Antipadrão de número excessivo de novas tentativas
Quando um serviço está indisponível ou ocupado, fazer com que os clientes tentem realizar suas conexões novamente com frequência excessiva pode aumentar a dificuldade de recuperação do serviço e, como resultado, piorar o problema. Também não faz sentido tentar novamente para sempre, pois as solicitações normalmente são válidas apenas por um período definido.
Descrição do problema
Na nuvem, às vezes, os serviços enfrentam problemas e ficam indisponíveis para os clientes ou precisam impor restrições ou limitar as taxas dos clientes. Embora seja uma boa prática entre os clientes tentar realizar novamente conexões com falha aos serviços, é importante que eles não o façam com frequência excessiva ou por tempo demais. Novas tentativas realizadas em um curto período são improváveis de funcionar, já que os serviços provavelmente não terão se recuperado. Além disso, os serviços podem ser submetidos a uma carga de estresse ainda maior quando há inúmeras tentativas de conexão sendo feitas ao mesmo tempo em que eles estão tentando se recuperar. Na verdade, repetidas tentativas de conexão podem sobrecarregar o serviço ao ponto de piorar ainda mais o problema subjacente.
O exemplo a seguir ilustra um cenário em que um cliente se conecta a uma API baseada em servidor. Se a solicitação não for bem sucedida, o cliente tentará novamente de imediato e continuará tentando para sempre. Geralmente, esse tipo de comportamento é mais sutil do que neste exemplo, mas o princípio aplicado é o mesmo.
public async Task<string> GetDataFromServer()
{
while(true)
{
var result = await httpClient.GetAsync(string.Format("http://{0}:8080/api/...", hostName));
if (result.IsSuccessStatusCode) break;
}
// ... Process result.
}
Como corrigir o problema
Os aplicativos cliente devem seguir as melhores práticas do mercado para evitar gerar um número excessivo de novas tentativas.
- Limite o número de novas tentativas e não mantenha esse comportamento por um período muito longo. Embora possa parecer simples escrever um loop
while(true), certamente não fará sentido seguir tentando novamente por um longo período, já que a situação que levou à solicitação que está sendo iniciada provavelmente mudou. Na maioria dos aplicativos, tentar novamente por alguns segundos ou minutos é suficiente. - Faça uma pausa entre cada nova tentativa. Se um serviço está indisponível, é improvável que ele funcione se você tentar novamente de imediato. Aumente gradualmente a quantidade de tempo esperada entre as novas tentativas, por exemplo, usando uma estratégia de retirada exponencial.
- Gerencie os erros com naturalidade. Se o serviço não estiver respondendo, considere a possibilidade de anular a tentativa e retornar um erro para o usuário ou o chamador do componente. Leve em conta esses cenários de falha ao projetar seu aplicativo.
- Considere a possibilidade de usar o padrão Disjuntor, que foi projetado especificamente para ajudar a evitar números excessivos de novas tentativas.
- Se o servidor fornecer um cabeçalho de resposta
retry-after, não tente novamente até que o período especificado tenha decorrido. - Use SDKs oficiais ao se comunicar com os serviços do Azure. Esses SDKs geralmente têm políticas e proteções internas para tentar novamente que impedem a geração ou a contribuição para o problema de número excessivo de novas tentativas. Se você estiver se comunicando com um serviço que não tem um SDK ou em que o SDK não gerencia corretamente a lógica de tentar novamente, considere a possibilidade de usar uma biblioteca como a Polly (para .NET) ou a Retry (para JavaScript) a fim de gerenciar corretamente sua lógica de tentar novamente e evitar escrever o código por conta própria.
- Se o ambiente de execução for compatível com a malha de serviço (ou outra camada de abstração), use-a para enviar chamadas de saída. Normalmente, essas ferramentas, como a Dapr, são compatíveis com as políticas de repetição e seguem de modo automático as práticas recomendadas, como interromper o processo após algumas tentativas repetidas. Essa abordagem significa que você não precisa escrever o código de repetição.
- Considere a possibilidade de realizar solicitações em lote e de usar um pool de solicitações, sempre que disponível. Muitos SDKs gerenciam para você as solicitações em lote e o pool de conexões, o que reduz o número total de tentativas de conexão de saída que seu aplicativo faz, embora você ainda precise ter cuidado para não tentar realizar essas conexões novamente com frequência excessiva.
Os serviços também devem se proteger contra o problema de número excessivo de novas tentativas.
- Adicione uma camada de gateway para que você possa desativar as conexões durante um incidente. Este é um exemplo do padrão bulkhead. O Azure fornece vários serviços de gateway distintos para diferentes tipos de soluções, incluindo o Front Door, o Gateway de Aplicativo e o Gerenciamento de API.
- Limite as solicitações no gateway para que não seja possível aceitar tantas solicitações que os componentes de back-end não consigam seguir operando normalmente.
- Se você estiver aplicando um limite, envie um cabeçalho
retry-afterpara ajudar os clientes a entender quando tentar novamente a conexão.
Considerações
- Os clientes devem considerar o tipo de erro retornado. Alguns tipos de erro não indicam falha do serviço, mas sim que o cliente enviou uma solicitação inválida. Por exemplo, se um aplicativo cliente receber uma resposta de erro
400 Bad Request, tentar novamente a mesma solicitação provavelmente não ajudará, pois o servidor está informando que a solicitação não é válida. - Os clientes devem ponderar sobre o período que faz sentido tentar novamente as conexões. O período que você deve tentar novamente será orientado pelos seus requisitos de negócios e se você pode, de maneira razoável, propagar um erro de volta para um usuário ou chamador. Na maioria dos aplicativos, tentar novamente por alguns segundos ou minutos é suficiente.
Como detectar o problema
Da perspectiva do cliente, os sintomas que indicam esse problema são, dentre outros, tempo de processamento ou de resposta muito longo, juntamente com uma telemetria que indique tentativas recorrentes de refazer a conexão.
Da perspectiva de um serviço, os sintomas que indicam esse problema são, dentre outros, um grande número de solicitações do mesmo cliente em um curto período ou um grande número de solicitações de apenas um cliente durante a recuperação de interrupções. Os sintomas também podem incluir dificuldades ao recuperar o serviço ou falhas contínuas em cascata do serviço, logo após uma falha ter sido reparada.
Diagnóstico de exemplo
As seções a seguir ilustram uma abordagem para detectar um possível número excessivo de novas tentativas de conexão, tanto no lado do cliente quanto no lado do serviço.
Identificação com base na telemetria do cliente
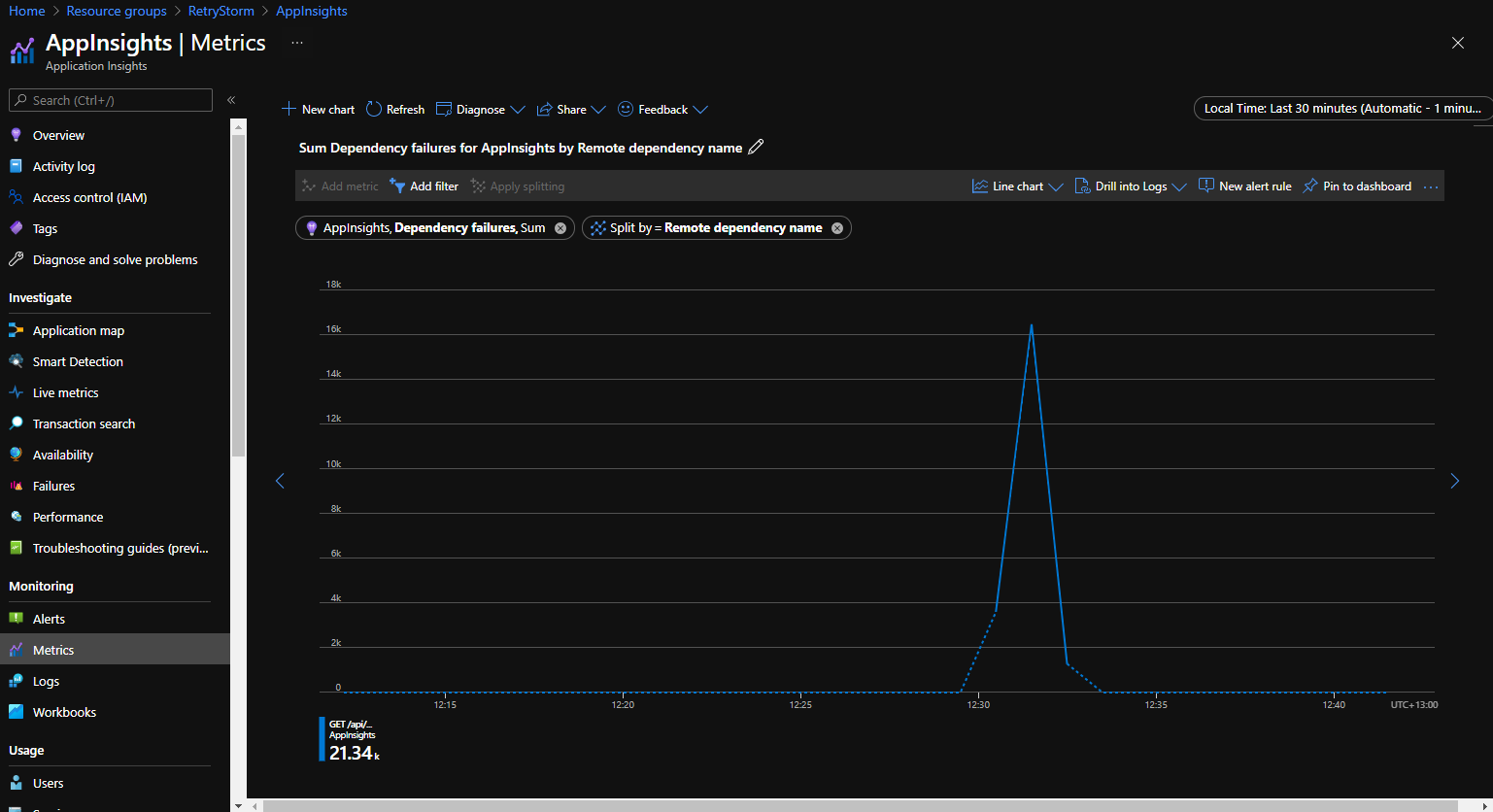
O Azure Application Insights registra a telemetria dos aplicativos e disponibiliza os dados para consulta e visualização. As conexões de saída são controladas como dependências e as informações sobre elas podem ser acessadas e modeladas para identificar quando um cliente está fazendo um grande número de solicitações de saída para o mesmo serviço.
O grafo a seguir foi extraído da guia Métricas do portal do Application Insights e a exibição da métrica de Falhas de dependência dividida por Nome da dependência remota. Isso ilustra um cenário em que havia um grande número de tentativas de conexão com falha (mais de 21.000) para uma dependência dentro de um curto período.
Identificação com base na telemetria do servidor
Os aplicativos de servidor podem ser capazes de detectar grandes números de conexões do mesmo cliente. No exemplo a seguir, o Azure Front Door atua como um gateway de aplicativo e foi configurado para registrar todas as solicitações em um workspace do Log Analytics.
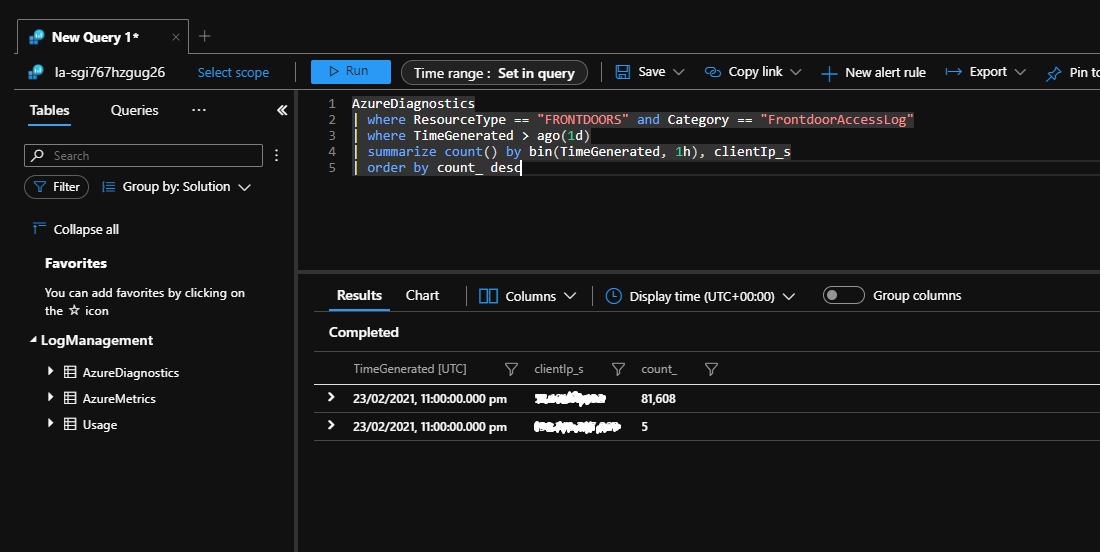
A consulta Kusto a seguir pode ser executada no Log Analytics. Ela identificará os endereços IP do cliente que enviaram grandes números de solicitações ao aplicativo no dia anterior.
AzureDiagnostics
| where ResourceType == "FRONTDOORS" and Category == "FrontdoorAccessLog"
| where TimeGenerated > ago(1d)
| summarize count() by bin(TimeGenerated, 1h), clientIp_s
| order by count_ desc
A execução dessa consulta durante uma falha de número excessivo de novas tentativas mostra um grande número de tentativas de conexão vindas do mesmo endereço IP.
Recursos relacionados
Comentários
Em breve: Ao longo de 2024, eliminaremos os problemas do GitHub como o mecanismo de comentários para conteúdo e o substituiremos por um novo sistema de comentários. Para obter mais informações, consulte https://aka.ms/ContentUserFeedback.
Enviar e exibir comentários de