Antipadrão de instanciação inadequada
Às vezes, instâncias de uma classe são criadas continuamente, quando ela deve ser criada uma vez e, depois, compartilhada. Esse comportamento pode prejudicar o desempenho e é chamado de antipadrão de instanciação inadequada. Um antipadrão é uma resposta comum a um problema recorrente que geralmente é ineficaz e pode até mesmo ser contraproducente.
Descrição do problema
Muitas bibliotecas fornecem abstrações de recursos externos. Internamente, essas classes normalmente gerenciam suas próprias conexões ao recurso, atuando como agentes que os clientes podem usar para acessar o recurso. Aqui estão alguns exemplos de classes de agente que são relevantes para aplicativos do Azure:
System.Net.Http.HttpClient. Se comunica com um serviço Web usando HTTP.Microsoft.ServiceBus.Messaging.QueueClient. Envia e recebe mensagens para uma fila do Barramento de Serviço.Microsoft.Azure.Documents.Client.DocumentClient. Conecta a uma instância do Azure Cosmos DB.StackExchange.Redis.ConnectionMultiplexer. Conecta-se ao Redis, incluindo o Cache Redis do Azure.
Essas classes são destinadas a serem instanciados uma vez e reutilizadas em todo o tempo de vida de um aplicativo. No entanto, é comum cometer o equívoco de achar que essas classes devem ser adquiridas somente quando necessário e lançadas rapidamente. (As listadas aqui são bibliotecas .NET, mas o padrão não é exclusivo do .NET.) O exemplo ASP.NET a seguir cria uma instância de HttpClient para se comunicar com um serviço remoto. Você pode encontrar o exemplo completo aqui.
public class NewHttpClientInstancePerRequestController : ApiController
{
// This method creates a new instance of HttpClient and disposes it for every call to GetProductAsync.
public async Task<Product> GetProductAsync(string id)
{
using (var httpClient = new HttpClient())
{
var hostName = HttpContext.Current.Request.Url.Host;
var result = await httpClient.GetStringAsync(string.Format("http://{0}:8080/api/...", hostName));
return new Product { Name = result };
}
}
}
Em um aplicativo Web, essa técnica não será escalonável. Um novo objeto HttpClient é criado para cada solicitação de usuário. Sob carga pesada, o servidor Web pode esgotar o número de soquetes disponíveis, resultando em erros SocketException.
Esse problema não está restrito à classe HttpClient. Outras classes que encapsulam recursos ou que são caros de criar podem causar problemas semelhantes. O exemplo a seguir cria uma instância da classe ExpensiveToCreateService. Aqui o problema não é necessariamente o esgotamento de soquete, mas simplesmente quanto tempo leva para criar cada instância. Criar e destruir continuamente instâncias dessa classe pode prejudicar a escalabilidade do sistema.
public class NewServiceInstancePerRequestController : ApiController
{
public async Task<Product> GetProductAsync(string id)
{
var expensiveToCreateService = new ExpensiveToCreateService();
return await expensiveToCreateService.GetProductByIdAsync(id);
}
}
public class ExpensiveToCreateService
{
public ExpensiveToCreateService()
{
// Simulate delay due to setup and configuration of ExpensiveToCreateService
Thread.SpinWait(Int32.MaxValue / 100);
}
...
}
Como corrigir o antipadrão de instanciação inadequada
Se a classe que encapsula o recurso externo for compartilhável e thread-safe, crie uma instância singleton compartilhada ou um pool de instâncias reutilizáveis da classe.
O seguinte exemplo usa uma instância HttpClient estática, compartilhamento, portanto, a conexão entre todas as solicitações.
public class SingleHttpClientInstanceController : ApiController
{
private static readonly HttpClient httpClient;
static SingleHttpClientInstanceController()
{
httpClient = new HttpClient();
}
// This method uses the shared instance of HttpClient for every call to GetProductAsync.
public async Task<Product> GetProductAsync(string id)
{
var hostName = HttpContext.Current.Request.Url.Host;
var result = await httpClient.GetStringAsync(string.Format("http://{0}:8080/api/...", hostName));
return new Product { Name = result };
}
}
Considerações
O elemento chave desse antipadrão é criar e destruir repetidamente as instâncias de um objeto compartilhável. Se a classe não for compartilhável (não é thread-safe), então esse antipadrão não se aplica.
O tipo de recurso compartilhado pode determinam se você deve usar um singleton ou criar um pool. A classe
HttpClientfoi projetada para ser compartilhada em vez de ser colocada em pool. Outros objetos podem oferecer suporte a pool, permitindo que o sistema distribua a carga de trabalho entre várias instâncias.Os objetos que você compartilha entre várias solicitações devem ser thread-safe. A classe
HttpClientfoi projetada para ser usada dessa maneira, mas outras classes podem não oferecer suporte a solicitações simultâneas, portanto, verifique a documentação disponível.Tenha cuidado ao definir propriedades em objetos compartilhados, pois isso pode levar a condições de corrida. Por exemplo, a definição
DefaultRequestHeadersna classeHttpClientantes de cada solicitação pode criar uma condição de corrida. Definir essas propriedades uma vez (por exemplo, durante a inicialização) e criar instâncias separadas, se você precisar definir configurações diferentes.Alguns tipos de recurso são escassos e não devem ser mantidos. Conexões de banco de dados são um exemplo. Manter uma conexão de banco de dados aberto que não seja necessária pode impedir que outros usuários simultâneos tenham acesso ao banco de dados.
No .NET Framework, muitos objetos estabelecem conexões com recursos externos são criados usando os métodos de fábrica estáticos de outras classes que gerenciam essas conexões. Esses objetos destinam-se a ser salvos e reutilizados, em vez de descartados e recriados. Por exemplo, no Barramento de Serviço do Azure, o objeto
QueueClienté criado por meio de um objetoMessagingFactory. Internamente, oMessagingFactorygerencia as conexões. Para saber mais informações, consulte Práticas recomendadas para melhorias de desempenho usando o Sistema de Mensagens do Barramento de Serviço.
Como detectar o antipadrão de instanciação inadequada
Sintomas desse problema incluem uma queda na taxa de transferência ou um aumento na taxa de erro, junto com um ou mais dos sintomas a seguir:
- Um aumento nas exceções que indica o esgotamento de recursos, como soquetes, conexões de banco de dados, identificadores de arquivos e assim por diante.
- Um aumento no uso de memória e na coleta de lixo.
- Um aumento na atividade de banco de dados, disco ou rede.
Você pode executar as etapas a seguir para ajudar a identificar o problema:
- Executar o monitoramento de processos do sistema de produção, para identificar os pontos onde os tempos de resposta ficam mais lentos ou onde o sistema falha devido à falta de recursos.
- Examine os dados de telemetria capturados nesses pontos para determinar quais operações podem estar criando e destruindo os objetos que consomem recursos.
- Faça o teste de carga de cada operação suspeita em um ambiente de teste controlado em vez de em um sistema de produção.
- Examine o código-fonte e examine como os objetos do agente são gerenciados.
Observe os rastreamentos de pilha para operações que são lentas ou que geram exceções quando o sistema está sob carga. Essas informações podem ajudar a identificar como essas operações estão utilizando os recursos. Exceções podem ajudar a determinar se os erros são causados por recursos compartilhados sendo esgotados.
Diagnóstico de exemplo
As seções a seguir aplicam essas etapas ao aplicativo de exemplo descrito anteriormente.
Identificar pontos de lentidão ou falha
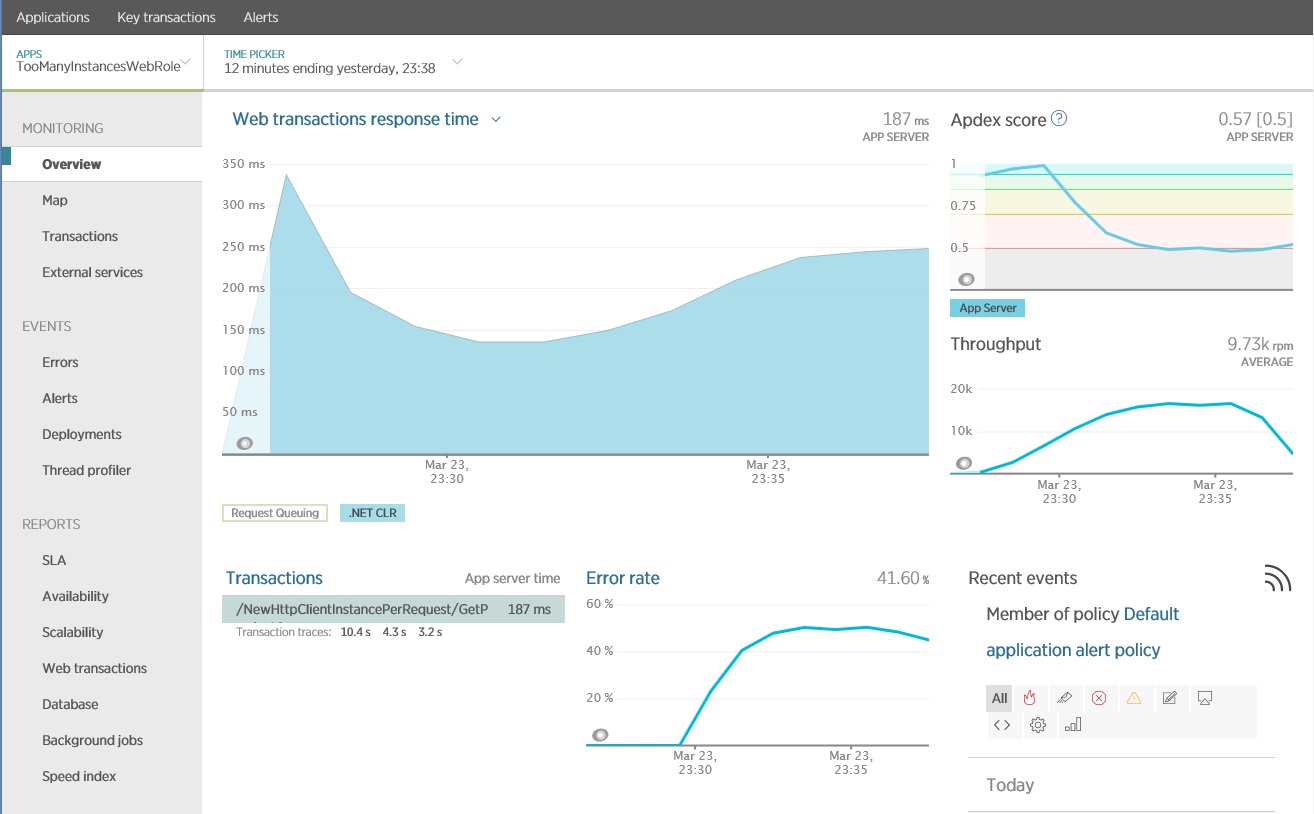
A imagem a seguir mostra os resultados gerados usando o APM (Gerenciamento de Desempenho de Aplicativos) da New Relic, mostrando também as operações que têm um tempo de resposta ruim. Nesse caso, vale a pena fazer uma investigação mais detalhada ao método GetProductAsync no controlador NewHttpClientInstancePerRequest. Observe que a taxa de erros também aumenta quando essas operações estão em execução.
Examinar os dados de telemetria e localizar correlações
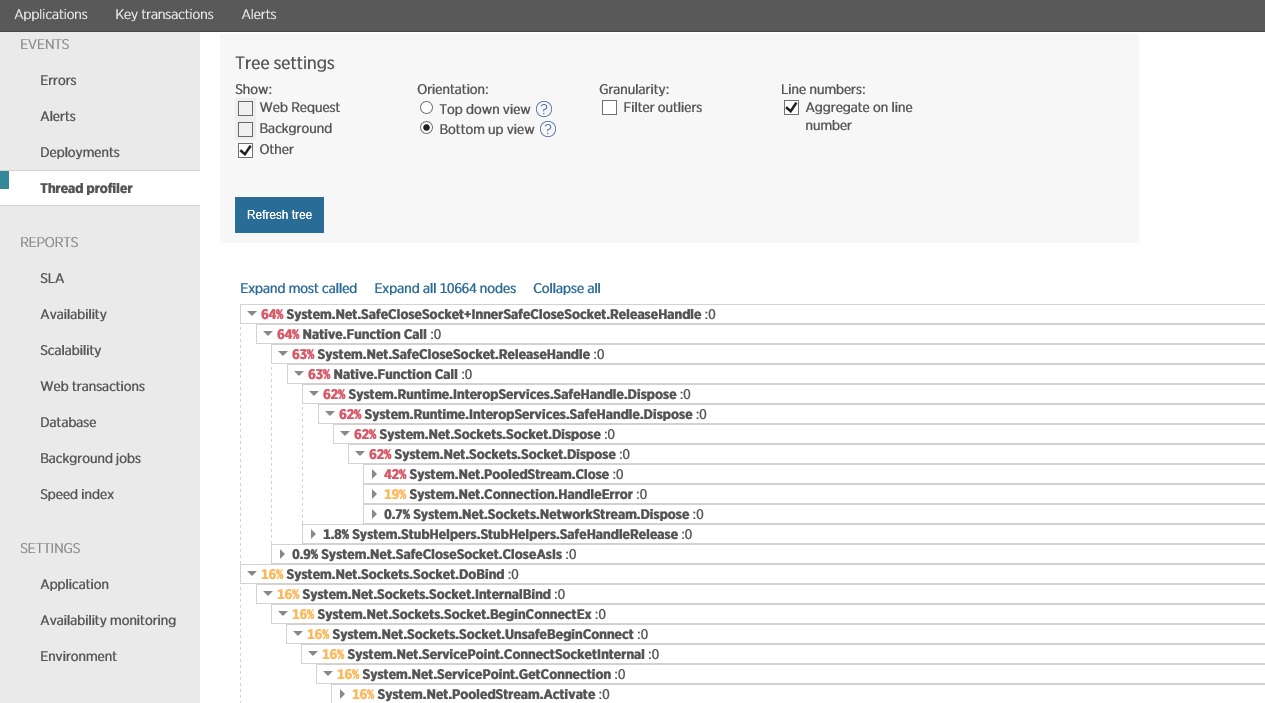
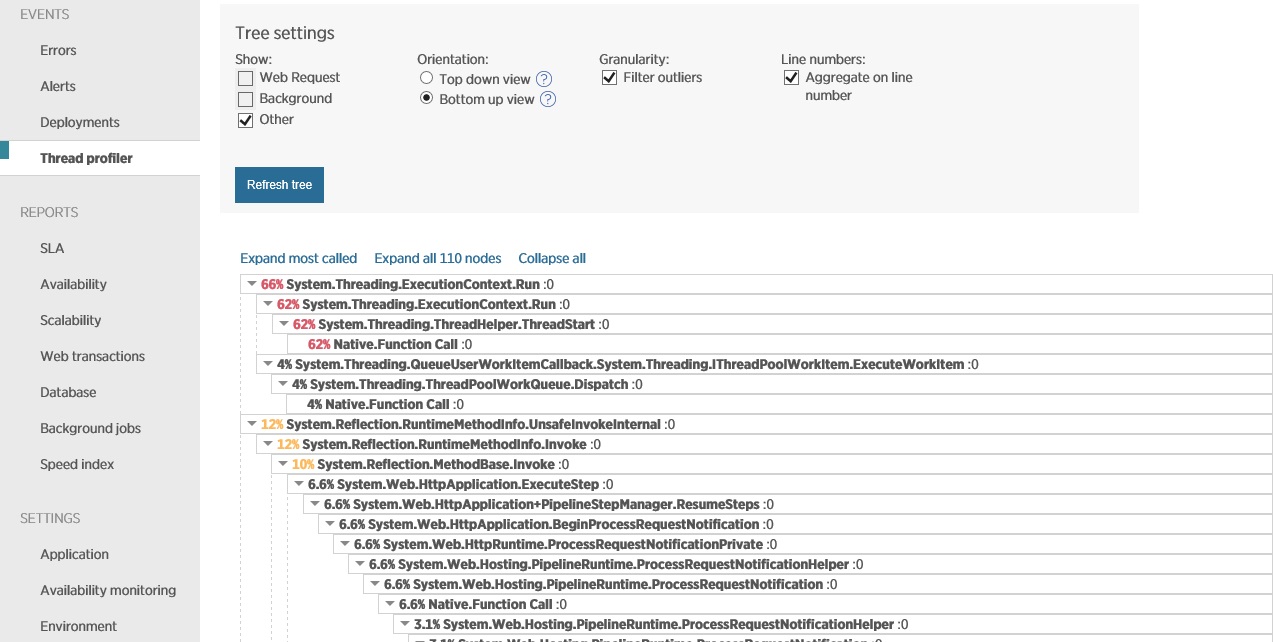
A imagem seguinte mostra os dados capturados usando a criação de perfil de thread, no mesmo período correspondente à imagem anterior. O sistema gasta um tempo significativo abrindo as conexões de soquete e ainda mais tempo fechando-as e tratando as exceções de soquete.
Executar o teste de carga
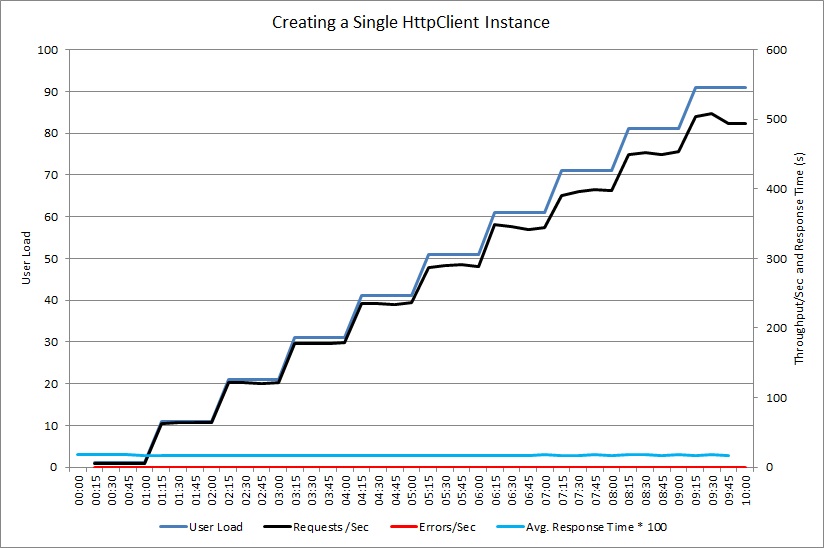
Use o teste de carga para simular as operações comuns que podem ser executadas pelos usuários. Isso pode ajudar a identificar quais partes de um sistema são afetadas por um esgotamento de recursos sob cargas diferentes. Execute esses testes em um ambiente controlado em vez de um sistema de produção. O gráfico a seguir mostra a taxa de transferência de solicitações manipulada pelo controlador NewHttpClientInstancePerRequest, já que a carga de usuários aumenta para 100 usuários simultâneos.
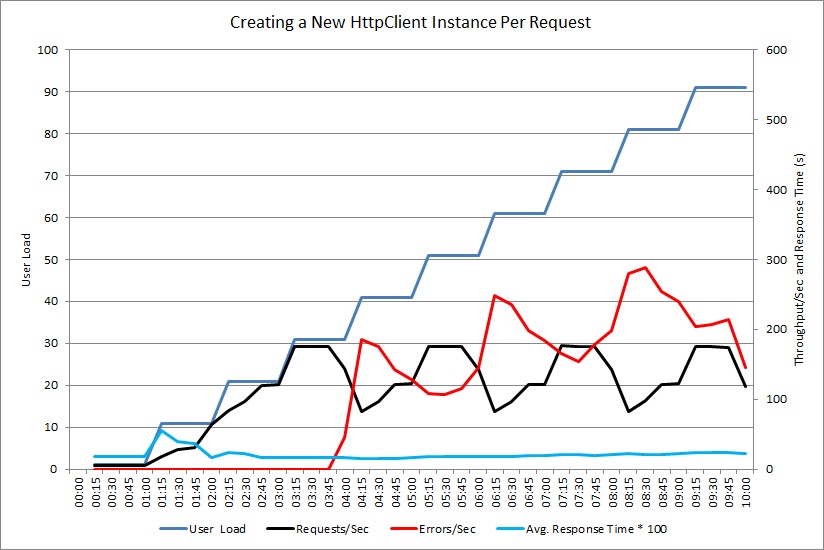
Primeiro, o volume de solicitações tratadas por segundo aumenta conforme aumenta a carga de trabalho. Depois de aproximadamente 30 usuários, no entanto, o volume de solicitações bem sucedidas atinge um limite e o sistema começa a gerar exceções. Daí em diante, o volume de exceções aumenta gradualmente junto com a carga de usuário.
O teste de carga relatou essas falhas como erros HTTP 500 (servidor interno). Uma revisão da telemetria mostrou que esses erros foram causados pela execução do sistema sem recursos de soquete, já que cada vez mais objetos HttpClient foram criados.
O gráfico seguinte mostra um teste semelhante para um controlador que cria o objeto ExpensiveToCreateService personalizado.
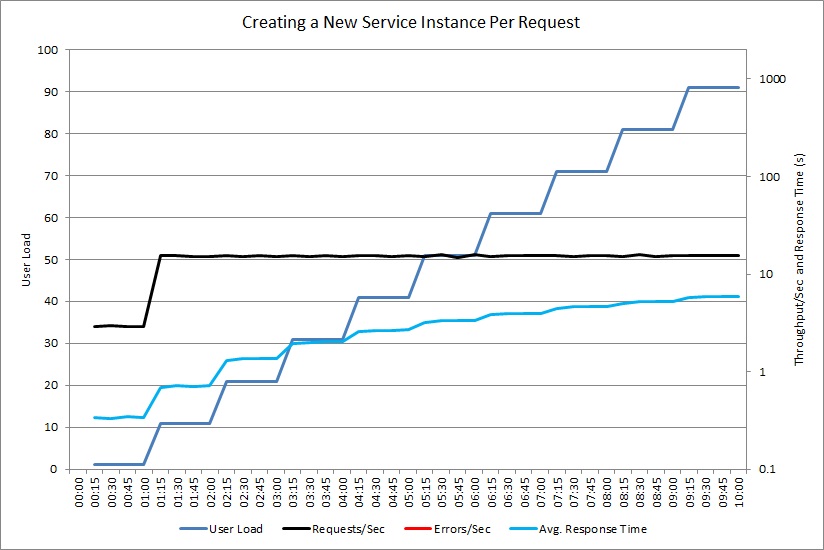
Neste momento, o controlador não gera exceções, mas a taxa de transferência ainda atinge um limite, enquanto o tempo médio de resposta aumenta em um fator de 20. (O gráfico usa uma escala logarítmica para tempo de resposta e taxa de transferência.) A telemetria mostrou que a criação de novas instâncias do ExpensiveToCreateService foi a principal causa do problema.
Implementar a solução e verificar o resultado
Depois de alternar o método GetProductAsync para compartilhar uma única instância HttpClient, um segundo teste de carga mostrou um melhor desempenho. Nenhum erro foi relatado, e o sistema foi capaz de lidar com um aumento da carga de até 500 solicitações por segundo. O tempo médio de resposta diminuiu pela metade, em comparação com o teste anterior.
Para comparação, a imagem a seguir mostra a telemetria de rastreamento de pilha. Dessa vez o sistema gasta a maior parte do tempo executando o trabalho real, em vez de abrindo e fechando soquetes.
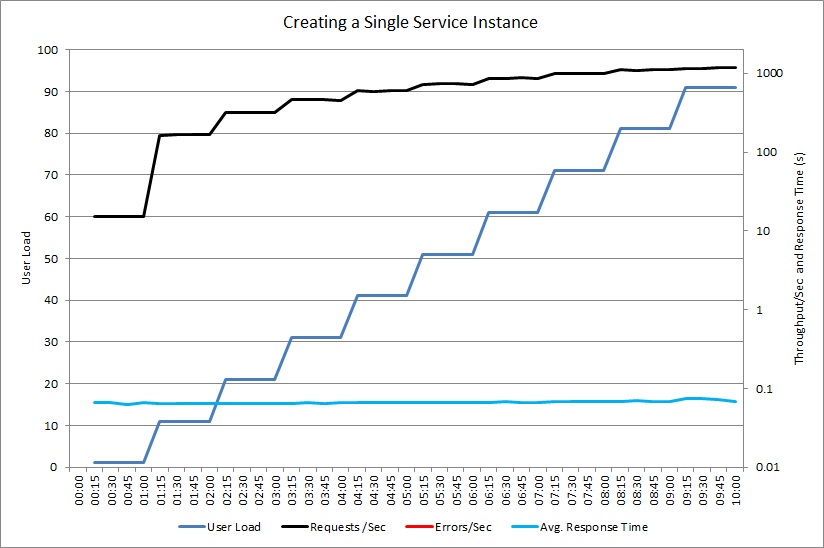
O gráfico seguinte mostra um teste de carga semelhante usando uma instância compartilhada do objeto ExpensiveToCreateService. Novamente, o volume de solicitações manipuladas aumenta junto com a carga de usuário enquanto o tempo médio de resposta permanece baixo.
Comentários
Em breve: Ao longo de 2024, eliminaremos os problemas do GitHub como o mecanismo de comentários para conteúdo e o substituiremos por um novo sistema de comentários. Para obter mais informações, consulte https://aka.ms/ContentUserFeedback.
Enviar e exibir comentários de