Considerações de design de aplicativo para cargas de trabalho de missão crítica
A arquitetura de referência de missão crítica de linha de base ilustra uma carga de trabalho altamente confiável por meio de um aplicativo de catálogo online simples. Os usuários finais podem navegar por um catálogo de itens, ver detalhes de um item e postar classificações e comentários para itens. Este artigo foca os aspectos de confiabilidade e resiliência de um aplicativo de missão crítica, como o processamento assíncrono de solicitações e como obter alta taxa de transferência em uma solução.
Importante
 A orientação é apoiada por uma implementação de referência de nível de produção que mostra o desenvolvimento de aplicativos de missão crítica no Azure. Essa implementação pode ser usada como base para o desenvolvimento de soluções adicionais na sua primeira etapa para produção.
A orientação é apoiada por uma implementação de referência de nível de produção que mostra o desenvolvimento de aplicativos de missão crítica no Azure. Essa implementação pode ser usada como base para o desenvolvimento de soluções adicionais na sua primeira etapa para produção.
Composição do aplicativo
Para aplicativos de missão crítica de alta escala, é essencial otimizar a arquitetura para escalabilidade e resiliência de ponta a ponta. Este estado pode ser alcançado por meio da separação de componentes em unidades funcionais que podem operar de forma independente. Aplique essa separação em todos os níveis na pilha de aplicativos, permitindo que cada parte do sistema seja dimensionada de forma independente e atenda às mudanças na demanda.
Um exemplo dessa abordagem é mostrado na implementação. O aplicativo usa pontos de extremidade de API sem estado, que desacoplam solicitações de gravação de execução longa e assíncrona por meio de um agente de mensagens. A carga de trabalho é composta de forma que todo o cluster do AKS e outras dependências no carimbo possam ser excluídos e recriados a qualquer momento. Os principais componentes são:
- Interface do usuário (IU): o aplicativo Web de página única acessado pelos usuários finais é localizado na hospedagem de site estático da Conta de Armazenamento do Azure.
- API (
CatalogService): API REST chamada pelo aplicativo de IU, mas disponível para outras aplicações cliente em potencial. - Trabalho (
BackgroundProcessor): trabalho em segundo plano, que processa solicitações de gravação no banco de dados ouvindo novos eventos no barramento de mensagens. Este componente não expõe nenhuma API. - API do serviço de integridade (
HealthService): usada para informar a integridade do aplicativo verificando se os componentes críticos (banco de dados, barramento de mensagens) estão funcionando.

Os aplicativos de API, trabalho e verificação de integridade são chamados de carga de trabalho e hospedados como contêineres em um namespace do AKS dedicado (chamado workload). Não há comunicação direta entre os pods. Os pods são sem estado e capazes de escalar de forma independente.
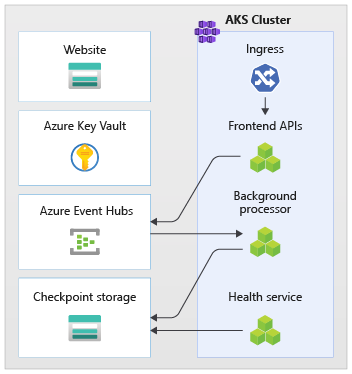
Há outros componentes de suporte em execução no cluster:
- Controlador de entrada: O controlador de entrada Nginx é usado para rotear solicitações de entrada para a carga de trabalho e balanceamento de carga entre pods. Ele é exposto por meio do Azure Load Balancer com um endereço IP público (mas acessado somente por meio do Azure Front Door).
- Gerenciador de certificados: o
cert-managerdo Jetstack é usado para provisionar automaticamente certificados SSL/TLS (usando Let's Encrypt) para as regras de entrada. - Driver de segredos CSI: o Provedor do Cofre de Chaves do Azure para CSI do repositório de segredos é usado para ler segredos com segurança, como cadeias de conexão do Azure Key Vault.
- Agente de monitoramento: a configuração padrão do OMSAgent é ajustada para reduzir a quantidade de dados de monitoramento enviados ao workspace do Log Analytics.
Conexão de banco de dados
Devido à natureza efêmera dos carimbos de implantação, evite ao máximo a persistência do estado dentro do carimbo. O estado deve persistir em um armazenamento de dados externalizado. Para oferecer suporte ao SLO de confiabilidade, esse armazenamento de dados precisa ser resiliente. É recomendável usar serviços gerenciados (PaaS) combinados com bibliotecas nativas do SDK que lidam automaticamente com tempos limites, desconexões e outros estados de falha.
Na implementação de referência, o Azure Cosmos DB serve como o armazenamento de dados principal para o aplicativo. O Azure Cosmos DB foi escolhido porque fornece gravações de várias regiões. Cada carimbo pode gravar na réplica do Azure Cosmos DB na mesma região com o Azure Cosmos DB manipulando internamente a replicação de dados e a sincronização entre regiões. O Azure Cosmos DB for NoSQL é usado porque oferece suporte a todos os recursos do mecanismo de banco de dados.
Para obter mais informações, consulte Plataforma de dados para cargas de trabalho de missão crítica.
Observação
Novos aplicativos devem usar o Azure Cosmos DB for NoSQL. Para aplicativos herdados que usam outro protocolo NoSQL, avalie o caminho de migração para o Azure Cosmos DB.
Dica
Para aplicativos de missão crítica que priorizam a disponibilidade em detrimento do desempenho, a gravação de uma região e a leitura de várias regiões com nível de consistência forte são recomendadas.
Nessa arquitetura, há a necessidade de armazenar o estado temporariamente no carimbo para o ponto de verificação dos Hubs de Eventos. O Armazenamento do Azure é usado para essa finalidade.
Todos os componentes de carga de trabalho usam o SDK do .NET Core do Azure Cosmos DB para se comunicar com o banco de dados. O SDK inclui lógica robusta para manter conexões de banco de dados e lidar com falhas. Aqui estão algumas definições de configuração importantes:
- Use o modo de conectividade Direct. Essa é a configuração padrão do .NET SDK v3 porque oferece melhor desempenho. Há menos saltos de rede em comparação com o modo Gateway, que usa HTTP.
- A resposta de retorno de conteúdo na gravação está desabilitada para impedir que o cliente do Azure Cosmos DB retorne o documento das operações Create, Upsert, Patch e Replace para reduzir o tráfego de rede. Além disso, isso não é necessário para processamento adicional no cliente.
- A serialização personalizada é usada para definir a política de nomenclatura de propriedade JSON para
JsonNamingPolicy.CamelCasetraduzir propriedades .NET para JSON padrão e vice-versa. A condição de ignorar padrão ignora propriedades com valores nulos durante a serialização (JsonIgnoreCondition.WhenWritingNull). - A região do aplicativo é definida como a região do carimbo, o que permite que o SDK localize o ponto de extremidade de conexão mais próximo (de preferência dentro da mesma região).
//
// /src/app/AlwaysOn.Shared/Services/CosmosDbService.cs
//
CosmosClientBuilder clientBuilder = new CosmosClientBuilder(sysConfig.CosmosEndpointUri, sysConfig.CosmosApiKey)
.WithConnectionModeDirect()
.WithContentResponseOnWrite(false)
.WithRequestTimeout(TimeSpan.FromSeconds(sysConfig.ComsosRequestTimeoutSeconds))
.WithThrottlingRetryOptions(TimeSpan.FromSeconds(sysConfig.ComsosRetryWaitSeconds), sysConfig.ComsosMaxRetryCount)
.WithCustomSerializer(new CosmosNetSerializer(Globals.JsonSerializerOptions));
if (sysConfig.AzureRegion != "unknown")
{
clientBuilder = clientBuilder.WithApplicationRegion(sysConfig.AzureRegion);
}
_dbClient = clientBuilder.Build();
Mensagens assíncronas
O acoplamento flexível permite que os serviços sejam projetados de forma que um serviço não tenha dependência de outros serviços. O aspecto solto permite que um serviço opere de forma independente. O aspecto de acoplamento permite a comunicação entre serviços por meio de interfaces bem definidas. No contexto de um aplicativo de missão crítica, ele facilita a alta disponibilidade, evitando que falhas downstream sejam transmitidas em cascata para front-ends ou carimbos de implantação diferentes.
Principais características:
- Os serviços não precisam necessariamente usar a mesma plataforma de computação, linguagem de programação ou sistema operacional.
- Os serviços são dimensionados de forma independente.
- As falhas downstream não afetam as transações do cliente.
- A integridade transacional é mais difícil de manter, porque a criação e a persistência de dados acontecem em serviços separados. Esse também é um desafio entre os serviços de mensagens e persistência, conforme descrito nesta orientação sobre processamento de mensagens idempotentes.
- O rastreamento de ponta a ponta requer orquestração mais complexa.
O uso de padrões de design bem conhecidos, como o padrão de nivelamento de carga baseado em fila e o padrão de consumidores concorrentes, é altamente recomendado. Esses padrões ajudam na distribuição de carga do produtor para os consumidores e no processamento assíncrono pelos consumidores. Por exemplo, o trabalho permite que a API aceite a solicitação e retorne ao chamador rapidamente enquanto processa uma operação de gravação de banco de dados separadamente.
Os Hubs de Eventos do Azure são usados como o agente de mensagens entre a API e o trabalho.
Importante
O agente de mensagens não se destina a ser usado como um armazenamento de dados persistente por longos períodos. O Serviço de Hubs de Eventos oferece recurso de captura que permite que um hub de eventos grave automaticamente uma cópia das mensagens em uma conta de Armazenamento do Azure vinculada. Isso mantém a utilização sob controle, mas também serve como um mecanismo para fazer backup de mensagens.
Detalhes de implementação para operações de gravação
As operações de gravação, como postagem de classificação e comentários, são processadas de forma assíncrona. A API primeiro envia uma mensagem com todas as informações relevantes, como tipo de ação e dados de comentário, para a fila de mensagens e retorna HTTP 202 (Accepted) imediatamente com cabeçalho adicional Location do objeto a ser criado.
As mensagens na fila são processadas por BackgroundProcessor instâncias que manipulam a comunicação real do banco de dados para operações de gravação. BackgroundProcessor dimensiona vertical e horizontalmente com base no volume de mensagens na fila. O limite de dimensionamento das instâncias do processador é definido pelo número máximo de partições dos Hubs de Eventos (que é 32 para as camadas Básica e Padrão, 100 para a camada Premium e 1024 para a camada Dedicada).

A biblioteca do Processador do Hub de Eventos do Azure no BackgroundProcessor usa o Armazenamento de Blobs do Azure para gerenciar a propriedade da partição, o balanceamento de carga entre diferentes instâncias de trabalho e para controlar o progresso usando pontos de verificação. Gravar os pontos de verificação no armazenamento de blob não ocorre após cada evento porque isso adicionaria um atraso proibitivamente caro para cada mensagem. Em vez disso, a gravação do ponto de verificação ocorre em um loop de temporizador (duração configurável com uma configuração atual de 10 segundos):
while (!stoppingToken.IsCancellationRequested)
{
await Task.Delay(TimeSpan.FromSeconds(_sysConfig.BackendCheckpointLoopSeconds), stoppingToken);
if (!stoppingToken.IsCancellationRequested && !checkpointEvents.IsEmpty)
{
string lastPartition = null;
try
{
foreach (var partition in checkpointEvents.Keys)
{
lastPartition = partition;
if (checkpointEvents.TryRemove(partition, out ProcessEventArgs lastProcessEventArgs))
{
if (lastProcessEventArgs.HasEvent)
{
_logger.LogDebug("Scheduled checkpointing for partition {partition}. Offset={offset}", partition, lastProcessEventArgs.Data.Offset);
await lastProcessEventArgs.UpdateCheckpointAsync();
}
}
}
}
catch (Exception e)
{
_logger.LogError(e, "Exception during checkpointing loop for partition={lastPartition}", lastPartition);
}
}
}
Se o aplicativo do processador encontrar um erro ou for interrompido antes de processar a mensagem, então:
- Outra instância coletará a mensagem para reprocessamento, porque ela não foi corretamente verificada no armazenamento.
- Se o trabalho anterior conseguiu manter o documento no banco de dados antes de falhar, um conflito ocorrerá (porque o mesmo ID e chave de partição são usados) e o processador poderá ignorar a mensagem com segurança, pois ela foi mantida.
- Se o trabalho anterior foi encerrado antes de gravar no banco de dados, a nova instância repetirá as etapas e finalizará a persistência.
Detalhes de implementação para operações de leitura
As operações de leitura são processadas diretamente pela API e retornam imediatamente os dados ao usuário.

Não haverá nenhum canal de retorno que se comunica com o cliente se a operação for concluída com êxito. O aplicativo cliente precisa sondar proativamente a API para obter atualizações do item especificado no cabeçalho HTTP Location.
Escalabilidade
Os componentes individuais da carga de trabalho devem ser expandidos independentemente porque cada um tem padrões de carga diferentes. Os requisitos de dimensionamento dependem da funcionalidade do serviço. Alguns serviços têm um impacto direto no usuário final e espera-se que consigam expandir agressivamente para fornecer resposta rápida para um bom desempenho e experiência positiva do usuário a qualquer momento.
Na implementação, os serviços são empacotados como contêineres do Docker e implantados usando pacotes Helm para cada carimbo. Eles são configurados para ter as solicitações e limites esperados do Kubernetes e uma regra de dimensionamento automático pré-configurada. O componente CatalogService e a carga de trabalho BackgroundProcessor pode ser expandido individualmente, ambos os serviços são sem estado.
Os usuários finais interagem diretamente com CatalogService, portanto, essa parte da carga de trabalho deve responder sob qualquer carga. Há pelo menos 3 instâncias por cluster para dividir entre três zonas de disponibilidade em uma região do Azure. O dimensionador automático de pod horizontal (HPA) do AKS cuida da adição automática de mais pods, se necessário, e o dimensionamento automático do Azure Cosmos DB é capaz de aumentar e reduzir dinamicamente os RUs disponíveis para a coleção. Juntos, o CatalogService e o Azure Cosmos DB formam uma unidade de escala dentro de um carimbo.
O HPA é implantado com um pacote Helm com número máximo e mínimo configurável de réplicas. Os valores são configurados como:
Durante um teste de carga, foi identificado que cada instância deve lidar com cerca de 250 solicitações/segundo com um padrão de uso típico.
O serviço BackgroundProcessor tem requisitos muito diferentes e é considerado um trabalho em segundo plano, o que tem impacto limitado na experiência do usuário. Como tal, BackgroundProcessor tem uma configuração de dimensionamento automático diferente, e CatalogService pode ser dimensionado entre 2 e 32 instâncias (esse limite deve ser baseado no número de partições usadas nos Hubs de Eventos e não há benefício em ter mais trabalhos do que partições).
| Componente | minReplicas |
maxReplicas |
|---|---|---|
| CatalogService | 3 | 20 |
| BackgroundProcessor | 2 | 32 |
Além disso, cada componente da carga de trabalho, incluindo dependências, como ingress-nginx, tem orçamentos de interrupção de pod (PDBs) configurados para garantir que um número mínimo de instâncias esteja sempre disponível quando as alterações forem implementadas em clusters.
#
# /src/app/charts/healthservice/templates/pdb.yaml
# Example pod distribution budget configuration.
#
apiVersion: policy/v1
kind: PodDisruptionBudget
metadata:
name: {{ .Chart.Name }}-pdb
spec:
minAvailable: 1
selector:
matchLabels:
app: {{ .Chart.Name }}
Observação
O número mínimo e máximo real de pods para cada componente deve ser determinado por meio de testes de carga e pode diferir por carga de trabalho.
Instrumentação
A instrumentação é um mecanismo importante na avaliação de gargalos de desempenho e problemas de integridade que os componentes de carga de trabalho podem introduzir no sistema. Cada componente deve emitir informações suficientes por meio de métricas e logs de rastreamento para ajudar a quantificar as decisões. Aqui estão algumas considerações importantes para instrumentar seu aplicativo.
- Envie logs, métricas e telemetria adicional para o sistema de log do carimbo.
- Use o log estruturado em vez de texto sem formatação para que as informações possam ser consultadas.
- Implemente a correlação de eventos para garantir a visualização completa da transação. No RI, cada resposta de API contém ID de operação como um cabeçalho HTTP para rastreabilidade.
- Não confie apenas no registro em log stdout (console). No entanto, esses logs podem ser usados para solução imediata de problemas de um pod com falha.
Essa arquitetura implementa o rastreamento distribuído com o Application Insights apoiado pelo Log Analytics Workspace para todos os dados de monitoramento de aplicativos. O Azure Log Analytics é usado para logs e métricas de todos os componentes de carga de trabalho e infraestrutura. A carga de trabalho implementa o rastreamento completo de ponta a ponta de solicitações provenientes da API, por meio de Hubs de Eventos, para o Azure Cosmos DB.
Importante
Os recursos de monitoramento de carimbo são implantados em um grupo de recursos de monitoramento separado e têm ciclo de vida diferente do próprio carimbo. Para obter mais informações, consulte Monitoramento de dados para recursos de carimbo.

Detalhes da implementação para monitoramento de aplicativos
O componente BackgroundProcessor usa o pacote NuGet Microsoft.ApplicationInsights.WorkerService para obter instrumentação pronta para uso do aplicativo. Além disso, o Serilog é usado para todos os logs dentro do aplicativo com o Azure Application Insights configurado como um coletor (ao lado do coletor do console). Somente quando necessário para controlar métricas adicionais, uma instância TelemetryClient do Application Insights é usada diretamente.
//
// /src/app/AlwaysOn.BackgroundProcessor/Program.cs
//
public static IHostBuilder CreateHostBuilder(string[] args) =>
Host.CreateDefaultBuilder(args)
.ConfigureServices((hostContext, services) =>
{
Log.Logger = new LoggerConfiguration()
.ReadFrom.Configuration(hostContext.Configuration)
.Enrich.FromLogContext()
.WriteTo.Console(outputTemplate: "[{Timestamp:yyyy-MM-dd HH:mm:ss.fff zzz} {Level:u3}] {Message:lj} {Properties:j}{NewLine}{Exception}")
.WriteTo.ApplicationInsights(hostContext.Configuration[SysConfiguration.ApplicationInsightsConnStringKeyName], TelemetryConverter.Traces)
.CreateLogger();
}
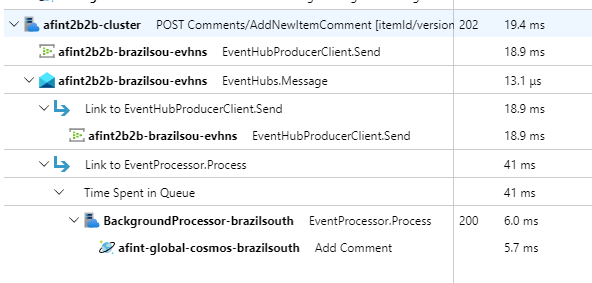
Para demonstrar a rastreabilidade prática da solicitação, cada solicitação de API (bem-sucedida ou não) retorna o cabeçalho de ID de Correlação para o chamador. Com esse identificador, a equipe de suporte do aplicativo pode pesquisar o Application Insights e obter uma visão detalhada da transação completa.
//
// /src/app/AlwaysOn.CatalogService/Startup.cs
//
app.Use(async (context, next) =>
{
context.Response.OnStarting(o =>
{
if (o is HttpContext ctx)
{
// ... code omitted for brevity
context.Response.Headers.Add("X-Server-Location", sysConfig.AzureRegion);
context.Response.Headers.Add("X-Correlation-ID", Activity.Current?.RootId);
context.Response.Headers.Add("X-Requested-Api-Version", ctx.GetRequestedApiVersion()?.ToString());
}
return Task.CompletedTask;
}, context);
await next();
});
Observação
O SDK do Application Insights tem a amostragem adaptável habilitada por padrão. Isso significa que nem todas as solicitações são enviadas para a nuvem e pesquisáveis por ID. As equipes de aplicativos de missão crítica precisam ser capazes de rastrear de forma confiável cada solicitação, portanto, a implementação de referência tem a amostragem adaptável desabilitada no ambiente de produção.
Detalhes da implementação do monitoramento do Kubernetes
Além do uso de configurações de diagnóstico para enviar logs e métricas do AKS para o Log Analytics, o AKS também é configurado para usar o Container Insights. Ao ativar o Container Insights, você implanta o OMSAgentForLinux por meio de um DaemonSet do Kubernetes em cada um dos nós em clusters do AKS. O OMSAgentForLinux é capaz de coletar logs e métricas adicionais de dentro do cluster do Kubernetes e enviá-los para seu espaço de trabalho correspondente do Log Analytics. Ele contém dados mais granulares sobre pods, implantações, serviços e a integridade geral do cluster.
O registro extensivo pode afetar negativamente o custo, ao mesmo tempo que não oferece nenhum benefício. Por esse motivo, a coleta de logs stdout e a extração do Prometheus estão desabilitadas para os pods de carga de trabalho na configuração do Container Insights, pois todos os rastreamentos já são capturados por meio do Application Insights, gerando registros duplicados.
#
# /src/config/monitoring/container-azm-ms-agentconfig.yaml
# This is just a snippet showing the relevant part.
#
[log_collection_settings]
[log_collection_settings.stdout]
enabled = false
exclude_namespaces = ["kube-system"]
Consulte o arquivo de configuração completo para referência.
Monitoramento da integridade
O monitoramento e a observabilidade do aplicativo são comumente usados para identificar rapidamente problemas com um sistema e informar o modelo de integridade sobre o estado atual do aplicativo. O monitoramento de integridade, exibido por meio de pontos de extremidade de integridade e usado por investigações de integridade, fornece informações, que são imediatamente acionáveis, normalmente instruindo o balanceador de carga principal a tirar o componente não íntegro da rotação.
Na arquitetura, o monitoramento de integridade é aplicado nestes níveis:
- Pods de carga de trabalho em execução no AKS. Esses pods têm investigação de atividade e integridade, portanto, o AKS é capaz de gerenciar seu ciclo de vida.
- O serviço de integridade é um componente dedicado no cluster. O Azure Front Door está configurado para investigar os serviços de integridade em cada carimbo e remover carimbos não íntegros do balanceamento de carga automaticamente.
Detalhes da implementação do serviço de integridade
HealthService é um componente de carga de trabalho que está sendo executado junto com outros componentes (CatalogService e BackgroundProcessor) no cluster de cálculo. Ele fornece uma API REST que é chamada pela verificação de integridade do Azure Front Door para determinar a disponibilidade de um carimbo. Ao contrário das investigações básicas de atividade, o serviço de integridade é um componente mais complexo que adiciona o estado das dependências além do seu.
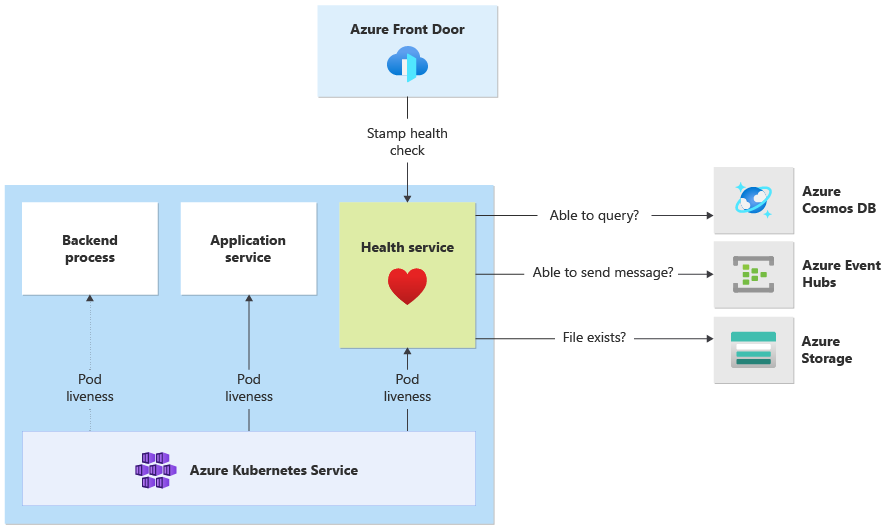
Se o cluster do AKS estiver inativo, o serviço de integridade não responderá, tornando a carga de trabalho não íntegra. Quando o serviço está em execução, ele executa verificações periódicas em componentes críticos da solução. Todas as verificações são feitas de forma assíncrona e em paralelo. Se alguma delas falhar, todo o carimbo será considerado indisponível.
Aviso
As investigações de integridade do Azure Front Door podem gerar uma carga significativa no serviço de integridade, porque as solicitações são originadas de vários locais PoP. Para evitar a sobrecarga dos componentes downstream, o cache apropriado precisa ocorrer.
O serviço de integridade também é usado para testes de ping de URL explicitamente configurados com o recurso Application Insights de cada carimbo.
Para obter mais detalhes sobre a implementação do HealthService, consulte o Serviço de integridade do aplicativo.
Comentários
Em breve: Ao longo de 2024, eliminaremos os problemas do GitHub como o mecanismo de comentários para conteúdo e o substituiremos por um novo sistema de comentários. Para obter mais informações, consulte https://aka.ms/ContentUserFeedback.
Enviar e exibir comentários de