Este artigo descreve uma abordagem alternativa para os projetos de data warehouse que são chamados de EDA (análise de dados exploratórios). Essa abordagem pode reduzir os desafios de operações de ETL (extração, transformação, carregamento). Ele se concentra primeiro em gerar insights de negócios e, em seguida, a resolver as tarefas de modelagem e ETL.
Arquitetura

Baixe um Arquivo Visio dessa arquitetura.
Para a EDA, você está preocupado apenas com o lado direito do diagrama. O SQL sem servidor do Azure Synapse é usado como o mecanismo de computação nos arquivos do data lake.
Para realizar a EDA:
- As consultas T-SQL são executadas diretamente no SQL sem servidor do Azure Synapse ou no Azure Synapse Spark.
- As consultas são executadas de uma ferramenta de consulta gráfica como Power BI ou Azure Data Studio.
Recomendamos que você persista todos os dados do lakehouse usando Parquet ou Delta.
Você pode implementar o lado esquerdo do diagrama (ingestão de dados) usando qualquer ferramenta de extração, carregamento, transformação (ELT). Ele não tem nenhum efeito sobre a EDA.
Componentes
O Azure Synapse Analytics combina integração de dados, data warehouse corporativo e análise de Big Data sobre dados do lakehouse. Nesta solução:
- Um espaço de trabalho do Azure Synapse promove a colaboração entre engenheiros de dados, cientistas de dados, analistas de dados e profissionais de BI (business intelligence) para tarefas de EDA.
- Os pools de SQL sem servidor do Azure Synapse analisam os dados não estruturados e semiestruturados no Azure Data Lake Storage usando o T-SQL padrão.
- Os pools de Apache Spark sem servidor do Azure Synapse fazem explorações do Code First no Data Lake Storage usando as linguagens do Spark, como Spark SQL, PySpark e Scala.
O Azure Data Lake Storage fornece armazenamento para dados que são analisados por pools de SQL sem servidor do Azure Synapse.
O Azure Machine Learning fornece dados para o Azure Synapse Spark.
O Power BI é usado nesta solução para consultar dados para realizar a EDA.
Alternativas
É possível substituir ou complementar o pools de SQL sem servidor do Synapse com o Azure Databricks.
Em vez de usar um modelo lakehouse com pools de SQL sem servidor do Synapse, é possível usar pools de SQL dedicados do Azure Synapse para armazenar dados corporativos. Examine os casos de uso e as considerações neste artigo e os recursos relacionados para decidir qual tecnologia usar.
Detalhes do cenário
Esta solução mostra uma implementação da abordagem EDA para projetos de data warehouse. Essa abordagem pode reduzir os desafios das operações de ETL. Ele se concentra primeiro em gerar insights de negócios e, em seguida, a resolver as tarefas de modelagem e ETL.
Possíveis casos de uso
Outros cenários que podem se beneficiar desse padrão de análise:
Análise prescritiva. Fazer perguntas sobre seus dados, como a próxima melhor açãoou o que fazemos em seguida? Use dados para ser mais controlados por dados e menos controlados pelo instinto. Os dados podem ser não estruturados e de muitas fontes externas de qualidade variável. Talvez você queira usar os dados o mais rápido possível para avaliar sua estratégia de negócios sem realmente carregar os dados em um data warehouse. Você pode descartar os dados depois de responder suas perguntas.
ETL de autoatendimento. Faça o ETL/ELT ao fazer suas atividades de EDA (área restrita de dados). Transforme os dados e torne-os valiosos. Isso pode melhorar a escala dos seus desenvolvedores de ETL.
Sobre análise exploratória de dados
Antes de olharmos mais detalhadamente como a EDA funciona, vale a pena resumir a abordagem tradicional para projetos de data warehouse. A abordagem tradicional é parecida com esta:
Coleta de requisitos. Documente o que fazer com os dados.
Modelagem de dados. Determine como modelar os dados numéricos e de atributo em tabelas de fatos e dimensões. Tradicionalmente, você faz essa etapa antes de adquirir os novos dados.
ETL. Adquira os dados e mensagem-os no modelo de dados do data warehouse.
Essas etapas podem levar semanas ou até mesmo meses. Em seguida, você pode começar a consultar os dados e resolver o problema de negócios. O usuário vê o valor somente depois que os relatórios são criados. A arquitetura da solução geralmente é semelhante a esta:
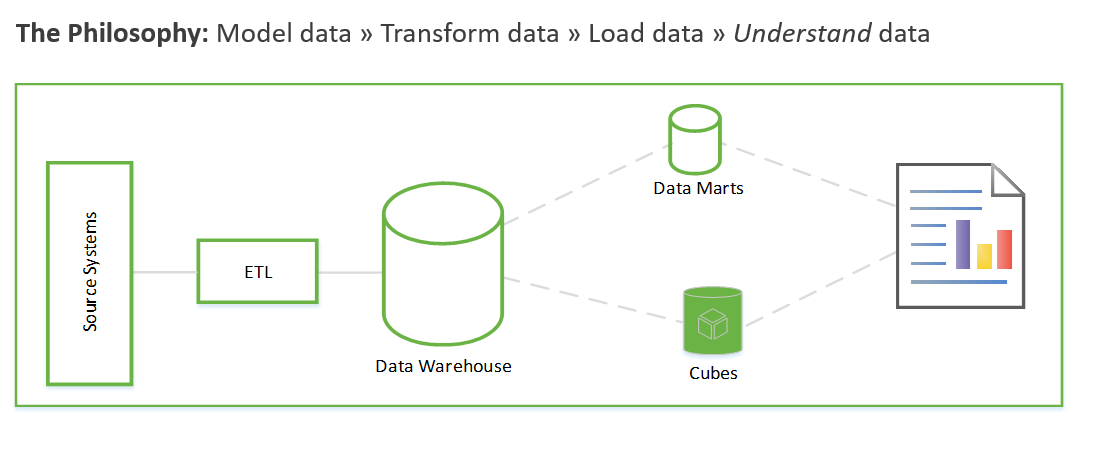
É possível fazer isso de outra forma que se concentre primeiro em gerar insights de negócios e, em seguida, a resolver as tarefas de modelagem e ETL. O processo é semelhante aos processos de ciência de dados. É algo semelhante a isto:
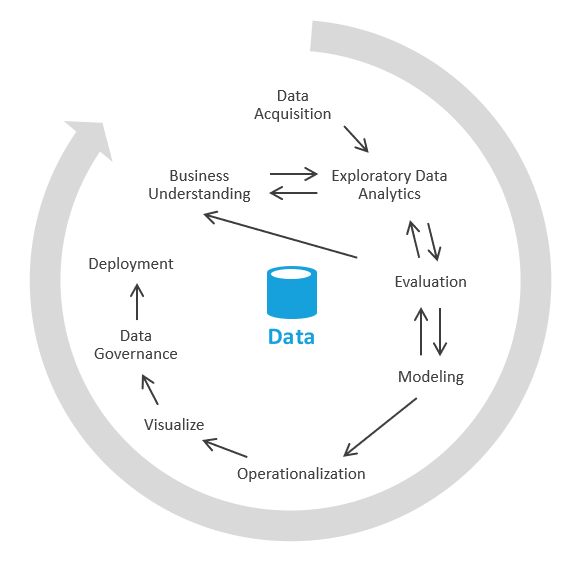
No setor, esse processo é chamado de EDA, ou análise exploratória de dados.
Aqui estão as etapas para fazer isso:
Aquisição de dados. Primeiro, você precisa determinar quais fontes de dados precisam ser ingeridas no data lake/sandbox. Em seguida, você precisa colocar esses dados na área de aterrissagem do seu Lake. o Azure fornece ferramentas como Azure Data Factory e Aplicativos Lógicos do Azure que podem ingerir dados rapidamente.
Área restrita de dados. Inicialmente, um analista de negócios e um engenheiro capacitado na análise de dados exploratório por meio do Azure Synapse Analytics sem servidor ou SQL básico, trabalham juntos. Durante essa fase, eles estão tentando descobrir as insight de negócios usando os novos dados. A EDA é um processo iterativo. Talvez seja necessário ingerir mais dados, conversar com SMEs, fazer mais perguntas ou gerar visualizações.
Avaliação. Depois de encontrar o insight de negócios, você precisa avaliar o que fazer com os dados. Talvez você queira manter os dados na data warehouse (para mover para a fase de modelagem). Em outros casos, você pode optar por manter os dados no data lake/lakehouse e usá-los para análise preditiva (algoritmos de aprendizado de máquina). Ainda em outros casos, você pode optar por aterrar seus sistemas de registro com as novas informações. Com base nessas decisões, você pode obter uma melhor compreensão do que precisa fazer em seguida. Talvez você não precise fazer a ETL.
Esses métodos são o núcleo da verdadeira análise de autoatendimento. Usando o data lake e uma ferramenta de consulta como o Azure Synapse sem servidor que compreende os padrões de consulta do data lake, você pode colocar seus ativos de dados nas mãos das pessoas de negócios que compreendem um pouco de SQL. Você pode reduzir radicalmente o tempo de implantação usando esse método e remover parte do risco associado às iniciativas de dados corporativos.
Considerações
Essas considerações implementam os pilares do Azure Well-Architected Framework, que é um conjunto de princípios de orientação que podem ser usados para aprimorar a qualidade de uma carga de trabalho. Para obter mais informações, confira Microsoft Azure Well-Architected Framework.
Disponibilidade
Os pools de SQL sem servidor do Azure Synapse são um recurso de plataforma como serviço (PaaS) que pode atender aos seus requisitos de HA (alta disponibilidade) e DR (recuperação de desastre).
Os pools sem servidor estão disponíveis sob demanda. Eles não exigem escalar horizontalmente, vertical, redução, expansão ou administração de qualquer tipo. Eles usam um modelo de pagamento por consulta, portanto, não há capacidade não utilizada a qualquer momento. Os pools sem servidor são ideais para:
- Explorações de ciência de dados ad hoc em T-SQL.
- Protótipos iniciais para entidades de data warehouse.
- Definição de exibições que os consumidores podem usar, por exemplo, no Power BI, para cenários que podem tolerar retardo de desempenho.
- Análise exploratória de dados.
Operações
O SQL sem servidor do Synapse usa o T-SQL padrão para consulta e operações. É possível usar a interface do usuário do espaço de trabalho do Synapse, Azure Data Studio ou SQL Server Management Studio como a ferramenta T-SQL.
Otimização de custo
A otimização de custos é a análise de maneiras de reduzir as despesas desnecessárias e melhorar a eficiência operacional. Para obter mais informações, confira Visão geral do pilar de otimização de custo.
O preço do Data Lake Storage depende do volume de dados armazenados e da frequência com que os dados são usados. O preço de exemplo inclui um TB de dados armazenados, com pressuposições transacionais adicionais. O um TB se refere ao tamanho do data lake, não ao tamanho do banco de dados herdado original.
O pool do Spark do Azure Synapse baseia o preço no tamanho do nó, no número de instâncias e no tempo de atividade. O exemplo supõe um pequeno nó de computação com utilização entre cinco horas por semana e 40 horas por mês.
O pool de SQL sem servidor do Azure Synapse baseia o preço nos TBs dos dados processados. O exemplo pressupõe 50 TBs processados por mês. Esse valor se refere ao tamanho do data lake, não ao tamanho do banco de dados herdado original.
Colaboradores
Este artigo está sendo atualizado e mantido pela Microsoft. Ele foi originalmente escrito pelos colaboradores a seguir.
Principais autores:
- Dave Wentzel | Arquiteto Técnico Principal do CTM
Próximas etapas
- Roteiros de aprendizagem de engenheiros de dados
- Tutorial: Introdução ao Azure Synapse Analytics
- Criar um banco de dados individual – Banco de Dados SQL do Azure
- Arquitetura do SQL do Azure Synapse
- Criar uma conta de armazenamento do Azure Data Lake Storage
- Início Rápido dos Hubs de Eventos do Azure – Criar um hub de eventos usando o portal do Azure
- Início Rápido – criar um trabalho do Stream Analytics usando o portal do Azure
- Guia de Início Rápido: introdução ao Azure Machine Learning