Este artigo foi traduzido por máquina.
Simultaneidade
Otimizando a simultaneidade no ThreadPool do CLR 4.0
Erika Fuentes
O ThreadPool do CLR na versão mais recente (4. 0 do CLR) obteve várias grandes alterações desde que o CLR 2. 0. A mudança recente nas tendências da tecnologia, como, por exemplo, o uso disseminado das arquiteturas de vários núcleos e o desejo resultante de paralelizar aplicativos existentes ou escrever um novo código paralelo, tem sido um dos fatores motivando maiores no aperfeiçoamento do CLR ThreadPool.
Em dezembro de 2008 MSDN Magazine CLR coluna, “ Thread Management no CLR ” (msdn.microsoft.com/magazine/dd252943 de ), eu abordou algumas das motivações e associado a problemas como, por exemplo, o controle de simultaneidade e ruído. Agora, descreverei como nós já endereçada esses no ThreadPool de 4. 0 do CLR, as opções de implementação associada e como elas podem afetar seu comportamento. Além disso, eu me concentrarei a abordagem utilizada em direção ao automatizar o controle de simultaneidade no atual ThreadPool de 4. 0 do CLR (daqui em diante chamado apenas como ThreadPool para conveniência). Eu também fornecerá uma breve descrição da arquitetura do ThreadPool. Este artigo aborda o assunto de detalhes de implementação para mudar em versões futuras. No entanto, os leitores design e criação de novos aplicativos simultâneos que estejam interessados em aprimorar aplicativos antigos, tirando proveito da simultaneidade ou fazer uso das tecnologias asp.net ou extensão paralela (todos no contexto do 4. 0 do CLR), pode ser útil este material compreender e aproveitar as vantagens do comportamento atual do ThreadPool.
Visão geral sobre o ThreadPool
Um pool de segmentos é destinado a fornecer serviços principais como gerenciamento de threads, abstrações para diferentes tipos de simultaneidade e otimização de operações simultâneas. Ao fornecer estes serviços, um pool de segmentos retira alguma carga do usuário para fazê-lo manualmente. Para o usuário inexperiente, é conveniente, não há necessidade de aprender e lidar com os detalhes de um ambiente multithread. Para usuários mais experientes, ter um meio confiável de sistema de threads que ele possa se concentrar no aprimoramento de diferentes aspectos do aplicativo. O ThreadPool fornece esses serviços para aplicativos gerenciados e suporte para a portabilidade entre plataformas, executando determinados aplicativos do Microsoft .NET Framework no Mac OS, por exemplo.
Existem diferentes tipos de simultaneidade pode estar relacionada a várias partes do sistema. São os mais relevantes: Paralelismo de CPU, o paralelismo de e/S;timers e sincronização;e utilização de recurso e o balanceamento de carga. Forneça uma breve Resumimos a arquitetura do ThreadPool em termos de diferentes aspectos de simultaneidade (para obter mais detalhes sobre o arquitetura de ThreadPool e o uso APIs relacionado, consulte “ O CLR do Thread Pool ” (msdn.microsoft.com/magazine/cc164139 ). Especificamente, vale a pena mencionar que há duas implementações independentes do ThreadPool: um lida com paralelismo de CPU e é conhecido como o operador de ThreadPool;a outra lida com paralelismo de e/S e pode ser apelidada de ThreadPool de e/S. A próxima seção se concentrará em paralelismo de CPU e o trabalho de implementação associada no ThreadPool — em especial, sobre as estratégias para a otimização de simultaneidade.
O ThreadPool do trabalho Projetado para fornecer serviços no nível de paralelismo de CPU, o ThreadPool do operador aproveita arquiteturas multi-core. Há dois principais considerações de paralelismo de CPU: expedir o trabalho rapidamente e o desempenho ideal;controle e o grau de paralelismo. Para o anterior, usar ThreadPool torna a implementação de estratégias, tais como filas de liberar o bloqueio para evitar a contenção e roubo de trabalho para o balanceamento de carga, as áreas que estão fora do escopo desta discussão (consulte msdn.microsoft.com/magazine/cc163340 de para obter mais informações sobre esses tópicos). O último — o grau de paralelismo de otimização – envolve o controle de simultaneidade para evitar a contenção de recursos de diminuir a produtividade geral.
Paralelismo de CPU pode ser especialmente difícil porque envolve muitos parâmetros, tais como determinar quantos itens de trabalho podem ser executados simultaneamente em um determinado momento. Outro problema é o número de núcleos e como ajustar para tipos diferentes de cargas de trabalho. Por exemplo, ter um segmento por CPU é melhor (na teoria), mas se a carga de trabalho estiver bloqueando constantemente, em seguida, tempo da CPU é desperdiçado porque mais threads podem ser usadas para executar mais de trabalho. O tamanho e tipo de carga de trabalho é, na verdade, outro parâmetro. Por exemplo, no caso de bloqueio de cargas de trabalho, é extremamente difícil determinar o número de segmentos que otimiza a taxa de transferência geral como é difícil determinar quando uma solicitação for concluída (ou talvez até mesmo a freqüência com que ele chegará — isso está intimamente relacionado ao bloqueio de e/S). A API associada a este ThreadPool é QueueUserWorkItem, que coloca em fila um método (o item de trabalho) para execução (consulte msdn.microsoft.com/library/system.threading.threadpool.queueuserworkitem de ). É recomendável para aplicativos que têm o trabalho que potencialmente pode ser executado em paralelo (com outras coisas). O trabalho é entregue ao ThreadPool, que automaticamente “ descobre ” ao executá-lo. Este recurso se afastar do programador a necessidade de se preocupar sobre como e quando criar threads;No entanto, não é a solução mais eficiente para todos os cenários.
O ThreadPool de e/S Nesta parte da implementação de ThreadPool, relacionada ao paralelismo de e/S lida com cargas de trabalho de bloqueio (ou seja, a solicitações de e/S que levam um tempo relativamente longo ao serviço) ou e/S assíncrona. Em chamadas assíncronas, segmentos não são bloqueados e poderá continuar a fazer outro trabalho enquanto a solicitação é atendida. Este ThreadPool se encarrega de coordenação entre as solicitações e threads. O ThreadPool de e/S – o operador de ThreadPool, como — tem um algoritmo para a otimização de simultaneidade;Ele gerencia o número de segmentos com base na taxa de conclusão das operações assíncronas. Mas esse algoritmo é bastante diferente daquele que o operador de ThreadPool e está fora do escopo deste documento.
Simultaneidade no ThreadPool
Lidar com simultaneidade é uma tarefa difícil, mas é necessária que afeta diretamente o desempenho geral de um sistema. Como o sistema regula simultaneidade diretamente afeta outras tarefas como, por exemplo, sincronização, utilização de recursos e o balanceamento de carga (e vice-versa).
O conceito de controle de simultaneidade “ ” ou mais adequadamente, simultaneidade, a otimização “ ” indica o número de threads que têm permissão para trabalhar em um momento específico no ThreadPool;é uma diretiva para decidir quantos segmentos podem ser executados simultaneamente sem afetando o desempenho. Controle de simultaneidade em nossa discussão é apenas em relação ao operador de ThreadPool. Em oposição a qual pode ser intuitivo, controle de simultaneidade é sobre a otimização e a redução do número de itens de trabalho que podem ser executados em paralelo para melhorar a taxa de transferência de ThreadPool do trabalho (ou seja, controla o grau de simultaneidade está impedindo que trabalho em execução).
O algoritmo de controle de simultaneidade no ThreadPool escolhe automaticamente o nível de simultaneidade;Ela decide para o usuário quantos segmentos são necessários para manter o desempenho geralmente melhor. A implementação desse algoritmo é uma das partes mais interessantes e complexas do ThreadPool. Há diversas abordagens para otimizar o desempenho do ThreadPool no contexto de nível de simultaneidade (em outras palavras, determinar o número de threads em execução ao mesmo tempo “ correto ”). A próxima seção, abordarei algumas dessas abordagens que foram consideradas ou usadas no CLR.
A evolução do controle de simultaneidade no ThreadPool
Uma das abordagens primeira tiradas era otimizar com base na utilização da CPU observada e adição de threads para maximizá-la — em execução como a quantidade de trabalho possível para manter a CPU ocupado. Usando a utilização da CPU como uma métrica é útil ao lidar com cargas de trabalho de longas ou variáveis. No entanto, essa abordagem não era adequada porque os critérios para avaliar a métrica podem ser enganosos. Considere, por exemplo, um aplicativo em que a grande quantidade de paginação de memória está acontecendo. A utilização de CPU observada seria baixa e adicionar mais threads em tal situação resultaria na memória que está sendo usada, que conseqüentemente resulta em menos da CPU. Outro problema nessa abordagem é que, nas situações em que há muita contenção, o tempo da CPU é realmente gasto fazendo a sincronização, não fazendo o trabalho real, portanto, adicionar mais threads apenas tornaria a pior situação.
Outra idéia era simplesmente permitir que o sistema operacional se encarregar de nível de simultaneidade. Na verdade, isso é o que faz o ThreadPool de e/S, mas o operador de ThreadPool exigiu um nível mais alto de abstração para fornecer maior portabilidade e gerenciamento mais eficiente de recursos. Essa abordagem pode funcionar em alguns cenários, mas o programador precisa saber como fazer otimização para evitar sobre saturação dos recursos (por exemplo, se a milhares de threads são criados, contenção de recursos pode se tornar um problema e a adição de threads, na verdade, fazer as coisas piores). Além disso, isso implica que o programador ainda tem se preocupar com simultaneidade, que anula a finalidade de ter um pool de segmentos.
Uma abordagem mais recente foi incluir o conceito de taxa de transferência, medido a conclusão de itens de trabalho por unidade de tempo, como uma medida usada para ajustar o desempenho. Nesse caso, quando a utilização da CPU for baixa, threads são adicionados para ver se isso melhora a taxa de transferência. Em caso afirmativo, são adicionadas mais threads;Se isso não ajudar, threads são removidos. Essa abordagem é mais sensata do que as anteriores porque leva em consideração a quantidade de trabalho está sendo completada, em vez de apenas como os recursos estão sendo usados. Infelizmente, a taxa de transferência é afetada por muitos fatores que não apenas o número de segmentos ativos (por exemplo, tamanho do item de trabalho), que torna difícil ajustar.
Teoria de controle de simultaneidade de otimização
Para superar algumas das limitações das implementações anteriores, idéias de novos foram introduzidas com 4. 0 do CLR. A primeira metodologia considerada na área de teoria do controle, era o algoritmo de alpinismo Hill (HC). Essa técnica é uma abordagem de auto-ajuste com base em um loop de comentários de entrada e saída. A saída do sistema é monitorada e medida em intervalos de tempo pequeno para ver quais efeitos a entrada controlada tinha, e essa informação é alimentada para o algoritmo para ajustar ainda mais a entrada. Olhando para a entrada e saída como variáveis, o sistema é modelado como uma função em termos dessas variáveis. O objetivo é, em seguida otimizar a saída de medida.
No contexto do operador de sistema de ThreadPool, a entrada é o número de segmentos que estão executando o trabalho ao mesmo tempo (ou nível de simultaneidade) e a saída é a taxa de transferência (consulte do Figura 1).

Figura 1 do loop de comentários sobre o ThreadPool
Podemos observar e medir, ao longo do tempo, as alterações na taxa de transferência do resultado da adição ou a remoção de threads, em seguida, decidir adicionar ou remover mais threads com base na degradação da taxa de transferência observado ou melhoria. A Figura 2 ilustra a idéia.

De taxa de transferência modelado como uma função de nível de simultaneidade, a Figura 2
Com a taxa de transferência como uma função (polinomial) de nível de simultaneidade, o algoritmo adiciona threads, até que o máximo da função for atingido (cerca de 20 neste exemplo). Neste ponto, aparecerá uma diminuição na taxa de transferência e o algoritmo irá remover segmentos. Ao longo de cada intervalo de tempo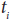 um exemplo de por meio de colocar medidas é feito e “ média ”. Isso é usado para tomar uma decisão para o próximo intervalo de tempo
um exemplo de por meio de colocar medidas é feito e “ média ”. Isso é usado para tomar uma decisão para o próximo intervalo de tempo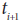 . É compreensível que, se as medições são barulhentas, informações estatísticas não o representante da situação real, a menos que talvez é realizada através de um grande intervalo de tempo. É difícil dizer se uma melhoria era um resultado da alteração no nível de simultaneidade ou devido a um outro fator como flutuações de carga de trabalho.
. É compreensível que, se as medições são barulhentas, informações estatísticas não o representante da situação real, a menos que talvez é realizada através de um grande intervalo de tempo. É difícil dizer se uma melhoria era um resultado da alteração no nível de simultaneidade ou devido a um outro fator como flutuações de carga de trabalho.
Abordagens adaptáveis em sistemas reais são complicadas;no nosso caso seu uso foi especialmente problemático devido a dificuldade de detecção de pequenas variações ou extraindo as alterações de um ambiente muito barulhento através de um curto período de tempo. O primeiro problema observado com essa abordagem é que a função modelada (veja a tendência de preta em do Figura 2) não é um destino estático em situações do mundo real (consulte azul pontos também no gráfico), portanto, medir pequenas alterações é difícil. O seguinte problema, talvez mais relacionadas, é que o ruído (variações em medidas causadas pelo ambiente do sistema, como determinada atividade do sistema operacional, coleta de lixo e muito mais) torna difícil dizer se há uma relação entre a entrada e saída, ou seja, para saber se a taxa de transferência não é apenas uma função do número de threads. Na verdade, no ThreadPool, a taxa de transferência constitui apenas uma parte pequena de que a saída real observada é — a maioria delas é ruído. Por exemplo, se um aplicativo cuja carga de trabalho usa vários threads. Adicionando apenas algumas mais não fará diferença na saída;uma melhoria observada em um intervalo de tempo, mesmo não pode estar relacionada a alterações no nível de simultaneidade (ajuda 3 Figura ilustrar este problema).


Do exemplo de ruído no ThreadPool, a Figura 3
Figura 3 , no eixo x é o horário;no eixo y, as medidas de nível de taxa de transferência e a simultaneidade são over-imposed. O gráfico superior mostra que algumas cargas de trabalho, mesmo se o número de threads (vermelhos) é mantida constante, lá podem ser observadas alterações na taxa de transferência (azul). Neste exemplo, as flutuações são ruído. O gráfico inferior é outro exemplo de onde o geral aumento na taxa de transferência é observado ao longo do tempo na presença de ruído. No entanto, o número de segmentos foi mantido constante para que o aprimoramento na taxa de transferência é devido a um parâmetro diferente do sistema.
A próxima seção, abordarei uma abordagem para lidar com ruído.
Colocar no processamento de sinal
Processamento de sinal é usado em muitas áreas de engenharia para reduzir o ruído os sinais;a idéia é a localização padrão do sinal de entrada no sinal de saída. Essa teoria pode ser aplicada no contexto do ThreadPool se nós considerado (nível de simultaneidade) de entrada e saída (taxa de transferência) do algoritmo de controle de simultaneidade de sinais. Se nós de entrada de um nível de simultaneidade intencionalmente modificado como “ onda ” com período conhecido e a amplitude e procure esse padrão de som tipo wave originais na saída, pode distinguir o que é o ruído do efeito real de entrada sobre a taxa de transferência. Figura 4 ilustra essa idéia.

De Determinando fatores de saída de ThreadPool, a Figura 4
Considere, por alguns instantes, o sistema como uma caixa-preta que gera a saída fornecida uma entrada. Figura 4 mostra um exemplo simplificado de entrada de HC e saída (verde);abaixo, que é um exemplo de como a entrada e saída ficaria como ondas usando uma técnica de filtragem (preta).
Em vez de alimentar a bemol, constante de entrada, apresenta um sinal e, em seguida, tente localizá-lo na saída com ruídos. Esse efeito pode ser obtido por meio de técnicas como, por exemplo, passar de banda de correspondência de filtro, geralmente usado para extração de ondas de outras ondas ou encontrar sinais muito específicos na saída ou. Isso também significa que, introduzindo alterações à entrada, o algoritmo é tomada de decisões em todos os pontos com base na última parte pequena da entrada de dados.
O algoritmo específico usado no ThreadPool usa uma transformação de Fourier discreta, uma metodologia que fornece informações sobre como a magnitude e a fase de uma onda. Essas informações, em seguida, podem ser usadas para verificar se e como a entrada afetado a saída. O gráfico no do Figura 5 mostra um exemplo do comportamento do ThreadPool usando essa metodologia, uma carga de trabalho que executam mais de 600 segundos.

De medição como entrada afeta a saída, a Figura 5
No exemplo de Figura 5, o padrão conhecido de onda de entrada (fase, freqüência e amplitude) pode ser rastreado na saída. O gráfico ilustra o comportamento do algoritmo de simultaneidade, uso da filtragem em uma carga de trabalho de exemplo. A tendência de vermelha corresponde à entrada e o azul corresponde à saída. Nós variar a contagem de thread de cima para baixo ao longo do tempo, mas isso não significa que podemos criar ou destruir threads;Podemos mantê-los ao redor.
Embora a escala do número de segmentos é diferente do que a taxa de transferência, podemos ver como é possível mapear como a entrada afeta a saída. O número de segmentos é alterado constantemente pelo menos um em uma fatia de tempo , mas isso não significa que um thread está sendo criado ou destruído. Em vez disso, são mantidos “ alive ” threads no pool, mas eles não estiverem ativamente fazendo o trabalho.
Em oposição à abordagem inicial usando HC, no qual o objetivo era modelar a curva de taxa de transferência e a decisão sobre que tipo de cálculo de base, a metodologia de melhor apenas determina se ou não uma alteração na entrada ajudou a melhorar a saída. Intuitivamente, há uma confiança maior do que as alterações que apresentamos artificialmente estão tendo efeito observado na saída (o número máximo de segmentos observado até o momento ser introduzido no sinal é 20, o que é bastante razoável — especialmente em cenários que possuem muitos threads). Uma das desvantagens da abordagem que usa o processamento de sinal é que devido ao padrão de som tipo wave artificial introduzido, o nível de simultaneidade ideal sempre será desativado pelo menos um segmento. Além disso, os ajustes para o nível de simultaneidade acontecem relativamente devagar (algoritmos mais rápidos baseados em métricas de utilização da CPU) porque é necessário reunir dados suficientes para tornar o modelo estável. E a velocidade dependerá do tamanho dos itens de trabalho.
Essa abordagem não é perfeita e funciona melhor para algumas cargas de de trabalho que outras pessoas;No entanto, é consideravelmente melhor do que as metodologias anteriores. Os tipos de cargas de trabalho para o qual nosso algoritmo funciona melhor são aqueles com itens de trabalho individuais relativamente curto, pois quanto menor for o item de trabalho, o algoritmo mais rápido é permitido para adaptar-se. Por exemplo, ele funciona muito bem com as durações de item de trabalho menos de 250ms, mas é melhor quando as durações são menos de 10 ms.
Gerenciamento de simultaneidade, vai faça por você
Quebra automática de, o ThreadPool fornece serviços que ajudam a concentrar-se em coisas diferentes de gerenciamento de simultaneidade programador. Para fornecer essa funcionalidade, a implementação de ThreadPool incorporou algoritmos de engenharia de high-end que podem automatizar muitas decisões para o usuário. Um exemplo é o simultaneidade controle algoritmo, que evoluiu baseado na tecnologia e as necessidades expressas em diferentes cenários, tais como a necessidade de medir o progresso útil de execução do trabalho.
A finalidade do algoritmo de controle de simultaneidade em 4. 0 do CLR é automaticamente decidir quantos itens de trabalho podem ser executados simultaneamente, de maneira eficiente, assim como otimizar a taxa de transferência do ThreadPool. Esse algoritmo é difícil ajustar por causa de ruído e parâmetros como, por exemplo, o tipo de carga de trabalho;Ele depende também a suposição de que cada item de trabalho é uma parte do trabalho útil. O design atual e o comportamento tem foi intensamente influenciada pelos cenários do asp.net e o Parallel Framework, para os quais ele tem um bom desempenho. Em geral, o ThreadPool pode fazer um bom trabalho ao executar o trabalho com eficiência. No entanto, o usuário deve estar ciente de que há pode ser um comportamento inesperado para algumas cargas de trabalho, ou se, por exemplo, existem vários ThreadPools executando ao mesmo tempo.
Erika Fuentes, Ph.d. é um engenheiro de desenvolvimento de software em teste na equipe do CLR, onde trabalha na equipe de desempenho com foco específico na área do sistema operacional principal no encadeamento. Ela escreveu diversas publicações acadêmicas sobre computação científica, sistemas adaptativos e estatísticas.
Graças aos seguintes especialistas técnicos para revisão deste artigo: Eric Eilebrecht e do Aziz do Mohamed Abd El