Omówienie oceny zapytań i składania zapytań w dodatku Power Query
Ten artykuł zawiera podstawowe omówienie sposobu przetwarzania zapytań M i zamieniania ich w żądania źródła danych.
Skrypt Power Query M
Każde zapytanie, niezależnie od tego, czy zostało utworzone przez dodatek Power Query, ręcznie napisane przez Ciebie w edytorze zaawansowanym, czy wprowadzone przy użyciu pustego dokumentu, składa się z funkcji i składni języka formuł Power Query M. To zapytanie jest interpretowane i oceniane przez aparat Power Query w celu wyprowadzenia wyników. Skrypt języka M służy jako zestaw instrukcji potrzebnych do oceny zapytania.
Napiwek
Skrypt języka M można traktować jako przepis opisujący sposób przygotowywania danych.
Najczęstszym sposobem tworzenia skryptu języka M jest użycie edytora Power Query. Na przykład po nawiązaniu połączenia ze źródłem danych, takim jak baza danych programu SQL Server, zauważysz po prawej stronie ekranu, że znajduje się sekcja o nazwie zastosowane kroki. W tej sekcji przedstawiono wszystkie kroki lub przekształcenia używane w zapytaniu. W tym sensie edytor Power Query służy jako interfejs, który ułatwia tworzenie odpowiedniego skryptu języka M dla przekształceń, które są używane, i zapewnia, że używany kod jest prawidłowy.
Uwaga
Skrypt języka M jest używany w edytorze Power Query w celu:
- Wyświetl zapytanie jako serię kroków i zezwól na tworzenie lub modyfikowanie nowych kroków.
- Wyświetl widok diagramu.
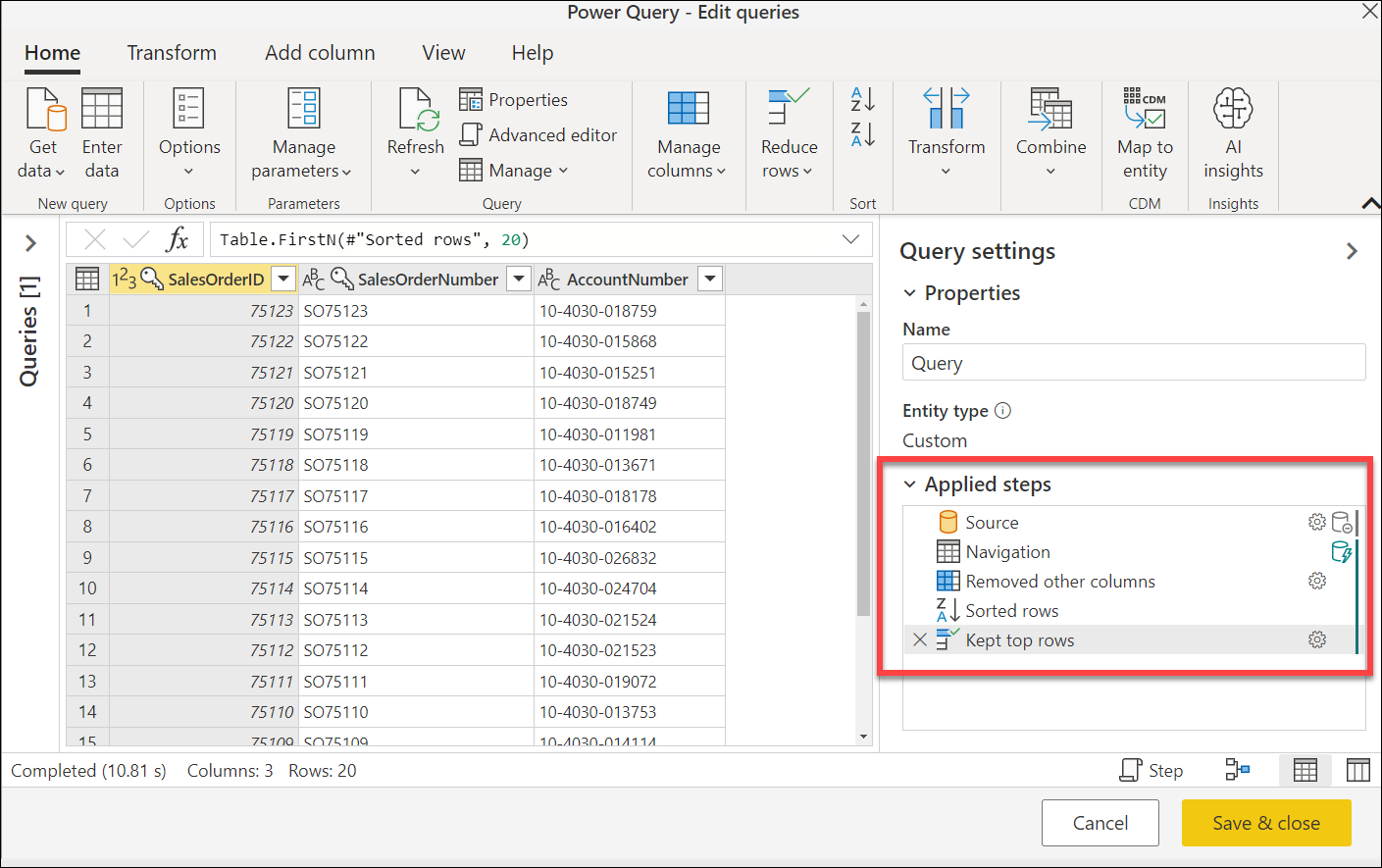
Na poprzedniej ilustracji przedstawiono sekcję zastosowane kroki, która zawiera następujące kroki:
- Źródło: nawiązuje połączenie ze źródłem danych. W takim przypadku jest to połączenie z bazą danych programu SQL Server.
- Nawigacja: przechodzi do określonej tabeli w bazie danych.
- Usunięto inne kolumny: wybiera kolumny z tabeli, które mają być zachowywane.
- Posortowane wiersze: sortuje tabelę przy użyciu co najmniej jednej kolumny.
- Przechowywane pierwsze wiersze: filtruje tabelę, aby zachować tylko określoną liczbę wierszy w górnej części tabeli.
Ten zestaw nazw kroków to przyjazny sposób wyświetlania skryptu języka M utworzonego przez dodatek Power Query. Istnieje kilka sposobów wyświetlania pełnego skryptu języka M. W dodatku Power Query możesz wybrać Edytor zaawansowany na karcie Widok. Możesz również wybrać Edytor zaawansowany z grupy Zapytanie na karcie Narzędzia główne. W niektórych wersjach dodatku Power Query można również zmienić widok paska formuły, aby wyświetlić skrypt zapytania, przechodząc do karty Widok, a następnie z grupy Układ wybierz pozycję Skrypt widoku>skryptu.
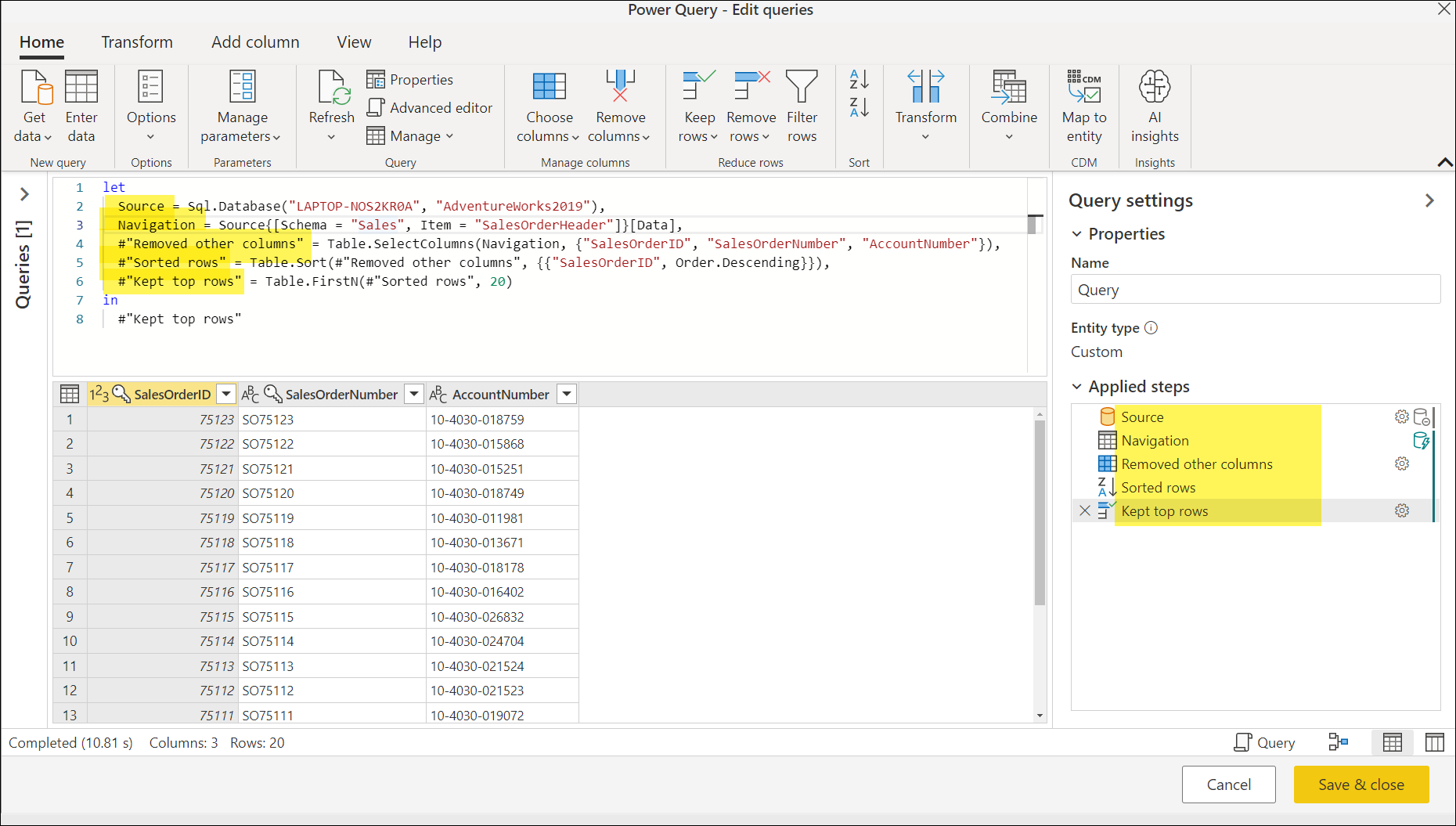
Większość nazw znalezionych w okienku Zastosowane kroki jest również używana tak, jak w skry skryscie języka M. Kroki zapytania są nazywane przy użyciu identyfikatorów w języku M. Czasami dodatkowe znaki są opakowane wokół nazw kroków w języku M, ale te znaki nie są wyświetlane w zastosowanych krokach. Przykładem jest #"Kept top rows", który jest klasyfikowany jako identyfikator cytowany z powodu tych dodatkowych znaków. Identyfikator cytowany może służyć do zezwalania na używanie dowolnej sekwencji znaków Unicode zero lub więcej znaków Unicode jako identyfikatora, w tym słów kluczowych, białych znaków, komentarzy, operatorów i znaków interpunkcyjnych. Aby dowiedzieć się więcej na temat identyfikatorów w języku M, przejdź do struktury leksykalnej.
Wszelkie zmiany wprowadzone w zapytaniu za pośrednictwem edytora Power Query automatycznie zaktualizują skrypt języka M dla zapytania. Na przykład użycie poprzedniego obrazu jako punktu początkowego, jeśli zmienisz nazwę kroku Zachowaj pierwsze wiersze na 20 pierwszych wierszy, ta zmiana zostanie automatycznie zaktualizowana w widoku skryptu.
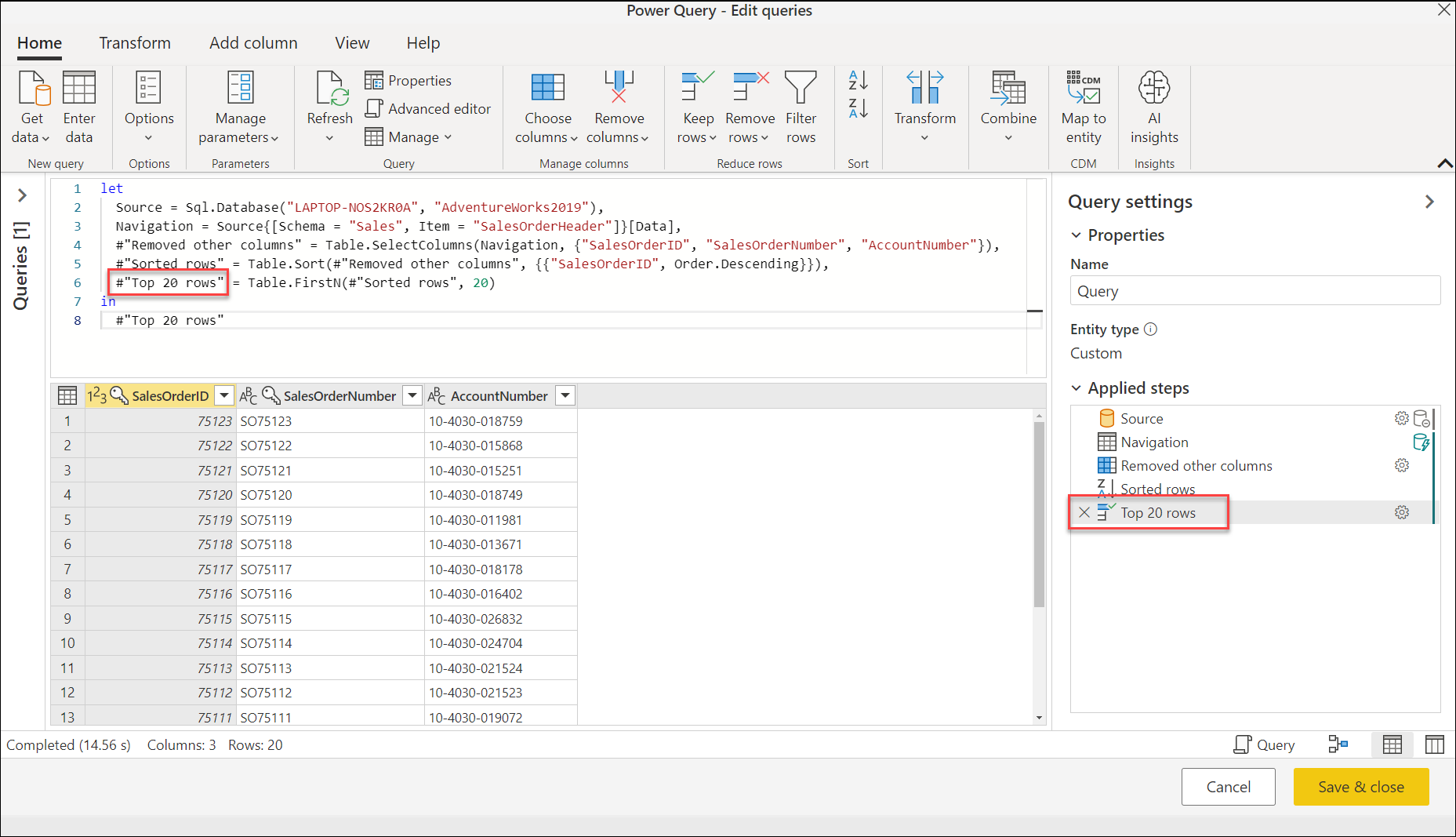
Chociaż zalecamy użycie edytora Power Query do utworzenia wszystkich lub większości skryptu języka M, możesz ręcznie dodać lub zmodyfikować fragmenty skryptu języka M. Aby dowiedzieć się więcej na temat języka M, przejdź do oficjalnej witryny dokumentacji języka M.
Uwaga
Skrypt języka M, nazywany również kodem M, jest terminem używanym dla dowolnego kodu, który używa języka M. W kontekście tego artykułu skrypt języka M odnosi się również do kodu znajdującego się wewnątrz zapytania Power Query i dostępnego za pośrednictwem okna edytora zaawansowanego lub widoku skryptu na pasku formuły.
Ocena zapytań w dodatku Power Query
Na poniższym diagramie przedstawiono proces, który występuje, gdy zapytanie jest oceniane w dodatku Power Query.
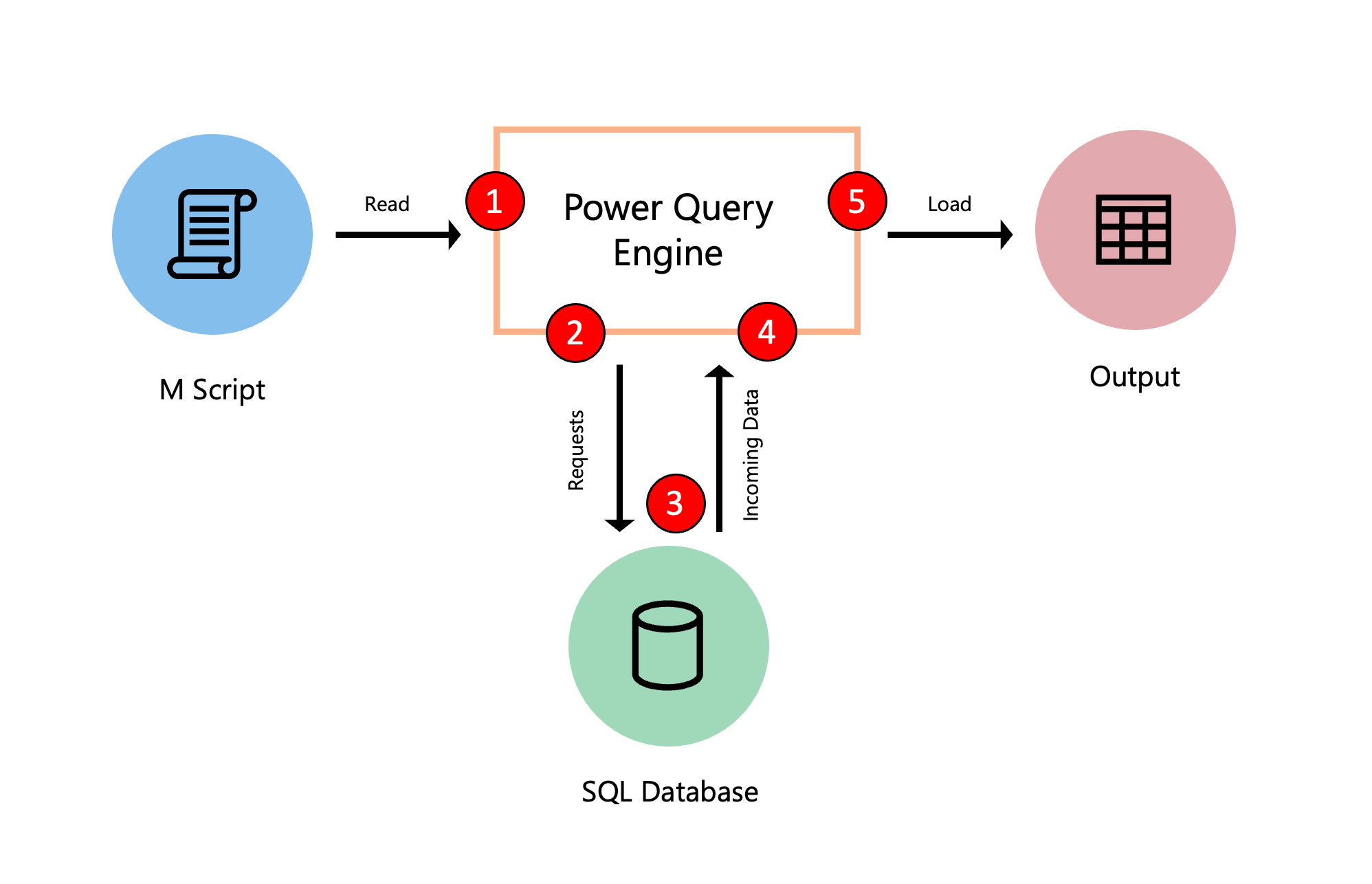
- Skrypt języka M znajdujący się w edytorze zaawansowanym jest przesyłany do aparatu Power Query. Uwzględniono również inne ważne informacje, takie jak poświadczenia i poziomy prywatności źródła danych.
- Dodatek Power Query określa, jakie dane mają zostać wyodrębnione ze źródła danych i przesyła żądanie do źródła danych.
- Źródło danych odpowiada na żądanie z dodatku Power Query, przesyłając żądane dane do dodatku Power Query.
- Dodatek Power Query odbiera dane przychodzące ze źródła danych i wykonuje wszelkie przekształcenia przy użyciu aparatu Power Query, jeśli to konieczne.
- Wyniki pochodzące z poprzedniego punktu są ładowane do miejsca docelowego.
Uwaga
W tym przykładzie pokazano zapytanie z usługą SQL Database jako źródłem danych, ale pojęcie dotyczy zapytań z lub bez źródła danych.
Gdy dodatek Power Query odczytuje skrypt języka M, uruchamia skrypt za pośrednictwem procesu optymalizacji, aby wydajniej ocenić zapytanie. W tym procesie określa, które kroki (przekształcenia) z zapytania można odciążyć do źródła danych. Określa również, które inne kroki należy ocenić przy użyciu aparatu Power Query. Ten proces optymalizacji jest nazywany składaniem zapytań, w którym dodatek Power Query próbuje wypchnąć jak najwięcej możliwych wykonań do źródła danych w celu zoptymalizowania wykonywania zapytania.
Ważne
Wszystkie reguły z języka formuł Power Query M (nazywanego również językiem M) są przestrzegane. Przede wszystkim leniwa ocena odgrywa ważną rolę podczas procesu optymalizacji. W tym procesie dodatek Power Query rozumie, jakie konkretne przekształcenia z zapytania należy ocenić. Dodatek Power Query rozumie również, czego nie trzeba oceniać, ponieważ nie są one potrzebne w danych wyjściowych zapytania.
Ponadto w przypadku uwzględnienia wielu źródeł poziom prywatności danych każdego źródła danych jest brany pod uwagę podczas oceniania zapytania. Więcej informacji: Za kulisami zapory prywatności danych
Na poniższym diagramie przedstawiono kroki, które mają miejsce w tym procesie optymalizacji.
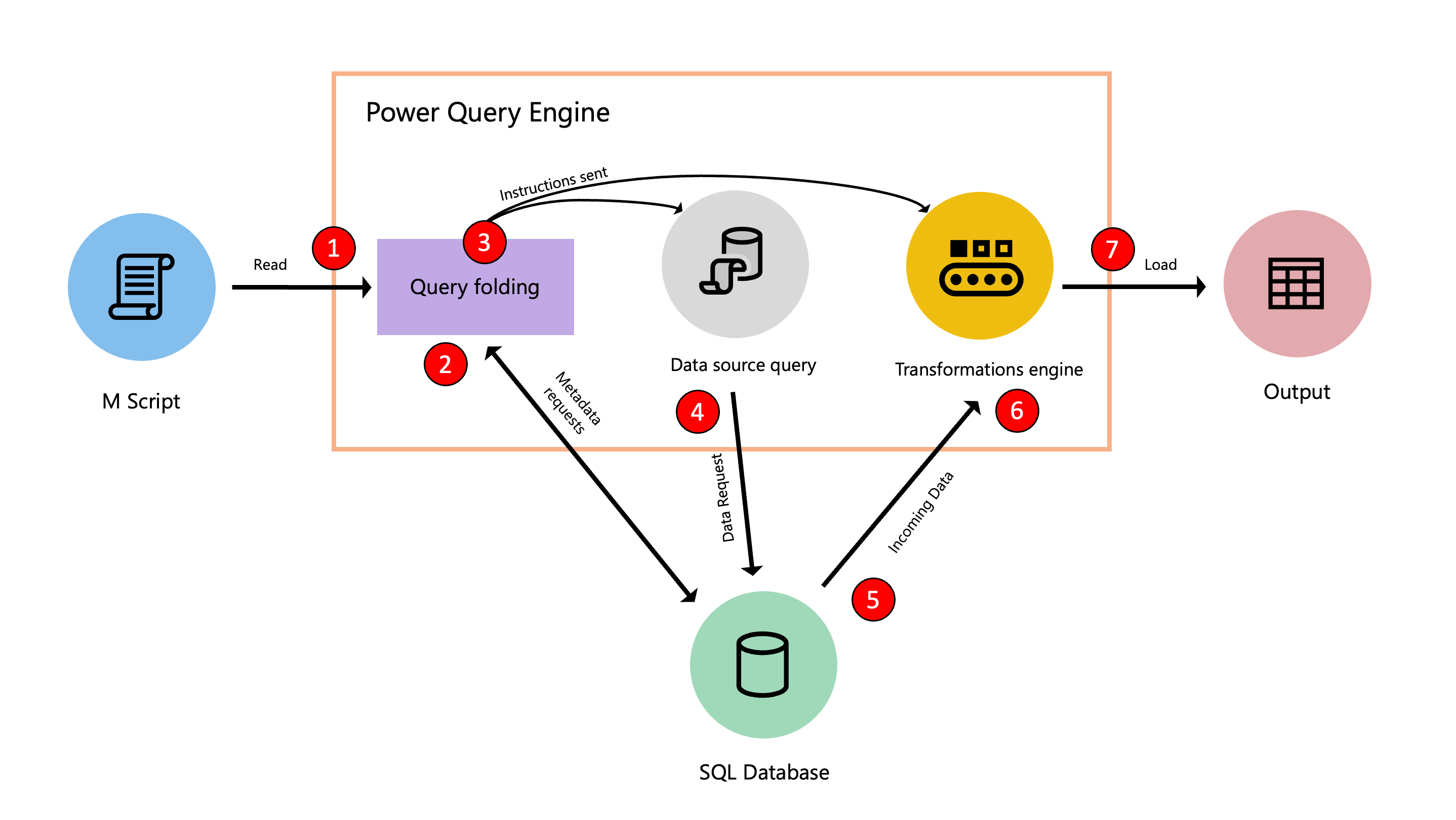
- Skrypt języka M znajdujący się w edytorze zaawansowanym jest przesyłany do aparatu Power Query. Podano również inne ważne informacje, takie jak poświadczenia i poziomy prywatności źródła danych.
- Mechanizm składania zapytań przesyła żądania metadanych do źródła danych w celu określenia możliwości źródła danych, schematów tabel, relacji między różnymi tabelami w źródle danych i nie tylko.
- Na podstawie odebranych metadanych mechanizm składania zapytań określa, jakie informacje mają być wyodrębnione ze źródła danych i jaki zestaw przekształceń należy wykonać wewnątrz aparatu Power Query. Wysyła on instrukcje do dwóch innych składników, które w razie potrzeby pobierają dane ze źródła danych i przekształcają dane przychodzące w a aparat Power Query.
- Po otrzymaniu instrukcji przez wewnętrzne składniki dodatku Power Query zapytanie Power Query wysyła żądanie do źródła danych przy użyciu zapytania źródła danych.
- Źródło danych odbiera żądanie z dodatku Power Query i przesyła dane do aparatu Power Query.
- Gdy dane znajdują się wewnątrz dodatku Power Query, aparat przekształcania wewnątrz dodatku Power Query (nazywanego również aparatem mashupu) wykonuje przekształcenia, których nie można składać ani odciążać do źródła danych.
- Wyniki pochodzące z poprzedniego punktu są ładowane do miejsca docelowego.
Uwaga
W zależności od przekształceń i źródła danych używanych w skry skryptzie języka M dodatek Power Query określa, czy będzie przesyłać strumieniowo lub buforować dane przychodzące.
Omówienie składania zapytań
Celem składania zapytań jest odciążenie lub wypchnięcie jak najwięcej oceny zapytania do źródła danych, które może obliczyć przekształcenia zapytania.
Mechanizm składania zapytań osiąga ten cel, tłumacząc skrypt języka M na język, który może być interpretowany i wykonywany przez źródło danych. Następnie wypycha ocenę do źródła danych i wysyła wynik tej oceny do dodatku Power Query.
Ta operacja często zapewnia znacznie szybsze wykonywanie zapytań niż wyodrębnianie wszystkich wymaganych danych ze źródła danych i uruchamianie wszystkich przekształceń wymaganych przez aparat Power Query.
Gdy używasz środowiska pobierania danych, dodatek Power Query przeprowadzi Cię przez proces, który ostatecznie umożliwia nawiązanie połączenia ze źródłem danych. W tym celu dodatek Power Query używa serii funkcji w języku M sklasyfikowanych jako uzyskiwanie dostępu do funkcji danych. Te konkretne funkcje używają mechanizmów i protokołów do nawiązywania połączenia ze źródłem danych przy użyciu języka, który może zrozumieć źródło danych.
Jednak kroki, które należy wykonać w zapytaniu, to kroki lub przekształcenia, które mechanizm składania zapytań próbuje zoptymalizować. Następnie sprawdza, czy można je odciążyć do źródła danych zamiast przetwarzać przy użyciu aparatu Power Query.
Ważne
Wszystkie funkcje źródła danych, często wyświetlane jako krok źródłowy zapytania, wysyła zapytania do danych w źródle danych w języku natywnym. Mechanizm składania zapytań jest używany we wszystkich przekształceniach zastosowanych do zapytania po funkcji źródła danych, dzięki czemu można je przetłumaczyć i połączyć w jedno zapytanie źródła danych lub dowolną liczbę przekształceń, które można odciążyć do źródła danych.
W zależności od struktury zapytania może istnieć trzy możliwe wyniki dla mechanizmu składania zapytań:
- Pełne składanie zapytań: gdy wszystkie przekształcenia zapytań są wypychane z powrotem do źródła danych i minimalne przetwarzanie odbywa się w a aparatze Power Query.
- Częściowe składanie zapytań: jeśli tylko kilka przekształceń w zapytaniu, a nie wszystkie, można odepchnąć z powrotem do źródła danych. W takim przypadku tylko podzbiór przekształceń odbywa się w źródle danych, a pozostałe przekształcenia zapytań są wykonywane w aucie Power Query.
- Brak składania zapytań: jeśli zapytanie zawiera przekształcenia, których nie można przetłumaczyć na natywny język zapytań źródła danych, ponieważ przekształcenia nie są obsługiwane lub łącznik nie obsługuje składania zapytań. W tym przypadku dodatek Power Query pobiera nieprzetworzone dane ze źródła danych i używa aparatu Power Query do osiągnięcia żądanych danych wyjściowych przez przetwarzanie wymaganych przekształceń na poziomie aparatu Power Query.
Uwaga
Mechanizm składania zapytań jest dostępny głównie w łącznikach dla źródeł danych ustrukturyzowanych, takich jak microsoft SQL Server i źródło danych OData, ale nie tylko. W fazie optymalizacji aparat może czasami zmienić kolejność kroków w zapytaniu.
Wykorzystanie źródła danych, które ma więcej zasobów przetwarzania i ma możliwości składania zapytań, może przyspieszyć czas ładowania zapytań, gdy przetwarzanie odbywa się w źródle danych, a nie w aucie Power Query.
Następne kroki
Aby uzyskać szczegółowe przykłady trzech możliwych wyników mechanizmu składania zapytań, zobacz Przykłady składania zapytań.
Aby uzyskać informacje na temat wskaźników składania zapytań znalezionych w okienku Zastosowane kroki , przejdź do sekcji Wskaźniki składania zapytań
Opinia
Dostępne już wkrótce: W 2024 r. będziemy stopniowo wycofywać zgłoszenia z serwisu GitHub jako mechanizm przesyłania opinii na temat zawartości i zastępować go nowym systemem opinii. Aby uzyskać więcej informacji, sprawdź: https://aka.ms/ContentUserFeedback.
Prześlij i wyświetl opinię dla