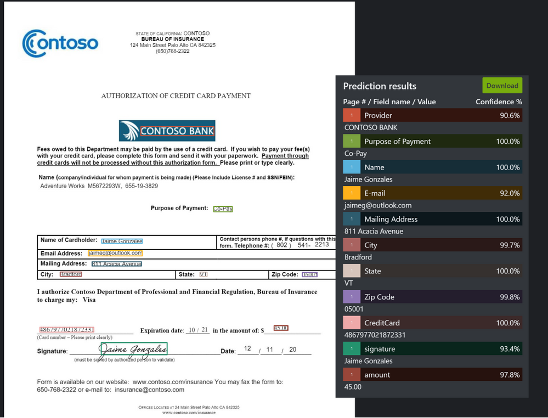
Co to jest analiza dokumentów sztucznej inteligencji platformy Azure?
Azure AI Document Intelligence to oparta na chmurze usługa, która wyodrębnia dane z obrazów i dokumentów przy użyciu uczenia maszynowego. Analiza dokumentów umożliwia analizowanie i wyodrębnianie danych z różnych typów dokumentów, w tym tabel, plików PDF, zdjęć, dokumentów napisanych i wpisanych, paragonów, faktur i wizytówek.
Używanie procesów ręcznych do wyodrębniania danych z formularzy jest czasochłonne i trudne. Dzięki analizie dokumentów można zautomatyzować ten proces, zmniejszyć liczbę błędów wprowadzania ręcznego i zaoszczędzić czas, jednocześnie zwiększając dostępność danych.
Interfejs API układu
Interfejs API układu analizy dokumentów może wyodrębniać tekst, znaczniki zaznaczenia i struktury tabeli, w tym liczby wierszy i kolumn skojarzonych z tekstem oraz współrzędnych pola ograniczenia.

Wstępnie utworzone modele
Wstępnie utworzone modele analizy dokumentów są dostępne dla ponad 15. W tym miejscu zapoznamy się z czterema modelami: fakturą, paragonem, identyfikacją i wizytówką.
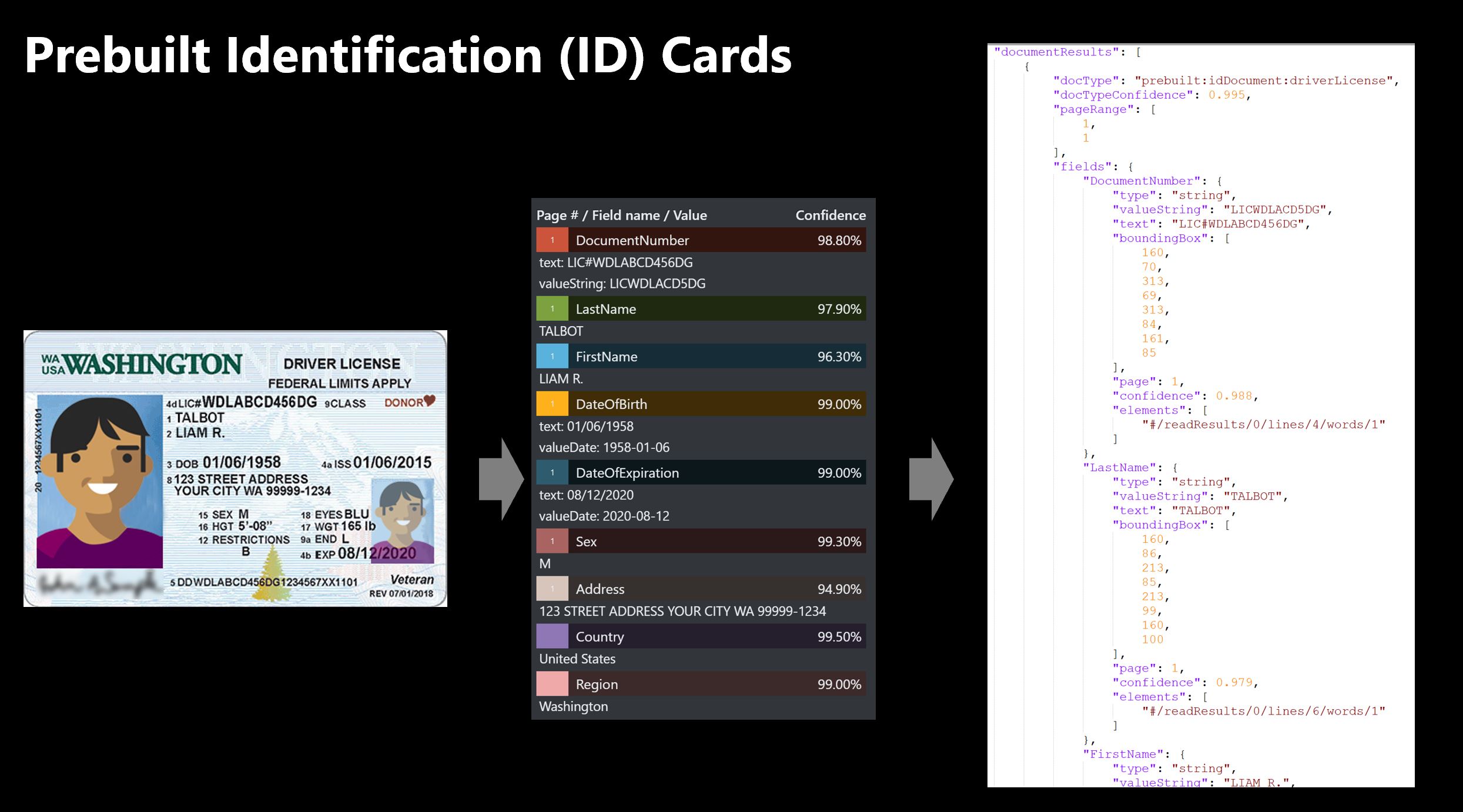
Wstępnie utworzony model faktury
Wstępnie utworzony model faktury wyodrębnia dane z faktur w różnych formatach i zwraca dane ustrukturyzowane. Ten model wyodrębnia kluczowe informacje, takie jak identyfikator faktury, szczegóły klienta i dostawcy, informacje o wysyłki i rozliczeniach, sumy cen i kwoty podatkowe.
Model faktury może wyodrębnić pełne elementy wiersza i części składowe — opis, ilość, ilość, identyfikator produktu, datę i inne. Ponadto ten model jest przeznaczony do analizowania i zwracania wszystkich tekstu i tabel w danych ustrukturyzowanych w celu zautomatyzowania procesu faktury.
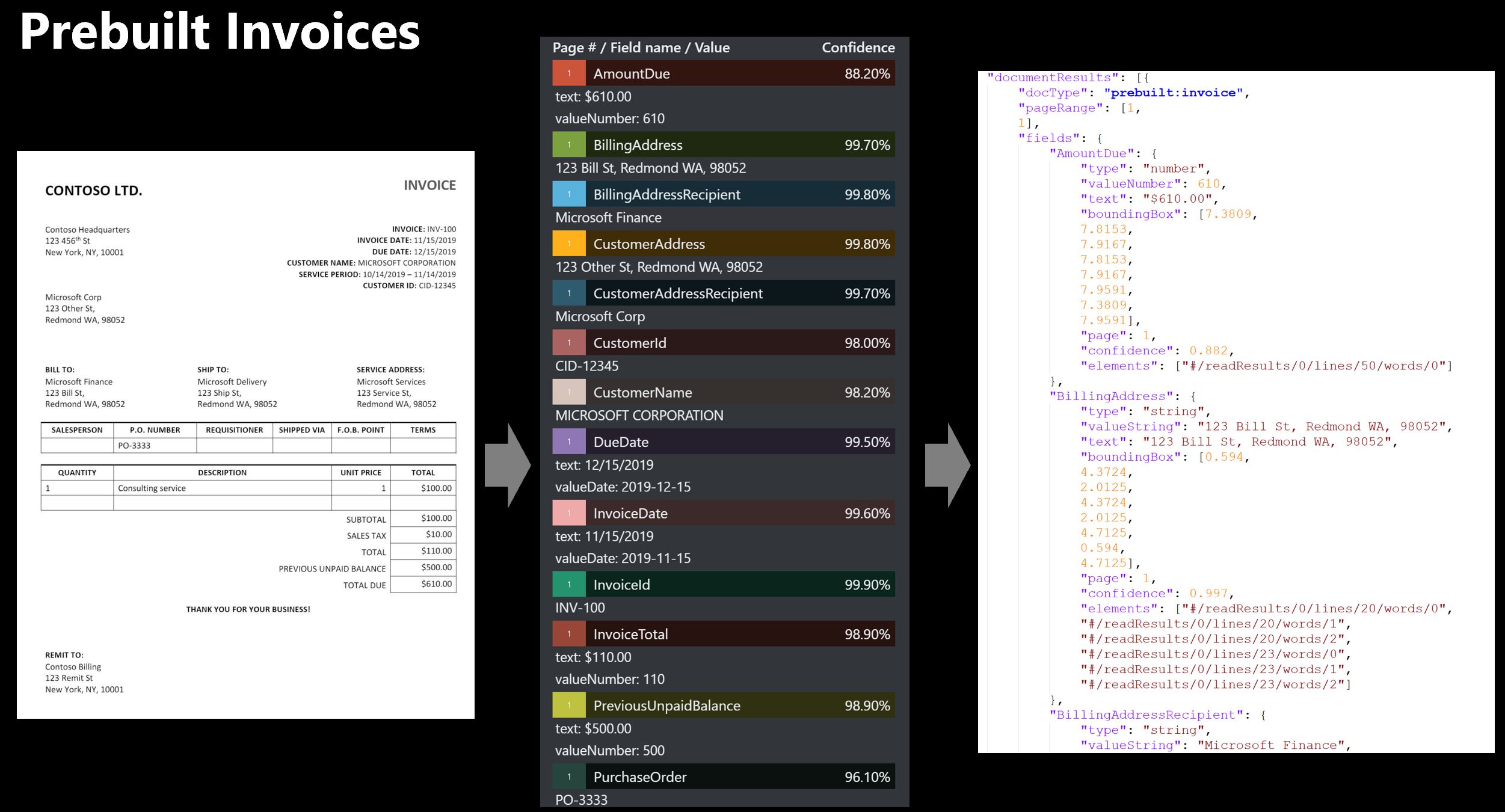
Wstępnie utworzony model paragonu
Ten wstępnie utworzony model paragonu służy do analizowania obrazów paragonów drukowanych, termicznych i odręcznych oraz paragonów hotelowych. Model paragonu wyodrębnia kluczowe informacje, takie jak godzina i data transakcji, informacje o kupcu i łączna kwota podatku. Dane można wyodrębnić z różnych obrazów paragonów, w tym cyfrowych, zeskanowanych, sfotografowanych i drukowanych kopii.
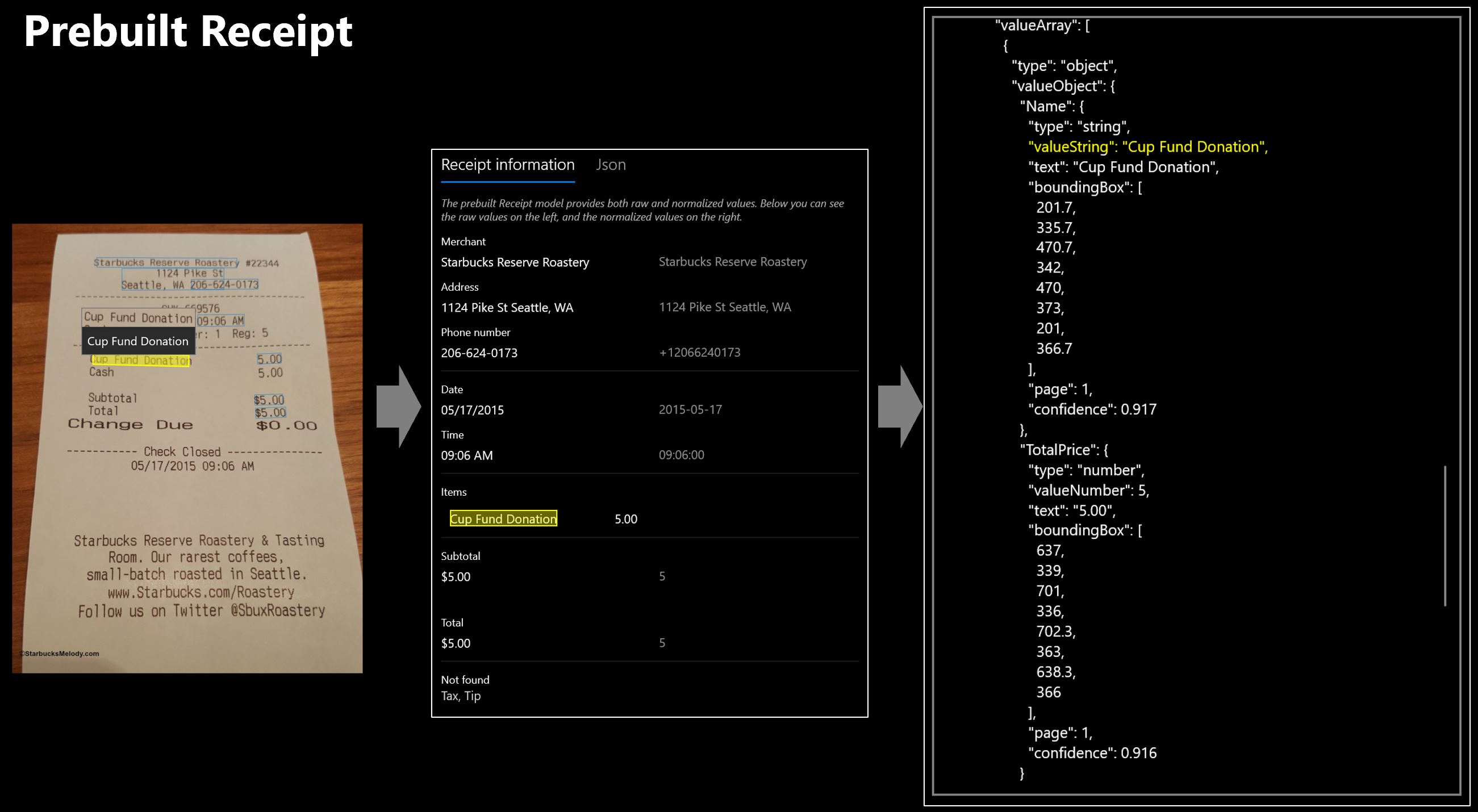
Wstępnie utworzony model dokumentu identyfikatora
Wstępnie utworzony model dokumentu identyfikatora wyodrębnia dane z paszportów na całym świecie, licencji kierowców i kart identyfikacyjnych. Przetwarzanie dokumentów identyfikatorów to ważny krok w każdej operacji biznesowej, która wymaga potwierdzenia tożsamości. Model analizuje dokumenty tożsamości i wyodrębnia kluczowe informacje (takie jak imię, nazwisko, data urodzenia) i zwraca ustrukturyzowaną reprezentację danych JSON.
Wstępnie utworzony model wizytówek
Model wizytówek wyodrębnia kluczowe informacje z drukowanych wizytówek i zwraca ustrukturyzowaną reprezentację danych JSON. Wyodrębnione informacje obejmują imię, nazwisko, nazwę firmy, adres e-mail i numer telefonu. Wyodrębnianie danych wizytówek to typowy scenariusz przetwarzania obrazów w systemach przedsiębiorstwa.

Modele niestandardowe
Modele niestandardowe można dostosować do wyodrębniania par tekstowych, par klucz-wartość, znaków zaznaczenia i danych tabeli z określonych formularzy i dokumentów. Modele są trenowane na podstawie dostarczanych danych, aby ulepszyć wyodrębnianie danych i dane wyjściowe ze strukturą w formacie dostosowywalnym. Modele niestandardowe doskonale nadają się do regularnego używania formularzy i są specyficzne dla organizacji lub branży.
Model niestandardowy można utworzyć, przekazując przykłady dokumentów w witrynie Azure Portal. Możesz nawet utworzyć bardzo dokładny model, oznaczając odpowiednie dane w celu wyodrębnienia z przykładów.