Divida um armazenamento de dados em um conjunto de partições horizontais ou fragmentos. Isso pode melhorar a escalabilidade ao armazenar e acessar grandes volumes de dados.
Contexto e problema
Um repositório de dados hospedado por um único servidor pode estar sujeito às seguintes limitações:
Espaço de armazenamento. Um repositório de dados para um aplicativo de nuvem em grande escala deve conter um grande volume de dados que podem aumentar significativamente ao longo do tempo. Um servidor geralmente fornece apenas uma quantidade finita de armazenamento em disco, mas você pode substituir discos existentes por maiores ou adicionar mais discos a uma máquina com o crescimento dos volumes de dados. No entanto, o sistema uma hora atingirá um limite em que não é possível aumentar facilmente a capacidade de armazenamento em um determinado servidor.
Recursos de computação. Um aplicativo de nuvem é necessário para dar suporte a um grande número de usuários simultâneos, cada um dos quais executa consultas que recuperam informações do repositório de dados. Um servidor que hospeda o armazenamento de dados pode não conseguir fornecer a capacidade de computação necessária para dar suporte a essa carga, resultando em tempos de resposta estendidos para usuários e falhas frequentes à medida que os aplicativos tentam armazenar e recuperar o tempo limite de dados. Pode ser possível adicionar processadores de memória ou de atualização, mas o sistema atingirá um limite quando não for possível aumentar ainda mais os recursos de computação.
Largura de banda da rede. Por fim, o desempenho de um repositório de dados em execução em um único servidor é controlado pela velocidade em que o servidor pode receber solicitações e enviar respostas. É possível que o volume de tráfego de rede possa exceder a capacidade da rede usada para se conectar ao servidor, resultando em solicitações com falha.
Geografia. Talvez seja necessário armazenar os dados gerados por usuários específicos na mesma região que esses usuários por motivos legais, de conformidade ou de desempenho ou para reduzir a latência de acesso aos dados. Se os usuários estão distribuídos em diferentes países ou regiões, pode não ser possível armazenar todos os dados do aplicativo em um único repositório de dados.
O dimensionamento vertical por adição de mais capacidade em disco, capacidade de processamento, memória e conexões de rede pode adiar os efeitos de algumas dessas limitações, mas é provável que seja apenas uma solução temporária. Um aplicativo de nuvem comercial capaz de dar suporte a grandes números de usuários e grandes volumes de dados deve ser capaz de ser dimensionado quase indefinidamente, então o dimensionamento vertical não é necessariamente a melhor solução.
Solução
Divida o repositório de dados em partições horizontais ou fragmentos. Cada fragmento tem o mesmo esquema, mas mantém seu próprio subconjunto distinto dos dados. Um fragmento é um repositório de dados em si (ele pode conter os dados de várias entidades de tipos diferentes), em execução em um servidor que atua como nó de armazenamento.
Esse padrão tem os seguintes benefícios:
Você pode dimensionar o sistema horizontalmente acrescentando mais fragmentos executados em nós de armazenamento adicionais.
Um sistema pode usar hardware disponível no mercado em vez de computadores especializados e caros para cada nó de armazenamento.
Você pode reduzir a contenção e melhorar o desempenho equilibrando a carga de trabalho entre fragmentos.
Na nuvem, fragmentos podem estar localizados fisicamente próximos aos usuários que acessarão os dados.
Ao dividir um repositório de dados em fragmentos, decida quais dados devem ser colocados em cada fragmento. Geralmente, um fragmento contém itens que se encontram em um intervalo específico determinado por um ou mais atributos dos dados. Esses atributos formam a chave de fragmentação (também conhecida como a chave de partição). A chave de fragmentação deve ser estática. Ela não deve ser baseada em dados que possam ser alterados.
A fragmentação física organiza os dados. Quando um aplicativo armazena e recupera dados, a lógica de fragmentação direciona o aplicativo para o fragmento apropriado. Essa lógica de fragmentação pode ser implementada como parte do código de acesso a dados no aplicativo ou pode ser implementada pelo sistema de armazenamento de dados se ele oferece suporte à fragmentação de forma transparente.
A abstração do local físico dos dados na lógica de fragmentação fornece um alto nível de controle sobre quais fragmentos contêm os dados. Ela também permite que dados migrem entre fragmentos sem refazer a lógica de negócios de um aplicativo se os dados nos fragmentos precisarem ser redistribuídos posteriormente (por exemplo, se os fragmentos se tornarem desbalanceados). A desvantagem é a sobrecarga de acesso a dados adicionais necessária para determinar a localização de cada item dos dados conforme eles são recuperados.
Para garantir o desempenho e a escalabilidade ideais, é importante dividir os dados de maneira adequada para os tipos de consultas que o aplicativo executa. Em muitos casos, é improvável que o esquema de fragmentação corresponda exatamente aos requisitos de cada consulta. Por exemplo, em um sistema multilocatário, um aplicativo pode precisar recuperar dados do locatário usando a ID do locatário, mas também pode precisar procurar esses dados com base em algum outro atributo, como o nome ou o local do locatário. Para lidar com essas situações, implemente uma estratégia de fragmentação com uma chave de fragmentação que ofereça suporte às consultas realizadas com mais frequência.
Se as consultas regularmente recuperam dados usando uma combinação de valores de atributo, você provavelmente pode definir uma chave de fragmentação composta vinculando atributos. Como alternativa, use um padrão como Tabela de Índice para oferecer pesquisa rápida de dados com base em atributos que não são cobertos pela chave de fragmentação.
Estratégias de fragmentação
Três estratégias são usadas frequentemente ao selecionar a chave de fragmentação e decidir como distribuir dados entre fragmentos. Observe que não é necessário que haja uma correspondência individual entre fragmentos e os servidores que os hospedam, um servidor pode hospedar vários fragmentos. As estratégias são:
A estratégia de pesquisa. Nesta estratégia, a lógica de fragmentação implementa um mapa que encaminha uma solicitação de dados para o fragmento que contém os dados usando a chave de fragmentação. Em um aplicativo multilocatário, todos os dados de um locatário podem ser armazenados juntos em um fragmento usando a ID do locatário como a chave do estilhaço. Vários locatários podem compartilhar o mesmo fragmento, mas os dados de um único locatário não serão distribuídos a vários fragmentos. A figura ilustra a fragmentação dos dados de locatário com base nas IDs de locatário.
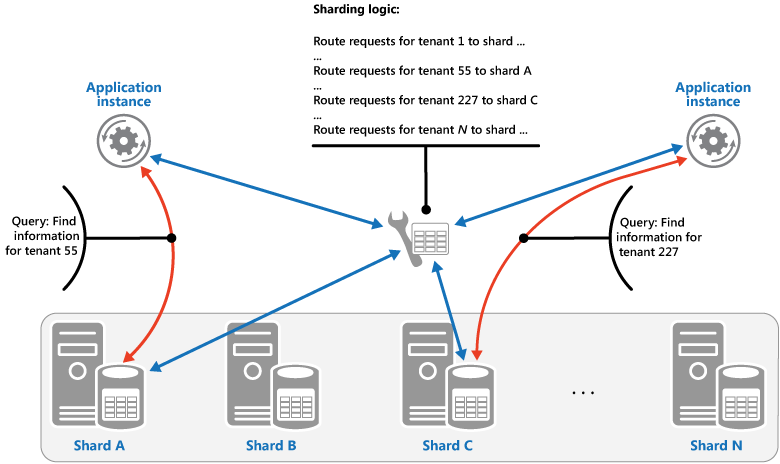
O mapeamento entre a chave de fragmentação e o armazenamento físico pode ser baseado em fragmentos físicos nos quais cada chave de fragmentação é mapeada a uma partição física. Como alternativa, uma técnica mais flexível para rebalancear fragmentos é o particionamento virtual, no qual as chaves de fragmentação são mapeadas ao mesmo número de fragmentos virtuais, que por sua vez são mapeados a menos partições físicas. Nessa abordagem, um aplicativo localiza os dados usando uma chave de fragmentação que se refere a um fragmento virtual e o sistema mapeia de maneira transparentemente fragmentos virtuais a partições físicas. O mapeamento entre um fragmento virtual e uma partição física pode mudar sem a necessidade de modificar o código do aplicativo para usar um conjunto diferente de chaves de fragmentação.
A estratégia de intervalo. Essa estratégia agrupa itens relacionados no mesmo fragmento e os classifica por chave de fragmentação. As chaves de fragmentação são sequenciais. É útil para aplicativos que frequentemente recuperam conjuntos de itens usando consultas de intervalo (consultas que retornam um conjunto de itens de dados para uma chave de fragmentação que fica dentro de um determinado intervalo). Por exemplo, se um aplicativo precisar localizar regularmente todos os pedidos feitos em um determinado mês, esses dados podem ser recuperados mais rapidamente se todos os pedidos de um mês estiverem armazenados ordenados por data e hora no mesmo fragmento. Se cada pedido foi armazenado em um fragmento diferente, eles precisam ser buscados individualmente executando um grande número de consultas pontuais (consultas que retornam um único item de dados). A figura seguinte ilustra como armazenar conjuntos sequenciais (intervalos) de dados no fragmento.
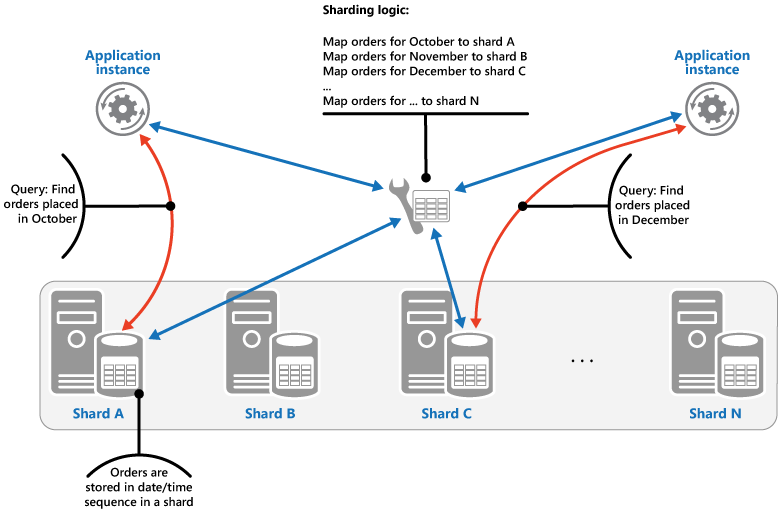
Neste exemplo, a chave de fragmentação é uma chave composta que contém o mês do pedido como o elemento mais significativo, seguido por dia e hora do pedido. Os dados de pedidos são classificados naturalmente quando novos pedidos são criados e adicionados a um fragmento. Alguns repositórios de dados aceitam chaves de fragmentação de duas partes contendo um elemento de chave de partição que identifica o fragmento e uma chave de linha que identifica exclusivamente um item no fragmento. Normalmente, os dados são mantidos na ordem da chave de linha no fragmento. Itens que estão sujeitos a consultas de intervalo e precisam ser agrupados podem usar uma chave de fragmentação que tenha o mesmo valor para a chave de partição, mas um valor exclusivo para a chave de linha.
A estratégia de Hash. A finalidade dessa estratégia é reduzir a chance de pontos problemáticos (fragmentos que recebem uma quantidade desproporcional de carga). Ela distribui os dados entre os fragmentos de forma que alcance um equilíbrio entre o tamanho de cada fragmento e a carga média que cada fragmento encontrará. A lógica de fragmentação calcula o fragmento para armazenar um item com base em um hash de um ou mais atributos dos dados. A função de hash de escolhida deve distribuir os dados uniformemente entre os fragmentos, possivelmente introduzindo algum elemento aleatório na computação. A próxima figura ilustra a fragmentação dos dados de locatário com base em um hash de IDs de locatário.
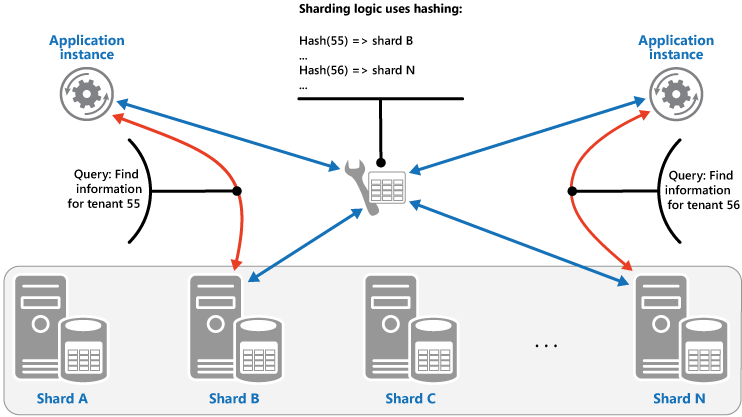
Para entender a vantagem da estratégia de Hash sobre outras estratégias de fragmentação, considere como um aplicativo multilocatário que registra novos locatários sequencialmente pode atribuir os locatários a fragmentos no armazenamento de dados. Ao usar a estratégia de Intervalo, os dados para locatários de 1 a n serão todos armazenados no fragmento A, os dados para locatários de n+1 a m serão todos armazenados no fragmento B e assim por diante. Se os locatários registrados mais recentemente também forem os mais ativos, a maior parte das atividades de dados ocorrerá em um pequeno número de fragmentos, o que pode resultar em pontos problemáticos. Por outro lado, a estratégia de Hash aloca locatários a fragmentos com base em um hash das IDs de locatário. Isso significa que locatários sequenciais têm mais probabilidade de serem alocados para fragmentos diferentes, que distribuirão a carga entre eles. A figura anterior mostra a isso para os locatários 55 e 56.
As três estratégias de fragmentação têm as seguintes vantagens e considerações:
Pesquisa. Oferece mais controle sobre a forma em que os fragmentos são configurados e usados. O uso de fragmentos virtuais reduz o impacto ao rebalancear dados porque novas partições físicas podem ser adicionadas para uniformizar a carga de trabalho. O mapeamento entre um fragmento virtual e as partições físicas que implementam o fragmento pode ser modificado sem afetar o código do aplicativo que usa uma chave de fragmentação para armazenar e recuperar dados. A pesquisa de locais de fragmento pode impor uma sobrecarga adicional.
Intervalo. É fácil de implementar e funciona bem com consultas de intervalo porque geralmente podem buscar vários itens de dados em um único fragmento em uma única operação. Essa estratégia oferece gerenciamento de dados mais fácil. Por exemplo, se os usuários na mesma região estiverem no mesmo fragmento, podem ser agendadas atualizações em cada fuso horário com base no padrão de carga local e demanda. No entanto, essa estratégia não fornece o equilíbrio ideal entre fragmentos. O rebalanceamento de fragmentos é difícil e pode não resolver o problema de carga irregular se a maior parte da atividade for para chaves de fragmentação adjacentes.
Hash. Essa estratégia oferece mais chances de uma distribuição de dados e carga mais uniforme. O roteamento de solicitação pode ser realizado diretamente usando a função de hash. Não é necessário manter um mapa. Observe que calcular o hash pode impor uma sobrecarga adicional. Além disso, o rebalanceamento de fragmentos é difícil.
Os sistemas mais comuns de fragmentação implementam uma das abordagens descritas acima, mas você também deve considerar os requisitos de negócios de seus aplicativos e seus padrões de uso de dados. Por exemplo, em um aplicativo multilocatário:
Você pode fragmentar dados com base na carga de trabalho. Você pode separar os dados para locatários altamente voláteis em fragmentos separados. A velocidade do acesso aos dados para outros locatários pode ser melhorada como resultado.
Você pode fragmentar dados com base na localização dos locatários. Você pode tornar os dados de locatários em uma região geográfica específica offline para manutenção e backup fora do horário de pico nessa região, enquanto os dados de locatários em outras regiões permanecem online e acessíveis durante os respectivos horários comerciais.
Os locatários de alto valor podem receber seus próprios fragmentos privados, de alto desempenho e levemente carregados, enquanto os locatários de menor valor podem compartilhar fragmentos mais densos e ocupados.
Os dados para locatários que precisam de um alto grau de isolamento de dados e privacidade podem ser armazenados em um servidor completamente separado.
Operações de movimentação de dados e dimensionamento
Cada uma das estratégias de fragmentação implica diferentes recursos e níveis de complexidade para gerenciar a redução, a expansão, a movimentação de dados e o estado de manutenção.
A estratégia de pesquisa permite que operações de movimentação de dados e dimensionamento sejam executadas no nível do usuário, online ou offline. A técnica resume-se em suspender algumas ou todas as atividades do usuário (talvez durante períodos de pico), mover os dados para a nova partição virtual ou fragmento físico, alterar os mapeamentos, invalidar ou atualizar quaisquer caches que mantenham esses dados e, em seguida, permitir que a atividade do usuário continue. Muitas vezes esse tipo de operação pode ser gerenciado de forma central. A estratégia de Pesquisa requer que o estado favoreça o armazenamento em cache e seja fácil de replicar.
A estratégia de Intervalo impõe algumas limitações a operações de movimentação de dados e dimensionamento, que normalmente devem ser executadas quando uma parte ou todo o repositório de dados está offline porque os dados devem ser divididos e mesclados entre os fragmentos. A movimentação dos dados para reequilibrar fragmentos não poderá resolver o problema de carga irregular se a maior parte da atividade for para chaves de fragmentação adjacentes ou identificadores de dados que estejam dentro do mesmo intervalo. A estratégia de Intervalo também pode exigir que algum estado seja mantido para mapear os intervalos às partições físicas.
A estratégia de Hash torna as operações de movimentação de dados e dimensionamento mais complexas porque as chaves de partição são hashes das chaves de fragmentação ou dos identificadores de dados. O novo local de cada fragmento deve ser determinado a partir da função de hash ou a função modificada para fornecer os mapeamentos corretos. No entanto, a estratégia de Hash não exige manutenção do estado.
Problemas e considerações
Considere os seguintes pontos ao decidir como implementar esse padrão:
A fragmentação é complementar a outras formas de particionamento, como particionamento vertical e particionamento funcional. Por exemplo, um único fragmento pode conter entidades que foram particionadas verticalmente e uma partição funcional pode ser implementada como vários fragmentos. Para saber mais sobre o particionamento, confira a Diretrizes de particionamento de dados.
Mantenha os fragmentos equilibrados para que todos tratem de um volume semelhante de E/S. À medida que os dados são inseridos e excluídos, é necessário reequilibrar periodicamente os fragmentos para garantir uma distribuição uniforme e reduzir a chance de pontos problemáticos. O rebalanceamento pode ser uma operação dispendiosa. Para reduzir a necessidade de rebalanceamento, planeje o crescimento garantindo que cada fragmento contenha espaço suficiente para lidar com o volume esperado de alterações. Você também deve desenvolver estratégias e scripts que possa usar para reequilibrar rapidamente fragmentos se isso for necessário.
Use dados estáveis para a chave de fragmentação. Se a chave de fragmentação for alterada, o item de dados correspondente talvez precise ser movido entre fragmentos, aumentando a quantidade de trabalho realizado pelas operações de atualização. Por esse motivo, evite basear a chave de fragmentação em informações potencialmente voláteis. Em vez disso, procure os atributos que sejam invariáveis ou que naturalmente formem uma chave.
Certifique-se de que as chaves de fragmentação sejam exclusivas. Por exemplo, evite usar campos de incremento automático como chave de fragmentação. Em alguns sistemas, campos incrementados automaticamente não podem ser coordenados entre fragmentos, possivelmente resultando em itens em fragmentos diferentes com a mesma chave de fragmentação.
Valores incrementados automaticamente em outros campos que não chaves de fragmentação também podem causar problemas. Por exemplo, se você usar campos incrementados automaticamente para gerar IDs exclusivas, dois itens diferentes localizados em fragmentos diferentes podem ter atribuída uma mesma ID.
Pode não ser possível criar uma chave de fragmentação que atenda aos requisitos de cada possível consulta dos dados. Fragmente os dados para dar suporte às consultas mais frequentemente executadas e, se necessário, crie tabelas de índice secundárias para dar suporte a consultas que recuperem dados usando os critérios baseados em atributos que não façam parte da chave de fragmentação. Para saber mais, confira o Padrão de Tabela de Índice.
Consultas que acessam apenas um único fragmento são mais eficientes do que aquelas que recuperam dados de vários fragmentos, portanto, evite implementar um sistema de fragmentação que resulte em aplicativos que executam grandes números de consultas que unem dados mantidos em fragmentos diferentes. Lembre-se de que um único fragmento pode conter os dados de vários tipos de entidades. Considere a desnormalização de seus dados para manter as entidades relacionadas que normalmente são consultadas em conjunto (por exemplo, os detalhes de clientes e os pedidos que eles fizeram) no mesmo fragmento para reduzir o número de leituras separadas que um aplicativo realiza.
Se uma entidade em um fragmento faz referência a uma entidade armazenada em outro fragmento, inclua a chave de fragmentação para a segunda entidade como parte do esquema da primeira entidade. Isso pode ajudar a melhorar o desempenho das consultas que fazem referência a dados relacionados entre fragmentos.
Se um aplicativo deve executar consultas que recuperam dados de vários fragmentos, pode ser possível buscar esses dados por meio de tarefas paralelas. Os exemplos incluem consultas do tipo fan-out, nas quais os dados de vários fragmentos são recuperados em paralelo e agregados em um único resultado. No entanto, essa abordagem inevitavelmente adiciona certa complexidade à lógica de acesso a dados de uma solução.
Para muitos aplicativos, a criação de um grande número de fragmentos pequenos pode ser mais eficiente do que um pequeno número de fragmentos grandes porque eles podem oferecer mais oportunidades de balanceamento de carga. Isso também pode ser útil se você prevê a necessidade de migrar os fragmentos de um local físico para outro. A movimentação de um fragmento pequeno é mais rápida do que mover um grande.
Verifique se os recursos disponíveis para cada nó de armazenamento de fragmento são suficientes para lidar com os requisitos de escalabilidade em termos de tamanho de dados e taxa de transferência. Para obter mais informações, confira a seção "Como criar partições para escalabilidade" em Diretrizes de particionamento de dados.
Considere a possibilidade de replicar dados de referência para todos os fragmentos. Se uma operação que recupera dados de um fragmento também faz referência a dados estáticos ou lentos, como parte da mesma consulta, adicione esses dados ao fragmento. O aplicativo pode então buscar todos os dados para a consulta facilmente, sem precisar fazer outro percurso de ida e volta a um repositório de dados separado.
Se os dados de referência mantidos em vários fragmentos mudarem, o sistema deve sincronizar essas alterações em todos os fragmentos. O sistema pode apresentar um grau de inconsistência enquanto ocorre a sincronização. Se você fizer isso, você deve projetar seus aplicativos para serem capazes de lidar com isso.
Pode ser difícil manter a integridade referencial e a consistência entre os fragmentos, portanto você deve minimizar as operações que afetam os dados em vários fragmentos. Se um aplicativo deve modificar dados em fragmentos, avalie se a consistência total dos dados é realmente necessária. Em vez disso, uma abordagem comum na nuvem é implementar a consistência eventual. Os dados em cada partição são atualizados separadamente e a lógica do aplicativo deve assumir a responsabilidade de garantir que todas as atualizações concluam com êxito, bem como tratar as inconsistências que possam surgir na consulta de dados durante a execução de uma operação que será consistente em algum momento. Para saber mais sobre como Para saber mais sobre como implementar a consistência eventual, confira Primer de Consistência de Dados.
A configuração e o gerenciamento de um grande número de fragmentos podem ser um desafio. Tarefas como monitoramento, backup, verificação de consistência e registro em log ou auditoria devem ser realizadas em vários fragmentos e servidores, possivelmente mantidos em vários locais. Essas tarefas possivelmente podem ser implementadas usando scripts ou outras soluções de automação, mas isso pode não eliminar completamente os requisitos administrativos adicionais.
Os fragmentos podem ser geolocalizados para que os dados que eles contêm estejam próximos das instâncias de um aplicativo que os usa. Essa abordagem pode melhorar significativamente o desempenho, mas requer considerações adicionais para tarefas que devem acessar vários fragmentos em diferentes locais.
Quando usar esse padrão
Use esse padrão quando um repositório de dados possa possivelmente precisar ser dimensionado além dos recursos disponíveis para um único nó de armazenamento ou para melhorar o desempenho reduzindo a contenção em um repositório de dados.
Observação
O foco principal da fragmentação é melhorar o desempenho e escalabilidade de um sistema, mas como subproduto também pode melhorar a disponibilidade devido a como os dados são divididos em partições separadas. Uma falha em uma partição não necessariamente impede que um aplicativo acesse os dados mantidos em outras partições e um operador pode realizar manutenção ou recuperação de uma ou mais partições sem tornar todos os dados inacessíveis para um aplicativo. Para saber mais, consulte Diretrizes de particionamento de dados.
Design de carga de trabalho
Um arquiteto deve avaliar como o padrão Sharding pode ser usado no design de sua carga de trabalho para abordar as metas e os princípios abordados nos pilares do Azure Well-Architected Framework. Por exemplo:
| Pilar | Como esse padrão apoia os objetivos do pilar |
|---|---|
| As decisões de design de confiabilidade ajudam sua carga de trabalho a se tornar resiliente ao mau funcionamento e a garantir que ela se recupere para um estado totalmente funcional após a ocorrência de uma falha. | Como os dados ou processamento são isolados para o fragmento, um mau funcionamento em um fragmento permanece isolado para esse fragmento. - Particionamento de dados RE:06 - RE:07 Autopreservação |
| A otimização de custos se concentra em sustentar e melhorar o retorno sobre o investimento da sua carga de trabalho. | Um sistema que implementa fragmentos geralmente se beneficia do uso de várias instâncias de recursos de computação ou armazenamento mais baratos, em vez de um único recurso mais caro. Em muitos casos, essa configuração pode economizar dinheiro. - CO:07 Custos de componentes |
| A eficiência de desempenho ajuda sua carga de trabalho a atender com eficiência às demandas por meio de otimizações em dimensionamento, dados e código. | Quando você usa o sharding em sua estratégia de dimensionamento, os dados ou o processamento são isolados em um fragmento, portanto, ele compete por recursos apenas com outras solicitações que são direcionadas a esse fragmento. Você também pode usar o sharding para otimizar com base na geografia. - PE:05 Dimensionamento e particionamento - PE:08 Desempenho de dados |
Tal como acontece com qualquer decisão de design, considere quaisquer compensações em relação aos objetivos dos outros pilares que possam ser introduzidos com este padrão.
Exemplo
O exemplo a seguir em C# usa um conjunto de bancos de dados do SQL Server atuando como fragmentos. Cada banco de dados contém um subconjunto dos dados usados por um aplicativo. O aplicativo recupera dados distribuídos entre os fragmentos usando sua própria lógica de fragmentação (esse é um exemplo de uma consulta do tipo fan-out). Os detalhes dos dados localizados em cada fragmento são retornados por um método chamado GetShards. Esse método retorna uma lista enumerável de objetos ShardInformation, na qual o tipo ShardInformation contém um identificador para cada fragmento e a cadeia de conexão do SQL Server que um aplicativo deve usar para se conectar ao fragmento (as cadeias de conexão não são mostradas no exemplo de código).
private IEnumerable<ShardInformation> GetShards()
{
// This retrieves the connection information from a shard store
// (commonly a root database).
return new[]
{
new ShardInformation
{
Id = 1,
ConnectionString = ...
},
new ShardInformation
{
Id = 2,
ConnectionString = ...
}
};
}
O código a seguir mostra como o aplicativo usa a lista de objetos ShardInformation para executar uma consulta que busca os dados de cada fragmento em paralelo. Os detalhes da consulta não são mostrados, mas os dados recuperados neste exemplo contêm uma cadeia de caracteres que pode conter informações como nome de um cliente se os fragmentos contiverem os detalhes de clientes. Os resultados são agregados em uma coleção ConcurrentBag a ser processada pelo aplicativo.
// Retrieve the shards as a ShardInformation[] instance.
var shards = GetShards();
var results = new ConcurrentBag<string>();
// Execute the query against each shard in the shard list.
// This list would typically be retrieved from configuration
// or from a root/primary shard store.
Parallel.ForEach(shards, shard =>
{
// NOTE: Transient fault handling isn't included,
// but should be incorporated when used in a real world application.
using (var con = new SqlConnection(shard.ConnectionString))
{
con.Open();
var cmd = new SqlCommand("SELECT ... FROM ...", con);
Trace.TraceInformation("Executing command against shard: {0}", shard.Id);
var reader = cmd.ExecuteReader();
// Read the results in to a thread-safe data structure.
while (reader.Read())
{
results.Add(reader.GetString(0));
}
}
});
Trace.TraceInformation("Fanout query complete - Record Count: {0}",
results.Count);
Próximas etapas
As diretrizes a seguir também podem ser relevantes ao implementar esse padrão:
- Primer de Consistência de Dados. Talvez seja necessário manter a consistência de dados distribuídos entre fragmentos diferentes. Resume os problemas em torno da manutenção de consistência de dados distribuídos e descreve os benefícios e as vantagens e desvantagens de modelos diferentes de consistência.
- Diretrizes de Particionamento de Dados. A fragmentação de um repositório de dados pode apresentar uma variedade de outros problemas. Descreve esses problemas em relação ao particionamento de repositórios de dados na nuvem para melhorar a escalabilidade, reduzir a contenção e otimizar o desempenho.
Recursos relacionados
Os seguintes padrões também serão relevantes durante a implementação desse padrão:
- Padrão de Tabela de Índice. Às vezes, não é possível oferecem suporte total a consultas apenas por meio do design da chave de fragmentação. Permite que um aplicativo recupere rapidamente os dados de um repositório de dados grande especificando uma chave que não seja a chave de fragmentação.
- Padrão de Exibição Materializada. Para manter o desempenho de algumas operações de consulta, é útil criar exibições materializadas que agreguem e resumam dados, especialmente se esses dados de resumo se basearem em informações distribuídas entre fragmentos. Descreve como gerar e preencher esses modos de exibição.