O sucesso da sua solução de nuvem depende da confiabilidade dela. Confiabilidade pode ser definida amplamente como a probabilidade de o sistema funcionar conforme o esperado, nas condições de ambiente especificadas, dentro de período especificado. A SRE (Engenharia de confiabilidade de sites) é um conjunto de princípios e práticas para a criação de sistemas de software altamente confiáveis e escalonáveis. Cada vez mais, a SRE é usada no design de serviços digitais para garantir maior confiabilidade.
Para obter mais informações sobre as estratégias de SRE, confira AZ-400: Desenvolver uma estratégia de SRE (Engenharia de confiabilidade de sites).
Possíveis casos de uso
Os conceitos neste artigo aplicam-se a:
- Serviços de nuvem baseados em API.
- Aplicativos Web voltados para o público.
- Cargas de trabalho baseadas em IoT ou em eventos.
Arquitetura

Baixe um arquivo do PowerPoint dessa arquitetura.
A arquitetura considerada aqui é a de uma plataforma de API escalonável. A solução é composta por vários microsserviços que usam uma variedade de bancos de dados e serviços de armazenamento, incluindo soluções de SaaS (software como serviço) como o Dynamics 365 e o Microsoft 365.
Este artigo considera uma solução que lida com casos de uso de mercado de alto nível e de comércio eletrônico para demonstrar os blocos mostrados no diagrama. Os casos de uso são:
- Procura de produtos.
- Registro e logon.
- Exibição de conteúdo, como artigos de notícias.
- Gerenciamento de pedidos e assinatura.
Aplicativos cliente, como aplicativos Web, aplicativos móveis e até mesmo aplicativos de serviço, consomem os serviços da plataforma de API por meio de um caminho de acesso unificado, https://api.contoso.com.
Componentes
- O Azure Front Door fornece um ponto de entrada seguro e unificado para todas as solicitações para a solução. Para obter mais informações, consulte Visão geral da arquitetura de roteamento.
- O Gerenciamento de API do Azure fornece uma camada de governança sobre todas as APIs publicadas. Use as políticas do Gerenciamento de API do Azure para aplicar recursos adicionais à camada da API, como restrições de acesso, cache e transformação de dados. O Gerenciamento de API dá suporte ao dimensionamento automático nas camadas Standard e Premium.
- O AKS (Serviço de Kubernetes do Azure) é a implementação do Azure de clusters do Kubernetes de código aberto. Como um serviço de Kubernetes hospedado, o Azure lida com tarefas críticas como o monitoramento de integridade e a manutenção. Como os mestres do Kubernetes são gerenciados pelo Azure, você só gerencia e mantém os nós de agente. Nessa arquitetura, todos os microsserviços são implantados no AKS.
- O Gateway de Aplicativo do Azure é um serviço de controlador de entrega de aplicativos. Ele opera na camada 7, a camada de aplicativo, e tem vários recursos de balanceamento de carga. O AGIC (Controlador de Entrada do Gateway de Aplicativo) é um aplicativo Kubernetes que possibilita aos clientes do AKS (Serviço de Kubernetes do Azure) usar o balanceador de carga L7 do Gateway de Aplicativo nativo do Azure para expor o software de nuvem à Internet. Há suporte para o dimensionamento automático e a redundância de zona no SKU v2.
- O Armazenamento do Microsoft Azure, o Azure Data Lake Storage, o Azure Cosmos DB e o SQL do Azure podem armazenar conteúdo estruturado e não estruturado. Os contêineres e bancos de dados do Azure Cosmos DB podem ser criados com taxa de transferência de dimensionamento automático.
- O Microsoft Dynamics 365 é uma oferta de SaaS (software como serviço) da Microsoft que fornece vários aplicativos de negócios para atendimento ao cliente, vendas, marketing e finanças. Nessa arquitetura, o Dynamics 365 é usado principalmente para gerenciar catálogos de produtos e o atendimento ao cliente. As unidades de escala fornecem resiliência aos aplicativos do Dynamics 365.
- O Microsoft 365 (anteriormente, Office 365) é usado como um sistema de gerenciamento de conteúdo empresarial criado no Office 365 SharePoint Online. Ele é usado para criar, gerenciar e publicar conteúdo, como ativos de mídia e documentos.
Alternativas
Como essa solução usa uma arquitetura baseada em microsserviços altamente escalonável, considere estas alternativas para o plano de computação:
- Azure Functions para serviços de API sem servidor
- Azure Spring Apps para microsserviços baseados em Java
Confiabilidade adequada
O grau de confiabilidade necessário para uma solução depende do contexto de negócios. Uma loja de outlet de varejo que fica aberta por 14 horas e cujo pico de uso do sistema ocorre dentro desse período tem requisitos diferentes de uma empresa online que aceita pedidos em todas as horas. As práticas de SRE podem ser ajustadas para alcançar o nível adequado de confiabilidade.
A confiabilidade é definida e medida usando SLOs (objetivos de nível de serviço), que definem o nível de destino de confiabilidade para um serviço. Atingir o nível de destino garante que os consumidores fiquem satisfeitos. As metas de SLO podem evoluir ou mudar dependendo das demandas da empresa. No entanto, os proprietários do serviço devem medir constantemente a confiabilidade em relação aos SLOs para detectar problemas e adotar ações corretivas. Normalmente, os SLOs são definidos como um percentual de conquista ao longo de um período.
Outro termo importante a ser observado é o SLI (indicador de nível de serviço), que é a métrica usada para calcular o SLO. Os SLIs são baseados em insights derivados dos dados capturados conforme o cliente consome o serviço. Os SLIs sempre são medidos do ponto de vista de um cliente.
Os SLOs e SLIs sempre caminham juntos e normalmente são definidos de maneira iterativa. Os SLOs são orientados pelos principais objetivos de negócios, enquanto os SLIs são orientados por aquilo que é possível medir durante a implementação do serviço.
A relação entre a métrica monitorada, o SLI e o SLO é descrita abaixo:
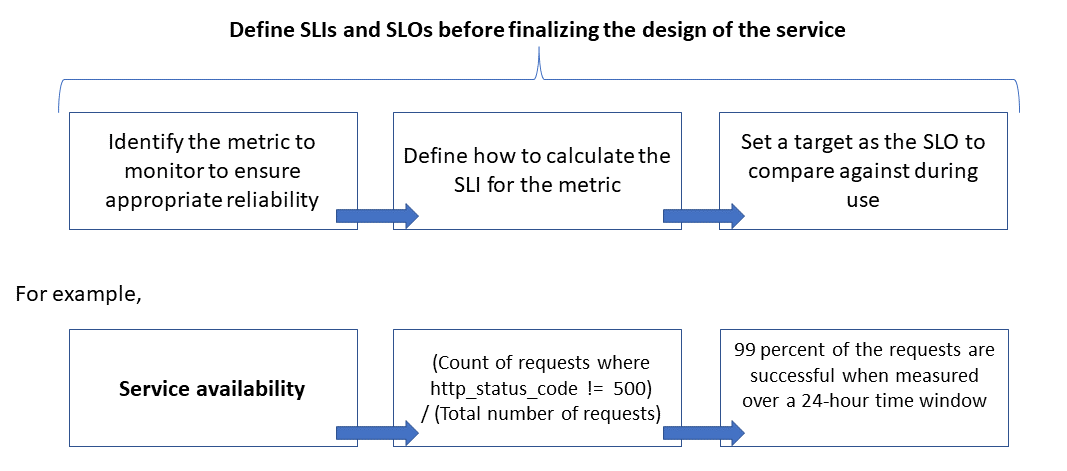
Isso é explicado em mais detalhes em Definir métricas de SLI para calcular SLOs.
Escala de modelagem e expectativas de desempenho
Para um sistema de software, desempenho geralmente se refere à capacidade de resposta geral do sistema ao executar uma ação dentro de um período especificado, enquanto escalabilidade é a capacidade do sistema de lidar com cargas de usuário maiores sem prejudicar o desempenho.
Um sistema será considerado escalonável se os recursos subjacentes forem disponibilizados de modo dinâmico para dar suporte a um aumento na carga. Aplicativos de nuvem devem ser projetados para ter escala, e às vezes é difícil prever o volume de tráfego. Picos sazonais podem aumentar os requisitos de escala, especialmente quando um serviço lida com solicitações para vários locatários.
É uma boa prática projetar os aplicativos de modo que os recursos de nuvem sejam escalados e reduzidos verticalmente de maneira automática conforme necessário para atender à carga. Basicamente, o sistema deve se adaptar ao aumento da carga de trabalho provisionando ou alocando recursos de maneira incremental para atender à demanda. A escalabilidade refere-se não apenas às instâncias de computação, mas também a outros elementos como armazenamento de dados e infraestrutura de mensagens.
Este artigo mostra como você pode garantir a confiabilidade adequada para um aplicativo de nuvem realizando a modelagem de escala e desempenho dos cenários de carga de trabalho e usando os resultados para definir os monitores, SLIs e SLOs.
Considerações
Confira os pilares de Confiabilidade e Eficiência de desempenho da Azure Well Architected Framework para obter diretrizes sobre a criação de aplicativos escalonáveis e confiáveis.
Este artigo explora como aplicar técnicas de modelagem de escalabilidade e desempenho para ajustar o design e a arquitetura da solução. Essas técnicas identificam alterações nos fluxos de transações para chegar a uma experiência de usuário ideal. Baseie suas decisões técnicas nos requisitos não funcionais da solução. O processo é:
- Identificar os requisitos de escalabilidade.
- Modelar a carga esperada.
- Definir os SLIs e SLOs para os cenários de usuário.
Observação
O Azure Application Insights, parte do Azure Monitor, é uma ferramenta avançada de APM (gerenciamento de desempenho de aplicativos) que você pode integrar facilmente aos seus aplicativos para enviar telemetria e analisar métricas específicas do aplicativo. Ele também fornece painéis prontos para uso e o Metrics Explorer, que você pode usar para analisar os dados a fim de explorar as necessidades de negócios.
Capturar os requisitos de escalabilidade
Suponha que essas sejam as métricas de carga de pico:
- Número de consumidores que usam a Plataforma de API: 1,5 milhão
- Consumidores ativos por hora (30% de 1,5 milhão): 450.000
- Percentual de carga para cada atividade:
- Procura de produtos: 75%
- Registro, incluindo criação de perfil e logon: 10%
- Gerenciamento de pedidos e assinaturas: 10%
- Exibição de conteúdo: 5%
A carga produz os seguintes requisitos de escala, sob carga de pico normal, para as APIs hospedadas pela plataforma:
- Microsserviço de produto: cerca de 500 RPS (solicitações por segundo)
- Microsserviço de perfil: cerca de 100 RPS
- Microsserviço de pedidos e pagamentos: cerca de 100 RPS
- Microsserviço de conteúdo: cerca de 50 RPS
Esses requisitos de escala não levam em consideração picos sazonais e aleatórios, nem picos durante eventos especiais, como campanhas de marketing. Durante picos, o requisito de escala de algumas atividades do usuário é de até 10 vezes a carga de pico normal. Tenha essas restrições e expectativas em mente ao fazer as escolhas de design para os microsserviços.
Definir métricas de SLI para calcular SLOs
As métricas de SLI indicam o grau em que um serviço fornece uma experiência satisfatória e podem ser expressas como a proporção entre bons eventos e o total de eventos.
Para um serviço de API, eventos referem-se às métricas específicas do aplicativo que são capturadas durante a execução como dados telemétricos ou processados. Este exemplo tem as seguintes métricas de SLI:
| Métrica | Description |
|---|---|
| Disponibilidade | Se a solicitação foi atendida pela API |
| Latency | Tempo para a API processar a solicitação e retornar uma resposta |
| Produtividade | Número de solicitações que a API tratou |
| Taxa de êxito | Número de solicitações que a API tratou com êxito |
| Taxa de erros | Número de erros para as solicitações que a API tratou |
| Atualização | Número de vezes que o usuário recebeu os dados mais recentes para operações de leitura na API, apesar de o armazenamento de dados subjacente ser atualizado com uma determinada latência de gravação |
Observação
Identifique os SLIs adicionais que forem importantes para sua solução.
Estes são exemplos de SLIs:
- (Número de solicitações concluídas com êxito em menos de 1.000 ms) / (Número de solicitações)
- (Número de resultados da pesquisa que retornam, em até três segundos, produtos publicados no catálogo) / (Número de pesquisas)
Depois de definir os SLIs, determine quais eventos ou dados telemétricos capturar para medi-los. Por exemplo, para medir a disponibilidade, você captura eventos para indicar se o serviço da API processou uma solicitação com êxito. Para serviços baseados em HTTP, os casos de êxito ou falha são indicados com códigos de status HTTP. O design e a implementação da API devem fornecer os códigos apropriados. Em geral, as métricas de SLI são uma entrada importante para a implementação da API.
Para sistemas baseados em nuvem, você pode obter algumas das métricas usando o suporte para diagnóstico e monitoramento disponível para os recursos. O Azure Monitor é uma solução abrangente para coleta, análise e ação com base na telemetria dos seus serviços de nuvem. Dependendo dos requisitos de SLI, mais dados de monitoramento podem ser capturados para calcular as métricas.
Usar distribuições de percentil
Alguns SLIs são calculados usando uma técnica de distribuição de percentil. Isso traz melhores resultados quando há exceções que podem distorcer outras técnicas, como distribuições médias ou medianas.
Por exemplo, considere que a métrica é a latência das solicitações à API e três segundos é o limite para o desempenho ideal. Os tempos de resposta classificados para uma hora de solicitações à API mostram que poucas solicitações levam mais de três segundos e a maioria delas recebe respostas dentro do limite. Esse é o comportamento esperado do sistema.
A distribuição de percentil deve excluir as exceções causadas por problemas intermitentes. Por exemplo, se as respostas de serviço apropriadas estão no 90º ou no 95º percentil, considera-se que o SLO foi atendido.
Escolher períodos de medição adequados
O período de medição para definir um SLO é muito importante. Ele deve capturar a atividade, e não a ociosidade, para que os resultados sejam significativos para a experiência do usuário. Essa janela pode ser de cinco minutos a 24 horas, dependendo de como você deseja monitorar e calcular a métrica de SLI.
Estabelecer um processo de governança de desempenho
O desempenho de uma API deve ser gerenciado desde sua criação até que ela seja preterida ou desativada. Um processo de governança robusto deve estar em vigor para garantir que problemas de desempenho sejam detectados e corrigidos no início, antes que causem uma grande interrupção que afete os negócios.
Estes são os elementos da governança de desempenho:
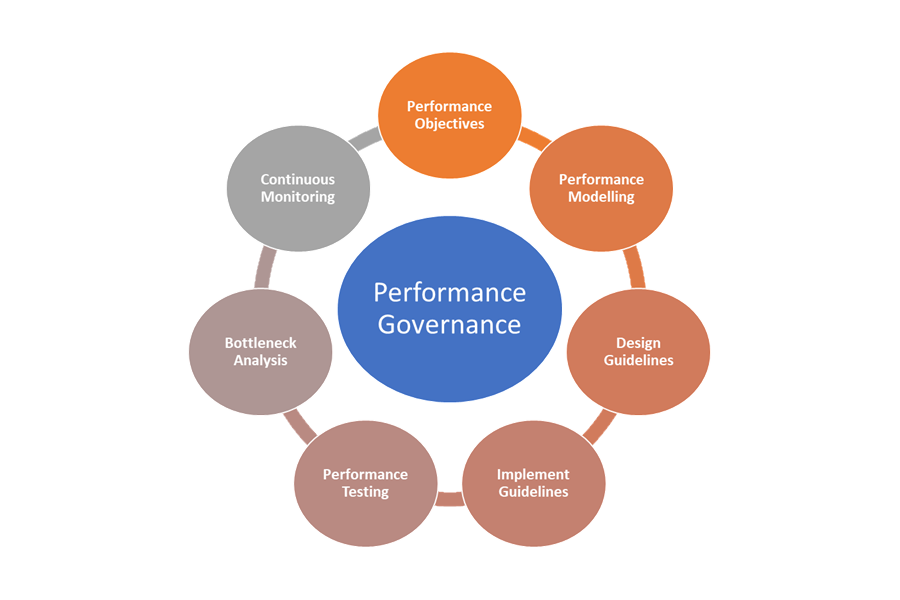
- Objetivos de desempenho: defina os SLOs de desempenho desejados para os cenários de negócios.
- Modelagem de desempenho: identifique fluxos de trabalho e transações comercialmente críticos e conduza a modelagem para entender as implicações relacionadas ao desempenho. Capture essas informações no nível granular para obter previsões mais precisas.
- Diretrizes de design: prepare as diretrizes de design de desempenho e recomende as modificações de fluxo de trabalho de negócios adequadas. Certifique-se de que as equipes entendam essas diretrizes.
- Implementar as diretrizes: implemente diretrizes de design de desempenho para os componentes da solução, incluindo a instrumentação para capturar métricas. Realize revisões do design de desempenho. É essencial acompanhar tudo isso usando os itens da lista de pendências do produto de arquitetura para as diferentes equipes.
- Teste de desempenho: conduza testes de carga e estresse de acordo com a distribuição do perfil de carga para capturar as métricas relacionadas à integridade da plataforma. Você também pode realizar esses testes para uma carga limitada para estabelecer o parâmetro de comparação dos requisitos de infraestrutura da solução.
- Análise de gargalo: use a inspeção de código e revisões de código para identificar, analisar e remover gargalos de desempenho em vários componentes. Identifique os aprimoramentos no dimensionamento horizontal ou vertical necessários para dar suporte às cargas de pico.
- Monitoramento contínuo: estabeleça uma infraestrutura de monitoramento e alerta contínuos como parte dos processos de DevOps. Certifique-se de que as equipes em questão sejam notificadas quando os tempos de resposta apresentarem uma degradação significativa em relação aos parâmetros de comparação.
- Governança de desempenho: estabeleça uma governança de desempenho composta por processos e equipes bem definidos para sustentar os SLOs de desempenho. Acompanhe a conformidade após cada versão para evitar qualquer degradação decorrente de atualizações de build. Faça revisões periodicamente para avaliar qualquer aumento de carga e identificar atualizações de solução.
Repita as etapas ao longo do desenvolvimento da solução como parte do processo progressivo de elaboração.
Acompanhar os objetivos as expectativas de desempenho na lista de pendências
Acompanhe os objetivos de desempenho para ajudar a garantir que eles sejam atingidos. Capture histórias de usuário granulares e detalhadas para acompanhamento. Isso ajudará a garantir que as equipes de desenvolvimento confiram às atividades de governança de desempenho uma prioridade alta.
Estabelecer os SLOs desejados para a solução de destino
Estes são exemplos de SLOs desejados para a solução de plataforma de API em consideração:
- Responde dentro de um segundo a 95% de todas as solicitações READ durante um dia.
- Responde dentro de três segundos a 95% de todas as solicitações CREATE e UPDATE durante um dia.
- Responde dentro de cinco segundos e sem falhas a 99% de todas as solicitações durante um dia.
- Responde com êxito e em cinco minutos a 99,9% de todas as solicitações durante um dia.
- Menos de 1% das solicitações durante a janela de uma hora de pico apresentam erro.
Os SLOs podem ser adaptados para atender a requisitos específicos do aplicativo. No entanto, é essencial que eles sejam granulares o suficiente para proporcionar clareza e garantir a confiabilidade.
Medir os SLOs iniciais baseados nos dados dos logs
Os logs de monitoramento são criados automaticamente quando o serviço de API está em uso. Suponha que uma semana de dados mostre o seguinte:
- Solicitações: 123.456
- Solicitações bem sucedidas: 123.204
- Latência no 90º percentil: 497 ms
- Latência no 95º percentil: 870 ms
- Latência no 99º percentil: 1.024 ms
Esses dados produzem os seguintes SLIs iniciais:
- Disponibilidade = (123.204 /123.456) = 99,8%
- Latência = pelo menos 90% das solicitações foram atendidas dentro de 500 ms
- Latência = cerca de 98% das solicitações foram atendidas dentro de 1000 ms
Suponha que, durante o planejamento, o SLO de latência de destino desejado seja que 90% das solicitações sejam processadas em 500 ms com uma taxa de êxito de 99% em um período de uma semana. Com os dados de log, você pode identificar facilmente se o SLO de destino foi atendido. Se fizer esse tipo de análise por algumas semanas, você começará a ver as tendências em torno da conformidade do SLO.
Diretrizes para mitigação de risco técnico
Use a seguinte lista de verificação de práticas recomendadas para reduzir os riscos de escalabilidade e desempenho:
- Projetar em prol da escala e do desempenho.
- Certifique-se de capturar os requisitos de escala de cada cenário de usuário e carga de trabalho, incluindo sazonalidade e picos.
- Faça a modelagem de desempenho para identificar restrições e gargalos do sistema
- Gerenciar o débito técnico.
- Faça um rastreamento amplo das métricas de desempenho.
- Considere usar scripts para executar ferramentas como K6.io, Karate e JMeter em seu ambiente de preparo de desenvolvimento com uma variedade de cargas de usuário — de 50 a 100 RPS, por exemplo. Isso fornecerá informações nos logs para detectar problemas de design e implementação.
- Integre os scripts de teste automatizado como parte dos processos de CD (implantação contínua) para detectar interrupções na compilação.
- Tenha uma mentalidade de produção.
- Ajuste os limites do dimensionamento automático conforme indicado pelas estatísticas de integridade.
- Prefira técnicas de dimensionamento horizontal ao vertical.
- Seja proativo com relação ao dimensionamento para lidar com a sazonalidade.
- Prefira a implantação baseada em anel.
- Use orçamentos de erro para fazer experimentos.
Preços
A confiabilidade, a eficiência de desempenho e a otimização de custos andam juntas. Os serviços do Azure usados na arquitetura ajudam a reduzir os custos, pois são dimensionados automaticamente para acomodar as mudanças nas cargas de usuário.
Para o AKS, você pode começar com VMs de tamanho padrão para o pool de nós. Depois, você pode monitorar os requisitos dos recursos durante o uso no desenvolvimento ou na produção e ajustar conforme necessário.
A otimização de custo é um pilar da Microsoft Azure Well-Architected Framework. Para obter mais informações, confira Visão geral do pilar de otimização de custo. Para estimar o custo de produtos e configurações do Azure, use a Calculadora de preços.
Colaboradores
Esse artigo é mantido pela Microsoft. Ele foi originalmente escrito pelos colaboradores a seguir.
Autor principal:
- Subhajit Chatterjee - Brasil | Engenheiro de Software Principal
Próximas etapas
- Documentação do Azure
- Estrutura Bem Projetada do Microsoft Azure
- Estilo de arquitetura de microsserviços
- Design para escalar horizontalmente
- Escolha um serviço de computação do Azure para seu aplicativo
- Padrões de design e implementação
- Arquitetura de microsserviços no Serviço de Kubernetes do Azure
- O que é o Azure Front Door?
- Sobre o Gerenciamento de API
- O que são controladores de entrada do Gateway de Aplicativo?
- Serviço de Kubernetes do Azure
- Dimensionamento automático e Gateway de Aplicativo com redundância de zona v2
- Escalar automaticamente um cluster para atender às demandas do aplicativo no AKS (Serviço de Kubernetes do Azure)
- Criar contêineres e bancos de dados do Azure Cosmos DB com a taxa de transferência de dimensionamento automático
- Documentação do Microsoft Dynamics 365
- Documentação do Microsoft 365
- Documentação da engenharia de confiabilidade de sites
- AZ-400: desenvolver uma estratégia de SRE (Engenharia de Confiabilidade de Site)