Tryby modelu semantycznego w usługa Power BI
Ten artykuł zawiera techniczne wyjaśnienie trybów semantycznych modeli usługi Power BI. Dotyczy ona modeli semantycznych reprezentujących połączenie na żywo z modelem usług Analysis Services hostowanych zewnętrznie, a także modeli opracowanych w programie Power BI Desktop. W tym artykule kładzie się nacisk na uzasadnienie poszczególnych trybów i możliwy wpływ na zasoby pojemności usługi Power BI.
Trzy tryby semantyczne modelu to:
Tryb Import
Tryb importu to najbardziej typowy tryb używany do tworzenia modeli semantycznych. Ten tryb zapewnia szybką wydajność dzięki zapytaniom w pamięci. Oferuje również elastyczność projektowania dla modelerów i obsługę określonych funkcji usługa Power BI (Q&A, Szybki wgląd w szczegółowe informacje itp.). Ze względu na te mocne strony jest to tryb domyślny podczas tworzenia nowego rozwiązania programu Power BI Desktop.
Ważne jest, aby zrozumieć, że zaimportowane dane są zawsze przechowywane na dysku. Podczas wykonywania zapytań lub odświeżania dane muszą zostać w pełni załadowane do pamięci pojemności usługi Power BI. W pamięci modele importu mogą uzyskiwać bardzo szybkie wyniki zapytań. Ważne jest również, aby zrozumieć, że nie ma pojęcia, że model importu jest częściowo ładowany do pamięci.
Po odświeżeniu dane są kompresowane i optymalizowane, a następnie przechowywane na dysku przez aparat magazynu VertiPaq. Po załadowaniu dysku do pamięci można zobaczyć 10-krotną kompresję. Dlatego rozsądnie jest oczekiwać, że 10 GB danych źródłowych może skompresować do około 1 GB rozmiaru. Rozmiar magazynu na dysku może osiągnąć 20% redukcji ze skompresowanego rozmiaru. Różnicę w rozmiarze można określić, porównując rozmiar pliku programu Power BI Desktop z użyciem pamięci Menedżera zadań pliku.
Elastyczność projektowania można osiągnąć na trzy sposoby:
- Integruj dane przez buforowanie danych z przepływów danych i zewnętrznych źródeł danych, niezależnie od typu lub formatu źródła danych.
- Użyj całego zestawu języka formuł Power Query M, określanego jako M, funkcji podczas tworzenia zapytań przygotowywania danych.
- Zastosuj cały zestaw funkcji języka DAX (Data Analysis Expressions) podczas ulepszania modelu za pomocą logiki biznesowej. Istnieje obsługa kolumn obliczeniowych, tabel obliczeniowych i miar.
Jak pokazano na poniższej ilustracji, model importu może integrować dane z dowolnej liczby obsługiwanych typów źródeł danych.
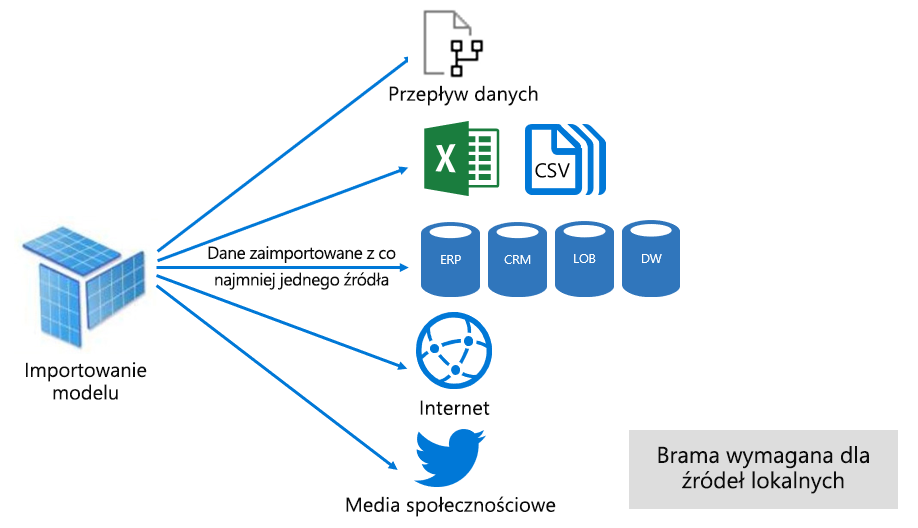
Jednak chociaż istnieją atrakcyjne zalety związane z modelami importu, istnieją również wady:
- Cały model musi zostać załadowany do pamięci, zanim usługa Power BI będzie mogła wykonywać zapytania dotyczące modelu, co może wywierać presję na dostępne zasoby pojemności, zwłaszcza w miarę wzrostu liczby i rozmiaru modeli importu.
- Dane modelu są tak aktualne, jak najnowsze odświeżanie, dlatego modele importu muszą być odświeżane, zwykle zgodnie z harmonogramem.
- Pełne odświeżanie usuwa wszystkie dane ze wszystkich tabel i ponownie ładuje je ze źródła danych. Ta operacja może być kosztowna w zakresie czasu i zasobów dla usługa Power BI oraz źródeł danych.
Uwaga
Usługa Power BI może uzyskać odświeżanie przyrostowe, aby uniknąć obcinania i ponownego ładowania całych tabel. Aby uzyskać więcej informacji, w tym obsługiwanych planów i licencjonowania, zobacz Odświeżanie przyrostowe i dane w czasie rzeczywistym dla modeli semantycznych.
Z perspektywy zasobów usługa Power BI modele importu wymagają:
- Wystarczająca ilość pamięci do załadowania modelu podczas wykonywania zapytań lub odświeżania.
- Przetwarzanie zasobów i dodatkowych zasobów pamięci w celu odświeżenia danych.
Tryb DirectQuery
Tryb DirectQuery jest alternatywą dla trybu importu. Modele opracowane w trybie DirectQuery nie importują danych. Zamiast tego składają się tylko z metadanych definiujących strukturę modelu. Gdy model jest odpytywane, zapytania natywne są używane do pobierania danych z bazowego źródła danych.
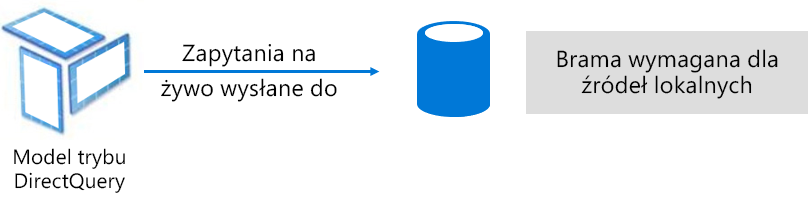
Istnieją dwa główne powody, dla których należy rozważyć utworzenie modelu DirectQuery:
- Gdy woluminy danych są zbyt duże, nawet w przypadku zastosowania metod redukcji danych, do załadowania do modelu lub praktycznie odświeżenia.
- Gdy raporty i pulpity nawigacyjne muszą dostarczać dane niemal w czasie rzeczywistym, poza tym, co można osiągnąć w ramach zaplanowanych limitów odświeżania. Limity zaplanowanego odświeżania to osiem razy dziennie dla pojemności udostępnionej i 48 razy dziennie dla pojemności Premium.
Istnieje kilka zalet związanych z modelami DirectQuery:
- Importowanie limitów rozmiaru modelu nie ma zastosowania.
- Modele nie wymagają zaplanowanego odświeżania danych.
- Użytkownicy raportów widzą najnowsze dane podczas interakcji z filtrami i fragmentatorami raportu. Ponadto użytkownicy raportu mogą odświeżyć cały raport, aby pobrać bieżące dane.
- Raporty w czasie rzeczywistym można opracowywać przy użyciu funkcji automatycznego odświeżania strony.
- Kafelki pulpitu nawigacyjnego w oparciu o modele DirectQuery mogą być aktualizowane automatycznie co 15 minut.
Istnieją jednak pewne ograniczenia związane z modelami DirectQuery:
- Wyrażenia Power Query/Mashup mogą być tylko funkcjami, które można transponować do natywnych zapytań zrozumiałych dla źródła danych.
- Formuły języka DAX są ograniczone do używania tylko funkcji, które można transponować do natywnych zapytań zrozumiałych dla źródła danych. Tabele obliczeniowe nie są obsługiwane.
- Szybki wgląd w szczegółowe informacje funkcje nie są obsługiwane.
Z perspektywy zasobów usługa Power BI modele DirectQuery wymagają:
- Minimalna ilość pamięci do załadowania modelu (tylko metadanych) podczas wykonywania zapytań.
- Czasami usługa Power BI musi używać znaczących zasobów procesora do generowania i przetwarzania zapytań wysyłanych do źródła danych. W takiej sytuacji może to mieć wpływ na przepływność, szczególnie w przypadku wykonywania zapytań względem modelu przez współbieżnych użytkowników.
Aby uzyskać więcej informacji, zobacz Używanie trybu DirectQuery w programie Power BI Desktop.
Tryb złożony
Tryb złożony może mieszać tryby Importuj i DirectQuery lub integrować wiele źródeł danych DirectQuery. Modele opracowane w trybie złożonym obsługują konfigurowanie trybu przechowywania dla każdej tabeli modeli. Ten tryb obsługuje również tabele obliczeniowe zdefiniowane przy użyciu języka DAX.
Tryb przechowywania tabel można skonfigurować jako Import, DirectQuery lub Dual. Tabela skonfigurowana jako tryb przechowywania podwójnego to Import i DirectQuery, a to ustawienie umożliwia usługa Power BI określenie najbardziej wydajnego trybu do użycia na podstawie zapytania.
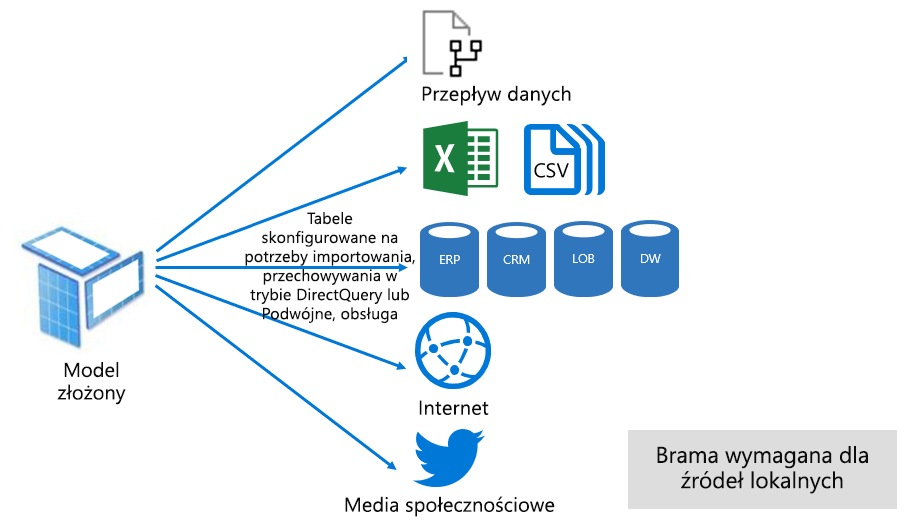
Modele złożone dążą do zapewnienia najlepszych trybów importu i trybu DirectQuery. Po odpowiednim skonfigurowaniu mogą łączyć wysoką wydajność zapytań modeli w pamięci z możliwością pobierania danych niemal w czasie rzeczywistym ze źródeł danych.
Aby uzyskać więcej informacji, zobacz Używanie modeli złożonych w programie Power BI Desktop.
Tabele Pure Import i DirectQuery
Osoby modelujące dane, które opracowują modele złożone, mogą konfigurować tabele wymiarów w trybie importowania lub przechowywania podwójnego oraz tabele faktów w trybie DirectQuery. Aby uzyskać więcej informacji na temat ról tabeli modelu, zobacz Omówienie schematu gwiazdy i znaczenia usługi Power BI.
Rozważmy na przykład model z tabelą wymiarów Product w trybie podwójnym i tabelą faktów Sales w trybie DirectQuery. Tabela Product może być wydajnie i szybko odpytywane z poziomu pamięci w celu renderowania fragmentatora raportu. Tabelę Sales można również wykonywać w trybie DirectQuery przy użyciu powiązanej tabeli Product . To ostatnie zapytanie może umożliwić generowanie pojedynczego wydajnego natywnego zapytania SQL, które łączy tabele Product i Sales oraz filtruje według wartości fragmentatora.
Tabele hybrydowe
Osoby modelające dane, które opracowują modele złożone, mogą również konfigurować tabele faktów jako tabele hybrydowe. Tabela hybrydowa to tabela z jedną lub wieloma partycjami importu i jedną partycją DirectQuery. Zaletą tabeli hybrydowej jest to, że może być wydajnie i szybko odpytywane z pamięci, jednocześnie uwzględniając najnowsze zmiany danych ze źródła danych, które wystąpiły po ostatnim cyklu importowania, jak pokazano w poniższej wizualizacji.
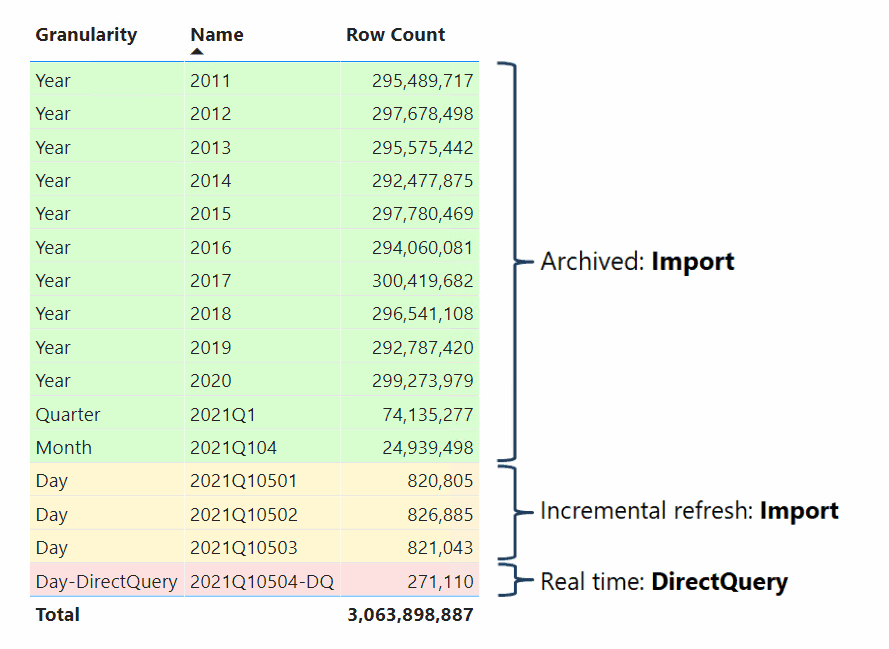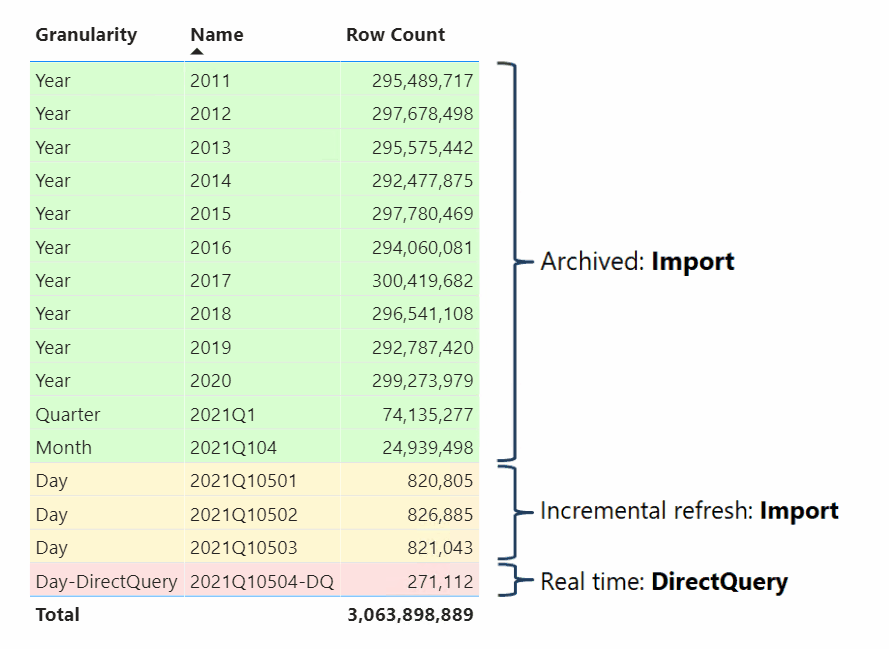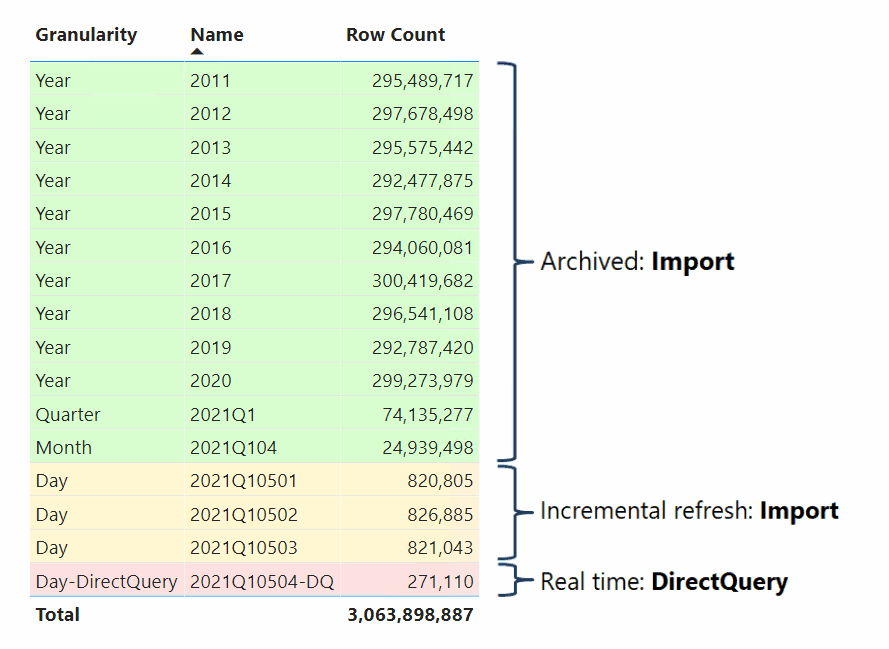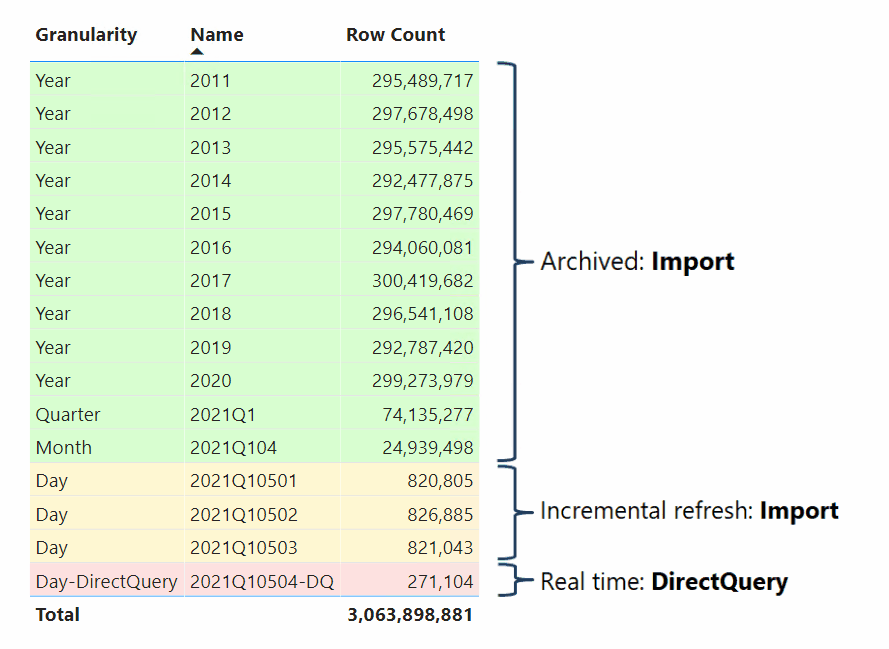
Najprostszym sposobem utworzenia tabeli hybrydowej jest skonfigurowanie zasad odświeżania przyrostowego w programie Power BI Desktop i włączenie opcji Pobierz najnowsze dane w czasie rzeczywistym przy użyciu trybu DirectQuery (tylko wersja Premium). Gdy usługa Power BI stosuje zasady odświeżania przyrostowego, które mają włączoną tę opcję, partycjonuje tabelę, taką jak schemat partycjonowania wyświetlany na poprzednim diagramie. Aby zapewnić dobrą wydajność, skonfiguruj tabele wymiarów w trybie przechowywania podwójnego, aby usługa Power BI mogła generować wydajne natywne zapytania SQL podczas wykonywania zapytań dotyczących partycji DirectQuery.
Uwaga
Usługa Power BI obsługuje tabele hybrydowe tylko wtedy, gdy model semantyczny jest hostowany w obszarach roboczych w pojemnościach Premium. W związku z tym należy przekazać model semantyczny do obszaru roboczego Premium, jeśli skonfigurujesz zasady odświeżania przyrostowego z opcją pobierania najnowszych danych w czasie rzeczywistym za pomocą trybu DirectQuery. Aby uzyskać więcej informacji, zobacz Odświeżanie przyrostowe i dane w czasie rzeczywistym dla modeli semantycznych.
Można również przekonwertować tabelę importu na tabelę hybrydową, dodając partycję DirectQuery przy użyciu języka TMSL (Tabular Model Scripting Language) lub tabelarycznego modelu obiektów (TOM) lub za pomocą narzędzia innej firmy. Na przykład można podzielić tabelę faktów na partycje, tak aby większość danych pozostała w magazynie danych, podczas gdy importowany jest tylko ułamek najnowszych danych. Takie podejście może pomóc w optymalizacji wydajności, jeśli większość tych danych to dane historyczne, do których dostęp jest rzadko używany. Tabela hybrydowa może mieć wiele partycji importu, ale tylko jedną partycję DirectQuery.