Usar o DISKSPD para testar o desempenho de armazenamento da carga de trabalho
Aplica-se a: Azure Stack HCI, versões 22H2 e 21H2; Windows Server 2022, Windows Server 2019
Este tópico fornece diretrizes sobre como usar DISKSPD para testar o desempenho do armazenamento de carga de trabalho. Você tem uma configuração de cluster do Azure Stack HCI, tudo pronto para uso. Ótimo, mas como você sabe se está obtendo as métricas de desempenho prometidas, se é latência, taxa de transferência ou IOPS? Isso ocorre quando você quer voltar para o DISKSPD. Depois de ler este tópico, você saberá como executar DISKSPD, entender um subconjunto de parâmetros, interpretar a saída e obter uma compreensão geral das variáveis que afetam o desempenho do armazenamento de carga de trabalho.
O que é DISKSPD?
DISKSPD é uma ferramenta de linha de comando de geração de E/S para micro-benchmarking. Ótimo, então o que todos esses termos significam? Qualquer pessoa que configure um cluster do Azure Stack HCI ou um servidor físico tem um motivo. Pode ser configurar um ambiente de hospedagem na Web ou executar áreas de trabalho virtuais para funcionários. Seja qual for o caso de uso do mundo real, você provavelmente deseja simular um teste antes de implantar seu aplicativo real. No entanto, testar seu aplicativo em um cenário real geralmente é difícil – é aí que o DISKSPD entra.
DISKSPD é uma ferramenta que você pode personalizar para criar suas próprias cargas de trabalho sintéticas e testar seu aplicativo antes da implantação. O interessante da ferramenta é que ela oferece a liberdade de configurar e ajustar os parâmetros para criar um cenário específico que se assemelha à carga de trabalho real. O DISKSPD pode fornecer um vislumbre do que seu sistema é capaz antes da implantação. Em sua essência, DISKSPD simplesmente emite um monte de operações de leitura e gravação.
Agora você sabe o que é DISKSPD, mas quando você deve usá-lo? O DISKSPD tem dificuldade em emular cargas de trabalho complexas. Mas DISKSPD é ótimo quando sua carga de trabalho não é aproximada por uma cópia de arquivo de thread único e você precisa de uma ferramenta simples que produz resultados de linha de base aceitáveis.
Início rápido: instalar e executar DISKSPD
Sem mais detalhes, vamos começar:
No computador de gerenciamento, abra o PowerShell como administrador para se conectar ao computador de destino que você deseja testar usando DISKSPD e digite o comando a seguir e pressione Enter.
Enter-PSSession -ComputerName <TARGET_COMPUTER_NAME>Neste exemplo, estamos executando uma VM (máquina virtual) chamada "node1".
Para baixar a ferramenta DISKSPD, digite os seguintes comandos e pressione Enter:
$client = new-object System.Net.WebClient$client.DownloadFile("https://github.com/microsoft/diskspd/releases/download/v2.0.21a/DiskSpd.zip","<ENTER_PATH>\DiskSpd-2.0.21a.zip")Use o seguinte comando para descompactar o arquivo baixado:
Expand-Archive -LiteralPath <ENTERPATH>\DiskSpd-2.0.21a.zip -DestinationPath C:\DISKSPDAltere o diretório para o diretório DISKSPD e localize o arquivo executável apropriado para o sistema operacional Windows que o computador de destino está executando.
Neste exemplo, estamos usando a versão amd64.
Observação
Você também pode baixar a ferramenta DISKSPD diretamente do repositório GitHub que contém o código-fonte aberto e uma página wiki que detalha todos os parâmetros e especificações. No repositório, em Versões, selecione o link para baixar automaticamente o arquivo ZIP.
No arquivo ZIP, você verá três subpastas: amd64 (sistemas de 64 bits), x86 (sistemas de 32 bits) e ARM64 (sistemas ARM). Essas opções permitem que você execute a ferramenta em todas as versões de cliente ou servidor do Windows.

Execute DISKSPD com o seguinte comando do PowerShell. Substitua tudo dentro dos colchetes, incluindo os próprios colchetes pelas configurações apropriadas.
.\[INSERT_DISKSPD_PATH] [INSERT_SET_OF_PARAMETERS] [INSERT_CSV_PATH_FOR_TEST_FILE] > [INSERT_OUTPUT_FILE.txt]Aqui está um exemplo de comando que você pode executar:
.\diskspd -t2 -o32 -b4k -r4k -w0 -d120 -Sh -D -L -c5G C:\ClusterStorage\test01\targetfile\IO.dat > test01.txtObservação
Se você não tiver um arquivo de teste, use o parâmetro -c para criar um. Se você usar esse parâmetro, inclua o nome do arquivo de teste ao definir seu caminho. Por exemplo: [INSERT_CSV_PATH_FOR_TEST_FILE] = C:\ClusterStorage\CSV01\IO.dat. No comando de exemplo, IO.dat é o nome do arquivo de teste e test01.txt é o nome do arquivo de saída DISKSPD.

Especificar parâmetros de chave
Bem, isso foi simples, certo? Infelizmente, há mais do que isso. Vamos desempacotar o que fizemos. Primeiro, há vários parâmetros com os quais você pode mexer e ele pode ser específico. No entanto, usamos o seguinte conjunto de parâmetros de linha de base:
Observação
Os parâmetros DISKSPD diferenciam maiúsculas de minúsculas.
-t2: isso indica o número de threads por arquivo de destino/teste. Esse número geralmente é baseado no número de núcleos de CPU. Nesse caso, dois threads foram usados para enfatizar todos os núcleos de CPU.
-o32: isso indica o número de solicitações de E/S pendentes por destino por thread. Isso também é conhecido como a profundidade da fila e, nesse caso, 32 foram usados para enfatizar a CPU.
-b4K: isso indica o tamanho do bloco em bytes, KiB, MiB ou GiB. Nesse caso, o tamanho do bloco de 4K foi usado para simular um teste de E/S aleatório.
-r4K: isso indica a E/S aleatória alinhada ao tamanho especificado em bytes, KiB, MiB, Gib ou blocos (substitui o parâmetro -s ). O tamanho comum de bytes de 4K foi usado para se alinhar corretamente com o tamanho do bloco.
-w0: especifica o percentual de operações que são solicitações de gravação (-w0 é equivalente a 100% de leitura). Nesse caso, 0% de gravações foram usadas para fins de um teste simples.
-d120: especifica a duração do teste, não incluindo resfriamento ou aquecimento. O valor padrão é 10 segundos, mas é recomendável usar pelo menos 60 segundos para qualquer carga de trabalho séria. Nesse caso, 120 segundos foram usados para minimizar quaisquer exceções.
-Suw: desabilita o cache de gravação de software e hardware (equivalente a -Sh).
-D: captura estatísticas de IOPS, como desvio padrão, em intervalos de milissegundos (por thread, por destino).
-L: mede estatísticas de latência.
-c5g: define o tamanho do arquivo de exemplo usado no teste. Ele pode ser definido em bytes, KiB, MiB, GiB ou blocos. Nesse caso, um arquivo de destino de 5 GB foi usado.
Para obter uma lista completa de parâmetros, consulte o repositório GitHub.
Entender o ambiente
O desempenho depende muito do seu ambiente. Então, qual é o nosso ambiente? Nossa especificação envolve um cluster do Azure Stack HCI com pool de armazenamento e S2D (Espaços de Armazenamento Diretos). Mais especificamente, há cinco VMs: DC, node1, node2, node3 e o nó de gerenciamento. O cluster em si é um cluster de três nós com uma estrutura de resiliência espelhada de três vias. Portanto, três cópias de dados são mantidas. Cada "nó" no cluster é uma VM Standard_B2ms com um limite máximo de IOPS de 1920. Em cada nó, há quatro unidades SSD P30 premium com um limite máximo de IOPS de 5000. Por fim, cada unidade SSD tem 1 TB de memória.
Você gera o arquivo de teste no namespace unificado que o CSV (Volume Compartilhado clusterizado) fornece (C:\ClusteredStorage) para usar todo o pool de unidades.
Observação
O ambiente de exemplo não tem o Hyper-V ou uma estrutura de virtualização aninhada.
Como você verá, é totalmente possível atingir independentemente o teto de IOPS ou largura de banda no limite da VM ou da unidade. Portanto, é importante entender o tamanho da VM e o tipo de unidade, pois ambos têm um limite máximo de IOPS e um teto de largura de banda. Esse conhecimento ajuda a localizar gargalos e entender seus resultados de desempenho. Para saber mais sobre qual tamanho pode ser apropriado para sua carga de trabalho, confira os seguintes recursos:
Entender a saída
Armado com sua compreensão dos parâmetros e do ambiente, você está pronto para interpretar a saída. Primeiro, a meta do teste anterior era maximizar o IOPS sem considerar a latência. Dessa forma, você pode ver visualmente se atinge o limite de IOPS artificial no Azure. Se você quiser visualizar graficamente o IOPS total, use Windows Admin Center ou Gerenciador de Tarefas.
O diagrama a seguir mostra como é a aparência do processo DISKSPD em nosso ambiente de exemplo. Ele mostra um exemplo de uma operação de gravação de 1 MiB de um nó não coordenador. A estrutura de resiliência de três vias, juntamente com a operação de um nó não coordenador, leva a dois saltos de rede, diminuindo o desempenho. Se você está se perguntando o que é um nó coordenador, não se preocupe! Você aprenderá sobre isso na seção Coisas a serem consideradas . Os quadrados vermelhos representam a VM e os gargalos de unidade.

Agora que você tem uma compreensão visual, vamos examinar as quatro seções main da saída do arquivo .txt:
Configurações de entrada
Esta seção descreve o comando que você executou, os parâmetros de entrada e detalhes adicionais sobre a execução do teste.
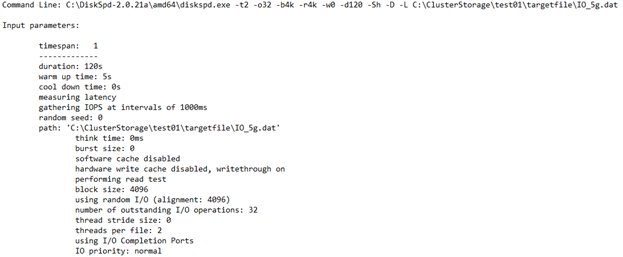
Detalhes de utilização da CPU
Esta seção destaca informações como o tempo de teste, o número de threads, o número de processadores disponíveis e a utilização média de cada núcleo de CPU durante o teste. Nesse caso, há dois núcleos de CPU que tiveram uma média de cerca de 4,67% de uso.
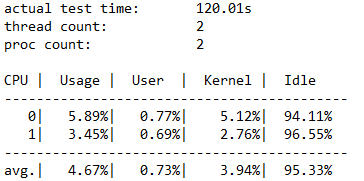
E/S total
Esta seção tem três subseções. A primeira seção destaca os dados gerais de desempenho, incluindo operações de leitura e gravação. A segunda e a terceira seções dividem as operações de leitura e gravação em categorias separadas.
Neste exemplo, você pode ver que a contagem total de E/S foi 234408 durante a duração de 120 segundos. Assim, IOPS = 234408 /120 = 1953,30. A latência média foi de 32,763 milissegundos e a taxa de transferência foi de 7,63 MiB/s. De informações anteriores, sabemos que o IOPS 1953.30 está próximo da limitação de IOPS de 1920 para nossa VM Standard_B2ms. Não acredita? Se você executar esse teste novamente usando parâmetros diferentes, como aumentar a profundidade da fila, descobrirá que os resultados ainda estão limitados a esse número.
As últimas três colunas mostram o desvio padrão de IOPS em 17,72 (do parâmetro -D), o desvio padrão da latência em 20,994 milissegundos (do parâmetro -L) e o caminho do arquivo.

Nos resultados, você pode determinar rapidamente que a configuração do cluster é terrível. Você pode ver que ele atingiu a limitação da VM de 1920 antes da limitação do SSD de 5000. Se você fosse limitado pelo SSD em vez da VM, poderia ter aproveitado até 20000 IOPS (4 unidades * 5000) abrangendo o arquivo de teste em várias unidades.
No final, você precisa decidir quais valores são aceitáveis para sua carga de trabalho específica. A figura a seguir mostra algumas relações importantes para ajudá-lo a considerar as compensações:

A segunda relação na figura é importante, e às vezes é conhecida como Lei de Little. A lei apresenta a ideia de que há três características que regem o comportamento do processo e que você só precisa alterar uma para influenciar as outras duas e, portanto, todo o processo. E assim, se você está infeliz com o desempenho do seu sistema, você tem três dimensões de liberdade para influenciá-lo. A Lei de Little determina que, em nosso exemplo, o IOPS é a "taxa de transferência" (operações de saída de entrada por segundo), a latência é o "tempo da fila" e a profundidade da fila é o "inventário".
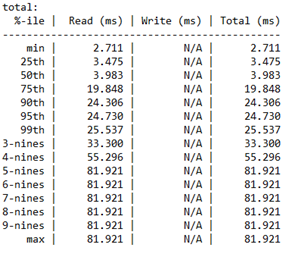
Análise de percentil de latência
Esta última seção detalha as latências de percentil por tipo de operação de desempenho de armazenamento do valor mínimo para o valor máximo.
Esta seção é importante porque determina a "qualidade" do seu IOPS. Ele revela quantas operações de E/S foram capazes de obter um determinado valor de latência. Cabe a você decidir a latência aceitável para esse percentil.
Além disso, os "noves" referem-se ao número de noves. Por exemplo, "3-noves" é equivalente ao 99º percentil. O número de noves expõe quantas operações de E/S foram executadas nesse percentil. Eventualmente, você chegará a um ponto em que não faz mais sentido levar a sério os valores de latência. Nesse caso, você pode ver que os valores de latência permanecem constantes após "4-noves". Neste ponto, o valor de latência é baseado em apenas uma operação de E/S das operações de 234408.





Itens a serem considerados
Agora que você começou a usar DISKSPD, há várias coisas a considerar para obter resultados de teste do mundo real. Isso inclui prestar muita atenção aos parâmetros definidos, à integridade do espaço de armazenamento e às variáveis, à propriedade CSV e à diferença entre DISKSPD e cópia de arquivo.
DISKSPD versus mundo real
O teste artificial do DISKSPD fornece resultados relativamente comparáveis para sua carga de trabalho real. No entanto, você precisa prestar muita atenção aos parâmetros definidos e se eles correspondem ao seu cenário real. É importante entender que as cargas de trabalho sintéticas nunca representarão perfeitamente a carga de trabalho real do aplicativo durante a implantação.
Preparação
Antes de executar um teste DISKSPD, há algumas ações recomendadas. Isso inclui verificar a integridade do espaço de armazenamento, verificar o uso de recursos para que outro programa não interfira no teste e preparar o gerenciador de desempenho se você quiser coletar dados adicionais. No entanto, como o objetivo deste tópico é fazer com que o DISKSPD seja executado rapidamente, ele não se aprofunda nas especificidades dessas ações. Para saber mais, confira Testar Espaços de Armazenamento desempenho usando cargas de trabalho sintéticas no Windows Server.
Variáveis que afetam o desempenho
O desempenho do armazenamento é uma coisa delicada. Ou seja, há muitas variáveis que podem afetar o desempenho. Portanto, é provável que você encontre um número inconsistente com suas expectativas. O seguinte destaca algumas das variáveis que afetam o desempenho, embora não seja uma lista abrangente:
- Largura de banda da rede
- Escolha de resiliência
- Configuração do disco de armazenamento: NVME, SSD, HDD
- Buffer de E/S
- Cache
- Configuração RAID
- Saltos de rede
- Velocidades do eixo do disco rígido
Propriedade do CSV
Um nó é conhecido como um proprietário de volume ou o nó coordenador (um nó não coordenador seria o nó que não possui um volume específico). Cada volume padrão recebe um nó e os outros nós podem acessar esse volume padrão por meio de saltos de rede, o que resulta em um desempenho mais lento (maior latência).
Da mesma forma, um CSV (Volume Compartilhado clusterizado) também tem um "proprietário". No entanto, um CSV é "dinâmico" no sentido de que ele vai saltar e alterar a propriedade toda vez que você reiniciar o sistema (RDP). Como resultado, é importante confirmar que DISKSPD é executado no nó coordenador que possui o CSV. Caso contrário, talvez seja necessário alterar manualmente a propriedade do CSV.
Para confirmar a propriedade do CSV:
Verifique a propriedade executando o seguinte comando do PowerShell:
Get-ClusterSharedVolumeSe a propriedade CSV estiver incorreta (por exemplo, você está no Node1, mas o Node2 possui o CSV), mova o CSV para o nó correto executando o seguinte comando do PowerShell:
Get-ClusterSharedVolume <INSERT_CSV_NAME> | Move-ClusterSharedVolume <INSERT _NODE_NAME>
Cópia de arquivo versus DISKSPD
Algumas pessoas acreditam que podem "testar o desempenho do armazenamento" copiando e colando um arquivo gigantesco e medindo quanto tempo esse processo leva. A main razão por trás dessa abordagem é provavelmente porque é simples e rápida. A ideia não está errada no sentido de testar uma carga de trabalho específica, mas é difícil categorizar esse método como "testando o desempenho de armazenamento".
Se o objetivo do mundo real é testar o desempenho da cópia de arquivo, isso pode ser um motivo perfeitamente válido para usar esse método. No entanto, se sua meta for medir o desempenho do armazenamento, recomendamos não usar esse método. Você pode pensar no processo de cópia de arquivo como usando um conjunto diferente de "parâmetros" (como fila, paralelização e assim por diante) que é específico para serviços de arquivos.
O resumo curto a seguir explica por que usar a cópia de arquivo para medir o desempenho do armazenamento pode não fornecer os resultados que você está procurando:
As cópias de arquivo podem não ser otimizadas, Há dois níveis de paralelismo que ocorrem, um interno e outro externo. Internamente, se a cópia de arquivo estiver indo para um destino remoto, o mecanismo CopyFileEx aplicará alguma paralelização. Externamente, há diferentes maneiras de invocar o mecanismo CopyFileEx. Por exemplo, cópias de Explorador de Arquivos são threaded único, mas o Robocopy é multi-threaded. Por essas razões, é importante entender se as implicações do teste são o que você está procurando.
Cada cópia tem dois lados. Quando você simplesmente copia e cola um arquivo, pode estar usando dois discos: o disco de origem e o disco de destino. Se um for mais lento que o outro, você essencialmente medirá o desempenho do disco mais lento. Há outros casos em que a comunicação entre a origem, o destino e o mecanismo de cópia pode afetar o desempenho de maneiras exclusivas.
Para saber mais, confira Usando a cópia de arquivo para medir o desempenho do armazenamento.
Experimentos e cargas de trabalho comuns
Esta seção inclui alguns outros exemplos, experimentos e tipos de carga de trabalho.
Confirmando o nó coordenador
Conforme mencionado anteriormente, se a VM que você está testando atualmente não possui o CSV, você verá uma queda de desempenho (IOPS, taxa de transferência e latência) em vez de testá-la quando o nó possui o CSV. Isso ocorre porque sempre que você emite uma operação de E/S, o sistema faz um salto de rede para o nó coordenador para executar essa operação.
Para uma situação espelhada de três nós e de três vias, as operações de gravação sempre fazem um salto de rede porque ela precisa armazenar dados em todas as unidades entre os três nós. Portanto, as operações de gravação fazem um salto de rede independentemente. No entanto, se você usar uma estrutura de resiliência diferente, isso poderá mudar.
Veja um exemplo:
- Em execução no nó local: .\DiskSpd-2.0.21a\amd64\diskspd.exe -t4 -o32 -b4k -r4k -w0 -Sh -D -L C:\ClusterStorage\test01\targetfile\IO.dat
- Em execução no nó não local: .\DiskSpd-2.0.21a\amd64\diskspd.exe -t4 -o32 -b4k -r4k -w0 -Sh -D -L C:\ClusterStorage\test01\targetfile\IO.dat
Neste exemplo, você pode ver claramente nos resultados da figura a seguir que a latência diminuiu, o IOPS aumentou e a taxa de transferência aumentou quando o nó coordenador possui o CSV.

Carga de trabalho de OLTP (Processamento de Transações Online)
As consultas de carga de trabalho OLTP (Processamento Transacional Online) (Atualização, Inserção, Exclusão) se concentram em tarefas orientadas a transações. Em comparação com o OLAP (Processamento Analítico Online), o OLTP depende da latência de armazenamento. Como cada operação emite pouca E/S, o que você se importa é com quantas operações por segundo você pode sustentar.
Você pode criar um teste de carga de trabalho OLTP para se concentrar no desempenho de E/S aleatório e pequeno. Para esses testes, concentre-se em quão longe você pode efetuar push da taxa de transferência, mantendo latências aceitáveis.
A opção básica de design para este teste de carga de trabalho deve, no mínimo, incluir:
- Tamanho do bloco de 8 KB => se assemelha ao tamanho da página que SQL Server usa para seus arquivos de dados
- 70% Leitura, 30% gravação => se assemelha ao comportamento típico de OLTP
Carga de trabalho de OLAP (Processamento Analítico Online)
As cargas de trabalho OLAP se concentram na recuperação e na análise de dados, permitindo que os usuários executem consultas complexas para extrair dados multidimensionais. Ao contrário do OLTP, essas cargas de trabalho não diferenciam a latência de armazenamento. Eles enfatizam o enfileiramento de muitas operações sem se importar muito com a largura de banda. Como resultado, as cargas de trabalho OLAP geralmente resultam em tempos de processamento mais longos.
Você pode criar um teste de carga de trabalho OLAP para se concentrar no desempenho sequencial de E/S grande. Para esses testes, concentre-se no volume de dados processados por segundo em vez do número de IOPS. Os requisitos de latência também são menos importantes, mas isso é subjetivo.
A opção básica de design para este teste de carga de trabalho deve, no mínimo, incluir:
Tamanho do bloco de 512 KB => se assemelha ao tamanho de E/S quando o SQL Server carrega um lote de 64 páginas de dados para uma verificação de tabela usando a técnica de leitura antecipada.
1 thread por arquivo => atualmente, você precisa limitar o teste a um thread por arquivo, pois podem surgir problemas em DISKSPD ao testar vários threads sequenciais. Se você usar mais de um thread, digamos dois, e o parâmetro -s , os threads começarão não deterministicamente a emitir operações de E/S em cima umas das outras no mesmo local. Isso ocorre porque cada um controla seu próprio deslocamento sequencial.
Há duas "soluções" para resolve esse problema:
A primeira solução envolve o uso do parâmetro -si . Com esse parâmetro, ambos os threads compartilham um único deslocamento interligado para que os threads emitam cooperativamente um único padrão sequencial de acesso ao arquivo de destino. Isso permite que nenhum ponto no arquivo seja operado em mais de uma vez. No entanto, como eles ainda correm entre si para emitir sua operação de E/S para a fila, as operações podem chegar fora de ordem.
Essa solução funcionará bem se um thread se tornar limitado pela CPU. Talvez você queira envolver um segundo thread em um segundo núcleo de CPU para fornecer mais E/S de armazenamento ao sistema de CPU para saturar ainda mais.
A segunda solução envolve o uso do deslocamento> -T<. Isso permite que você especifique o tamanho do deslocamento (intervalo entre E/S) entre operações de E/S executadas no mesmo arquivo de destino por threads diferentes. Por exemplo, os threads normalmente começam no deslocamento 0, mas essa especificação permite que você distancie os dois threads para que eles não se sobreponham. Em qualquer ambiente multithread, os threads provavelmente estarão em diferentes partes do destino de trabalho, e essa é uma maneira de simular essa situação.
Próximas etapas
Para obter mais informações e exemplos detalhados sobre como otimizar suas configurações de resiliência, consulte também:
Comentários
Em breve: Ao longo de 2024, eliminaremos os problemas do GitHub como o mecanismo de comentários para conteúdo e o substituiremos por um novo sistema de comentários. Para obter mais informações, consulte https://aka.ms/ContentUserFeedback.
Enviar e exibir comentários de