu usług i udostępniania ich w centralnej lokalizacji do przetwarzania. W porównaniu z systemami zorientowanymi na dzienniki, np. Scribe lub Flume, platforma Kafka oferuje równie dobrą wydajność, gwarancje większej trwałości dzięki replikacji i znacznie mniejsze opóźnienia.