Identyfikowanie raportów o błędach zabezpieczeń na podstawie tytułów raportów i hałaśliwych danych
| Mayana Pereira | Scott Christiansen |
|---|---|
| CELA — nauka o danych | Bezpieczeństwo i zaufanie klientów |
| Microsoft | Microsoft |
Abstrakcyjne — identyfikowanie raportów o błędach zabezpieczeń jest istotnym krokiem w cyklu tworzenia oprogramowania. W przypadku nadzorowanych rozwiązań do uczenia maszynowego zazwyczaj przyjmuje się, że wszystkie raporty o błędach są dostępne do trenowania i że ich etykiety są wolne od szumów. Zgodnie z naszą najlepszą wiedzą jest to pierwsze badanie pokazujące, że precyzyjne prognozowanie etykiet jest możliwe dla raportów o błędach zabezpieczeń nawet wtedy, gdy jest dostępny tylko tytuł i w obecności szumu etykiet.
Terminy indeksu — uczenie maszynowe, błędne etykietowanie, szum, raport o błędach zabezpieczeń, repozytoria błędów
I. WPROWADZENIE
Identyfikowanie problemów związanych z zabezpieczeniami spośród zgłoszonych błędów jest ważne dla zespołów deweloperów oprogramowania, ponieważ takie problemy wymagają szybszych poprawek w celu spełnienia wymagań dotyczących zgodności oraz zapewnienia integralności oprogramowania i danych klientów.
Uczenie maszynowe i narzędzia sztucznej inteligencji umożliwiają szybsze, elastyczne i poprawne tworzenie oprogramowania. Badacze zastosowali uczenie maszynowe do problemu identyfikowania błędów zabezpieczeń [2], [7], [8], [18]. W poprzednich opublikowanych badaniach przyjęto założenie, że cały raport o błędach jest dostępny do trenowania i oceniania modelu uczenia maszynowego. Niekoniecznie to jest istotą problemu. Występują sytuacje, w których nie można udostępnić całego raportu o błędach. Na przykład raport o błędach może zawierać hasła, dane osobowe lub inne rodzaje poufnych danych — sytuacja, która obecnie występuje w firmie Microsoft. W związku z tym ważne jest określenie, jak dobrze można przeprowadzić identyfikację błędów zabezpieczeń przy użyciu mniejszej ilości informacji, na przykład gdy dostępny jest tylko tytuł raportu o błędach.
Ponadto repozytoria błędów często zawierają błędne etykiety wpisów [7]: raporty błędów niezwiązanych z zabezpieczeniami sklasyfikowane jako związane z zabezpieczeniami i odwrotnie. Istnieje kilka powodów nieprawidłowego etykietowania, od braku wiedzy zespołu deweloperów w zakresie bezpieczeństwa po rozmycie niektórych problemów, na przykład błędy niezwiązane z zabezpieczeniami mogą być wykorzystywane w sposób pośredni, aby wpłynąć na zabezpieczenia. Jest to poważny problem, ponieważ błędne etykietowanie raportów o błędach zabezpieczeń powoduje, że specjaliści ds. zabezpieczeń muszą ręcznie przejrzeć bazę danych błędów, co jest kosztowne i czasochłonne. Zrozumienie, jak szum wpływa na różne klasyfikatory oraz jak niezawodne (lub słabe) są różne techniki uczenia maszynowego w obecności zestawów danych zanieczyszczonych różnego rodzaju szumem, jest problemem, który należy rozwiązać, aby zapewnić automatyczną klasyfikację w inżynierii oprogramowania.
Wstępne dane wskazują, że repozytoria błędów są wewnętrznie zaszumione i że szum może mieć niekorzystny wpływ na klasyfikatory uczenia maszynowego wydajności [7]. Nie istnieją jednak żadne systematyczne i ilościowe analizy, jak różne poziomy i typy szumu wpływają na wydajność różnych nadzorowanych algorytmów uczenia maszynowego w przypadku problemu identyfikowania raportów o błędach zabezpieczeń.
W tym badaniu pokazujemy, że klasyfikację raportów o błędach można wykonać nawet wtedy, gdy do trenowania i oceniania jest dostępny tylko tytuł. Zgodnie z naszą najlepszą wiedzą na ten temat najpierw należy wykonać to działanie. Ponadto zapewniamy pierwsze systematyczne badanie wpływu szumu w klasyfikacji raportów o błędach. Prowadzimy badanie porównawcze dotyczące niezawodności trzech technik uczenia maszynowego (regresja logistyczna, prosty algorytm Bayesa i AdaBoost) względem szumu niezależnego od klasy.
Chociaż istnieją modele analityczne, które rejestrują ogólny wpływ szumu na kilka prostych klasyfikatorów [5], [6], te wyniki nie zapewniają ścisłych granic wpływu na szum pod względem dokładności i są prawidłowe tylko dla konkretnej techniki uczenia maszynowego. Dokładna analiza efektów szumu w modelach uczenia maszynowego jest zwykle przeprowadzana w ramach eksperymentów obliczeniowych. Takie analizy zostały wykonane dla kilku scenariuszy od danych pomiaru oprogramowania [4] do klasyfikacji obrazów satelitarnych [13] i danych medycznych [12]. Nie można jednak przełożyć tych wyników na konkretny problem ze względu na jego wysoką zależność od charakteru zestawów danych i problemu klasyfikacji. Zgodnie z naszą najlepszą wiedzą nie ma opublikowanych wyników dotyczących wpływu zaszumionych zestawów danych na klasyfikację raportów o błędach zabezpieczeń.
NASZ WKŁAD W BADANIA:
Klasyfikatory są trenowane do identyfikowania raportów o błędach zabezpieczeń tylko na podstawie tytułu raportów. Zgodnie z naszą najlepszą wiedzą na ten temat najpierw należy wykonać to działanie. W poprzednich pracach użyto kompletnego raportu o błędach lub dodano do raportu o błędach dodatkowe funkcje uzupełniające. Klasyfikowanie błędów na podstawie samego kafelka jest szczególnie istotne w przypadku, gdy kompletne raporty o błędach nie mogą zostać udostępnione ze względu na kwestie związane z prywatnością. Na przykład często występują raporty o błędach, które zawierają hasła i inne poufne dane.
Zapewniamy również pierwsze systematyczne badanie tolerancji szumu etykiet w różnych modelach uczenia maszynowego i technikach używanych do automatycznej klasyfikacji raportów o błędach zabezpieczeń. Prowadzimy badanie porównawcze dotyczące niezawodności trzech różnych technik uczenia maszynowego (regresja logistyczna, prosty algorytm Bayesa i AdaBoost) względem szumu zależnego i niezależnego od klasy.
Pozostała część artykułu jest przedstawiona w następujący sposób: W sekcji II przedstawimy niektóre z poprzednich prac w literaturze. W sekcji III opisano zestaw danych i sposób, w jaki dane są wstępnie przetwarzane. Metodologia jest opisana w sekcji IV, a wyniki naszych eksperymentów przeanalizowano w sekcji V. Nasze wnioski i przyszłe działania są przedstawione w sekcji VI.
II. POPRZEDNIE DZIAŁANIA
ZASTOSOWANIE UCZENIA MASZYNOWEGO W REPOZYTORIACH BŁĘDÓW.
Istnieje obszerna literatura w zakresie stosowania wyszukiwania tekstu, przetwarzania języka naturalnego i uczenia maszynowego w odniesieniu do repozytoriów błędów próbujących zautomatyzować pracochłonne zadania, takie jak wykrywanie błędów zabezpieczeń [2], [7], [8], [18], znajdowanie zduplikowanych błędów [3], klasyfikacja błędów [1], [11]. W idealnym przypadku połączenie uczenia maszynowego i przetwarzania języka naturalnego może ograniczyć czynności ręczne wymagane do nadzorowania baz danych błędów, skrócić czas wymagany do wykonania tych zadań i zwiększyć niezawodność wyników.
W punkcie [7] autorzy proponują model języka naturalnego w celu zautomatyzowania klasyfikacji raportów o błędach zabezpieczeń na podstawie opisu błędu. Autorzy wyodrębniają słownictwo ze wszystkich opisów błędów w zestawie danych treningowych i ręcznie nadzorują ją na trzech listach wyrazów: odpowiednie wyrazy, wyrazy zatrzymania (typowe słowa, które wydają się nieistotne dla klasyfikacji) i synonimy. Porównują wydajność klasyfikatora błędów zabezpieczeń wytrenowanego na danych, które są oceniane przez inżynierów ds. zabezpieczeń, i klasyfikatora wytrenowanego na danych, które były ogólnie opisane w raportach błędów. Mimo że model ten jest bardziej efektywny, gdy jest wytrenowany na danych przeglądanych przez inżynierów ds. zabezpieczeń, proponowany model jest oparty na ręcznie tworzonym słownictwie, co sprawia, że zależy od nadzoru ludzkiego. Ponadto nie istnieje analiza, w jaki sposób różne poziomy szumu wpływają na model, jak różne klasyfikatory reagują na szum oraz czy szum w jednej z klas ma inny wpływ na wydajność.
Zou et. al [18] używać wielu typów informacji zawartych w raporcie o usterce, które obejmują pola nietekstowe raportu o usterce (funkcje meta, np. czas, ważność i priorytet) oraz tekstową zawartość raportu o usterce (funkcje tekstowe, tj. tekst w polach podsumowania). Na podstawie tych funkcji tworzą model, który automatycznie identyfikuje raporty o błędach zabezpieczeń za pośrednictwem technik przetwarzania języka naturalnego i uczenia maszynowego. W punkcie [8] autorzy wykonują podobną analizę, ale dodatkowo porównują wydajność nadzorowanych i nienadzorowanych technik uczenia maszynowego oraz sprawdzają, ile danych jest potrzebnych do trenowania modeli.
W punkcie [2] autorzy omawiają również różne techniki uczenia maszynowego, aby sklasyfikować błędy jako raporty o błędach zabezpieczeń lub raporty o błędach niezwiązanych z zabezpieczeniami na podstawie ich opisów. Proponują potok na potrzeby przetwarzania danych i trenowania modeli na podstawie TFIDF. Porównują proponowany potok z modelem na podstawie zbioru wyrazów i prostego algorytmu Bayesa. Wijayasekara et al. [16] używa również technik wyszukiwania tekstu do generowania wektora funkcji poszczególnych raportów błędów na podstawie częstych wyrazów w celu identyfikowania błędów ukrytego wpływu. Yang et al. [17] oświadcza identyfikację raportów o błędach o dużym wpływie (np. raportów o błędach zabezpieczeń) za pomocą częstotliwości terminów i prostego algorytmy Bayesa. W punkcie [9] autorzy proponują model do przewidywania ważności błędu.
SZUM ETYKIET
Problem związany z zestawami danych z szumem etykiet został szeroko przeanalizowany. Frenay i Verleysen proponują taksonomię szumów etykiet w punkcie [6] w celu odróżnienia różnych typów zaszumionych etykiet. Autorzy proponują trzy różne typy szumów: szum etykiet występujący niezależnie od rzeczywistej klasy i wartości funkcji wystąpienia, szum etykiet zależny tylko od rzeczywistej etykiety i szum etykiet, w którym prawdopodobieństwo błędnych etykiet zależy również od wartości funkcji. W naszym badaniu analizujemy dwa pierwsze typy szumów. Z perspektywy teoretycznej szum etykiet zwykle zmniejsza wydajność modelu [10] z wyjątkiem określonych przypadków [14]. Ogólnie rzecz biorąc, niezawodne metody polegają na unikaniu nadmiernego dopasowania w celu radzenia sobie z szumem etykiet [15]. Badanie efektów szumu w klasyfikacji zostało wykonane przed w wielu obszarach, takich jak klasyfikacja obrazu satelitarnego [13], klasyfikacja jakości oprogramowania [4] i klasyfikacja domeny medycznej [12]. Zgodnie z naszą najlepszą wiedzą nie ma opublikowanych badań, które analizują precyzyjną kwantyfikację efektów zaszumionych etykiet w ramach problemu klasyfikacji raportów o błędach zabezpieczeń. W tym scenariuszu dokładna relacja między poziomami szumu, typami szumu i obniżeniem wydajności nie została ustanowiona. Ponadto warto zrozumieć, w jaki sposób różne klasyfikatory zachowują się w obecności szumów. Ogólniej rzecz biorąc, nie znamy żadnej pracy, w której systematycznie przeanalizowano wpływ zaszumionych zestawów danych na wydajność różnych algorytmów uczenia maszynowego w kontekście raportów o błędach oprogramowania.
III. OPIS ZESTAWU DANYCH
Nasz zestaw danych składa się z 1 073 149 tytułów błędów, z których 552 073 odpowiada raportom o błędach zabezpieczeń, a 521 076 raportom o błędach niezwiązanych z zabezpieczeniami. Dane zostały zebrane od różnych zespołów w firmie Microsoft w latach 2015, 2016, 2017 i 2018. Wszystkie etykiety zostały uzyskane przez systemy weryfikacji błędów na podstawie sygnaturach lub dodane przez człowieka. Tytuły błędów w naszym zestawie danych to krótkie teksty zawierające około 10 wyrazów z omówieniem problemu.
Odp. Przetwarzanie wstępne danych — analizujemy każdy tytuł błędu za pomocą pustych miejsc, co powoduje wyświetlenie listy tokenów. Przetwarzamy każdą listę tokenów w następujący sposób:
Usuwanie wszystkich tokenów, które są ścieżkami plików
Podział tokenów, w których znajdują się następujące symbole: { , (, ), -, }, {, [, ], }
Usuń wyrazy zatrzymania — tokeny, które składają się tylko ze znaków liczbowych i tokenów, które są wyświetlane mniej niż 5 razy w całym korpusie.
IV. METODOLOGIA
Proces trenowania modeli uczenia maszynowego obejmuje dwa główne kroki: kodowanie danych do wektorów funkcji i trenowanie nadzorowanych klasyfikatorów uczenia maszynowego.
Odp. Wektory funkcji i techniki uczenia maszynowego
Pierwsza część obejmuje kodowanie danych do wektorów funkcji za pomocą algorytmu częstotliwości dokumentu odwróconej częstotliwości (TF-IDF), jak użyto w punkcie [2]. TF-IDF jest techniką pobierania informacji, która waży częstotliwość terminów (TF) i jej odwróconą częstotliwość dokumentu (IDF). Każdy wyraz lub termin ma odpowiednie wyniki TF i IDF. Algorytm TF-IDF przypisuje ważność do tego wyrazu w oparciu o liczbę wystąpień w dokumencie, a co ważniejsze, sprawdza, jak odpowiednie słowo kluczowe znajduje się w całej kolekcji tytułów w zestawie danych. Wytrenowaliśmy i porównaliśmy trzy techniki klasyfikacji: prosty algorytm Bayesa, wzmocnione drzewa decyzyjne (AdaBoost) i regresja logistyczna. Wybraliśmy te metody, ponieważ zostały one przedstawione jako działające dobrze dla powiązanego zadania identyfikacji raportów o błędach zabezpieczeń w oparciu o cały raport w literaturze. Wyniki te zostały potwierdzone we wstępnej analizie, w której te trzy klasyfikatory były wydajniejsze niż pomocnicze maszyny wektorowe i lasy losowe. W naszych eksperymentach korzystamy z biblioteki scikit-learn w zakresie kodowania i trenowania modeli.
B. Typy szumów
Szum badany w tej pracy odnosi się do szumu w etykiecie klasy w danych trenowania. W przypadku występowania takiego szumu proces uczenia i model wynikowy są ograniczone przez przykłady z niewłaściwymi etykietami. Analizujemy wpływ różnych poziomów szumu zastosowanych do informacji o klasie. Typy szumów etykiet zostały wcześniej omówione w literaturze przy użyciu różnych terminologii. W naszej pracy analizujemy skutki dwóch różnych szumów etykiet w naszych klasyfikatorach: szumu etykiety niezależnej od klasy, który jest wprowadzany przez losowy wybór wystąpień i przerzucanie ich etykiety, i szumu zależnego od klasy, w przypadku którego klasy mają różne prawdopodobieństwo szumu.
a) Szum niezależny od klasy: niezależny od klasy szum odnosi się do szumu, który występuje niezależnie od prawdziwej klasy wystąpień. W przypadku tego typu szumu prawdopodobieństwo dodania niewłaściwej etykiety pbr jest takie samo dla wszystkich wystąpień w zestawie danych. Wprowadzamy niezależny od klasy szum w naszych zestawach danych przez losowe przerzucanie każdej etykiety w zestawie danych przy prawdopodobieństwie pbr.
b) Szum zależny od klasy: Szum zależny od klasy odnosi się do szumu, który zależy od prawdziwej klasy wystąpień. W przypadku tego typu szumu prawdopodobieństwo dodania niewłaściwej etykiety w raporcie o błędach zabezpieczeń klasy wynosi psbr, a prawdopodobieństwo dodania niewłaściwej etykiety w klasie NSBR to pnsbr. Wprowadzamy szum zależny od klasy w naszym zestawie danych przez przerzucenie każdego wpisu w zestawie danych, dla którego etykieta to SBR z prawdopodobieństwem psbr. Analogicznie przerzucamy etykietę klasy wystąpień NSBR z prawdopodobieństwem pnsbr.
c) Szum jednoklasowy: Szum jednoklasowy jest specjalnym przypadkiem szumu zależnego od klasy, gdzie pnsbr = 0 i psbr> 0. Należy pamiętać, że w przypadku szumu niezależnego od klasy mamy psbr = pnsbr = pbr.
C. Generowanie szumów
Nasze eksperymenty badają wpływ różnych typów i poziomów szumów w trenowaniu klasyfikatorów SBR. W naszych eksperymentach ustawiono 25% zestawu danych jako dane testowe, 10% jako walidację i 65% jako dane trenowania.
Dodaliśmy szum do zestawów danych trenowania i walidacji dla różnych poziomów pbr, psbr i pnsbr. Nie wprowadzono żadnych zmian w zestawie danych testowych. Różne używane poziomy szumu to P = {0,05 × i|0 < i < 10}.
W przypadku eksperymentów szumów niezależnych od klasy dla pbr ∈ P wykonujemy następujące czynności:
Generowanie szumu dla zestawów danych trenowania i walidacji;
Trenowanie modeli regresji logistycznej, prostego algorytmu Bayesa i AdaBoost używających zestawu danych trenowania (z szumem); * Dostosowywanie modeli przy użyciu zestawu danych walidacji (z szumem);
Testowanie modeli przy użyciu zestawu danych testowych (bez szumu).
W przypadku eksperymentów szumów zależnych od klasy dla psbr ∈ P i pnsbr ∈ P wykonujemy następujące czynności dla wszystkich kombinacji psbr i pnsbr:
Generowanie szumu dla zestawów danych trenowania i walidacji;
Trenowanie modeli regresji logistycznej, prostego algorytmu Bayesa i AdaBoost przy użyciu zestawu danych trenowania (z szumem);
Dostosowywanie modeli przy użyciu zestawu danych walidacji (z szumem);
Testowanie modeli przy użyciu zestawu danych testowych (bez szumu).
V. WYNIKI EKSPERYMENTALNE
W tej sekcji przeanalizowano wyniki eksperymentów przeprowadzonych zgodnie z metodologią opisaną w sekcji IV.
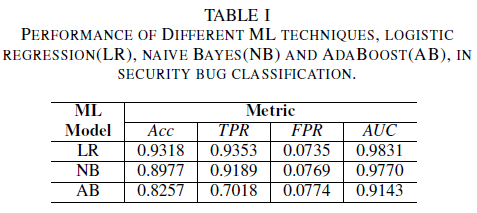
a) Wydajność modelu bez szumu w zestawie danych treningowych: Jednym z elementów tego artykułu jest propozycja modelu uczenia maszynowego w celu zidentyfikowania usterek zabezpieczeń przy użyciu tylko tytułu usterki jako danych do podejmowania decyzji. Umożliwia to trenowanie modeli uczenia maszynowego, nawet gdy zespoły deweloperów nie chcą udostępniać raportów o błędach w całości z powodu obecności poufnych danych. Porównano wydajność trzech modeli uczenia maszynowego wytrenowanych przy użyciu tylko tytułów błędów.
Model regresji logistycznej jest klasyfikatorem o najlepszej wydajności. Jest to klasyfikator z największą wartością AUC równą 0,9826, kompletność równą 0,9353 dla wartości FPR 0,0735. Klasyfikator prostego algorytmu Bayesa przedstawia nieco niższą wydajność niż klasyfikator regresji logistycznej z wartością AUC 0,9779 i kompletnością 0,9189 dla wartości FPR 0,0769. Klasyfikator AdaBoost ma gorszą wydajność w porównaniu do dwóch wcześniej wymienionych klasyfikatorów. Osiąga wartość AUC 0,9143 i kompletność 0,7018 dla wartości PFR 0,0774. Obszar pod krzywą ROC (AUC) jest dobrą metryką do porównywania wydajności kilku modeli, ponieważ podsumowuje w jednej wartości relację TPR a FPR. W kolejnej analizie ograniczymy nasze analizy porównawcze do wartości AUC.
Odp. Szum klasy: pojedyncza klasa
Załóżmy scenariusz, w którym wszystkie błędy są domyślnie przypisane do wartości NSBR klasy, a błąd zostanie przypisany tylko do wartości SBR klasy, jeśli specjalista ds. zabezpieczeń przegląda repozytorium błędów. Ten scenariusz jest reprezentowany w jednoklasowym ustawieniu eksperymentalnym, w którym zakładamy, że pnsbr = 0 i 0 < psbr< 0,5.
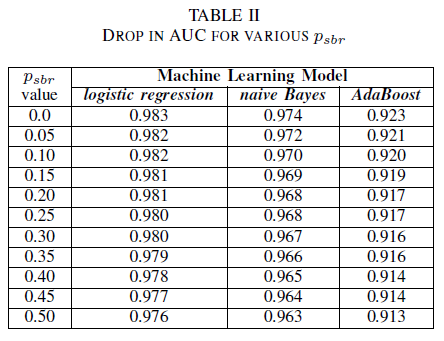
W tabeli II zaobserwowano bardzo mały wpływ na wartość AUC dla wszystkich trzech klasyfikatorów. Wartość AUC-ROC z modelu wytrenowanego na psbr = 0 w porównaniu do wartości AUC-ROC modelu, gdzie psbr = 0,25 różni się o 0,003 w przypadku regresji logistycznej, o 0,006 w przypadku prostego algorytmu Bayesa i o 0,006 dla klasyfikatora AdaBoost. W przypadku psbr = 0,50 wartość AUC zmierzona dla każdego z modeli różni się od modelu wytrenowanego za pomocą psbr = 0 o 0,007 dla regresji logistycznej, o 0,011 dla prostego algorytmu Bayesa i o 0,010 dla klasyfikatora AdaBoost. Klasyfikator regresji logistycznej wytrenowany w obecności szumu jednej klasy przedstawia najmniejsze zmiany w swojej metryce AUC, czyli bardziej niezawodne zachowanie w porównaniu z naszymi klasyfikatorami prostego algorytmu Bayesa i AdaBoost.
B. Szum klasy: niezależny od klasy
Porównujemy wydajność naszych trzech klasyfikatorów, gdy zestaw trenowania jest uszkodzony przez niezależny od klasy szum. Mierzymy wartość AUC dla każdego modelu, który jest wytrenowany przy użyciu różnych poziomów pbr w danych treningowych.

W tabeli III obserwujemy spadek wartości AUC-ROC dla każdego przyrostu szumu w eksperymencie. Wartość AUC-ROC mierzona dla modelu wytrenowanego dla danych bez szumu w porównaniu z wartością AUC-ROC modelu wytrenowanego z niezależnym od klasy szumem z pbr = 0,25 różni się o 0,011 w przypadku regresji logistycznej, o 0,008 w przypadku prostego algorytmu Bayesa i o 0,0038 w przypadku klasyfikatora AdaBoost. Obserwujemy, że szum etykiet nie ma znaczącego wpływu na wartość AUC prostego algorytmu Bayesa i AdaBoost, gdy poziomy szumu są mniejsze niż 40%. Z drugiej strony klasyfikator regresji logistycznej odnotowuje wpływ na miarę AUC dla poziomów szumów etykiet powyżej 30%.
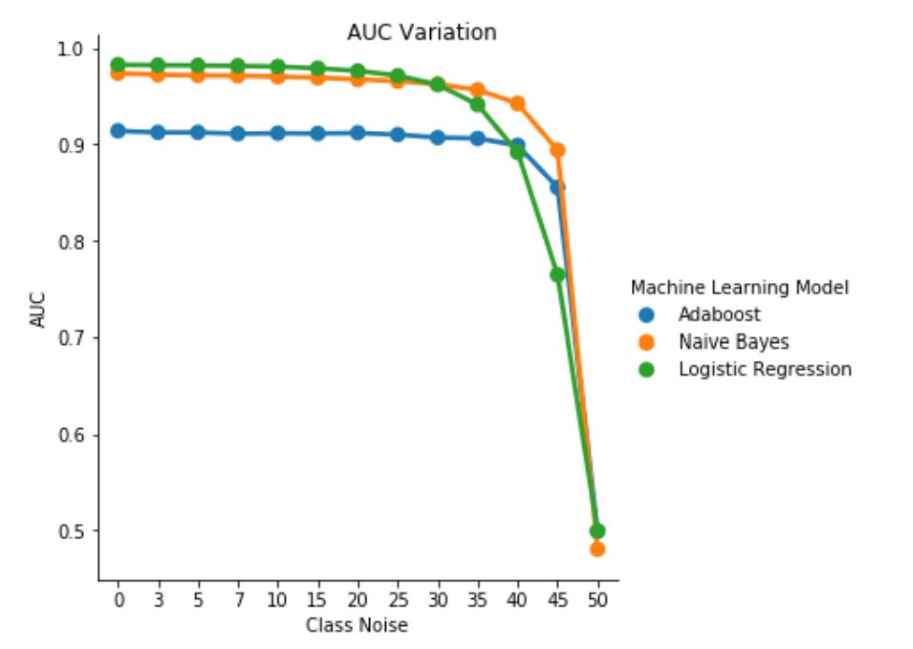
Rys. 1. Odmiana AUC-ROC w niezależnym od klasy szumie. Dla poziomu szumu pbr = 0,5 klasyfikator działa jak klasyfikator losowy, tj. AUC ≈ 0,5. Jednak możemy zaobserwować, że w przypadku niższych poziomów szumu (pbr ≤ 0,30) nauka regresji logistycznej przedstawia lepszą wydajność w porównaniu z dwoma pozostałymi modelami. Jednak w przypadku 0,35 ≤ pbr ≤ 0,45 prosty algorytm Bayesa ma lepsze metryki AUCROC.
C. Szum klasy: zależny od klasy
W ostatnim zestawie eksperymentów rozważamy scenariusz, w którym różne klasy zawierają różne poziomy szumu, tj. psbr ≠ pnsbr. Systematycznie zwiększamy psbr i pnsbr niezależnie o 0,05 w danych treningowych i obserwujemy zmianę zachowania trzech klasyfikatorów.
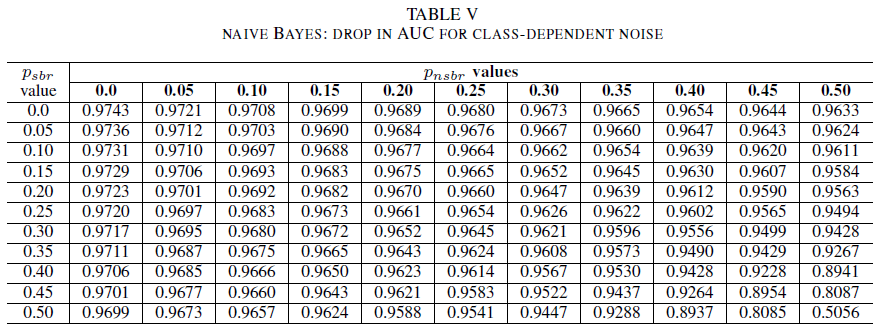
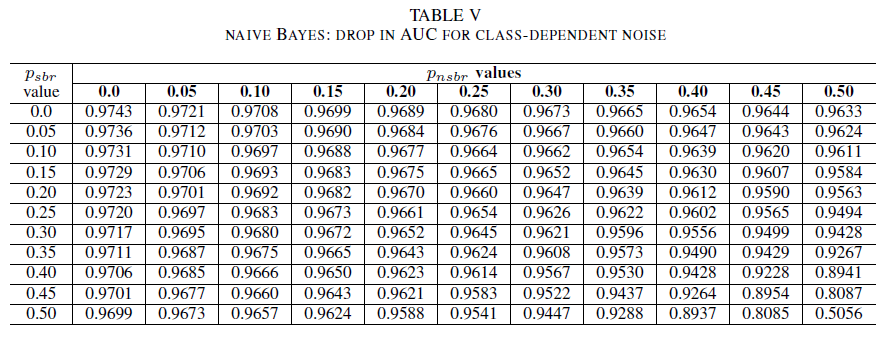

Tabele IV, V i VI wykazują wzrost zmiany AUC jako szumu na różnych poziomach w każdej klasie dla regresji logistycznej w tabeli IV, dla prostego algorytmu Bayesa w tabeli V i dla AdaBoost w tabeli VI. Dla wszystkich klasyfikatorów zauważono wpływ na metrykę AUC, gdy obie klasy mają poziom szumu powyżej 30%. Prosty algorytm Bayesa zachowuje się najbardziej niezawodnie. Wpływ na wartość AUC jest bardzo mały nawet wtedy, gdy 50% etykiety w klasie pozytywnej są przerzucane, pod warunkiem że klasa negatywna zawiera 30% lub mniej etykiet zaszumionych. W takim przypadku spadek wartości AUC wynosi 0,03. AdaBoost przedstawia najbardziej niezawodne zachowanie spośród wszystkich trzech klasyfikatorów. Znacząca zmiana wartości AUC nastąpi tylko dla poziomów szumu większych niż 45% w obu klasach. W takim przypadku zaczniemy obserwować spadek wartość AUC o więcej niż 0,02.
D. W obecności pozostałego szumu w oryginalnym zestawie danych
Nasz zestaw danych został oznaczony etykietą przez zautomatyzowane systemy oparte na sygnaturach i przez ekspertów. Ponadto wszystkie raporty o błędach zostały przejrzane i zamknięte przez ekspertów. Chociaż oczekujemy, że szum w naszym zestawie danych jest minimalny i nie jest statystycznie znaczący, obecność pozostałego szumu nie unieważnia naszych wniosków. Na potrzeby ilustracji przyjęto założenie, że oryginalny zestaw danych jest uszkodzony przez niezależny od klasy szum równy 0 < p < 1/2 niezależny i identyczny rozkład (i.i.d) dla każdego wpisu.
Jeśli do oryginalnego szumu zostanie dodany niezależny od klasy szum z prawdopodobieństwem pbr i.i.d, wynikowy szum na wpis będzie równy p∗ = p(1 − pbr)+(1 − p)pbr. Dla 0 < p,pbr< 1/2 mamy, że rzeczywisty szum na etykietę p∗ jest ściśle większy niż szum, który sztucznie dodamy do zestawu danych pbr . W ten sposób wydajność naszych klasyfikatorów będzie jeszcze lepsza, jeśli zostały one wytrenowane z zestawem danych całkowicie bez szumów (p = 0). Podsumowując, istnienie szczątkowego szumu w rzeczywistym zestawie danych oznacza, że odporność na szumy naszych klasyfikatorów jest lepsza niż przedstawione tutaj wyniki. Ponadto, jeśli szczątkowy hałas w naszym zestawie danych był statystycznie istotny, wartość AUC naszych klasyfikatorów wynosiłaby 0,5 (losowe odgadnięcie) dla poziomu szumu, który jest ściśle mniejszy niż 0,5. Nie obserwujemy takiego zachowania w naszych wynikach.
VI. WNIOSKI I PRZYSZŁE DZIAŁANIA
Nasz udział w tym dokumencie to dwa cele.
Po pierwsze przedstawiono możliwość klasyfikacji raportów o błędach zabezpieczeń na podstawie wyłącznie tytułu raportu o błędach. Jest to szczególnie istotne w scenariuszach, w których cały raport o błędach nie jest dostępny z powodu ograniczeń prywatności. Na przykład w naszym przypadku raporty o błędach zawierały prywatne informacje, takie jak hasła i klucze kryptograficzne, i nie były dostępne do trenowania klasyfikatorów. Nasz wynik pokazuje, że identyfikacja SBR może być przeprowadzana z wysoką dokładnością nawet wtedy, gdy są dostępne tylko tytuły raportów. Nasz model klasyfikacji, który korzysta z kombinacji TF-IDF i regresji logistycznej, ma wartość AUC 0,9831.
Po drugie przeanalizowaliśmy wpływ nieoznaczonych etykietami danych trenowania i walidacji. Porównano trzy dobrze znane techniki klasyfikacji uczenia maszynowego (prosty algorytm Bayesa, regresja logistyczna i AdaBoost) pod względem ich niezawodności przy różnych typach i poziomach szumu. Wszystkie trzy klasyfikatory są niezawodne dla szumu pojedynczej klasy. Szum w danych treningowych nie ma znaczącego wpływu na wynikowy klasyfikator. Spadek wartości AUC jest bardzo mały (0,01) dla poziomu szumu 50%. W przypadku szumu obecnego w obu klasach, który jest niezależny od klasy, prosty algorytm Bayesa i model AdaBoost prezentują znaczące wahania wartości AUC tylko w przypadku wytrenowania za pomocą zestawu danych z poziomami szumu większymi niż 40%.
Na koniec szum zależny od klasy znacząco wpływa na wartość AUC tylko wtedy, gdy w obu klasach występuje więcej niż 35% szumu. Model AdaBoost wykazał największą niezawodność. Wpływ na wartość AUC jest bardzo mały nawet wtedy, gdy klasa pozytywna ma 50% etykiet zaszumionych, pod warunkiem że klasa negatywna zawiera 45% lub mniej etykiet zaszumionych. W takim przypadku spadek wartości AUC jest mniejszy niż 0,03. Zgodnie z naszą najlepszą wiedzą jest to pierwsze systematyczne badanie wpływu zaszumionych zestawów danych na potrzeby identyfikacji raportów o błędach zabezpieczeń.
PRZYSZŁE DZIAŁANIA
W tym dokumencie zostało rozpoczęte systematyczne badanie wpływu szumu na wydajność klasyfikatorów uczenia maszynowego w celu identyfikacji błędów zabezpieczeń. Istnieje kilka interesujących kontynuacji tej pracy, w tym: badanie wpływu zaszumionych zestawów danych na określanie poziomu ważności błędu zabezpieczeń; zrozumienie skutków nierównowagi klasy na odporność wytrenowanych modeli na szum; zrozumienie wpływu szumu wprowadzonego w zestawie danych.
DOKUMENTACJA
[1] John Anvik, Lyndon Hiew i Gail C Murphy. Kto powinien naprawić ten błąd? W dokumencie Działania w ramach 28. międzynarodowej konferencji dotyczącej inżynierii oprogramowania, strony 361–370. ACM, 2006.
[2] Diksha Behl, Sahil Handa i Anuja Arora. Narzędzie wyszukiwania błędów do identyfikowania i analizowania błędów zabezpieczeń przy użyciu prostego algorytmu Bayesa i TF-IDF. W dokumencie Optymalizacja, niezawodność i technologie informatyczne (ICROIT), międzynarodowa konferencja z 2014 r. na stronach 294–299. IEEE, 2014.
[3] Nicolas Bettenburg, Rahul Premraj, Thomas Zimmermann i Sunghun Kim. Zduplikowane raporty o błędach są uważane za szkodliwe? W obszarze Konserwacja oprogramowania, 2008. ICSM 2008. Międzynarodowa konferencja IEEE na stronach 337–345. IEEE, 2008.
[4] Andres Folleco, Taghi M Khoshgoftaar, Jason Van Hulse i Lofton Bullard. Identyfikowanie mechanizmów nauki odpornych na dane o niskiej jakości. W obszarze Ponowne używanie informacji i integracja, 2008. IRI 2008. Międzynarodowa Konferencja IEEE na stronach 190–195. IEEE, 2008.
[5] Benoˆıt Frenay.´ Niepewność i szum etykiet w uczeniu maszynowym. Praca doktorska, Catholic University of Louvain, Louvain-la-Neuve, Belgia, 2013.
[6] Benoˆıt Frenay i Michel Verleysen. Klasyfikacja w obecności szumu etykiet: ankieta. Transakcje IEEE w sieciach neuronowych i systemach uczenia, 25 (5):845–869, 2014.
[7] Michael Gegick, Pete Rotella i Tao Xie. Identyfikowanie raportów o błędach zabezpieczeń za pośrednictwem wyszukiwania tekstu: analiza przypadku przemysłowego. W dokumencie Repozytoria wyszukiwania oprogramowania (MSR), 7 robocza konferencja IEEE z 2010 r., strony 11–20. IEEE, 2010.
[8] Katerina Goseva-Popstojanova i Jacob Tyo. Identyfikacja raportów o błędach zabezpieczeń za pośrednictwem wyszukiwania tekstu przy użyciu nadzorowanych i nienadzorowanych klasyfikacji. W dokumencie Międzynarodowa konferencja IEEE z 2018 r. dotycząca jakości, niezawodności i zabezpieczeń oprogramowania (QRS), strony 344–355, 2018.
[9] Ahmed Lamkanfi, Serge Demeyer, Emanuel Giger i Bart Goethals. Przewidywanie ważności zgłoszonego błędu. W dokumencie Repozytoria wyszukiwania oprogramowania (MSR), 7 robocza konferencja IEEE z 2010 r., strony 1–10. IEEE, 2010.
[10] Naresh Manwani i PS Sastry. Tolerancja szumu w ramach minimalizowania ryzyka. Transakcje IEEE dotyczące cybernetyki, 43 (3):1146–1151, 2013.
[11] G Murphy i D Cubranic. Automatyczna klasyfikacja błędów przy użyciu kategoryzacji tekstu. W dokumencie Działania w ramach 16. międzynarodowej konferencji dotyczącej inżynierii oprogramowania i inżynierii wiedzy. Citeseer, 2004.
[12] Mykola Pechenizkiy, Alexey Tsymbal, Seppo Puuronen i Oleksandr Pechenizkiy. Szum klasy i uczenie nadzorowane w domenach medycznych: efekt wyodrębniania cech. W dokumencie null, strony 708–713. IEEE, 2006.
[13] Charlotte Pelletier, Silvia Valero, Jordi Inglada, Nicolas Champion, Claire Marais Sicre i Gerard Dedieu.´ Wpływ szumu etykiet klas trenowania na wydajność klasyfikacji map terenu przy użyciu szeregów czasowych obrazów satelitarnych. Wykrywanie zdalne, 9(2):173, 2017.
[14] PS Sastry, GD Nagendra i Naresh Manwani. Zespół ds. ciągłego uczenia automatyzuje uczenie odporne na szum w półprzestrzeniach. Transakcje IEEE w systemach, relacjach międzyludzkich i cybernetyce, część B (cybernetyka), 40(1):19–28, 2010.
[15] Choh-Man Teng. Porównanie technik obsługi szumów. W dokumencie Konferencja FLAIRS, strony 269–273, 2001.
[16] Dumidu Wijayasekara, Milos Manic i Miles McQueen. Identyfikacja i klasyfikacja luk w zabezpieczeniach za pośrednictwem baz danych błędów wyszukiwania tekstu. W Industrial Electronics Society, IECON 2014-40th Annual Conference of the IEEE, strony 3612–3618. IEEE, 2014.
[17] Xinli Yang, David Lo, Qiao Huang, Xin Xia i Jianling Sun. Zautomatyzowana identyfikacja raportów o błędach o dużym wpływie korzystających z niezrównoważonych strategii uczenia. W dokumencie Konferencja dotycząca oprogramowania komputerowego i aplikacji (COMPSAC), 2016 — 40. coroczna konferencja IEEE, tom 1, strony 227–232. IEEE, 2016.
[18] Deqing Zou, Zhijun Deng, Zhen Li i Hai Jin. Automatyczne identyfikowanie raportów o błędach zabezpieczeń za pośrednictwem analizy funkcji wielu typów. W dokumencie Konferencja na temat bezpieczeństwa i prywatności w Australazji, strony 619–633. Springer, 2018.