Antipadrão do front-end ocupado
Executar um trabalho assíncrono em um grande número de threads em segundo plano pode enfraquecer outras tarefas de primeiro plano simultâneas de recursos, diminuindo os tempos de resposta a níveis inaceitáveis.
Descrição do problema
Tarefas de uso intensivo de recursos podem aumentar os tempos de resposta para solicitações de usuário e causar alta latência. Uma forma de melhorar os tempos de resposta é descarregando uma tarefa de uso intensivo de recursos para um thread separado. Essa abordagem faz com que o aplicativo permaneça responsivo enquanto o processamento ocorre em segundo plano. No entanto, as tarefas que são executadas em um thread em segundo plano ainda consumirão recursos. Se houver muitas delas, isso pode enfraquecer os threads que estão tratando de solicitações.
Observação
O termo recurso pode abranger muitas coisas, como utilização da CPU, ocupação da memória e E/S de rede ou disco.
Esse problema normalmente ocorre quando um aplicativo é desenvolvido como trecho de código monolítico, com toda a lógica de negócios combinada em uma única camada compartilhada com a camada de apresentação.
Veja um exemplo usando o ASP.NET que demonstra o problema. Você pode encontrar o exemplo completo aqui.
public class WorkInFrontEndController : ApiController
{
[HttpPost]
[Route("api/workinfrontend")]
public HttpResponseMessage Post()
{
new Thread(() =>
{
//Simulate processing
Thread.SpinWait(Int32.MaxValue / 100);
}).Start();
return Request.CreateResponse(HttpStatusCode.Accepted);
}
}
public class UserProfileController : ApiController
{
[HttpGet]
[Route("api/userprofile/{id}")]
public UserProfile Get(int id)
{
//Simulate processing
return new UserProfile() { FirstName = "Alton", LastName = "Hudgens" };
}
}
O método
Postno controladorWorkInFrontEndimplementa uma operação HTTP POST. Essa operação simula uma tarefa de longo prazo com uso intensivo de CPU. O trabalho é executado em um thread separado, em uma tentativa de permitir que a operação POST seja concluída rapidamente.O método
Getno controladorUserProfileimplementa uma operação HTTP GET. Esse método tem um uso muito menos intensivo da CPU.
A principal preocupação é com os requisitos do recurso do método Post. Embora ele coloque o trabalho em um thread em segundo plano, o trabalho ainda pode consumir muitos recursos da CPU. Esses recursos são compartilhados com outras operações sendo executadas por outros usuários simultâneos. Se um número moderado de usuários enviar essa solicitação ao mesmo tempo, o desempenho geral provavelmente será afetado, diminuindo todas as operações. Os usuários podem enfrentar latência significativa no método Get, por exemplo.
Como corrigir o problema
Mova os processos que consomem recursos significativos para um back-end separado.
Com essa abordagem, o front-end coloca as tarefas de uso intensivo de recursos em uma fila de mensagens. O back-end seleciona as tarefas para processamento assíncrono. A fila também atua como um nivelador de carga, armazenando solicitações em buffer para o back-end. Se o comprimento da fila ficar muito longo, você pode configurar o dimensionamento automático para escalar o back-end horizontalmente.
Eis aqui uma versão revisada do código anterior. Nessa versão, o método Post coloca uma mensagem em uma fila do Barramento de Serviço.
public class WorkInBackgroundController : ApiController
{
private static readonly QueueClient QueueClient;
private static readonly string QueueName;
private static readonly ServiceBusQueueHandler ServiceBusQueueHandler;
public WorkInBackgroundController()
{
var serviceBusConnectionString = ...;
QueueName = ...;
ServiceBusQueueHandler = new ServiceBusQueueHandler(serviceBusConnectionString);
QueueClient = ServiceBusQueueHandler.GetQueueClientAsync(QueueName).Result;
}
[HttpPost]
[Route("api/workinbackground")]
public async Task<long> Post()
{
return await ServiceBusQueueHandler.AddWorkLoadToQueueAsync(QueueClient, QueueName, 0);
}
}
O back-end efetua o pull de mensagens da fila do Barramento de Serviço e executa o processamento.
public async Task RunAsync(CancellationToken cancellationToken)
{
this._queueClient.OnMessageAsync(
// This lambda is invoked for each message received.
async (receivedMessage) =>
{
try
{
// Simulate processing of message
Thread.SpinWait(Int32.MaxValue / 1000);
await receivedMessage.CompleteAsync();
}
catch
{
receivedMessage.Abandon();
}
});
}
Considerações
- Essa abordagem adiciona um pouco de complexidade adicional ao aplicativo. Você deve tratar a inserção e remoção na fila com segurança para evitar a perda de solicitações em caso de falha.
- O aplicativo usa uma dependência em um serviço adicional para a fila de mensagens.
- O ambiente de processamento deve ser suficientemente escalonável para tratar a carga de trabalho esperada e atender às metas de taxa de transferência necessária.
- Embora essa abordagem deva melhorar a capacidade de resposta geral, as tarefas movidas para o back-end podem levar mais tempo para serem concluídas.
Como detectar o problema
Entre os sintomas de um front-end ocupado, temos a alta latência quando tarefas de uso intensivo de recursos estão sendo executadas. É provável que os usuários finais relatem tempos de resposta prolongados ou falhas causadas pelo tempo limite dos serviços. Essas falhas também podem retornar erros HTTP 500 (Servidor Interno) ou HTTP 503 (Serviço Indisponível). Examine os logs de eventos para o servidor Web, que provavelmente contêm informações mais detalhadas sobre as causas e as circunstâncias dos erros.
Você pode executar as etapas a seguir para ajudar a identificar o problema:
- Executar o monitoramento de processos do sistema de produção para identificar pontos quando os tempos de resposta ficam lentos.
- Examinar os dados de telemetria capturados nesses pontos para determinar a combinação de operações sendo executadas e recursos sendo usados.
- Encontrar quaisquer correlações entre os tempos de resposta ruins e os volumes e combinações de operações que estavam acontecendo nesses momentos.
- Fazer um teste de carga em cada operação suspeita para identificar quais operações estão consumindo recursos e enfraquecendo outras operações.
- Examinar o código-fonte dessas operações para determinar por que eles podem causar consumo excessivo de recursos.
Diagnóstico de exemplo
As seções a seguir aplicam essas etapas ao aplicativo de exemplo descrito anteriormente.
Identificar pontos de lentidão
Instrumente cada método para acompanhar a duração e os recursos consumidos por cada solicitação. Depois monitore o aplicativo em produção. Isso pode fornecer uma visão geral de como solicitações concorrem umas com as outras. Durante períodos de estresse, solicitações lentas que consomem muitos recursos provavelmente afetarão outras operações. Esse comportamento pode ser observado fazendo o monitoramento do sistema e observando a queda no desempenho.
A imagem a seguir mostra um painel de monitoramento. (Usamos AppDynamics para nossos testes.) Inicialmente, o sistema tem carga leve. Em seguida, os usuários começam a solicitar o método GET UserProfile. O desempenho é razoavelmente bom até que outros usuários comecem a emitir solicitações para o método POST WorkInFrontEnd. Nesse ponto, os tempos de resposta aumentam consideravelmente (primeira seta). Os tempos de resposta só melhoram após a diminuição do volume de solicitações para o controlador WorkInFrontEnd (segunda seta).
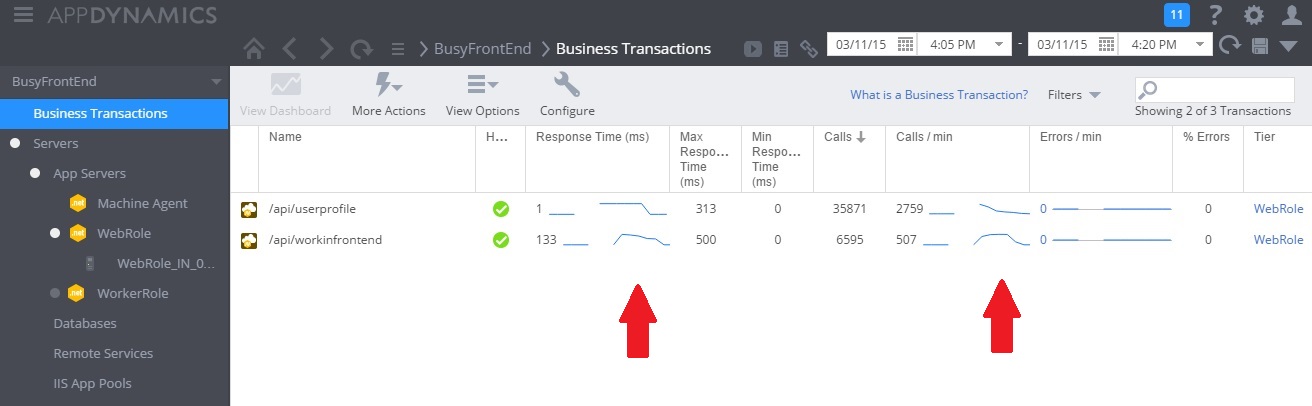
Examinar os dados de telemetria e localizar correlações
A imagem a seguir mostra algumas das métricas coletadas para monitorar a utilização de recursos durante o mesmo intervalo. No primeiro momento, poucos usuários estão acessando o sistema. À medida que mais usuários se conectam, a utilização da CPU fica muito alta (100%). Também observe que a taxa de E/S de rede inicialmente sobe à medida que o uso da CPU aumenta. Mas uma vez que o uso da CPU fica em pico, a E/S de rede diminui. Isso se deve ao fato de o sistema só conseguir lidar com um número relativamente pequeno de solicitações depois que a CPU está na capacidade máxima. À medida que os usuários se desconectam, a carga da CPU diminui.

Nesse ponto, parece que o método Post no controlador WorkInFrontEnd é um candidato perfeito para uma análise mais detalhada. É preciso um trabalho mais profundo em um ambiente controlado para confirmar a hipótese.
Realizar testes de carga
A próxima etapa é executar testes em um ambiente controlado. Por exemplo, executar uma série de testes de carga que incluam e depois omitam cada solicitação para ver os efeitos.
O gráfico abaixo mostra os resultados de um teste de carga executado em uma implantação idêntica do serviço em nuvem usado nos testes anteriores. O teste usou uma carga constante de 500 usuários executando a operação Get no controlador UserProfile, junto com uma carga por etapa de usuários executando a operação Post no controlador WorkInFrontEnd.
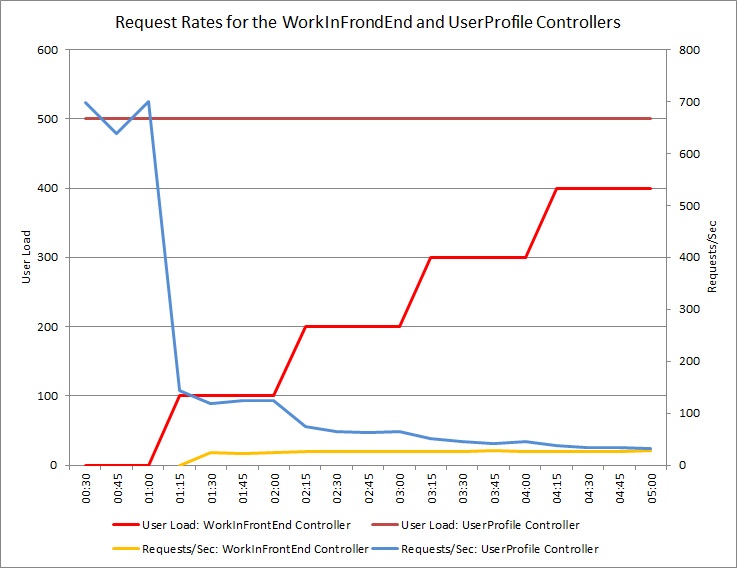
Inicialmente, a carga por etapa é 0, de modo que somente os usuários ativos estão executando as solicitações UserProfile. O sistema é capaz de responder a aproximadamente 500 solicitações por segundo. Depois de 60 segundos, uma carga de 100 usuários adicionais começa a enviar solicitações POST para o controlador WorkInFrontEnd. Quase imediatamente, a carga de trabalho enviada para o controlador UserProfile cai para cerca de 150 solicitações por segundo. Isso se deve à maneira como o executor de teste de carga funciona. Ele espera por uma resposta antes de enviar a próxima solicitação, portanto, quanto mais tempo ele leva para receber uma resposta, menor a taxa de solicitação.
À medida que mais usuários enviam solicitações POST para o controlador WorkInFrontEnd, a taxa de resposta do controlador UserProfile continua a cair. Mas observe que o volume de solicitações tratadas pelo controlador WorkInFrontEnd permanece relativamente constante. A saturação do sistema torna-se aparente à medida que a taxa geral de ambas as solicitações tende a um limite estável, mas baixo.
Examinar o código-fonte
A etapa final é examinar o código-fonte. A equipe de desenvolvimento estava ciente de que o método Post poderia demorar um tempo considerável, por isso que a implementação original usou um thread separado. Isso solucionou o problema imediato porque o método Post não foi bloqueado ao aguardar uma tarefa de execução longa ser concluída.
No entanto, o trabalho executado por esse método ainda consome CPU, memória e outros recursos. Habilitar esse processo para ser executado de forma assíncrona pode até afetar o desempenho, uma vez que os usuários podem acionar um grande número dessas operações simultaneamente e de maneira descontrolada. Há um limite para o número de threads que podem ser executados por um servidor. Ao passar desse limite, é provável que o aplicativo receba uma exceção ao tentar iniciar um novo thread.
Observação
Isso não significa que você deve evitar operações assíncronas. Executar uma espera assíncrona em uma chamada de rede é uma prática recomendada. (Veja o Antipadrão de E/S síncrona.) O problema aqui é que o trabalho intensivo de CPU foi gerado em outro thread.
Implementar a solução e verificar o resultado
A imagem a seguir mostra o monitoramento de desempenho depois de a solução ter sido implementada. A carga foi semelhante à mostrada anteriormente, mas os tempos de resposta para o controlador UserProfile agora estão muito mais rápidos. O volume de solicitações aumentou com a mesma duração: de 2.759 para 23.565.
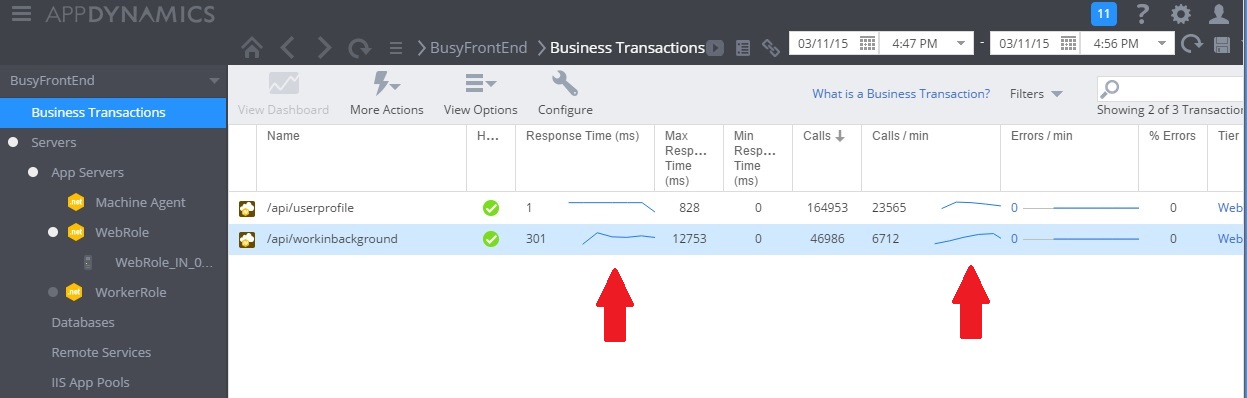
Observe que o controlador WorkInBackground também tratou de um volume muito maior de solicitações. No entanto, você não pode fazer uma comparação direta nesse caso porque o trabalho sendo executado nesse controlador é muito diferente do código original. A nova versão simplesmente coloca uma solicitação na fila, em vez de executar um cálculo demorado. O ponto principal é que esse método não mais arrasta para baixo todo o sistema sob carga.
O uso de CPU e de rede também mostra o desempenho aprimorado. O uso da CPU nunca atingiu 100%, e o volume de solicitações de rede tratadas era muito maior do que o anterior e não diminuiu até a carga de trabalho diminuir.

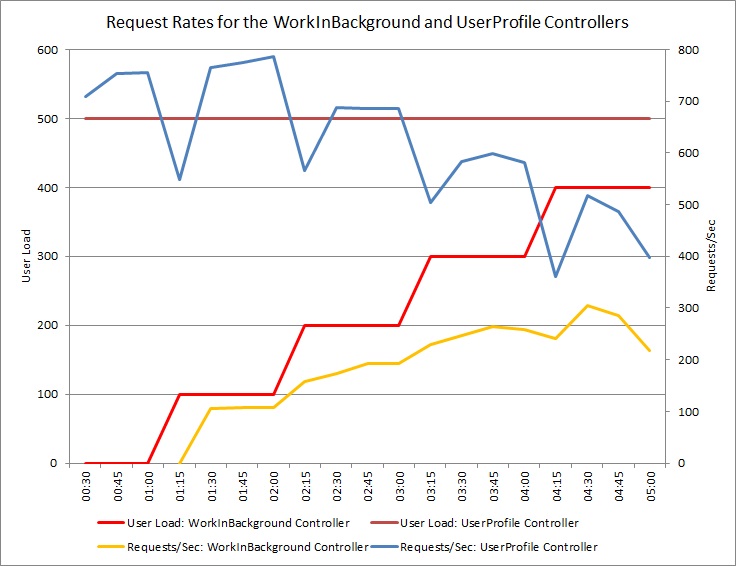
O gráfico a seguir mostra os resultados de um teste de carga. O volume total de solicitações atendidas é significativamente maior em comparação com os testes anteriores.
Diretrizes relacionadas
Comentários
Em breve: Ao longo de 2024, eliminaremos os problemas do GitHub como o mecanismo de comentários para conteúdo e o substituiremos por um novo sistema de comentários. Para obter mais informações, consulte https://aka.ms/ContentUserFeedback.
Enviar e exibir comentários de