Atividade de pesquisa no Azure Data Factory e no Azure Synapse Analytics
APLICA-SE A: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Gorjeta
Experimente o Data Factory no Microsoft Fabric, uma solução de análise tudo-em-um para empresas. O Microsoft Fabric abrange tudo, desde a movimentação de dados até ciência de dados, análises em tempo real, business intelligence e relatórios. Saiba como iniciar uma nova avaliação gratuitamente!
A atividade de pesquisa pode recuperar um conjunto de dados de qualquer uma das fontes de dados suportadas pelo data factory e pelos pipelines Synapse. Você pode usá-lo para determinar dinamicamente em quais objetos operar em uma atividade subsequente, em vez de codificar o nome do objeto. Alguns exemplos de objetos são arquivos e tabelas.
A atividade de pesquisa lê e retorna o conteúdo de um arquivo de configuração ou tabela. Ele também retorna o resultado da execução de uma consulta ou procedimento armazenado. A saída pode ser um valor singleton ou uma matriz de atributos, que podem ser consumidos em uma cópia, transformação ou atividades de fluxo de controle subsequentes, como a atividade ForEach.
Criar uma atividade de pesquisa com a interface do usuário
Para usar uma atividade de Pesquisa em um pipeline, conclua as seguintes etapas:
Procure Pesquisa no painel Atividades do pipeline e arraste uma atividade Pesquisa para a tela do pipeline.
Selecione a nova atividade Pesquisa na tela, se ainda não estiver selecionada, e a guia Configurações para editar seus detalhes.

Escolha um conjunto de dados de origem existente ou selecione o botão Novo para criar um novo.
As opções para identificar linhas a serem incluídas no conjunto de dados de origem variam de acordo com o tipo de conjunto de dados. O exemplo acima mostra as opções de configuração para um conjunto de dados de texto delimitado. Abaixo estão exemplos de opções de configuração para um conjunto de dados de tabela SQL do Azure e um conjunto de dados OData.
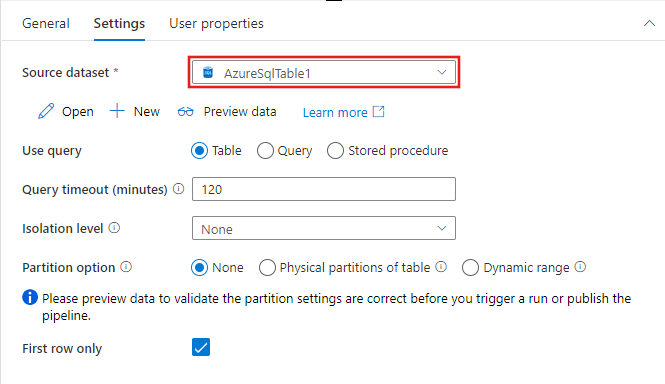
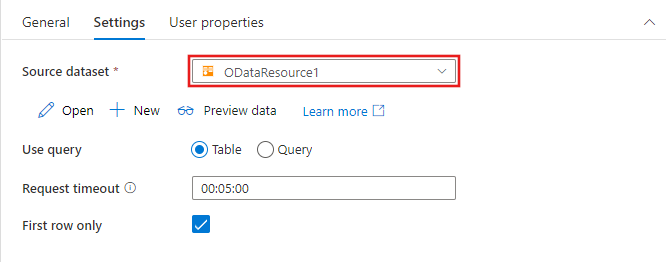
Capacidades suportadas
Tenha em atenção o seguinte:
- A atividade Pesquisa pode retornar até 5000 linhas, se o conjunto de resultados contiver mais registros, as primeiras 5000 linhas serão retornadas.
- A saída da atividade de pesquisa suporta até 4 MB de tamanho, a atividade falhará se o tamanho exceder o limite.
- A maior duração da atividade de Pesquisa antes do tempo limite é de 24 horas.
Nota
Quando você usa consulta ou procedimento armazenado para pesquisar dados, certifique-se de retornar um e exato um conjunto de resultados. Caso contrário, a atividade de pesquisa falhará.
As seguintes fontes de dados são suportadas para a atividade de pesquisa.
Nota
Qualquer conector marcado como Pré-visualização significa que o pode experimentar e enviar-nos comentários. Se quiser realizar uma dependência em conectores de pré-visualização na sua solução, contacte o Suporte do Azure.
Sintaxe
{
"name":"LookupActivity",
"type":"Lookup",
"typeProperties":{
"source":{
"type":"<source type>"
},
"dataset":{
"referenceName":"<source dataset name>",
"type":"DatasetReference"
},
"firstRowOnly":<true or false>
}
}
Propriedades do tipo
| Nome | Descrição | Type | Necessária? |
|---|---|---|---|
| conjunto de dados | Fornece a referência do conjunto de dados para a pesquisa. Obtenha detalhes da seção Propriedades do conjunto de dados em cada artigo do conector correspondente. | Par chave/valor | Sim |
| origem | Contém propriedades de origem específicas do conjunto de dados, as mesmas que a fonte Copy Activity. Obtenha detalhes na seção Copiar propriedades da atividade em cada artigo do conector correspondente. | Par chave/valor | Sim |
| firstRowOnly | Indica se deve retornar apenas a primeira linha ou todas as linhas. | Boolean | Não A predefinição é true. |
Nota
- Não há suporte para colunas de origem com o tipo ByteArray .
- A estrutura não é suportada em definições de conjunto de dados. Para arquivos de formato de texto, use a linha de cabeçalho para fornecer o nome da coluna.
- Se a origem da pesquisa for um arquivo JSON, a
jsonPathDefinitionconfiguração para remodelar o objeto JSON não será suportada. Os objetos inteiros serão recuperados.
Usar o resultado da atividade Pesquisa
O resultado da pesquisa é retornado na output seção do resultado da execução da atividade.
Quando
firstRowOnlyé definido como (padrão), o formato de saída é comotruemostrado no código a seguir. O resultado da pesquisa está sob uma chave fixafirstRow. Para usar o resultado na atividade subsequente, use o padrão de@{activity('LookupActivity').output.firstRow.table}.{ "firstRow": { "Id": "1", "schema":"dbo", "table":"Table1" } }Quando
firstRowOnlyé definido como , o formato de saída é comofalsemostrado no código a seguir. Umcountcampo indica quantos registros são retornados. Os valores detalhados são exibidos em uma matriz fixavalue. Nesse caso, a atividade Pesquisa é seguida por uma atividade Foreach. Você passa avaluematriz para o campo de atividadeitemsForEach usando o padrão de@activity('MyLookupActivity').output.value. Para acessar elementos navaluematriz, use a seguinte sintaxe:@{activity('lookupActivity').output.value[zero based index].propertyname}. Um exemplo é@{activity('lookupActivity').output.value[0].schema}.{ "count": "2", "value": [ { "Id": "1", "schema":"dbo", "table":"Table1" }, { "Id": "2", "schema":"dbo", "table":"Table2" } ] }
Exemplo
Neste exemplo, o pipeline contém duas atividades: Pesquisa e Cópia. A Atividade de Cópia copia dados de uma tabela SQL em sua instância do Banco de Dados SQL do Azure para o armazenamento de Blob do Azure. O nome da tabela SQL é armazenado em um arquivo JSON no armazenamento de Blob. A atividade Pesquisa procura o nome da tabela em tempo de execução. JSON é modificado dinamicamente usando essa abordagem. Não é necessário reimplantar pipelines ou conjuntos de dados.
Este exemplo demonstra a pesquisa apenas para a primeira linha. Para pesquisar todas as linhas e encadear os resultados com a atividade ForEach, consulte os exemplos em Copiar várias tabelas em massa.
Pipeline
- A atividade Pesquisa é configurada para usar LookupDataset, que se refere a um local no armazenamento de Blob do Azure. A atividade Pesquisa lê o nome da tabela SQL de um arquivo JSON neste local.
- A atividade de cópia usa a saída da atividade de pesquisa, que é o nome da tabela SQL. A propriedade tableName no SourceDataset é configurada para usar a saída da atividade Lookup. Copiar Atividade copia dados da tabela SQL para um local no armazenamento de Blob do Azure. O local é especificado pela propriedade SinkDataset .
{
"name": "LookupPipelineDemo",
"properties": {
"activities": [
{
"name": "LookupActivity",
"type": "Lookup",
"dependsOn": [],
"policy": {
"timeout": "7.00:00:00",
"retry": 0,
"retryIntervalInSeconds": 30,
"secureOutput": false,
"secureInput": false
},
"userProperties": [],
"typeProperties": {
"source": {
"type": "JsonSource",
"storeSettings": {
"type": "AzureBlobStorageReadSettings",
"recursive": true
},
"formatSettings": {
"type": "JsonReadSettings"
}
},
"dataset": {
"referenceName": "LookupDataset",
"type": "DatasetReference"
},
"firstRowOnly": true
}
},
{
"name": "CopyActivity",
"type": "Copy",
"dependsOn": [
{
"activity": "LookupActivity",
"dependencyConditions": [
"Succeeded"
]
}
],
"policy": {
"timeout": "7.00:00:00",
"retry": 0,
"retryIntervalInSeconds": 30,
"secureOutput": false,
"secureInput": false
},
"userProperties": [],
"typeProperties": {
"source": {
"type": "AzureSqlSource",
"sqlReaderQuery": {
"value": "select * from [@{activity('LookupActivity').output.firstRow.schema}].[@{activity('LookupActivity').output.firstRow.table}]",
"type": "Expression"
},
"queryTimeout": "02:00:00",
"partitionOption": "None"
},
"sink": {
"type": "DelimitedTextSink",
"storeSettings": {
"type": "AzureBlobStorageWriteSettings"
},
"formatSettings": {
"type": "DelimitedTextWriteSettings",
"quoteAllText": true,
"fileExtension": ".txt"
}
},
"enableStaging": false,
"translator": {
"type": "TabularTranslator",
"typeConversion": true,
"typeConversionSettings": {
"allowDataTruncation": true,
"treatBooleanAsNumber": false
}
}
},
"inputs": [
{
"referenceName": "SourceDataset",
"type": "DatasetReference",
"parameters": {
"schemaName": {
"value": "@activity('LookupActivity').output.firstRow.schema",
"type": "Expression"
},
"tableName": {
"value": "@activity('LookupActivity').output.firstRow.table",
"type": "Expression"
}
}
}
],
"outputs": [
{
"referenceName": "SinkDataset",
"type": "DatasetReference",
"parameters": {
"schema": {
"value": "@activity('LookupActivity').output.firstRow.schema",
"type": "Expression"
},
"table": {
"value": "@activity('LookupActivity').output.firstRow.table",
"type": "Expression"
}
}
}
]
}
],
"annotations": [],
"lastPublishTime": "2020-08-17T10:48:25Z"
}
}
Conjunto de dados de pesquisa
O conjunto de dados de pesquisa é o arquivo sourcetable.json na pasta de pesquisa do Armazenamento do Azure especificada pelo tipo AzureBlobStorageLinkedService.
{
"name": "LookupDataset",
"properties": {
"linkedServiceName": {
"referenceName": "AzureBlobStorageLinkedService",
"type": "LinkedServiceReference"
},
"annotations": [],
"type": "Json",
"typeProperties": {
"location": {
"type": "AzureBlobStorageLocation",
"fileName": "sourcetable.json",
"container": "lookup"
}
}
}
}
Conjunto de dados de origem para atividade de cópia
O conjunto de dados de origem usa a saída da atividade Pesquisa, que é o nome da tabela SQL. Copiar Atividade copia dados desta tabela SQL para um local no armazenamento de Blob do Azure. O local é especificado pelo conjunto de dados do coletor .
{
"name": "SourceDataset",
"properties": {
"linkedServiceName": {
"referenceName": "AzureSqlDatabase",
"type": "LinkedServiceReference"
},
"parameters": {
"schemaName": {
"type": "string"
},
"tableName": {
"type": "string"
}
},
"annotations": [],
"type": "AzureSqlTable",
"schema": [],
"typeProperties": {
"schema": {
"value": "@dataset().schemaName",
"type": "Expression"
},
"table": {
"value": "@dataset().tableName",
"type": "Expression"
}
}
}
}
Conjunto de dados do coletor para atividade de cópia
Copiar Atividade copia dados da tabela SQL para o arquivo filebylookup.csv na pasta csv no Armazenamento do Azure. O arquivo é especificado pela propriedade AzureBlobStorageLinkedService .
{
"name": "SinkDataset",
"properties": {
"linkedServiceName": {
"referenceName": "AzureBlobStorageLinkedService",
"type": "LinkedServiceReference"
},
"parameters": {
"schema": {
"type": "string"
},
"table": {
"type": "string"
}
},
"annotations": [],
"type": "DelimitedText",
"typeProperties": {
"location": {
"type": "AzureBlobStorageLocation",
"fileName": {
"value": "@{dataset().schema}_@{dataset().table}.csv",
"type": "Expression"
},
"container": "csv"
},
"columnDelimiter": ",",
"escapeChar": "\\",
"quoteChar": "\""
},
"schema": []
}
}
fontetable.json
Você pode usar dois tipos de formatos a seguir para o arquivo sourcetable.json .
Conjunto de objetos
{
"Id":"1",
"schema":"dbo",
"table":"Table1"
}
{
"Id":"2",
"schema":"dbo",
"table":"Table2"
}
Matriz de objetos
[
{
"Id": "1",
"schema":"dbo",
"table":"Table1"
},
{
"Id": "2",
"schema":"dbo",
"table":"Table2"
}
]
Limitações e soluções alternativas
Aqui estão algumas limitações da atividade Pesquisa e soluções alternativas sugeridas.
| Limitação | Solução |
|---|---|
| A atividade Pesquisa tem um máximo de 5.000 linhas e um tamanho máximo de 4 MB. | Projete um pipeline de dois níveis em que o pipeline externo itere sobre um pipeline interno, que recupera dados que não excedem as linhas ou o tamanho máximo. |
Conteúdos relacionados
Veja outras atividades de fluxo de controle suportadas pelos pipelines do Azure Data Factory e Sinapse: