Execução de teste
Analisando a exposição e o risco de projetos usando PERIL
Dr. James McCaffrey
Código disponível para download na MSDN Code Gallery
Navegue pelo código online
Sumário
Meta-riscos
Identificação de riscos
Análise de riscos
Conclusão
Todos os projetos de software enfrentam riscos. Um risco é um evento, que pode ou não ocorrer e que causa algum tipo de perda. A relação entre risco e teste de software é simples. Como, exceto em raras situações, não é possível testar exaustivamente um sistema de software, a análise de riscos revela problemas que podem causar a maior perda. Essas informações podem ser úteis para ajudá-lo a priorizar seu esforço de teste. Na coluna deste mês, apresento técnicas práticas para identificar e analisar os riscos envolvidos em um projeto de software. Vamos começar.
Imagine uma situação hipotética em que você esteja desenvolvendo um aplicativo ASP.NET baseado na Web de algum tipo. A Figura 1 ilustra alguns dos principais problemas e idéias associados à análise de riscos de software. O processo geral de análise de riscos envolve a identificação dos riscos, a estimativa da probabilidade de cada um, a determinação da perda associada a eles e a combinação de informações de possibilidade e de perda em um valor chamado exposição de risco.
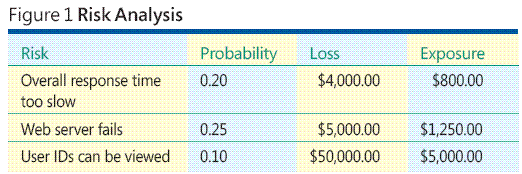
Segundo os dados de exemplo na Figura 1, o risco de que "IDs de usuário possam ser exibidas" tem a maior exposição, por isso, se os outros fatores forem iguais, provavelmente você vai querer priorizá-lo no teste a fim de evitar que o risco se torne realidade. Mas como identificar riscos? Como estimar perda e probabilidade de risco? É possível executar análise de riscos ainda que a perda e a probabilidade de risco não possam ser estimadas?
Apesar dos diversos esforços no sentido de formalizar e padronizar a terminologia da análise de riscos, na prática, termos diferentes tendem a ser usados em diferentes áreas problemáticas. Usarei o termo "análise de riscos" para significar a computação de exposição de risco por meio da multiplicação da possibilidade ou probabilidade de risco pela perda de risco, ou para indicar o processo geral de identificação, análise e gerenciamento de risco em projetos de software.
Embora a análise de riscos seja uma parte fundamental do desenvolvimento de software, minha experiência mostra que ainda há muitas técnicas de análise de riscos desconhecidas do grande público na comunidade de teste de software. Se você pesquisar na Web, encontrará milhares de referências a análise de riscos de software. Entretanto, a maioria dessas referências trata a análise de riscos em um nível muito alto, não apresenta técnicas práticas ou apresenta apenas uma técnica específica e não explica como adaptá-la a uma estrutura geral de análise de riscos. Apresentarei uma visão geral da análise de riscos, assim como técnicas úteis que podem ser empregadas imediatamente no ambiente de desenvolvimento de software.
Nas seções desta coluna, descrevo dois meta-riscos que são comuns a todos os projetos de software. Em seguida, apresento três formas de identificar riscos específicos associados ao seu projeto de software e três maneiras de analisar risco. Em particular, mostrarei uma interessante técnica nova de análise de riscos chamada Exposição de Projetos usando PERIL (Possibilidade e Impacto Classificados), que é especialmente útil em ambientes de desenvolvimento de software. Eu concluo com uma breve discussão sobre gerenciamento de risco. Acredito que as técnicas aqui apresentadas serão de grande valia para o seu kit de ferramentas de desenvolvimento, gerenciamento e teste de software.
Meta-riscos
Dois tipos especiais de análises de riscos de projetos de software são o que chamamos de análises de meta-riscos de custo e de tempo. O gerenciamento de projetos tradicional define um conceito que tem nomes diferentes como "a restrição tripla de gerenciamento de projetos" e "o triângulo de gerenciamento de projetos". Em resumo, a idéia é que praticamente todo projeto tem três fatores de limitação: custo, cronograma e escopo. Custo é quanto dinheiro você tem para gastar no projeto; cronograma é quanto tempo você tem para concluir o projeto; e escopo é o conjunto de recursos necessários e a qualidade deles.
Essas três restrições de projeto têm vários aliases. Por exemplo, custo também é conhecido como orçamento ou dinheiro. Cronograma costuma ser chamado de tempo ou duração. E escopo é chamado algumas vezes de recursos, qualidade ou até recursos/qualidade. Observe que essa última restrição pode ser (e, na verdade, geralmente é) considerada como duas restrições distintas.
Uma noção importante é que uma alteração em qualquer das restrições provavelmente modificará uma das outras restrições ou as duas. Por exemplo, se você estiver desenvolvendo um aplicativo de software e, de repente, precisar concluir o projeto em um prazo menor que o planejado, provavelmente terá de gastar mais dinheiro (para adquirir recursos adicionais ou terceirizar parte do projeto) ou cortar na qualidade ou em alguns recursos. Se o orçamento do seu projeto for cortado, é provável que você tenha de estender o prazo de conclusão do projeto, remover alguns recursos ou reduzir a qualidade do projeto. Usando o paradigma de triângulo de gerenciamento de projetos, já que a finalidade do teste de software é melhorar a qualidade de um sistema, conclui-se que os dois níveis mais altos de risco em um projeto de software são que o projeto não seja concluído dentro do prazo e que exceda o orçamento.
Existe uma maneira relativamente simples, mas eficaz, de estimar os riscos totais de custo e cronograma para um projeto de software. Vejamos apenas o meta-risco de tempo/cronograma (a análise do risco de orçamento/custo funciona exatamente do mesmo modo). A primeira etapa em uma análise de meta-riscos de alto nível é dividir o projeto em blocos de atividades menores e mais gerenciáveis.
Por exemplo, suponha que você está trabalhando em um projeto de aplicativo Web que precisa ser concluído em 30 dias úteis. Você começa a análise de meta-riscos listando todas as atividades envolvidas no projeto. A abordagem mais comum aqui é criar o que chamamos de estrutura de divisão de trabalho (WBS), como mostra a Figura 2. Você cria uma tarefa de nível superior que corresponde ao projeto inteiro e a divide em várias subtarefas, geralmente três a sete. Você repete o processo, decompondo cada tarefa secundária em subtarefas menores até alcançar o nível de granularidade apropriado para o seu ambiente.

Figura 2 Estrutura de divisão de trabalho
As tarefas de nó folha de nível inferior também são chamadas de pacotes de trabalho. O modo de decompor as tarefas e o nível de granularidade da WBS dependerão de vários fatores. Por exemplo, em um ambiente de desenvolvimento ágil, você pode decidir que uma estrutura de divisão de trabalho simples com profundidade de dois níveis atende às suas necessidades. Ou, se estiver trabalhando em um projeto de software muito grande e complexo usando uma metodologia tradicional de ciclo de vida de desenvolvimento de software, poderá ter milhares de pacotes de trabalho.
Você pode criar uma pequena WBS manualmente, usar ferramentas genéricas de produtividade como o Microsoft Office Excel ou fazer uso de ferramentas sofisticadas como o Microsoft Office Project. Uma WBS não contém informações de custo, de tempo ou de seqüenciamento. Em outras palavras, informa o que deve ser feito, mas não em que ordem, e não comunica quanto tempo cada tarefa levará ou quanto ela custará. Depois de gerar a estrutura de divisão de trabalho, a próxima etapa é usar os pacotes de trabalho para criar o que chamamos de diagrama de precedência.
.gif)
Figura 3 Diagrama de precedência
O diagrama de precedência adiciona informações de seqüenciamento. O diagrama mostrado na Figura 3 indica que a tarefa Requisitos deve ser concluída antes da tarefa Back-end de Banco de Dados, que, por sua vez, deve ser concluída antes que as tarefas Camada Intermediária e Front-end sejam iniciadas. Essas duas últimas tarefas podem ser executadas em paralelo, de acordo com o diagrama de precedência. Finalmente, tanto a tarefa Camada Intermediária como a Front-end devem ser concluídas antes da tarefa Implantar Aplicativo.
Depois de criar um diagrama de precedência com as informações de seqüenciamento correspondentes, a próxima etapa em uma análise de meta-riscos de tempo é estimar o tempo necessário para cada pacote de trabalho individual. Embora seja possível estimar cada tempo como um único ponto de dados, existe uma abordagem melhor, que é fornecer três estimativas: uma otimista, uma pessimista e uma que seja a melhor alternativa.
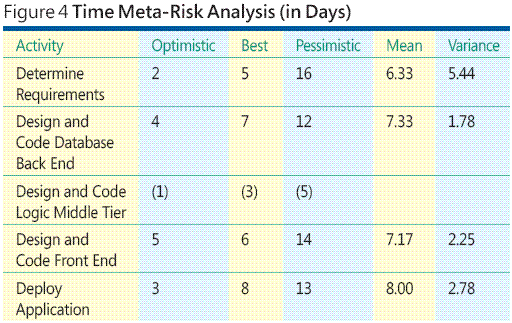
OK, mas de onde vêm tais estimativas? Determinar as estimativas de tempo e de custo é, de longe, a parte mais difícil das análises de meta-riscos de projetos de software. Existem muitas maneiras de estimar o custo e o tempo de atividades, como experiência histórica, palpites, modelos matemáticos sofisticados, etc. As técnicas utilizadas dependerão de cada situação em particular. Seja qual for o método escolhido, estimar o tempo e o custo de um conjunto de atividades menores é muito mais fácil do que de uma atividade monolítica. A tabela na Figura 4 mostra um exemplo de análise de meta-riscos de tempo.
Ao analisar dados de tempo otimistas, pessimistas ou da melhor alternativa, normalmente se usa uma distribuição matemática simples chamada “distribuição Beta”. A média de uma distribuição Beta é computada da seguinte forma:
(optimistic + (4 * best-guess) + pessimistic) / 6
Assim, para a tarefa Implantar Aplicativo, o tempo médio estimado para conclusão é:
mean = (3 + 4*8 + 13) / 6
= 48 / 6
= 8.0 days.
Observe que uma média Beta é simplesmente uma média ponderada com peso 1, 4 e 1. Portanto, a variância de uma distribuição Beta é resultado desta fórmula:
((pessimistic - optimistic)/6)²
Assim, para a tarefa Implantar Aplicativo, a variância é:
variance = ((13 - 3) / 6)²
= (10/6)²
= (1.6667)²
= 2.78 days²
O desvio padrão geral para o projeto é a raiz quadrada da soma das variâncias das atividades. Dessa forma, nesse exemplo, a equação tem a seguinte aparência:
std. deviation = sqrt(5.44 + 1.78 + 2.25 + 2.78)
= sqrt(12.25)
= 3.50 days
Observe que os meus cálculos não usam os dados referentes à atividade Camada Intermediária Lógica de Código e de Design. Como a atividade Camada Intermediária Lógica pode ser executada em paralelo com a atividade Back-end de Banco de Dados, e a atividade Front-end não pode começar enquanto as duas atividades paralelas não tiverem sido concluídas, a atividade paralela menor (Camada Intermediária Lógica) não contribui explicitamente para o tempo geral de conclusão do projeto.
Técnica padrão de gerenciamento de projetos, esse tipo de análise é chamado de método de caminho crítico (CPM). Com os dados de variância e média de cronograma computados, agora você pode computar a probabilidade de que o projeto inteiro leve mais de 30 dias para ser concluído:
z = (30.00 - 28.83) / 3.50 = 0.33
p(0.33) = 0.6293
p(late) = 1.0000 - 0.6293 = 0.3707
Primeiro, você computa o chamado valor z, que é igual ao tempo programado para finalizar o projeto (nesse caso, 30 dias) menos o tempo estimado para conclusão (28,83 dias), dividido pelo desvio padrão total de tarefas (3,50 dias). Em seguida, pega o valor z (0,33) e procura o valor p correspondente em uma tabela chamada Distribuição Normal Padrão ou usa a função NORMSDIST do Excel (0,6293). Finalmente, você subtrai o valor p de 1.0000 para obter a probabilidade de que o prazo do projeto não seja cumprido.
Você está executando uma análise unicaudal aqui porque está preocupado apenas com a possibilidade de o projeto levar mais tempo do que o previsto, e não menos. Com esses dados de exemplo, a probabilidade de que o aplicativo Web leve mais de 30 dias para ser concluído é de 0,3707, ou quase 40% – uma situação um tanto arriscada. Se você pensar nisso por alguns instantes, verá que esse resultado faz sentido. O seu cronograma planejado de 26 dias de desenvolvimento está muito próximo do limite de 30 dias para o projeto e, por isso, talvez você não tenha tempo suficiente para variações de cronograma.
Obviamente, a confiabilidade dos resultados do meta-risco está diretamente relacionada à dos dados de entrada (nesse caso, as estimativas de tempo). Se as suas estimativas de entrada estiverem erradas, nenhuma quantidade de análises estatísticas poderá produzir resultados expressivos. Você pode computar a probabilidade de meta-risco de que o seu projeto ultrapasse o orçamento usando a mesma técnica que acabei de demonstrar para o cronograma. Quando tiver a probabilidade para o não-cumprimento do prazo do projeto, você poderá computar a exposição de risco referente ao meta-risco se conseguir estimar a perda monetária decorrente do atraso.
Nos casos em que tenha sido assinado um contrato para criar um sistema de software, provavelmente as penalidades por atraso devem estar definidas nele. Por exemplo, suponha que o contrato determina uma multa de US$ 10.000,00 por atraso na entrega. Sua exposição de meta-risco é US$ 10.000,00 * 0,3707 = US$ 3.707. Em outras situações, é difícil estimar o custo de um projeto de software atrasado além de um "muito, muito caro".
Mas observe que, mesmo sem computar uma exposição de risco, a análise de meta-riscos gera informações úteis. Se você examinar os dados na Figura 4, verá que a tarefa Determinar Requisitos tem a maior variação de cronograma. Portanto, a simples aplicação de recursos adicionais logo no início do projeto pode diminuir a variação de tarefas, que, por sua vez, reduzirá a probabilidade de não-cumprimento do prazo.
Identificação de riscos
Ao contrário dos meta-riscos de custo e de tempo, nos quais os eventos de risco podem ser determinados de forma gradativa (embora nada fácil) decompondo-se iterativamente tarefas em subtarefas menores, a identificação de riscos costuma ser muito menos mecânica. Em um ambiente de desenvolvimento e teste de software, há três abordagens principais para a identificação de riscos: uma baseada em taxonomia, outra em cenário e uma terceira em especificação.
Uma taxonomia é simplesmente uma lista de classificação. Considere a analogia a seguir. Você vai viajar de avião, por isso usa uma lista de lembretes padrão reservada para antes de cada viagem. A lista contém assertivas ou perguntas como "Estou com minha carteira de identidade?" e "Verifiquei se o vôo está no horário?"
Ao longo dos anos, muitas pessoas e organizações criaram taxonomias de risco de software. Uma dessas listas foi criada por Barry Boehm, pioneiro e conhecido pesquisador na área de risco de projetos de software. Em 1989, Boehm identificou uma taxonomia com 10 principais riscos de software, que foi atualizada por ele em 1995. Esta é a versão de 1995:
- Problemas com pessoal
- Cronogramas, orçamentos, processo
- Software comercial pronto para uso, componentes externos
- Incompatibilidade de requisitos
- Incompatibilidade com a interface do usuário
- Arquitetura, desempenho, qualidade
- Alterações nos requisitos
- Software herdado
- Tarefas executadas externamente
- Ciência da computação exigida além do limite
Você deve ter observado que a lista de Boehm com os 10 principais riscos não identifica imediatamente os riscos. Em vez disso, a taxonomia serve apenas como ponto de partida para você começar a pensar nos riscos que se aplicam ao seu projeto de software. Por exemplo, o primeiro risco, "Problemas com pessoal", abrange vários riscos diferentes que podem estar relacionados a equipe. É possível que o seu projeto simplesmente não tenha engenheiros suficientes para criar o aplicativo ou sistema. Ou talvez um engenheiro importante deixe o projeto no meio do caminho. Ou, quem sabe, a equipe de engenheiros não tem a qualificação técnica necessária para o projeto. E assim por diante.
Você já deve estar familiarizado com a maioria das 10 principais categorias de risco, exceto talvez a décima, "Ciência da computação exigida além do limite". Trata-se de uma categoria abrangente que engloba tarefas relacionadas a itens como análise técnica, análise do custo-benefício e criação de protótipos.
Outra lista de taxonomia de risco de software muito usada é a criada pelo Software Engineering Institute (SEI). O SEI é um dos 36 centros de desenvolvimento e pesquisa financiados pelo Governo dos Estados Unidos. Esses centros são organizações híbridas meio estranhas, porque são financiadas por dinheiro público, mas vendem produtos e serviços. A taxonomia de risco de software do SEI foi criada em 1993 e consiste em aproximadamente 200 perguntas. Por exemplo, a primeira pergunta é "Os requisitos são estáveis? Caso negativo, qual é o efeito no sistema (qualidade, funcionalidade, cronograma, integração, design, teste)?" A pergunta nº 16 é "Como determinar a viabilidade de algoritmos e designs (criação de protótipos, modelagem, análise, simulação)?" A taxonomia de risco de software do SEI pode ser encontrada em um apêndice ao documento.
Na identificação de riscos de software baseada em cenário, você se imagina em diferentes funções, cria cenários para essas funções e identifica o que sairia errado em cada cenário. Usando a analogia da viagem de avião descrita anteriormente, você poderia traçar mentalmente as etapas da sua viagem. Por exemplo, "Primeiro, vou de carro até o aeroporto. Depois, estaciono o carro. Em seguida, faço check-in no balcão da companhia aérea". Esse processo de cenário poderia revelar muitos riscos, como engarrafamentos devido a um acidente ou a manutenção de estradas, falta de vagas no estacionamento, esquecimento da carteira de identidade, etc.
Em um ambiente de projeto de software, algumas funções comuns usadas para a identificação de riscos baseada em cenário são usuários, desenvolvedores, testadores, vendedores, arquitetos de software e gerentes de projeto. Um cenário de usuário poderia ser algo como "Primeiro, instalo o aplicativo. A seguir, inicializo o aplicativo". Em muitos casos, um cenário de identificação de riscos é mapeado diretamente para um caso de teste.
As funções da identificação de riscos baseada em cenário não são necessariamente pessoas. Também podem ser subsistemas ou módulos de software. Por exemplo, suponha que você tem um objeto C# que executa criptografia e descriptografia. Você pode imaginar que o objeto é a função e criar cenários como "Primeiro, aceito uma entrada e crio uma instância de mim mesmo. Em seguida, aceito uma entrada e a passo para o meu método de criptografia". Tem havido menos pesquisas sobre a identificação de riscos de software baseada em cenário do que sobre a identificação baseada em taxonomia. O artigo de pesquisa encontrado em Risk Identification Patterns for Software Projects apresenta uma boa visão geral do campo e propõe uma abordagem teórica, baseada em padrões e interessante para a identificação de riscos.
Além das estratégias de identificação de riscos baseada em cenário e em taxonomia, existe uma terceira abordagem, que é a baseada em especificação. Nela, você examina detalhadamente cada recurso e processo nos documentos de especificação do seu sistema ou produto e tenta identificar o que pode dar errado. Usando a analogia da viagem de avião, você poderia examinar cuidadosamente um itinerário de viagem criado por um agente de viagens. Imagine que um dos seus documentos de especificação de um aplicativo Web declara que você pretende usar um prestador de serviços terceirizado para produzir os diversos arquivos de ajuda para o aplicativo. Uma dependência de projeto externa pode dar origem a uma longa lista de riscos. E se o prestador de serviço não entregar dentro do prazo? E se a qualidade do trabalho dele não atender aos padrões exigidos por você?
Não existe uma estratégia de identificação de riscos ideal, pois cada uma tem prós e contras. As taxonomias de risco são uma maneira excelente de iniciar o processo de identificação dos riscos em seu projeto de software. Elas oferecem uma forma um tanto mecânica de dar início, pois você começa simplesmente examinando cada pergunta ou assertiva na taxonomia. As taxonomias também ajudam a distribuir o processo de identificação de riscos entre várias pessoas atribuindo diferentes perguntas de taxonomia a elas. O lado negativo do uso de taxonomias para identificação de riscos é que elas podem ser demoradas. Além disso, como são genéricas por natureza, não são capazes de identificar riscos específicos do seu sistema de software, a menos que você dedique esforços para descobri-los.
Comparada com a identificação de riscos baseada em taxonomia, uma vantagem da abordagem baseada em cenário é que ela tende a ser menos genérica e força você, desde o início, a ser mais preciso. Por outro lado, como a identificação de riscos baseada em cenário é um pouco mais arte do que ciência, fica fácil perder um cenário importante. A identificação de riscos baseada em especificação normalmente é uma abordagem menos genérica, mais específica. Entretanto, a confiabilidade de seus resultados está diretamente relacionada à dos documentos de especificação. Quando usadas em conjunto, as três abordagens permitem identificar os riscos de software de modo preciso.
Análise de riscos
A análise de riscos é o processo de combinar a probabilidade (ou possibilidade) de um evento de risco com a perda monetária (ou efeito negativo) que ocorrerá se esse evento acontecer, visando produzir um valor que possa ser usado para comparar e priorizar o risco em relação a outros riscos. Nesta seção, apresento duas abordagens mais antigas para análise de riscos (a técnica de valor esperado e a categórica) e uma abordagem nova, chamada PERIL. Vejamos primeiro a técnica de valor esperado.
Dê uma olhada no exemplo mostrado na Figura 5. Suponha que você identificou quatro eventos de risco. Vamos chamá-los de Risco A, Risco B, Risco C e Risco D. Você atribui probabilidades a cada evento de risco. Uma probabilidade é um número entre 0,00 (significando impossível) e 1,00 (significando certeza) que indica o quão provável é o evento. Em seguida, você atribui um valor de perda monetária a cada evento de risco, que é o custo com o qual você terá de arcar caso o evento ocorra. Agora, basta multiplicar a probabilidade e a perda de cada evento de risco para obter a exposição de risco.
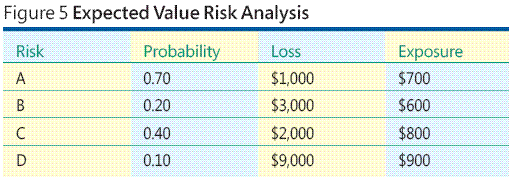
Usando esse método, a exposição de risco é apenas uma forma de valor esperado. Obviamente, há vários problemas importantes com a abordagem de valor esperado. Como estimar probabilidades de risco? Como estimar uma perda de risco? Em algumas situações, é possível que você tenha uma boa experiência ou dados históricos sólidos nos quais basear suas estimativas, mas isso é raro na criação de software. A minha experiência mostra que a abordagem de valor esperado para análise de riscos geralmente não é viável em ambientes de desenvolvimento de software.
Como, em muitos ambientes de desenvolvimento de software, é difícil (ou até impossível) estimar a probabilidade de um evento de risco ou sua perda associada, uma alternativa comum é usar escalas categóricas tanto para perda como para probabilidade de risco. Trata-se da técnica categórica. Um exemplo ajudará a esclarecer melhor. Suponha que você identificou quatro riscos: A, B, C e D. Agora, em vez de adivinhar uma probabilidade e uma perda para cada risco, você gera uma tabela de exposição de risco categórica como a mostrada na parte superior da Figura 6.
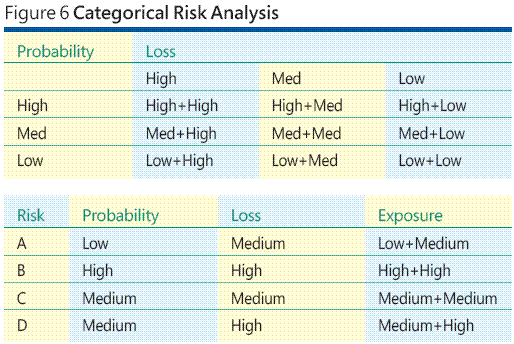
Como você pode ver, tenho um total de nove categorias de exposição de risco. Existem três categorias de probabilidade de risco – Baixa, Média e Alta. E há três categorias de perda – Baixa, Média e Alta.. O produto cruzado das categorias “probabilidade” e “perda” resulta em nove categorias de exposição de risco, desde Baixa-Baixa (baixa probabilidade de uma perda baixa) até Alta-Alta (alta probabilidade de uma perda alta). Agora posso ver cada um dos meus quatro eventos de risco, atribuir uma probabilidade Baixa, Média ou Alta e depois uma perda Baixa, Média ou Alta, produzindo uma exposição de risco de nove pontos. A idéia é que seja mais razoável atribuir um valor de probabilidade de "Baixa" em vez de um valor numérico exato como 0,05, por exemplo.
Os dados hipotéticos na tabela na parte inferior da Figura 6 sugerem que o Risco B tem a maior exposição e poderá justificar mais atenção ou recursos (como teste) do que o Risco A, cuja exposição é menor. Embora uma abordagem de análise de riscos categórica facilite um pouco a questão da atribuição de informações de perda e de probabilidades difíceis ou impossíveis de determinar, a técnica introduz novos problemas.
Observe que, aleatoriamente, usei três categorias tanto para probabilidade como para perda, que é uma abordagem bem grosseira. Mas suponha que decidi aprimorar minha análise de riscos usando cinco categorias para os dois fatores (probabilidade e perda): Muito Baixa, Baixa, Média, Alta e Muito Alta. Eu passaria a ter um total de 25 categorias de exposição de risco, de (Muito Baixa + Muito Baixa) até (Muita Alta + Muita Alta). Como classificar ou comparar esses 25 valores de exposição? Como comparar uma exposição (Muito Baixa + Alta) a uma que seja (Alta + Média)? Se várias pessoas estiverem avaliando seus dados de exposição de risco categórica, elas os interpretarão da mesma forma?
Para resolver os problemas com uma abordagem de análise de riscos puramente categórica, desenvolvi há alguns anos uma técnica que denominei Exposição de Projetos usando PERIL (Possibilidade e Impacto Classificados). A essência da idéia é usar categorias (como na abordagem categórica), mas convertê-las em uma escala quantitativa para que possam ser facilmente combinadas (como na abordagem de valor esperado) para produzir métricas de exposição numéricas.
Vou dar um exemplo. Suponha que você identificou quatro riscos: A, B, C e D. Agora, suponha que você chegue à conclusão de que tentar atribuir valores numéricos significativos à perda e à probabilidade de cada risco é simplesmente inviável. Além disso, você decide que, em seu ambiente, faz sentido categorizar possibilidade de risco em cinco categorias: Muito Baixa, Baixa, Média, Alta e Muito Alta. A seguir, você determina que categorizará perda/impacto em uma escala de quatro pontos: Muito Baixa, Baixa, Alta e Muito Alta. A técnica PERIL mapeia dados categóricos em uma escala quantitativa usando uma construção matemática simples chamada ordem de classificação de centróides. A técnica de mapeamento é mais bem explicada por meio de exemplos. Para uma escala de possibilidade de cinco categorias, meus cinco mapeamentos de ordem de classificação de centróides são mostrados na Figura 7.
Da mesma forma, meus mapeamentos de impacto de quatro categorias são computados, como mostra a Figura 8. Agora, posso combinar o valor de centróide do impacto e da possibilidade de cada risco para computar a exposição do risco por meio de multiplicação. Por exemplo, veja a Figura 9. Nela, o Risco D tem possibilidade Alta, que é mapeada para 0,25667, e impacto Baixo, que é mapeado para 0,14583. Assim, a exposição é 0,25667 * 0,14583 = 0,3743. Desses dados, concluo que o Risco C tem claramente a maior exposição e devo buscar formas de impedir que o risco ocorra e criar um plano de contingência caso isso aconteça.
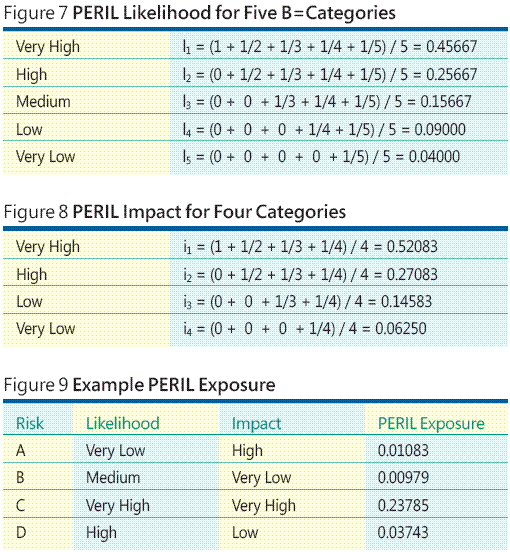
Em vez de computar a exposição de cada risco individualmente, posso construir uma tabela de pesquisa de exposição PERIL completa para cinco níveis de possibilidade e quatro níveis de impacto, e depois simplesmente ler os valores de exposição PERIL na tabela, conforme ilustra a Figura 10. A técnica PERIL é generalizada para qualquer número de categorias de impacto e possibilidade.
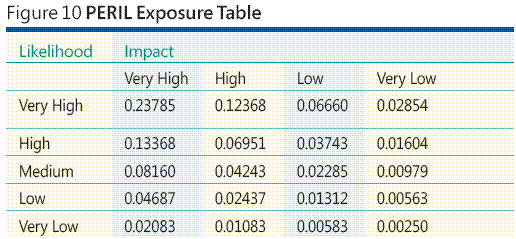
A ordem de classificação de centróides mapeia classificações (como primeiro, segundo, terceiro) para valores numéricos (como 0,61111, 0,27778, 0,11111). Observe que os valores da ordem de classificação de centróides são normalizados, pois somam 1,0 (sujeito a erro de arredondamento). Expresso na notação sigma, se N for o número de categorias, então o valor numérico correspondente à categoria kth é:
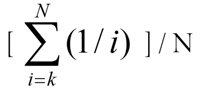
Há muitos outros mapeamentos matemáticos entre categorias e valores numéricos, mas algumas pesquisas sugerem que o uso da ordem de classificação de centróides é uma boa maneira de mapear classificações como as utilizadas na análise de riscos. O escopo desta coluna não inclui uma discussão completa sobre ordem de classificação de centróides, mas considere isso um argumento informal. Suponha que você está lidando com apenas duas categorias de possibilidade de evento de risco: Alta e Baixa. Presumivelmente, a possibilidade de evento de risco Alta tem probabilidade de ocorrer maior que 0,5 e, portanto, a possibilidade de evento de risco Baixa tem uma probabilidade de menos que 0,5. Sem informações adicionais, pode-se supor que a possibilidade de evento Alta é a metade de 0,5 e 1,0 e, portanto, é igual a 0,75. Da mesma forma, a possibilidade de evento Baixa é a metade de 0,0 e 0,5, ou seja, 0,25. Esses dois valores, 0,75 e 0,25, são a ordem de classificação de centróides para N = 2 categorias (como mostra a Figura 11).
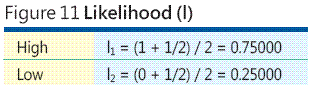
Observe que, ao usar PERIL, eu utilizo os termos “possibilidade” e “impacto” em vez de “probabilidade” e “perda”. O impacto e a possibilidade de PERIL são valores relativos, normalizados. Mesmo que os valores da possibilidade de PERIL somem 1,0 como ocorre em um conjunto de probabilidades, quero enfatizar que eles não são probabilidades. Da mesma forma, os valores do impacto de PERIL não são valores de perda monetária e só têm significado quando comparados entre si.
As três técnicas para determinar exposição de risco – a de valor esperado, a categórica e a PERIL – têm vantagens e desvantagens. Se você tem dados históricos sólidos que permitem estimar as probabilidades de eventos de risco e a perda monetária associada a cada evento, normalmente a melhor abordagem é a técnica de valor esperado. Entretanto, em um ambiente de desenvolvimento e teste de software, é raro ter dados suficientes para fazer estimativas significativas de perda e de probabilidade.
No outro extremo, se você praticamente não tem dados de risco históricos, a técnica categórica, com duas ou três categorias de probabilidade de risco e perda de risco associada, é uma abordagem razoável. Em situações nas quais é possível categorizar a possibilidade de evento de risco e o impacto de risco associado (que pode ser perda monetária ou não-monetária, como danos morais) em aproximadamente cinco categorias, geralmente a técnica PERIL é uma ótima opção.
Seja qual for a técnica de análise de riscos que você decida usar em seu ambiente, deve interpretar os resultados com cuidado. Lembre-se de que a análise de riscos quase sempre tem grandes quantidades de variabilidade nas estimativas de entrada. Em outras palavras, ela fornece orientações – e não regras – para priorizar seus esforços de teste de software.
Recursos de risco
Para obter mais informações sobre risco, consulte estas colunas da MSDN Magazine:
| "Execução de teste: Análise competitiva usando a técnica MAGIQ" |
| "Execução de teste: O processo de hierarquia analítica" |
Conclusão
Uma parte do processo geral de análise de riscos que não abordei nesta coluna é o gerenciamento de risco. Ele envolve atividades como o estabelecimento de um sistema para inserir e armazenar dados de risco e o monitoramento de informações de risco durante o desenrolar do projeto de software. Os sistemas de gerenciamento de risco podem variar desde um sistema informal baseado em email, passando por uma abordagem simples baseada em planilhas do Excel, até uma abordagem sofisticada baseada no uso de Itens de Risco em um sistema Microsoft Team Foundation Server.
É importante compreender que a análise de riscos deve ser um processo contínuo e iterativo, não importa como você decida gerenciar seu esforço de risco. Como o desenvolvimento de projetos de software é uma atividade dinâmica, você deve revisar os resultados e os dados de risco conforme o projeto evolui.
O bom senso sugere que a análise de riscos de software deve fazer parte de todos os projetos de software. Projetos que variam de pequenos esforços de uma semana com um desenvolvedor até projetos enormes de vários anos com centenas ou até milhares de desenvolvedores devem ter alguma forma de análise de riscos. Entretanto, as pesquisas mostram que geralmente as análises de riscos não são realizadas, principalmente em projetos de software pequenos e médios.
Há várias explicações prováveis. Uma razão pode ser o fato de as análises de riscos exigirem técnicas e aptidões que são praticamente o oposto das habilidades e aptidões necessárias para a codificação. Vou explicar. A maioria das atividades de desenvolvimento de software são relativamente bem definidas, baseadas em um sistema fechado, orientadas a pequenos objetivos e geralmente fornecem retorno imediato. Por exemplo, quando você escreve algum código como desenvolvedor, pode obter retorno instantâneo ao compilar e depois executar o código. Se a execução do código for conforme o esperado, normalmente você fica satisfeito. A realização da análise de riscos de software é um tipo de atividade muito diferente. Você não obterá nenhum tipo de retorno ou satisfação aos quais está acostumado.
A questão é que esse tipo de análise difere em muito da codificação. Espero que esta coluna o tenha convencido da importância de realizar a análise de riscos e mostrado algumas técnicas sistemáticas para criar softwares melhores e mais confiáveis.
Envie suas dúvidas e comentários para James pelo email testrun@microsoft.com.
Dr. James McCaffrey trabalha para a Volt Information Sciences Inc., onde gerencia o treinamento técnico para engenheiros de software que trabalham na Microsoft em Redmond, Washington. Ele trabalhou em vários produtos da Microsoft, como o Internet Explorer e o MSN Busca, e é autor do livro .NET Test Automation: A Problem-Solution Approach (Apress, 2006). Entre em contato com James pelos emails jmccaffrey@volt.com ou v-jammc@microsoft.com.