Tutorial – Implementar o Azure Databricks com um ponto de extremidade do Azure Cosmos DB
Este tutorial descreve como implementar uma rede virtual ambiente injetadas do Databricks com um Ponto de Extremidade de Serviço habilitado para o Azure Cosmos DB.
Neste tutorial, você aprenderá a:
- Criar um workspace do Azure Databricks em uma rede virtual
- Criar um ponto de extremidade de serviço do Azure Cosmos DB
- Criar uma conta do Azure Cosmos DB e importar dados
- Criar um cluster do Azure Databricks
- Consultar o Azure Cosmos DB de um notebook do Azure Databricks
Pré-requisitos
Antes de começar, faça o seguinte:
Baixe o conector do Spark.
Baixar dados de exemplo dos Centros Nacionais para Informações Ambientais da NOAA. Selecione um estado ou uma área e selecione Pesquisar. Na página seguinte, aceite os padrões e selecione Pesquisar. Em seguida, selecione Baixar o CSV no lado esquerdo da página para baixar os resultados.
Baixe o binário pré-compilado da Ferramenta de Migração de Dados do Azure Cosmos DB.
Criar um ponto de extremidade de serviço do Azure Cosmos DB
Quando você tiver implantado um workspace do Azure Databricks para uma rede virtual, navegue até a rede virtual no portal do Azure. Observe as sub-redes públicas e privadas que foram criadas por meio da implantação do Databricks.
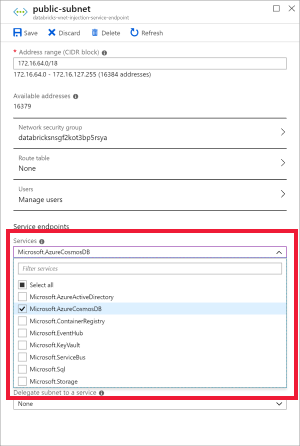
Selecione public-subnet e crie um ponto de extremidade de serviço do Azure Cosmos DB. Em seguida, Salve.
Criar uma conta do Azure Cosmos DB
Abra o portal do Azure. No lado superior esquerdo da tela, selecione Criar um recurso > Bancos de dados > Azure Cosmos DB.
Preencha os Detalhes da Instância na guia Noções Básicas com as seguintes configurações:
Configuração Valor Subscription sua assinatura Grupo de recursos seu grupo de recursos Nome da Conta db-vnet-service-endpoint API Núcleo (SQL) Location Oeste dos EUA Redundância geográfica Desabilitar Gravações de várias regiões Habilitar 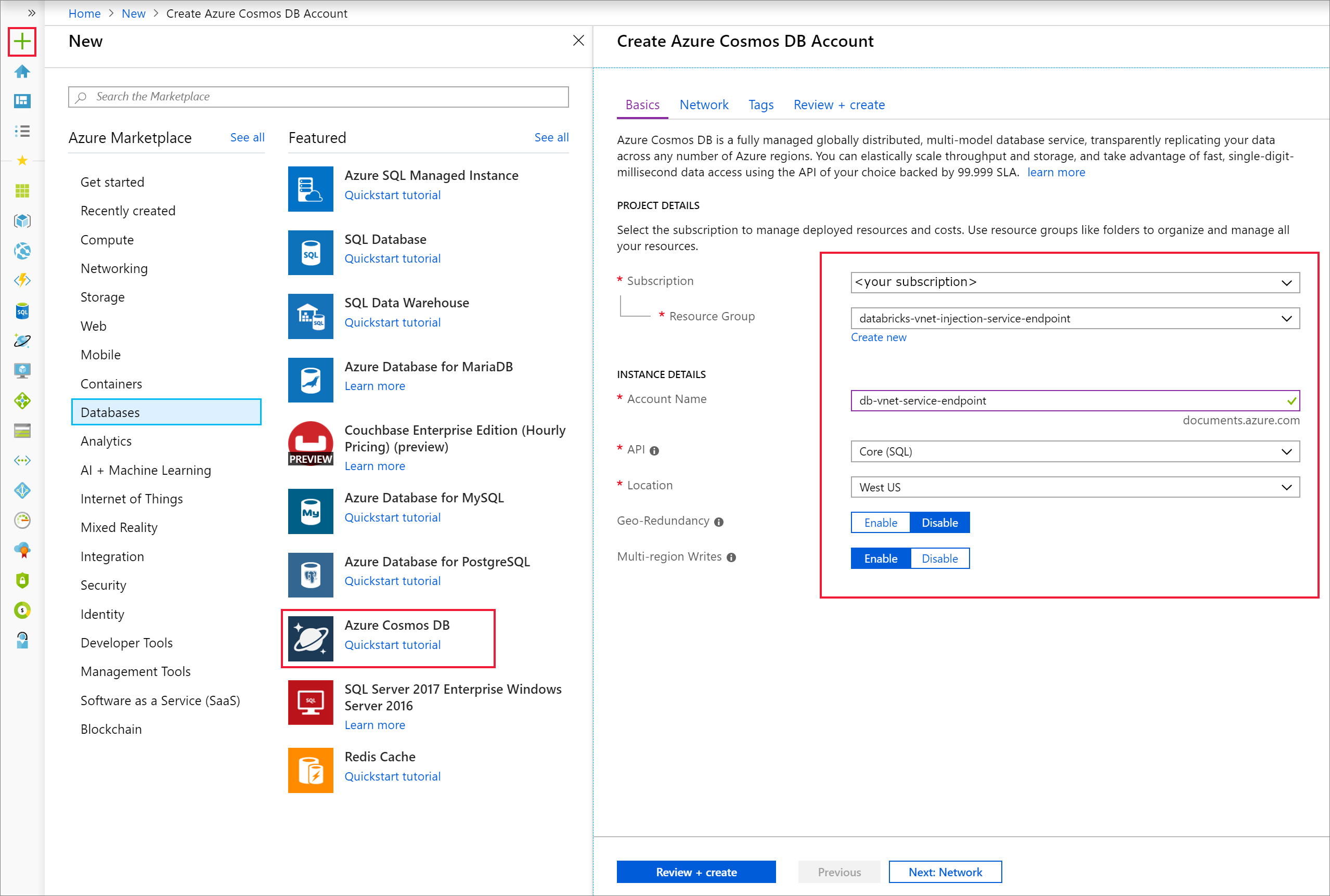
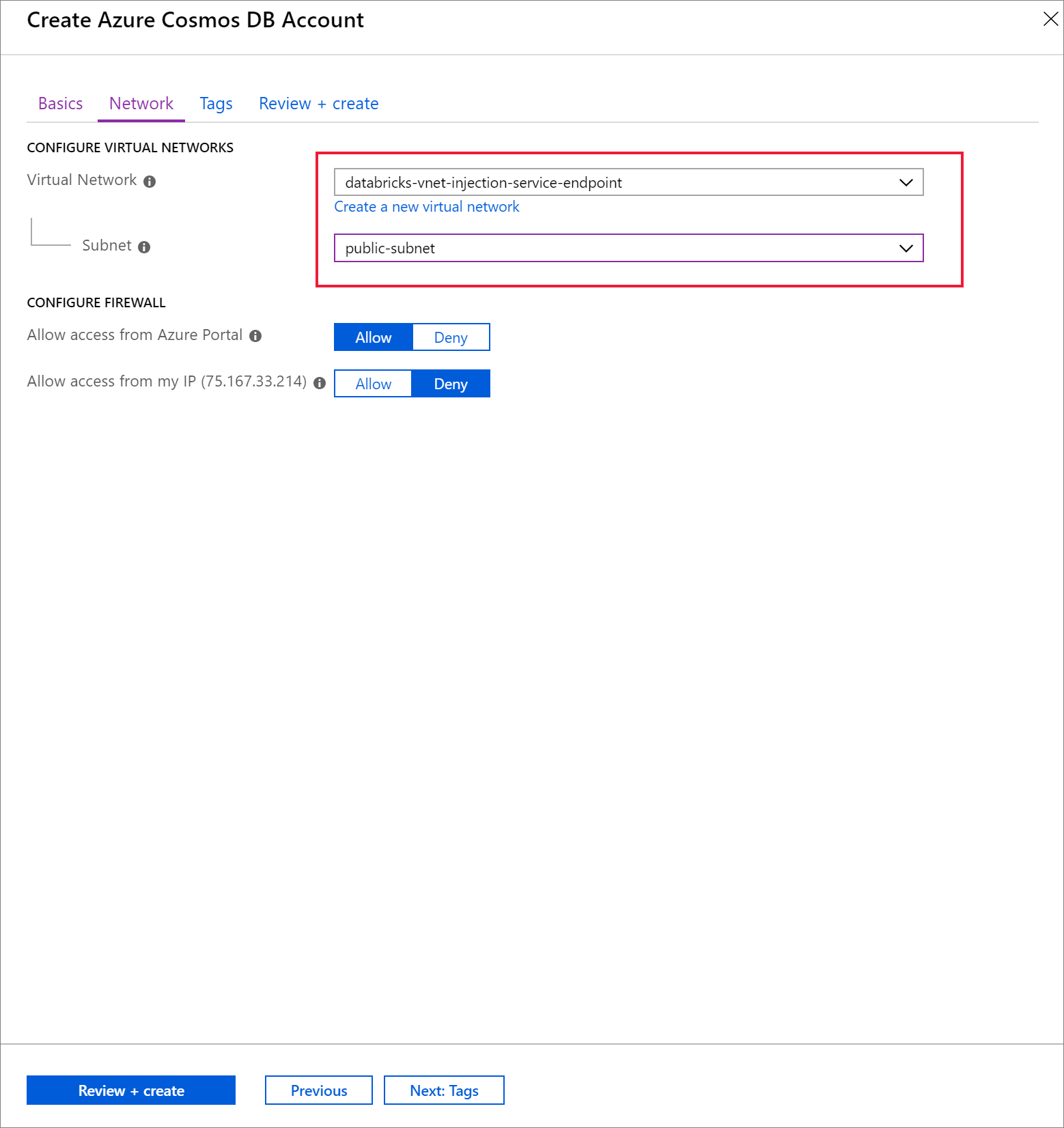
Selecione a guia Rede e configure sua rede virtual.
a. Escolha a rede virtual que você criou como pré-requisito e, em seguida, selecione public-subnet. Observe que private-subnet tem a observação O ponto de extremidade 'Microsoft AzureCosmosDB' está ausente '. Isso ocorre porque você habilitou apenas o ponto de extremidade de serviço do Azure Cosmos DB na public-subnet.
b. Verifique se você tem Permitir acesso do portal do Azure habilitado. Essa configuração permite que você acesse sua conta do Azure Cosmos DB no portal do Azure. Se essa opção estiver definida como Negar, você receberá erros ao tentar acessar sua conta.
Observação
Não é necessário para este tutorial, mas você também pode habilitar Permitir acesso do meu IP se quiser ter a capacidade de acessar sua conta do Azure Cosmos DB em seu computador local. Por exemplo, se você estiver se conectando à sua conta usando o SDK do Azure Cosmos DB, precisará habilitar essa configuração. Se estiver desabilitada, você receberá erros de "Acesso Negado".
Selecione Examinar + Criar e então Criar para criar sua conta do Azure Cosmos DB dentro da rede virtual.
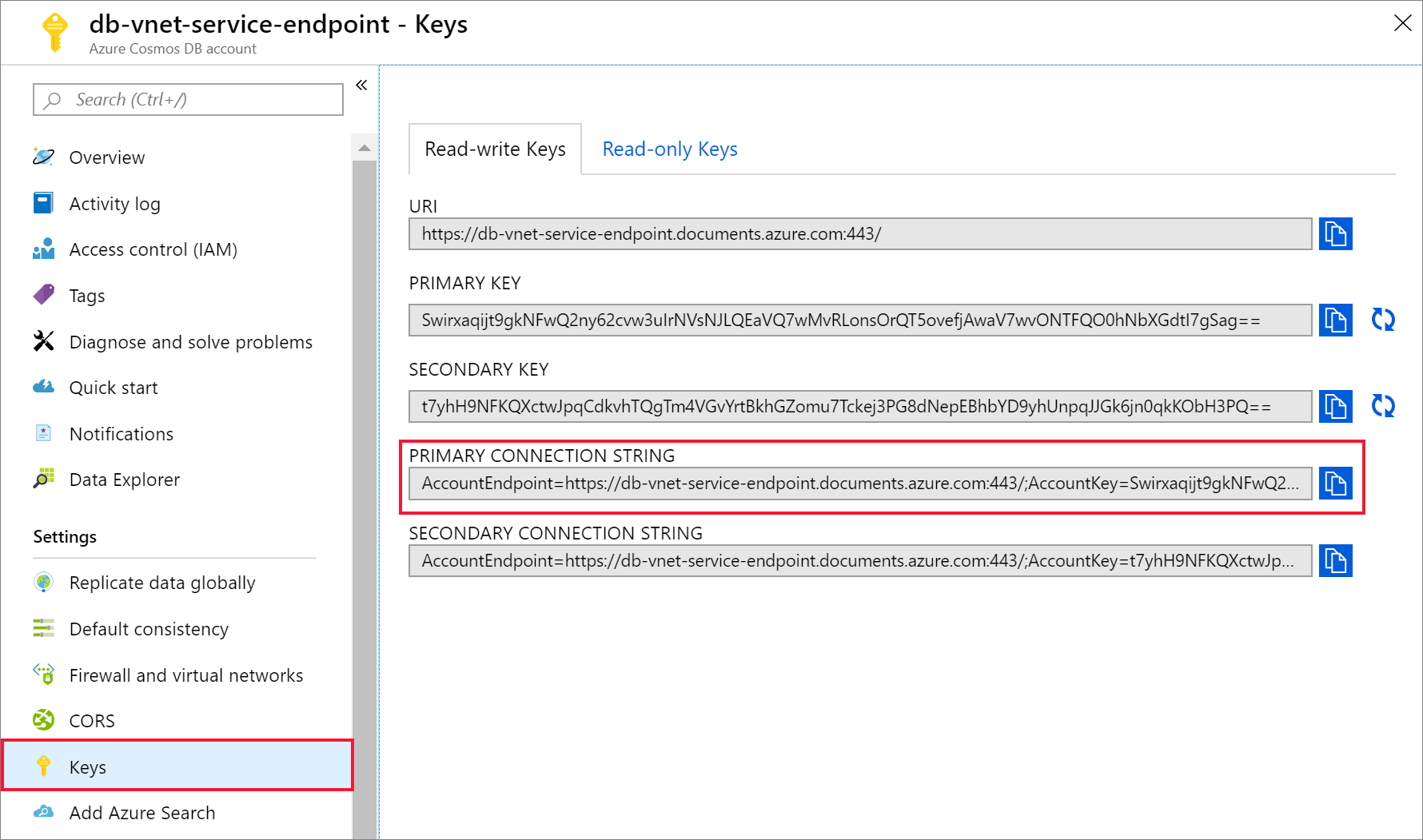
Quando sua conta do Azure Cosmos DB tiver sido criada, navegue até Chaves em Configurações. Copie a cadeia de conexão primária e salve-a em um editor de texto para uso posterior.
Selecione Data Explorer e Novo Contêiner para adicionar um novo banco de dados e um contêiner à conta do Azure Cosmos DB.
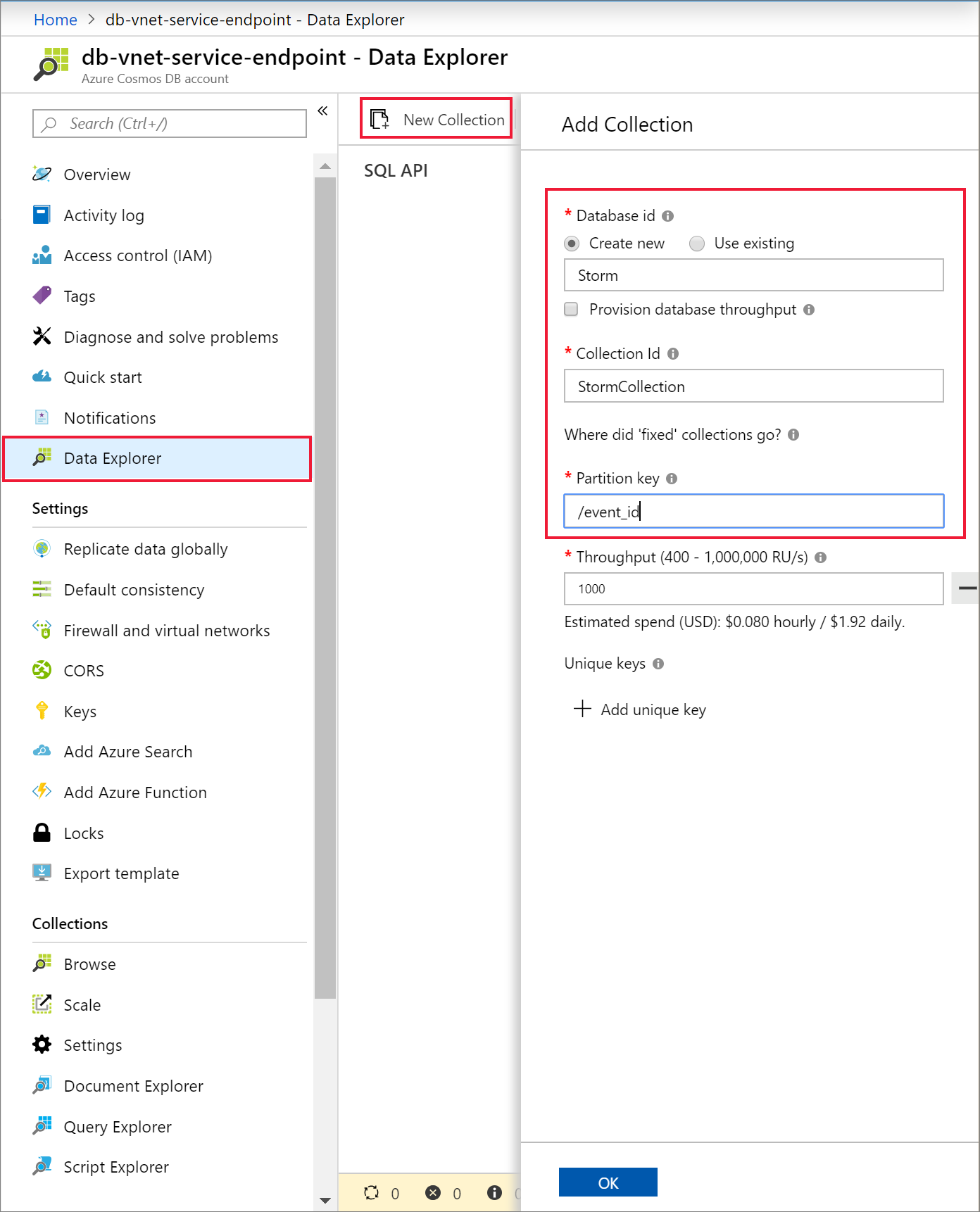
Carregar dados no Azure Cosmos DB
Abra a versão da interface gráfica da ferramenta de migração de dados para o Azure Cosmos DB, Dtui.exe.
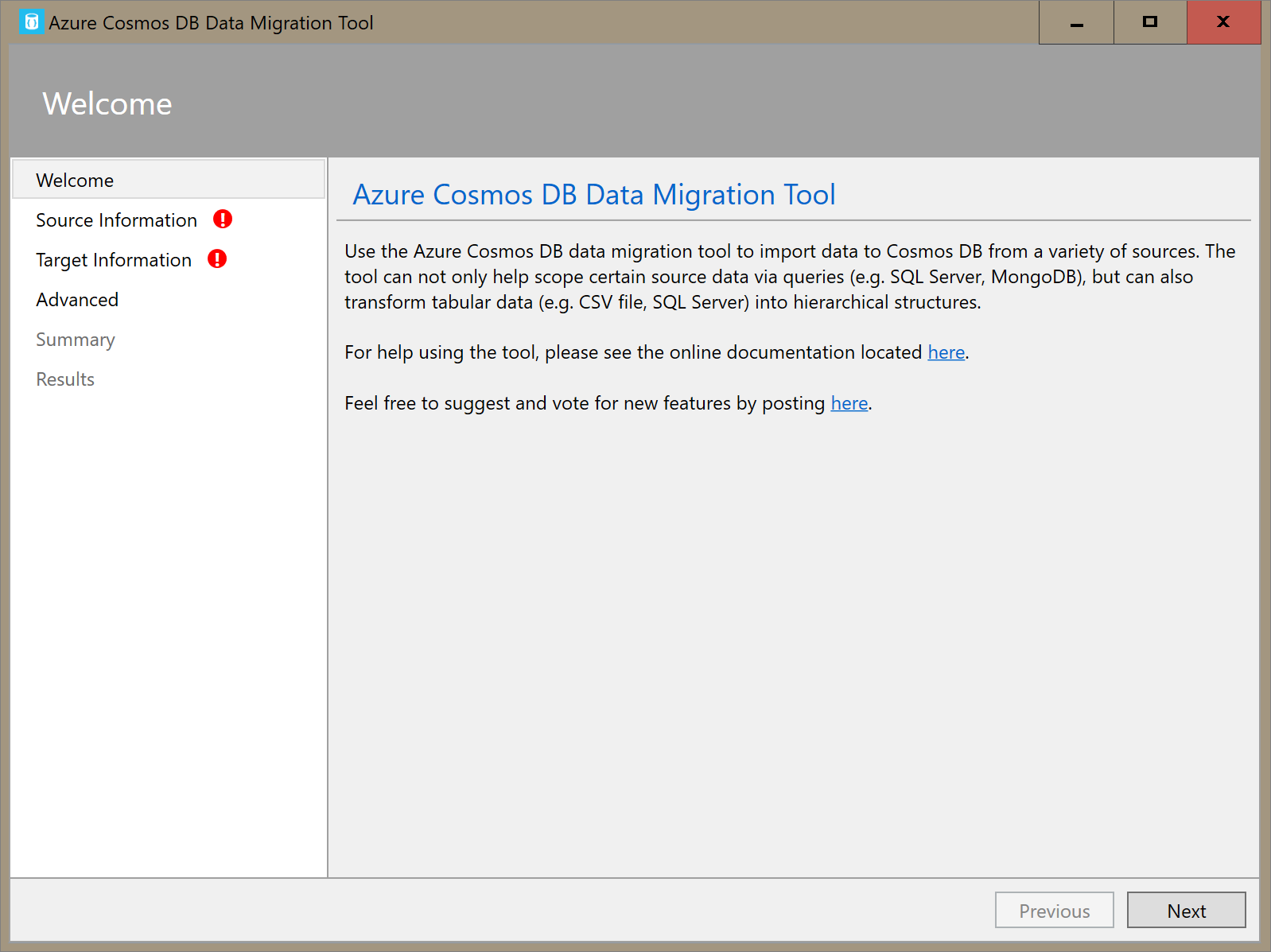
Na guia Informações de Origem, selecione Arquivo(s) CSV na lista suspensa Importar de. Em seguida, selecione Adicionar Arquivos e adicione os dados CSV que você baixou do storm como um pré-requisito.
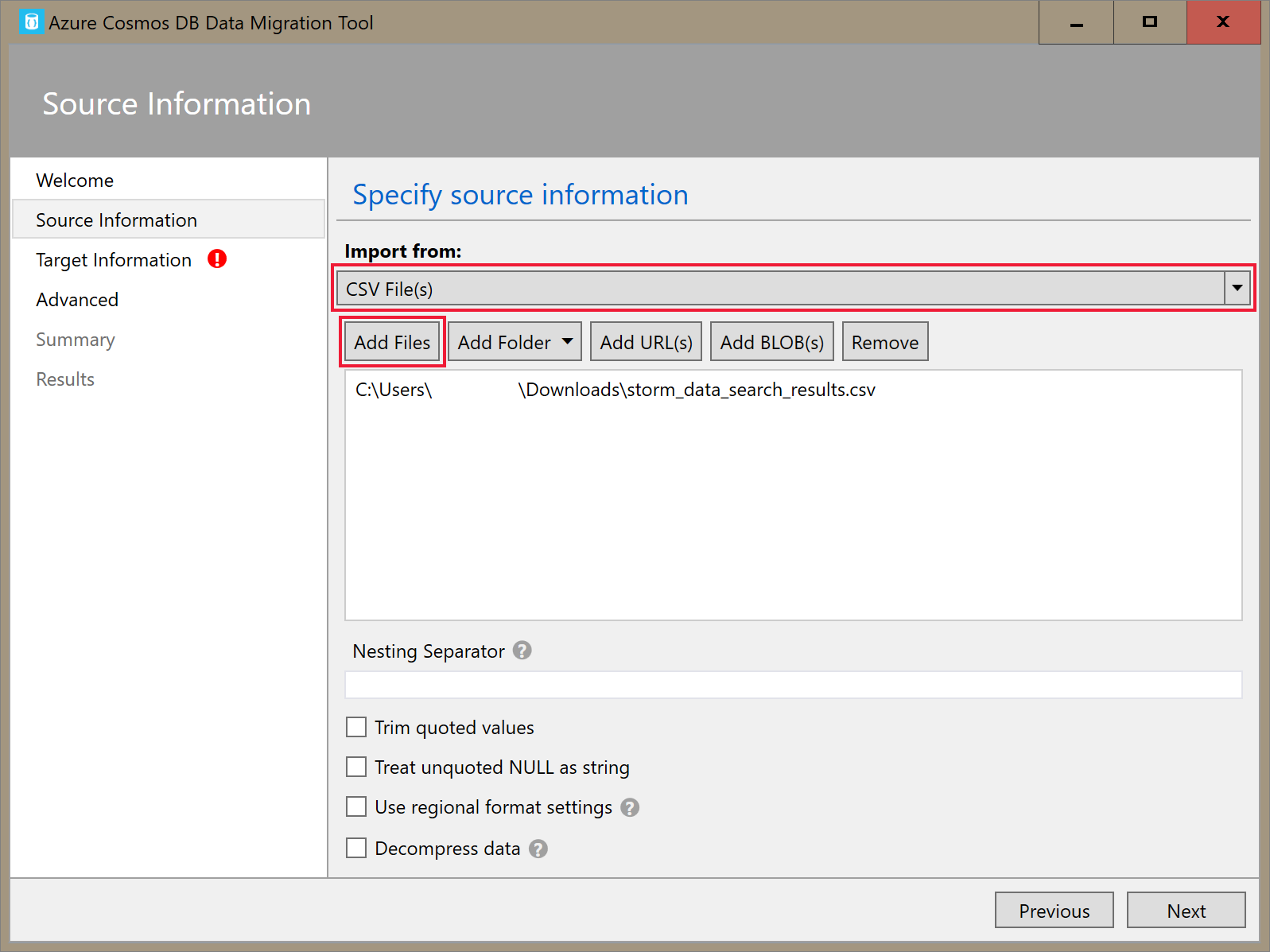
Na guia Informações sobre o Destino, insira sua cadeia de conexão. O formato da cadeia de conexão é
AccountEndpoint=<URL>;AccountKey=<key>;Database=<database>. AccountEndpoint e AccountKey estão incluídos na cadeia de conexão primária que você salvou na seção anterior. AcrescenteDatabase=<your database name>ao final da cadeia de conexão e selecione Verificar. Em seguida, adicione a chave de partição e o nome do contêiner.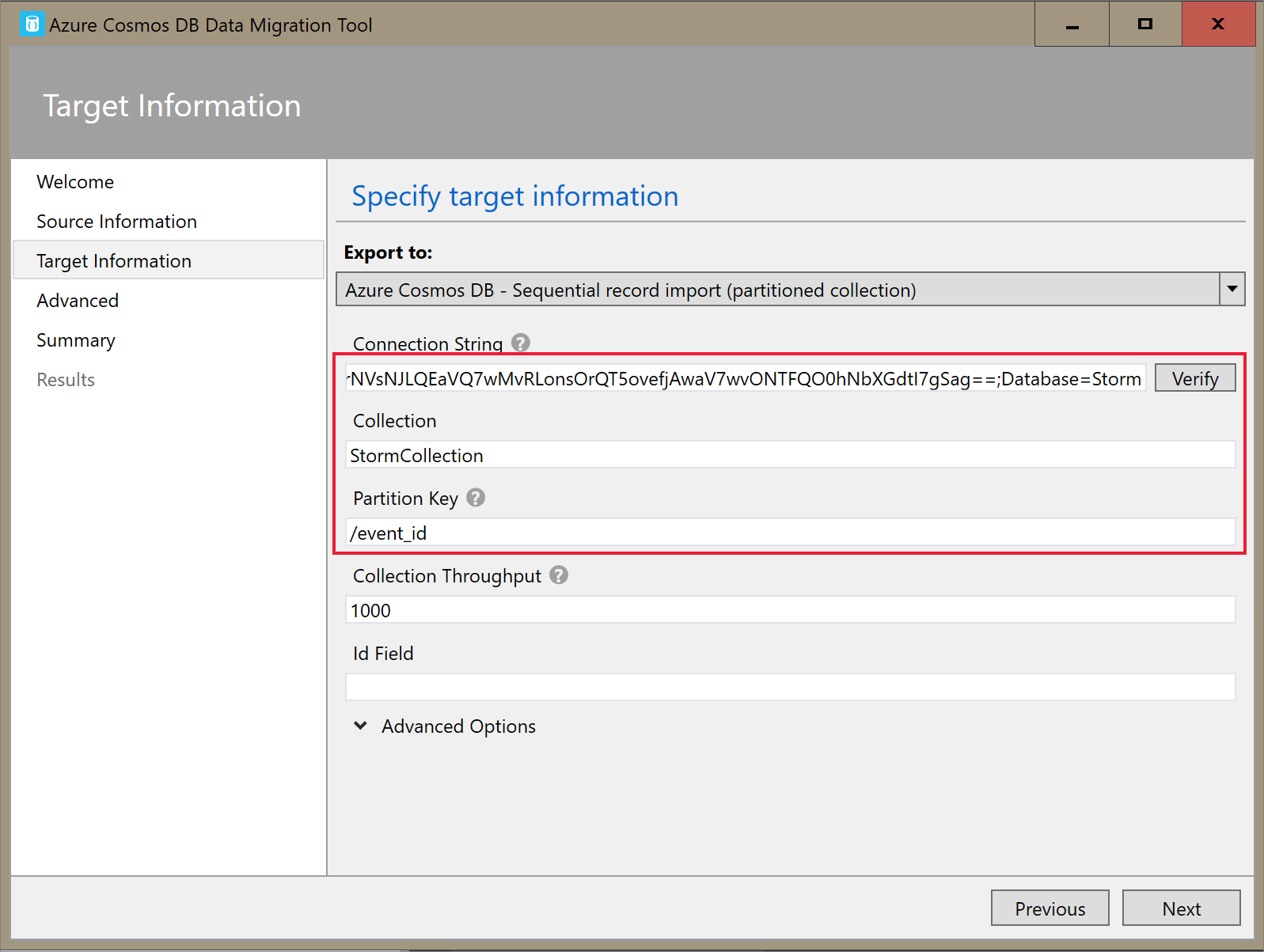
Selecione Avançar até chegar à página de Resumo. Em seguida, selecione Importar.
Criar um cluster e adicionar a biblioteca
Navegue até o serviço do Azure Databricks no portal do Azure e selecione Inicializar workspace.
Crie um novo cluster. Escolha um Nome de Cluster e aceite as configurações padrão restantes.
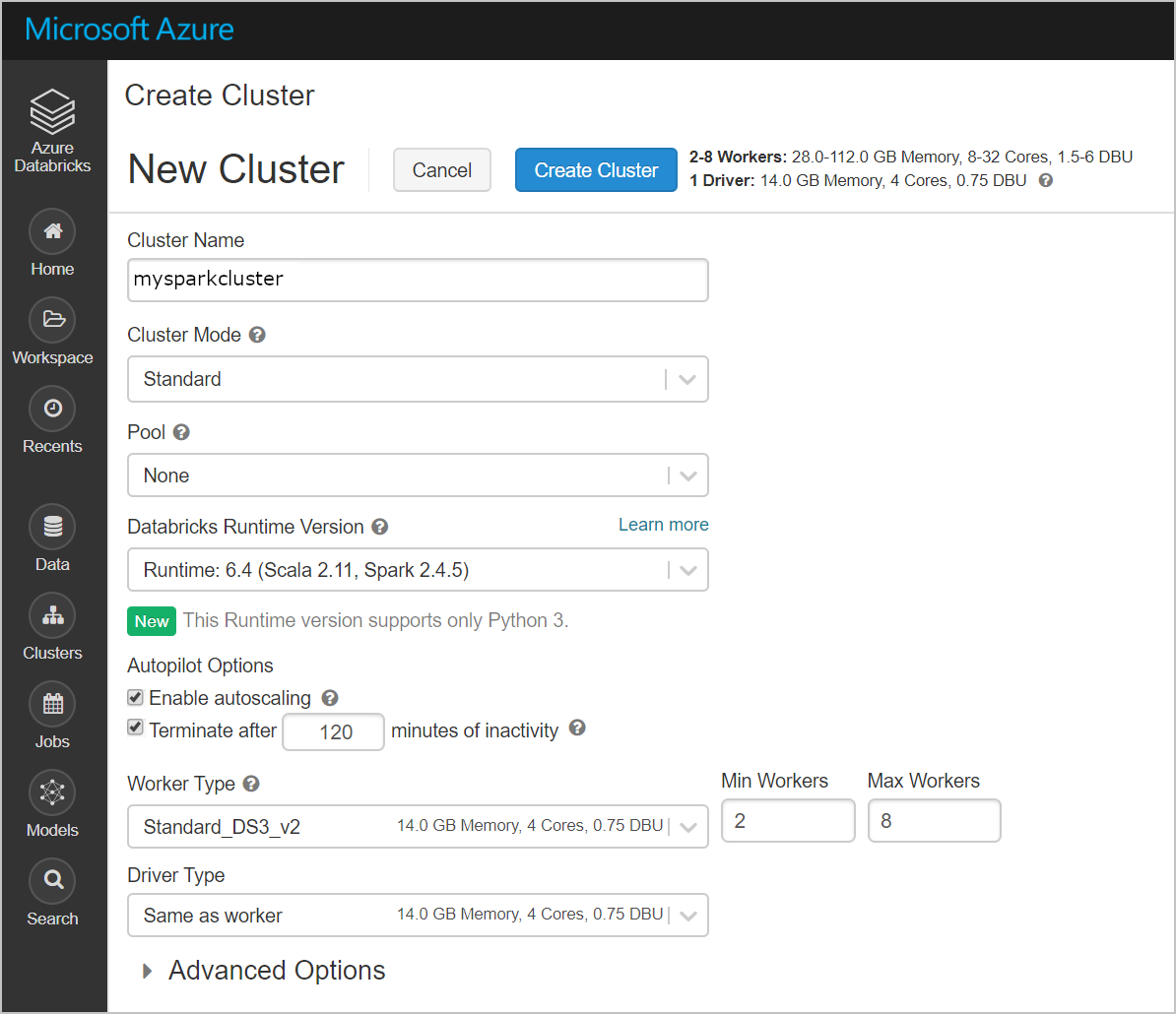
Depois que o cluster for criado, navegue até a página do cluster e selecione a guia Bibliotecas. Selecione Instalar Novo e carregue o arquivo jar do conector Spark para instalar a biblioteca.
Você pode verificar se a biblioteca foi instalada na guia Bibliotecas.

Consultar o Azure Cosmos DB de um notebook do Databricks
Navegue até seu workspace do Azure Databricks e crie um novo notebook do Python.
Execute o seguinte código do Python para definir a configuração de conexão do Azure Cosmos DB. Altere o Ponto de Extremidade, a Chave Mestra, o Banco de Dados e o Contêiner adequadamente.
connectionConfig = { "Endpoint" : "https://<your Azure Cosmos DB account name.documents.azure.com:443/", "Masterkey" : "<your Azure Cosmos DB primary key>", "Database" : "<your database name>", "preferredRegions" : "West US 2", "Container": "<your container name>", "schema_samplesize" : "1000", "query_pagesize" : "200000", "query_custom" : "SELECT * FROM c" }Use o seguinte código Python para carregar os dados e criar uma exibição temporária.
users = spark.read.format("com.microsoft.azure.cosmosdb.spark").options(**connectionConfig).load() users.createOrReplaceTempView("storm")Use o seguinte comando mágico para executar uma instrução SQL que retorna dados.
%sql select * from stormVocê conectou com sucesso seu workspace do Databricks injetado por VNet a um recurso do Azure Cosmos DB habilitado para ponto de extremidade de serviço. Para ler mais sobre como conectar-se ao Azure Cosmos DB, veja Conector do Azure Cosmos DB para Apache Spark.
Limpar os recursos
Quando não forem mais necessário, exclua o grupo de recursos, o workspace do Azure Databricks e todos os recursos relacionados. Excluir o trabalho evita cobrança desnecessária. Se você está planejando usar o workspace do Azure Databricks no futuro, pode parar o cluster e reiniciá-lo mais tarde. Se você não pretende continuar a usar esse workspace do Azure Databricks, exclua todos os recursos criados neste tutorial usando as seguintes etapas:
No menu à esquerda no portal do Azure, clique em Grupos de recursos e depois clique no nome do grupo de recursos criado.
Em sua página de grupo de recursos, selecione Excluir, digite o nome do recurso a ser excluído na caixa de texto e selecione Excluir.
Próximas etapas
Neste tutorial, você implantou um workspace do Azure Databricks a uma rede virtual e usou o conector Spark do Azure Cosmos DB para consultar dados do Azure Cosmos DB do Databricks. Para saber mais sobre como trabalhar com o Azure Databricks em uma rede virtual, continue com o tutorial usando o SQL Server com o Azure Databricks.