Este artigo foi traduzido por máquina.
Windows Azure Insider
Hadoop e HDInsight: Grandes volumes de dados no Windows Azure
Bruno Terkaly
Ricardo Villalobos
 Vamos começar com uma afirmação ousada: "Se você, sua inicialização ou a empresa que você trabalha para não salvar enormes quantidades de dados para o disco para análise atual e futura, você está comprometendo sua eficácia como um líder técnico." Não é tolo para basear as decisões de negócios importantes em instinto dados sozinho, ao invés de real quantitativa de intestino?
Vamos começar com uma afirmação ousada: "Se você, sua inicialização ou a empresa que você trabalha para não salvar enormes quantidades de dados para o disco para análise atual e futura, você está comprometendo sua eficácia como um líder técnico." Não é tolo para basear as decisões de negócios importantes em instinto dados sozinho, ao invés de real quantitativa de intestino?
Há muitas razões por que o grande volume de dados é tão penetrante. Em primeiro lugar, é incrivelmente barato para coletar e armazenar dados em qualquer formulário, estruturados ou não, especialmente com a ajuda de produtos tais como o Windows Azure Storage services. Em segundo lugar, que é econômico alavancar a nuvem para fornecer o poder de computação necessário — rodando em hardware commodity — para analisar esses dados. Finalmente, o grande volume de dados muito bem fornece uma grande vantagem competitiva para as empresas porque é possível extrair informações desconhecidas de vastas quantidades de dados não-estruturados. O objetivo do artigo deste mês é mostrar como você pode aproveitar a plataforma Windows Azure — em particular, o serviço de HDInsight do Windows Azure — para solucionar os desafios de grande volume de dados.
Passa mal um dia sem algum história estaríamos na imprensa IT — e às vezes até mesmo na mídia — sobre o grande volume de dados. Grande volume de dados refere-se simplesmente a conjuntos de dados tão grandes e complexo que são difíceis de processo usando técnicas tradicionais, tais como cubos de dados, tabelas relacionais de normalizado e extrato baseados em lote, transformação e carregamento de motores (ETL), para citar alguns. Defensores falam sobre extração de negócios e inteligência científica de petabytes de dados não estruturados podem se originar de uma variedade de fontes: sensores, logs da Web, dispositivos móveis e a Internet das coisas ou muito (tecnologias baseadas em identificação por rádio freqüência [RFID], tais como a comunicação de campo próximo, códigos de barras, códigos de resposta rápida [QR] e watermarking digital). Muito altera a definição de grande — estamos falando agora de exabytes de dados por dia!
Grande volume de dados jus a todo o hype? Microsoft considera definitivamente faz e tem grande aposta em grande volume de dados. Em primeiro lugar, grandes dados leva a melhor estratégias de marketing, substituindo a decisão baseada no intestino fazendo com o analytics com base no comportamento do consumidor real. Em segundo lugar, os líderes empresariais podem melhorar decisões estratégicas, como a adição de um novo recurso para uma aplicação ou Web site, porque eles podem estudar os dados de telemetria e uso de aplicações rodando em uma multiplicidade de dispositivos. Em terceiro lugar, ajuda serviços financeiros detectar fraudes e avaliar o risco. Finalmente, embora você não pode realizá-lo, é tecnologias de grande volume de dados que normalmente são usadas para construir os motores de recomendação (acho Netflix). Recomendações são muitas vezes oferecidas como um serviço na Web ou dentro de grandes empresas para agilizar decisões de negócios. As empresas realmente inteligentes estão coletando dados de hoje sem nem saber que tipo de perguntas que eles vão pedir os dados de amanhã.
Grande volume de dados realmente significa a análise de dados, que estêve ao redor por muito tempo. Embora sempre tenha havido armazenamentos de dados enorme, sendo extraídos para a inteligência, o que diferencia o mundo de hoje é a enorme variedade de principalmente dados não-estruturados. Felizmente, produtos como o Windows Azure trazem grande economia, permitindo que qualquer pessoa ampliar seu poder de computação e aplicá-lo a grandes quantidades de armazenamento, tudo no mesmo datacenter. Cientistas dados descrevem o novo fenómeno de dados como os três Vs — velocidade, volume e variedade. Nunca dados foi criados com tal velocidade, tamanho e a falta de uma estrutura definida.
O mundo de grande volume de dados contém um ecossistema grande e vibrante, mas um projeto open source Reina acima-los todos e esse é o Hadoop. Hadoop é o padrão de facto para processamento de dados distribuídos. Você encontrará uma excelente introdução à Hadoop no bit.ly/PPGvDP: "Hadoop fornece um quadro de MapReduce para escrever aplicativos que processam grandes quantidades de dados estruturados e semi-estruturados em paralelo através de grandes conjuntos de máquinas de uma forma muito confiável e tolerante." Além disso, como você aprende mais sobre este espaço, você provavelmente vai concordar com a perspectiva de Matt Winkler (principal PM em HDInsight) que o Hadoop é "um ecossistema dos projetos relacionados no topo do armazenamento de núcleo distribuído e MapReduce framework." Paco Nathan, diretor da ciência de dados em simultâneo e um committer do projeto de código aberto em cascata (cascading.org), diz mais, "as camadas de abstração habilitar pessoas alavancar Hadoop em escala sem conhecer os fundamentos."
O modelo de MapReduce
MapReduce é o modelo de programação usado para processar grandes conjuntos de dados; essencialmente é a "linguagem assembly" para Hadoop, para que compreender o que ele faz é crucial para a compreensão Hadoop. MapReduce algoritmos são escritos em Java e divide o conjunto de dados de entrada em pedaços independentes que são processados pelas tarefas do mapa de forma completamente paralela. O quadro classifica a saída dos mapas, que são em seguida entrada para as tarefas de reduzir. Normalmente, a entrada e a saída do trabalho são armazenados em um sistema de arquivos. Cuida-se o quadro de agendamento de tarefas, controlando-os e re-executar tarefas de falhadas.
Em última análise, a maioria dos desenvolvedores não autoria de baixo nível de código Java para MapReduce. Em vez disso, vai usar ferramentas avançadas que abstrai a complexidade de MapReduce, tais como a colméia ou porco. Para obter uma apreciação dessa abstração, vamos dar uma olhada de baixo nível Java MapReduce e em como o mecanismo de consulta de colméia de alto nível, que oferece suporte a HDInsight, torna o trabalho muito mais fácil.
Por que HDInsight?
HDInsight é uma implementação do Apache Hadoop que é executado em datacenters da Microsoft distribuídos globalmente. É um serviço que permite que você facilmente criar um cluster de Hadoop em minutos quando você precisar dele e derrubá-lo depois de executar seus trabalhos de MapReduce. Como o Windows Azure Insiders, acreditamos que há algumas proposições de valor da chave de HDInsight. O primeiro é que é 100% baseado em Apache, não uma versão especial de Microsoft, significando que à medida que evolui Hadoop, Microsoft vai abraçar as versões mais recentes. Além disso, a Microsoft é dos principais contribuintes para o projeto Hadoop/Apache e forneceu uma grande quantidade de seu know-how otimização de consulta para as ferramentas de consulta, a colméia.
O segundo aspecto da HDInsight que é interessante é que ele funciona perfeitamente com Windows Azure Blobs, mecanismos para armazenar grandes quantidades de dados não estruturados que podem ser acessados de qualquer lugar do mundo via HTTP ou HTTPS. HDInsight também torna possível persistir os meta-dados de definições de tabela no SQL Server , para que quando o cluster é desligado, você não tem que re-criar seus modelos de dados do zero.
Figura 1 retrata a amplitude e a profundidade do Hadoop suporte na plataforma Windows Azure.
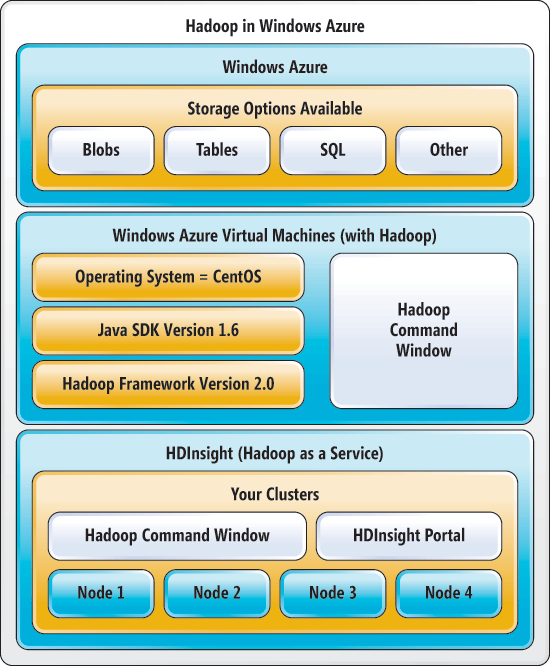
Figura 1 Hadoop ecossistema no Windows Azure
No topo é o sistema de armazenamento do Windows Azure, que fornece armazenamento seguro e confiável e inclui built-in geo-replicação para redundância de dados em todas as regiões. Windows Azure Storage inclui uma variedade de mecanismos de armazenamento flexível e poderoso, como tabelas (uma NoSQL, keyvalue loja), banco de dados SQL, Blobs e muito mais. Ele suporta um resto-ful API que permite que qualquer cliente executar criar, ler, atualizar, excluir (CRUD) operações em dados de texto ou binário, como vídeo, áudio e imagens. Isto significa que qualquer cliente HTTP compatível pode interagir com o sistema de armazenamento. Hadoop interage diretamente com Blobs, mas que não limitam sua capacidade de alavancar outros mecanismos de armazenamento dentro do seu próprio código.
A segunda área chave é o suporte de Windows Azure para máquinas virtuais (VMs), rodando Linux. Hadoop roda em cima do Linux e utiliza o Java, que torna possível configurar seu próprio cluster Hadoop nó único ou vários nó. Isso pode ser uma poupança de dinheiro enorme e impulsionador da produtividade, porque um único VM no Windows Azure é muito econômico. Você pode construir seu próprio cluster de vários nó à mão, mas não é trivial e não é necessário quando você está tentando validar alguns algoritmos básicos.
Criação de seu próprio cluster Hadoop torna mais fácil para começar a aprender e desenvolver aplicativos Hadoop. Além disso, se executar a instalação fornece insights valiosos sobre o funcionamento interno de um trabalho de Hadoop. Se você quer saber como fazer isso, consulte o blog post, "como para instalar Hadoop em um Linux-Based Windows Azure máquina Virtual," a bit.ly/1am85mU.
Claro, uma vez que você precisar de um aglomerado maior, você vai querer tirar proveito de HDInsight, que está disponível hoje no modo de visualização. Para começar, vá para o portal do Windows Azure (bit.ly/12jt5KW) e Cadastre-se. Em seguida, selecione serviços de dados | HDInsight | Crie rapidamente. Você será solicitado para um nome de cluster, o número de computação nós (atualmente quatro a 32 nós) e o armazenamento de conta ao qual deseja ligar. A localização da sua conta de armazenamento determina a localização do seu cluster. Finalmente, clique em criar HDINSIGHT CLUSTER. Levará de 10 a 15 minutos para configurar o cluster. O tempo que demora a prestação não está relacionado com o tamanho do cluster.
Note que você também pode criar e gerenciar um cluster HDInsight programaticamente usando o Windows PowerShell, bem como através da cruz-plataforma em Linux e Mac-baseado sistemas de ferramental. Grande parte da funcionalidade na interface de linha de comando (CLI) também está disponível em um portal de gerenciamento fácil de usar que permite que você gerencie o cluster, incluindo a execução e a gestão de postos de trabalho no cluster. Você pode baixar o Windows Azure PowerShell, bem como as CLIs para Mac e Linux em bit.ly/ZueX9Z. Em seguida, configure sua VM rodando CentOS (uma versão do Linux), juntamente com o Java SDK e Hadoop.
Explorando o Hadoop
Para experimentar com Hadoop e aprender sobre o seu poder, decidimos aproveitar os dados publicamente disponíveis de data.sfgov.org. Especificamente, baixamos um arquivo contendo dados de criminalidade de San Francisco durante os três meses anteriores e usado como está. O arquivo inclui mais de 33.000 registros (relativamente pequeno por padrões de grande volume de dados), derivados do sistema de relatórios de incidente de Crime SFPD. Nosso objetivo era realizar algumas análises simples, como calcular o número e tipo de incidentes de crime. Figura 2 mostra parte da saída do trabalho Hadoop que resumiu os dados do crime.
Figura 2 Crime dados resumidos pelo tipo
| Roubo de automóvel fechado | 2617 |
| Comportamento pernicioso | 1623 |
| Carteira de motorista | 1230 |
| Caso objecto de auxílio | 1195 |
| Achados e perdidos | 1083 |
O código em Figura 3 resume os três meses de crimes. O arquivo de entrada continha mais de 30.000 linhas de dados, enquanto a saída continha apenas 1.000 registros. O top cinco desses 1.000 discos são mostrados em Figura 2.
Figura 3 o código de Java de MapReduce que resume os dados do Crime
// CrimeCount.java
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.conf.*;
import org.apache.hadoop.io.*;
import org.apache.hadoop.mapred.*;
import org.apache.hadoop.util.*;
// This code is based on the standard word count examples
// you can find almost everywhere.
// We modify the map function to be able to aggregate based on
// crime type.
// The reduce function as well as main is unchanged,
// except for the name of the job.
public class CrimeCount {
public static class Map extends MapReduceBase implements
Mapper<LongWritable, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
private String mytoken = null;
public void map(LongWritable key, Text value,
OutputCollector<Text, IntWritable> output,
Reporter reporter) throws IOException {
// Read one line from the input file.
String line = value.toString();
// Parse the line into separate columns.
String[] myarray = line.split(",");
// Verify that there are at least three columns.
if(myarray.length >= 2){
// Grab the third column and increment that
// crime (i.e.
LOST PROPERTY found, so add 1).
mytoken = myarray[2];
word.set(mytoken);
// Add the key/value pair to the output.
output.collect(word, one);
}
}
// A fairly generic implementation of reduce.
public static class Reduce extends MapReduceBase implements Reducer<Text,
IntWritable, Text, IntWritable> {
public void reduce(Text key, Iterator<IntWritable> values,
OutputCollector<Text,
IntWritable> output,
Reporter reporter) throws IOException {
// Loop through an aggregate key/value pairs.
int sum = 0;
while (values.hasNext()) {
sum += values.
next().get();
}
output.collect(key, new IntWritable(sum));
}
}
// Kick off the MapReduce job, specifying the map and reduce
// construct, as well as input and output parameters.
public static void main(String[] args) throws Exception {
JobConf conf = new JobConf(CrimeCount.class);
conf.setJobName("crimecount");
conf.setOutputKeyClass(Text.class);
conf.setOutputValueClass(IntWritable.class);
conf.setMapperClass(Map.class);
conf.setCombinerClass(Reduce.class);
conf.setReducerClass(Reduce.class);
conf.setInputFormat(TextInputFormat.class);
conf.setOutputFormat(TextOutputFormat.class);
FileInputFormat.setInputPaths(conf, new Path(args[0]));
FileOutputFormat.setOutputPath(conf, new Path(args[1]));
JobClient.runJob(conf);
}
}
Uma vez que você salvar o código no Figura 3 como CrimeCount.java, você precisa compilar, empacotar e enviar o trabalho Hadoop. Figura 4 contém as instruções para copiar o arquivo de dados de entrada do crime para o Hadoop distribuídos arquivo System (HDFS); compilação CrimeCount.java; Criando o arquivo de crimecount.jar; executando o trabalho de Hadoop (usando crimecount.jar); e exibir os resultados — ou seja, os dados de saída. Para baixar o código-fonte inteiro, vá para sdrv.ms/16kKJKh e com o botão direito na pasta CrimeCount.
Figura 4 Compilando, embalagem e executando o trabalho Hadoop
# Make a folder for the input file.
hadoop fs -mkdir /tmp/hadoopjob/crimecount/input
# Copy the data file into the folder.
hadoop fs -put SFPD_Incidents.csv /tmp/hadoopjob/crimecount/input
# Create a folder for the Java output classes.
mkdir crimecount_classes
# Compile the Java source code.
javac -classpath /usr/lib/hadoop/hadoop-common-2.0.0-cdh4.3.0.jar:/usr/lib/hadoop-0.20-mapreduce/hadoop-core-2.0.0-mr1-cdh4.3.0.jar -d crimecount_classes CrimeCount.java
# Create a jar file from the compiled Java code.
jar -cvf crimecount.jar -C crimecount_classes/ .
# Submit the jar file as a Hadoop job, passing in class path as well as
# the input folder and output folder.
# *NOTE* HDInsight users can use \"asv:///SFPD_Incidents.csv,\" instead of
# \"/tmp/hadoopjob/crimecount/input\" if they uploaded the input file
# (SFPD_Incidents.csv) to Windows Azure Storage.
hadoop jar crimecount.jar org.myorg.CrimeCount /tmp/hadoopjob/crimecount/input /tmp/hadoopjob/crimecount/output
# Display the output (the results) from the output folder.
hadoop fs -cat /tmp/hadoopjob/crimecount/output/part-00000
Agora você tem uma idéia das peças que compõem um ambiente mínimo do Hadoop, bem como o código MapReduce Java parece e como ele acaba sendo apresentada como um trabalho de Hadoop na linha de comando. As chances são, em algum momento que você vai querer aumento da rotação um cluster para executar alguns trabalhos grandes e, em seguida, fechado para baixo, usando ferramentas de alto nível como colméia ou porco e isto é o que HDInsight se trata porque torna tudo mais fácil, com suporte interno para porco e colméia.
Depois que o cluster é criado, você pode trabalhar no prompt de comando do Hadoop, ou você pode usar o portal para emitir consultas de colméia e porco. A vantagem dessas consultas é que você nunca tem que mergulhar em Java e modificar funções de MapReduce, executar a compilação e empacotamento ou chutar o Hadoop trabalho com o arquivo. jar. Embora você possa remoto em para o nó principal do cluster Hadoop e executar essas tarefas (escrever código Java , compilando o código Java , embalá-lo como um arquivo. jar e usando o arquivo. jar para executá-lo como um trabalho Hadoop), esta não é a abordagem ideal para a maioria dos usuários do Hadoop — é também de baixo nível.
A maneira mais produtiva para executar trabalhos de MapReduce é alavancar o portal do Windows Azure em HDInsight e emitir consultas de colméia, supondo-se que usando o porco é tecnicamente menos apropriado. Você pode pensar da colméia como ferramentas de nível superior que abstrai a complexidade da escrita MapReduce funções em Java. É realmente nada mais do que um SQL-como linguagem de scripting. Consultas escritas na colméia se compilado em Java MapReduce funções. Além disso, porque a Microsoft contribuiu com porções significativas de código de otimização para colméia no projeto Apache Hadoop, as chances são que consultas escritas na colméia serão melhor otimizadas e execute mais eficientemente do que código artesanal em Java. Você pode encontrar um excelente tutorial em bit.ly/Wzlfbf.
Todo o código Java e script que apresentamos anteriormente pode ser substituído com a pequena quantidade de código em Figura 5. É notáveis como três linhas de código no Hive eficientemente podem alcançar os resultados de igual ou melhores do que o código anterior.
Figura 5 colméia consulta código para executar o MapReduce
# Hive does a remarkable job of representing native Hadoop data stores
# as relational tables so you can issue SQL-like statements.
# Create a pseudo-table for data loading and querying
CREATE TABLE sfpdcrime(
IncidntNum string,
Category string,
Descript string,
DayOfWeek string,
CrimeDate string,
CrimeTime string,
PdDistrict string,
Resolution string,
Address string,
X string,
Y string,
CrimeLocation string) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',';
# Load data into table.
LOAD DATA INPATH 'asv://sanfrancrime@brunoterkaly.blob.core.windows.
net/SFPD_Incidents.csv' OVERWRITE INTO TABLE sfpdcrime;
select count(*) from sfpdcrime;
# Ad hoc query to aggregate and summarize crime types.
SELECT Descript, COUNT(*) AS cnt FROM sfpdcrime GROUP BY Descript
order by cnt desc;
Existem alguns pontos importantes a observar sobre Figura 5. Primeiro, observe que esses comandos parecem familiares instruções SQL, permitindo que você crie estruturas de tabela na qual você pode carregar os dados. O que é particularmente interessante é o carregamento de dados de serviços do Windows Azure Storage. Observe o prefixo asv na instrução de carga em Figura 5. ASV defende Azure Storage Vault, que você pode usar como um mecanismo de armazenamento para fornecer dados de entrada para Hadoop empregos. Como você pode recordar, enquanto o processo de um cluster de HDInsight, de provisionamento você especificou uma ou mais contas de serviço específicas do Windows Azure Storage. A capacidade de utilizar os serviços do Windows Azure Storage em HDInsight dramaticamente melhora a usabilidade e a eficiência da gestão e execução de trabalhos de Hadoop.
Nós apenas arranhamos a superfície neste artigo. Há uma quantidade significativa de ferramentas sofisticadas que suporta e estende-se HDInsight e uma variedade de outros projetos de código aberto, você pode aprender sobre o portal do Apache Hadoop (hadoop.apache.org). As próximas etapas devem incluir assistindo o canal 9 vídeo "faça seu Apps mais esperto com Azure HDInsight" em bit.ly/19OVzfr. Se seu objetivo é manter-se competitivo por tomar decisões baseadas em análises e dados reais, o HDInsight está aqui para ajudar.
O ecossistema Hadoop
Uma vez que você deixar o mundo de baixo nível da escrita MapReduce empregos em Java, você vai descobrir um incrível, altamente evoluído ecossistema de ferramentas que grandemente estende os recursos do Hadoop. Por exemplo, Cloudera e Hortonworks são bem sucedidas empresas com modelos de negócio baseados em produtos Hadoop, educação e serviços de consultoria. Muitos projetos open source fornecem recursos adicionais, tais como máquina de aprendizagem (ML); Mecanismos de consulta do tipo SQL que oferecem suporte a sumarização de dados e consultas ad hoc (colméia); dados -fluxo de suporte de idioma (porco); e muito mais. Aqui estão apenas alguns dos projetos que valem a pena uma olhada: Sqoop, porco, Apache Mahout, em cascata e Oozie. Microsoft oferece uma variedade de ferramentas, como o Excel com PowerPivot, exibição de poder e ODBC drivers que tornam possível para aplicativos do Windows para emitir consultas em relação a dados de colméia. Visite bit.ly/WIeBeq para ver um visual fascinante do ecossistema Hadoop.
Bruno Terkaly é desenvolvedor e divulgador da Microsoft. Seu profundo conhecimento é fruto de anos de experiência no campo, escrevendo código para uma grande quantidade de plataformas, linguagens, estruturas, SDKs, bibliotecas e APIs. Ele passa seu tempo escrevendo código, escrevendo blogs e fazendo apresentações ao vivo sobre como criar aplicativos baseados na nuvem, especificamente usando a plataforma Windows Azure. Você pode ler seu blog em blogs.msdn.com/b/brunoterkaly.
Ricardo Villalobos is a seasoned software architect with more than 15 years of experience designing and creating applications for companies in the supply chain management industry. Segurando diferentes certificações técnicas, bem como um mestrado em Administração pela Universidade de Dallas, trabalha como arquiteto no grupo de incubação Windows Azure CSV de nuvem da Microsoft. Você pode ler seu blog em blog.ricardovillalobos.com.
Terkaly e Villalobos conjuntamente apresentar conferências da indústria em geral. Eles encorajam os leitores do Windows Azure Insider contatá-los para disponibilidade. Terkaly pode ser contatado em bterkaly@microsoft.com e Villalobos pode ser contatado em Ricardo.Villalobos@microsoft.com.
Agradecemos aos seguintes especialistas técnicos pela revisão deste artigo: Paco Nathan (simultâneas Inc.) e Matt Winkler (Microsoft)