Agregação e exibição das métricas do Azure Monitor explicadas
Este artigo explica a agregação de métricas no banco de dados Azure Monitor série temporal que possibilitam as métricas de plataforma e as métricas personalizadas do Azure Monitor. Este artigo também se aplica às métricas de Application Insightspadrão.
Este é um tópico complexo e não é necessário entender todas as informações neste artigo para usar as métricas do Azure Monitor com eficiência.
Visão geral e termos
Quando você adiciona uma métrica a um gráfico, o Metrics Explorer seleciona automaticamente a sua agregação padrão. O padrão faz sentido nos cenários básicos, mas você pode usar agregações diferentes para obter mais informações sobre a métrica. A exibição de agregações diferentes em um gráfico requer que você entenda como o Metrics Explorer as manipula.
Primeiro, vamos definir alguns termos claramente:
- Valor de métrica – um valor de medida único coletado para um recurso específico.
- Banco de dados de série temporal - um banco de dados otimizado para o armazenamento e a recuperação de pontos de dados que contêm um valor e um carimbo de data/hora correspondente.
- Período de tempo – um período de tempo genérico.
- Intervalo de tempo – o período de tempo entre a coleta de dois valores de métrica.
- Intervalo de tempo – o período de tempo exibido em um gráfico. O padrão típico é de 24 horas. Somente intervalos específicos estão disponíveis.
- Granularidade de tempo ou intervalo de tempo – o período de tempo usado para agregar valores em conjunto para permitir a exibição em um gráfico. Somente intervalos específicos estão disponíveis. O mínimo atual é 1 minuto. Para ser útil, o valor de granularidade de tempo deve ser menor do que o intervalo de tempo selecionado. Caso contrário, apenas um valor é mostrado para todo o gráfico.
- Tipo de agregação – um tipo de estatística calculada de vários valores de métrica.
- Agregação – o processo de coletar vários valores de entrada e, em seguida, usá-los para produzir um único valor de saída por meio das regras definidas pelo tipo de agregação. Por exemplo, usando uma média de vários valores.
Resumo das tarefas
As métricas são uma série de valores armazenados com um carimbo de data/hora. No Azure, a maioria das métricas é armazenada no banco de dados de série temporal de métricas do Azure. Quando você plota um gráfico, os valores das métricas selecionadas são recuperados do banco de dados e, em seguida, agregados separadamente com base na granularidade de tempo escolhida (também conhecida como intervalo de tempo). Selecione o tamanho da granularidade de tempo usando o seletor de tempo do gerenciador de métricas. Se você não fizer uma seleção explícita, a granularidade de tempo será selecionada automaticamente com base no intervalo de tempo atualmente selecionado. Uma vez selecionados, os valores de métrica que foram capturados durante cada intervalo de granularidade de tempo são agregados e colocados no gráfico – um ponto de dados por intervalo.
Tipos de agregação
Há cinco tipos de agregação básicos disponíveis no Metrics Explorer. O Metrics Explorer oculta as agregações que são irrelevantes e não podem ser usadas por uma determinada métrica.
- Soma – a soma de todos os valores capturados durante o intervalo de agregação. Às vezes, chamado de agregação total.
- Contagem – o número de medições capturadas durante o intervalo de agregação. A contagem não examina o valor da medida, apenas o número de registros.
- Média – a média dos valores de métrica capturados durante o intervalo de agregação. Para a maioria das métricas, esse valor é soma/contagem.
- Min – o menor valor capturado durante o intervalo de agregação.
- Max – o maior valor capturado durante o intervalo de agregação.
Por exemplo, suponha que um gráfico esteja mostrando a métrica total da rede para uma máquina virtual usando a agregação SUM durante o último período de 24 horas. O intervalo de tempo e a granularidade podem ser alterados do canto superior direito do gráfico, conforme mostrado na captura de tela a seguir.
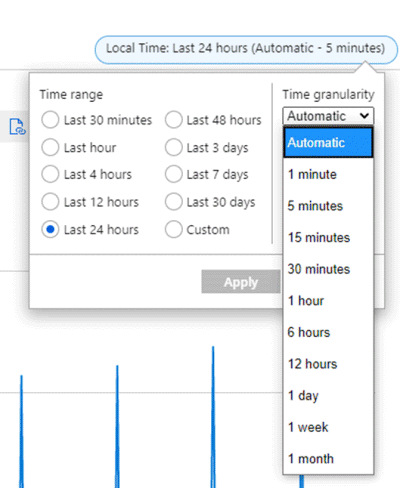
Para granularidade de tempo = 30 minutos e o intervalo de tempo = 24 horas:
- O gráfico é desenhado a partir de 48 pontos de dados. Isso é 24 horas x 2 pontos de dados por hora (60 min/30 min) agregados de pontos de dados de 1 minuto.
- O gráfico de linhas conecta 48 pontos na área de plotagem do gráfico.
- Cada ponto de dados representa a soma de todos os bytes de saída de rede enviados durante cada um dos períodos de tempo de 30 minutos relevantes.

Clique nas imagens desta seção para ver as versões maiores.
Se você alterar a granularidade de tempo para 15 minutos, o gráfico será desenhado a partir de 96 pontos de dados agregados. Ou seja, 60 min/15 min = 4 pontos de dados por hora x 24 horas.

Para a granularidade de tempo de 5 minutos, você obtém 24 x (60/5) = 288 pontos.
Para a granularidade de tempo de 1 minuto (o menor possível no gráfico), você obtém 24 x 60/1 = 1440 pontos.

Os gráficos parecem diferentes para essas somas, conforme mostrado nas capturas de tela anteriores. Observe como essa máquina virtual tem muita saída em um período de tempo pequeno em relação ao restante da janela de tempo.
A granularidade de tempo permite ajustar a proporção de "sinal para ruído" em um gráfico. As agregações mais altas removem os picos de ruído e suavização. Observe as variações no gráfico de 1 minuto inferior e como elas são suavizadas à medida que você passa para valores de granularidade mais altos.
Esse comportamento de suavização é importante quando você envia esses dados para outros sistemas, por exemplo, alertas. Normalmente, você não deseja ser alertado por picos muito curtos no tempo de CPU em mais de 90%. Mas se a CPU permanecer em 90% por 5 minutos, isso provavelmente é importante. Se você configurar uma regra de alerta na CPU (ou em qualquer métrica), tornar a granularidade de tempo maior pode reduzir o número de alertas falsos recebidos.
É importante estabelecer o que é "normal" para sua carga de trabalho para saber que intervalo de tempo é melhor. Esse é um dos benefícios dos alertas dinâmicos, que é um tópico diferente não abordado aqui.
Como o sistema coleta métricas
A coleta de dados varia de acordo com a métrica.
Frequência de coleta de medidas
Há dois tipos de períodos de coletas.
Regular – a métrica é coletada em um intervalo de tempo consistente que não varia.
Baseado em atividade – a métrica é coletada com base em quando uma transação de um determinado tipo ocorre. Cada transação tem uma entrada de métrica e um carimbo de data/hora. Elas não são coletadas em intervalos regulares, portanto, há um número variável de registros em um determinado período de tempo.
Granularidade
A granularidade de tempo mínima é de 1 minuto, mas o sistema subjacente pode capturar dados mais rápido dependendo da métrica. Por exemplo, a porcentagem de CPU para uma VM do Azure é capturada em um intervalo de tempo de 15 segundos. Como as falhas de HTTP são rastreadas como transações, elas podem facilmente levar muito mais de um minuto. Outras métricas, como SQL Storage, são capturadas em um intervalo de tempo a cada 20 minutos. Essa opção depende do provedor de recursos individual e do tipo. A maioria tenta fornecer o menor intervalo de tempo possível.
Dimensões, divisão e filtragem
As métricas são capturadas para cada recurso individual. No entanto, o nível no qual as métricas são coletadas, armazenadas e demonstradas em gráficos pode variar. Esse nível é representado por métricas adicionais disponíveis nas dimensões de métricas. Cada provedor de recursos individual obtém a definição de como os dados coletados são detalhados. O Azure Monitor define apenas como esses detalhes devem ser apresentados e armazenados.
Quando você fornece um gráfico de uma métrica no Metrics Explorer, tem a opção de "dividir" o gráfico por uma dimensão. Dividir um gráfico significa que você está procurando os dados subjacentes para obter mais detalhes e ver os dados em gráfico ou filtrados no Metrics Explorer.
Por exemplo, o Microsoft.ApiManagement/Service tem o local como uma dimensão para diversas métricas.
A capacidade é uma dessas métricas. Ter a dimensão de local implica que o sistema subjacente está armazenando um registro de métrica para a capacidade de cada local, em vez de apenas um para o valor agregado. Em seguida, você pode recuperar ou dividir essas informações em um gráfico de métricas.
Observando a duração geral das solicitações de gateway, há duas dimensões local e nome do host, novamente informando você sobre o local de uma duração e de qual nome do host ele veio.
Uma das métricas mais flexíveis, solicitações, tem sete dimensões diferentes.
Verifique o artigo métricas com suporte do Azure Monitor para obter detalhes sobre cada métrica e as dimensões disponíveis. Além disso, a documentação para cada provedor de recursos e tipo pode fornecer informações adicionais sobre as dimensões e o que elas medem.
Você pode usar a divisão e a filtragem em conjunto para se aprofundar em um problema. Abaixo está o exemplo de um gráfico mostrando Bytes Médios de Gravação de Disco para um grupo de máquinas virtuais em um grupo de recursos. Temos um acúmulo de todas as máquinas virtuais com essa métrica, mas talvez queiramos nos aprofundar para ver quais, na verdade, são responsáveis pelos picos em torno das 6h. Eles são do mesmo computador? Quantos computadores estão envolvidos?

Clique nas imagens desta seção para ver as versões maiores.
Quando aplicamos a divisão, podemos ver os dados subjacentes, mas isso é pouco bagunçado. Acontece que há 20 máquinas virtuais sendo agregadas no gráfico acima. Nesse caso, usamos nosso mouse para focalizar no grande pico ocorrido às 6h que nos diz que CH-DCVM11 é a causa. No entanto, é difícil ver o restante dos dados associados a essa máquina virtual por causa de outras máquinas obstruindo o gráfico.

O uso da filtragem nos permite limpar o gráfico para ver o que realmente está acontecendo. Você pode marcar ou desmarcar as máquinas virtuais que deseja ver. Observe as linhas pontilhadas. Elas são mencionadas em uma seção posterior.

Para obter mais informações sobre como mostrar dados de dimensão dividida em um gráfico do gerenciador de métricas, consulte Recursos avançados do Metrics Explorer – filtros e divisão.
Valores nulos e zero
Quando o sistema espera dados de métrica de um recurso, mas não o recebe, ele registra um valor nulo. O NULL (nulo) é diferente de um valor zero, que se torna importante no cálculo de agregações e gráficos. Os valores nulos não são contados como medidas válidas.
Os nulos aparecem de forma diferente em diferentes gráficos. As plotagens de dispersão ignoram a exibição de um ponto no gráfico. Os gráficos de barras não exibem a barra. Em gráficos de linhas, valores NULL podem aparecer como linhas pontilhadas ou tracejadas como as mostradas na captura de tela da seção anterior. Ao calcular as médias que incluem os valores nulos, há menos pontos de dados dos quais obter a média. Esse comportamento, às vezes, pode resultar numa queda inesperada dos valores em um gráfico, embora geralmente menor que se o valor fosse convertido em um zero e usado como um ponto de dados válido.
As métricas personalizadas sempre usam valores nulos quando nenhum dado é recebido. Com as métricas de plataforma, cada provedor de recursos decide se deve usar zeros ou nulos com base no que faz mais sentido para uma determinada métrica.
Os alertas do Azure Monitor usam os valores que o provedor de recursos grava no banco de dados de métricas. Portanto, é importante saber como o provedor de recursos lida com os nulos exibindo os dados primeiro.
Como funciona a agregação
Os gráficos de métricas no sistema anterior mostram tipos diferentes de dados agregados. O sistema agrega os dados previamente para que os gráficos solicitados possam ser exibidos mais rapidamente sem muita computação repetida.
Neste exemplo:
- Estamos coletando uma métrica transacional fictícia chamada falhas de HTTP
- Servidor é uma dimensão para a métrica de falhas de HTTP.
- Temos três servidores – servidor A, B e C.
Para simplificar a explicação, começaremos apenas com o tipo de agregação SUM.
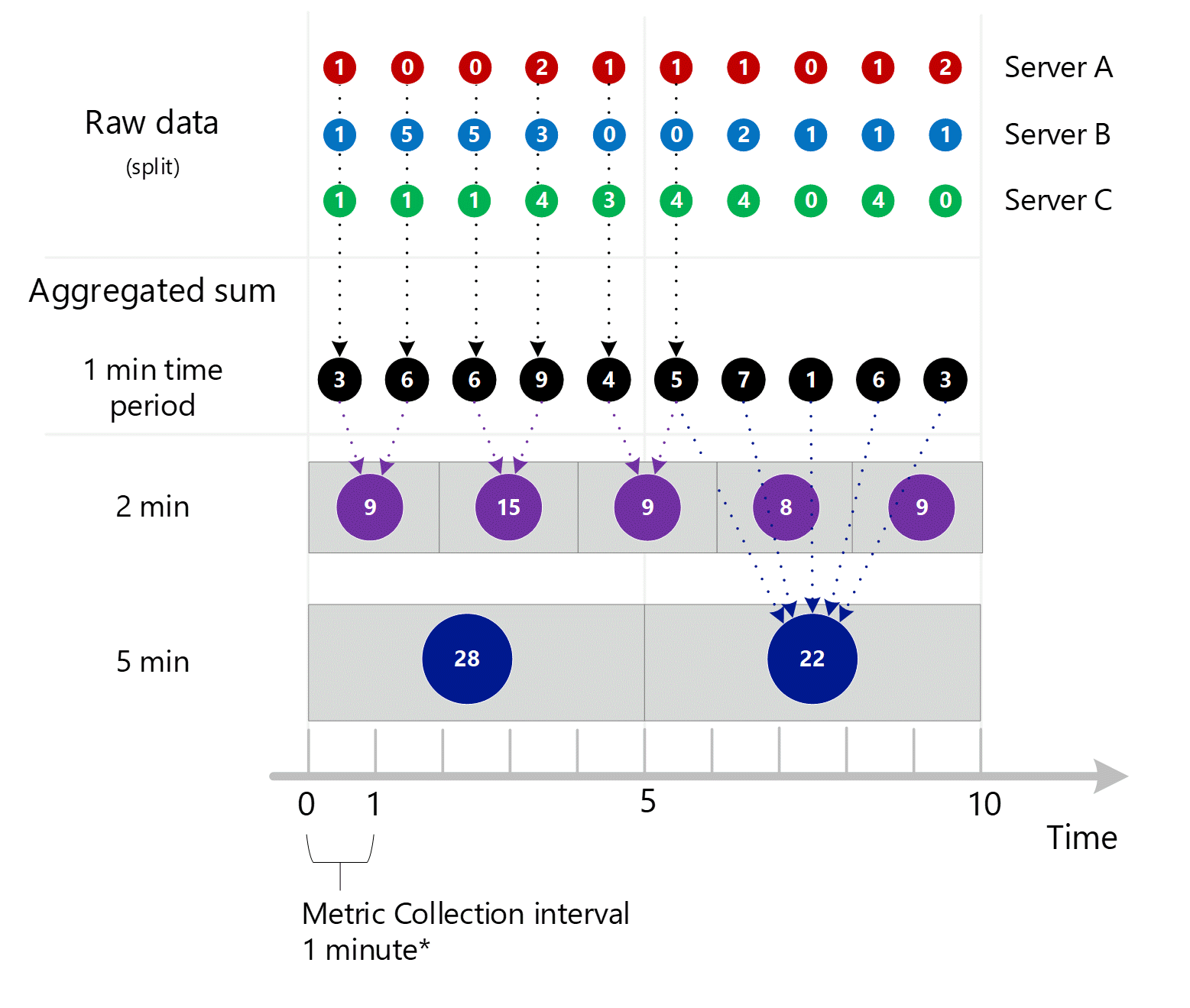
Subminuto para agregação de 1 minuto
Os primeiros dados de métrica brutos são coletados e armazenados no banco de dados de métricas do Azure Monitor. Nesse caso, cada servidor tem registros de transação armazenados com um carimbo de data/hora porque o servidor é uma dimensão. Levando-se em conta que o menor período de tempo que você pode exibir como um cliente é de 1 minuto, esses carimbos de data/hora são agregados primeiro em valores de métrica de 1 minuto para cada servidor individual. O processo de agregação para o servidor B é mostrado no gráfico abaixo. Os servidores A e C são realizados da mesma maneira e têm dados diferentes.
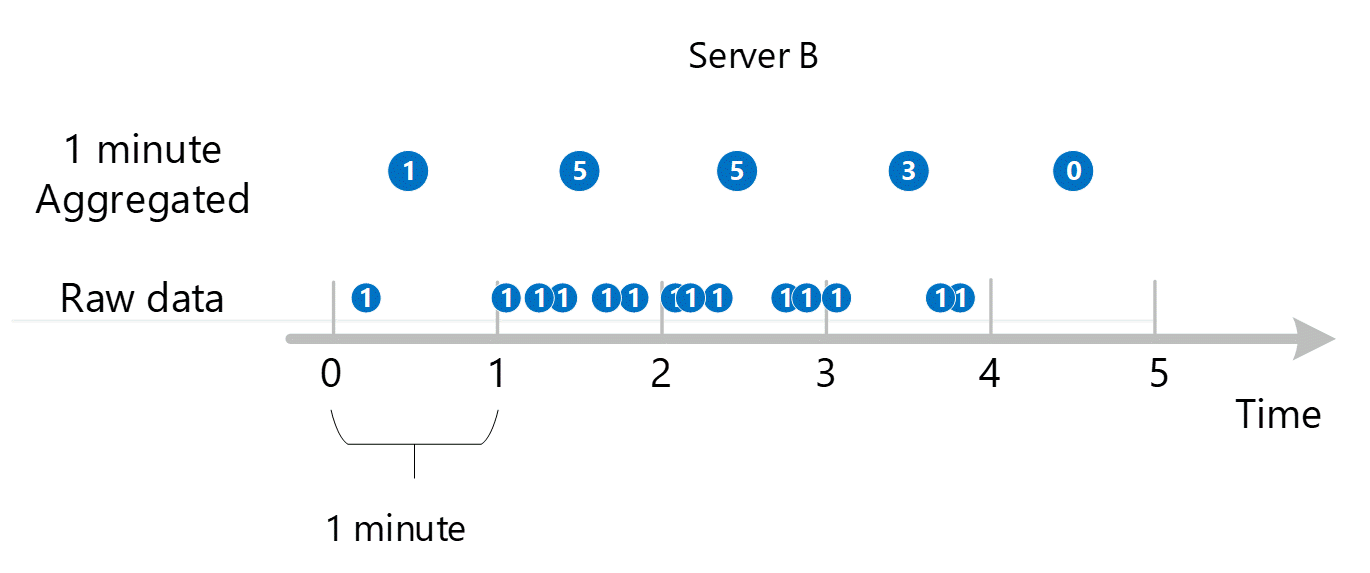
Os valores agregados de 1 minuto resultantes são armazenados como novas entradas no banco de dados de métricas para que possam ser coletados para cálculos posteriores.
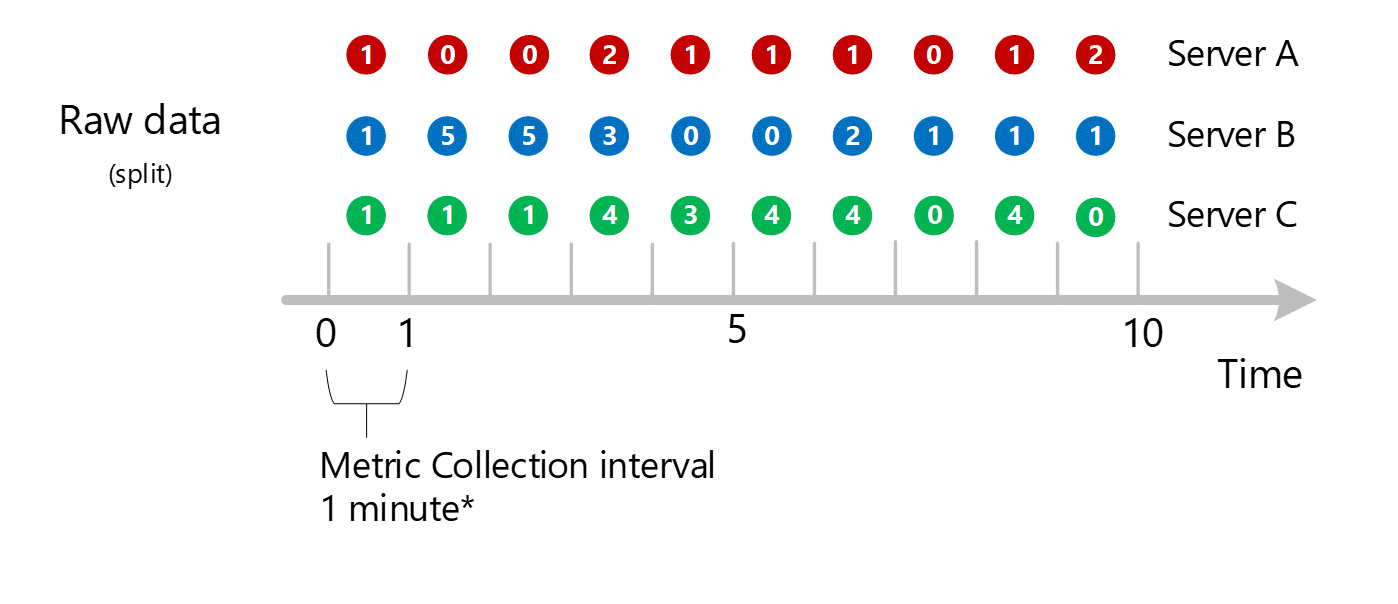
Agregação de dimensão
Os cálculos de 1 minuto são então recolhidos pela dimensão e novamente armazenados como registros individuais. Nesse caso, todos os dados de todos os servidores individuais são agregados em uma métrica de intervalo de 1 minuto e armazenados no banco de dados de métricas para uso em agregações posteriores.
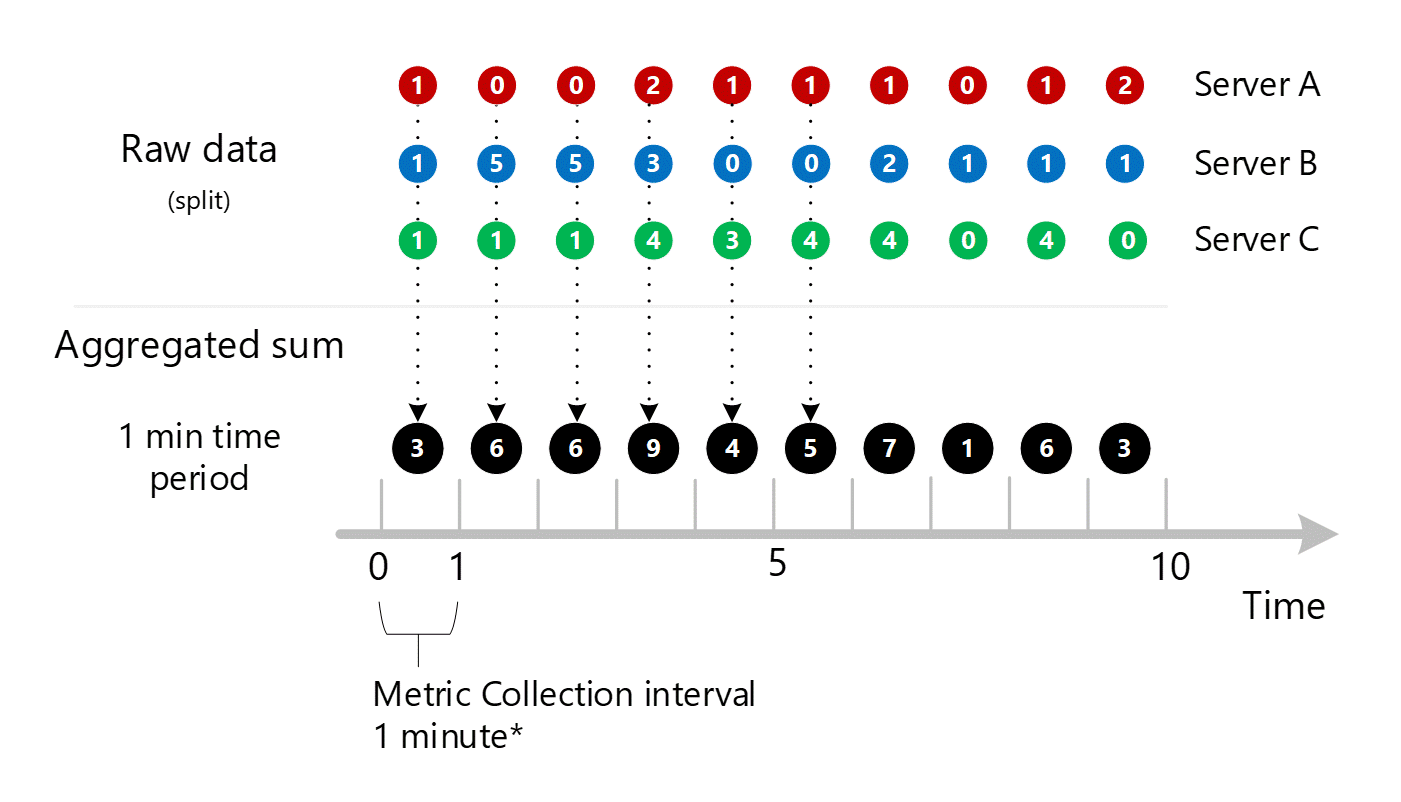
Para maior clareza, a tabela a seguir mostra o método de agregação.
| Período | Servidor A | Servidor B | o Servidor C | Soma (A + B + C) |
|---|---|---|---|---|
| Minuto 1 | 1 | 1 | 1 | 3 |
| Minuto 2 | 0 | 5 | 1 | 6 |
| Minuto 3 | 0 | 5 | 1 | 6 |
| Minuto 4 | 2 | 3 | 4 | 9 |
| Minuto 5 | 1 | 0 | 3 | 4 |
| Minuto 6 | 1 | 0 | 4 | 5 |
| Minuto 7 | 1 | 2 | 4 | 7 |
| Minuto 8 | 0 | 1 | 0 | 1 |
| Minuto 9 | 1 | 1 | 4 | 6 |
| Minuto 10 | 2 | 1 | 0 | 3 |
Somente uma dimensão é mostrada acima, mas esse mesmo processo de agregação e armazenamento ocorre para todas as dimensões às quais uma métrica dá suporte.
- Colete valores em um conjunto agregado de 1 minuto por essa dimensão. Armazene esses valores.
- Recolha a dimensão em uma soma agregada de 1 minuto. Armazene esses valores.
Vamos apresentar outra dimensão de falhas de HTTP chamada NetworkAdapter. Considere que temos um número variável de adaptadores por servidor.
- O servidor A tem um adaptador
- O servidor B tem dois adaptadores
- O servidor C tem três adaptadores
Coletamos dados para as transações a seguir separadamente. Eles serão marcados com:
- Uma hora
- Um valor
- O servidor de origem da transação
- O adaptador de origem da transação
Cada um desses fluxos de subminutos seria agregado em valores de série temporal de 1 minuto e armazenado no banco de dados de métricas do Azure Monitor:
- Servidor A, adaptador 1
- Servidor B, adaptador 1
- Servidor B, adaptador 2
- Servidor C, adaptador 1
- Servidor C, adaptador 2
- Servidor C, adaptador 3
Além disso, as seguintes agregações recolhidas também seriam armazenadas:
- Servidor A, adaptador 1 (porque não há nada a ser recolhido, ele seria armazenado novamente)
- Servidor B, adaptador 1+2
- Servidor C, adaptador 1+2+3
- Todos os servidores, todos os adaptadores
Isso mostra que as métricas com grandes números de dimensões têm um número maior de agregações. Não é importante conhecer todas as permutas, apenas entender o raciocínio. O sistema deseja ter os dados individuais e os dados agregados armazenados para a recuperação rápida do acesso a qualquer gráfico. O sistema escolhe a agregação armazenada mais relevante ou os dados brutos subjacentes, dependendo do que você escolher para exibir.
Agregação sem dimensões
Como essa métrica tem um servidorde dimensão, você pode obter os dados subjacentes para o servidor A, B e C acima por meio de divisão e filtragem, conforme explicado anteriormente neste artigo. Se a métrica não tivesse o servidor como uma dimensão, você como um cliente poderia acessar apenas as somas de 1 minuto agregadas mostradas em preto no diagrama. Ou seja, os valores de 3, 6, 6, 9, etc. O sistema também não faria o trabalho subjacente de agregar valores de divisão que nunca os usaria no gerenciador de métricas nem os enviaria por meio da API REST de métricas.
Exibindo granularidades de tempo acima de 1 minuto
Se você solicitar métricas em uma granularidade maior, o sistema usará as somas agregadas de 1 minuto para calcular as somas das granularidades de tempo maiores. A seguir, as linhas pontilhadas mostram o método de somatório para as granularidades de tempo de 2 e 5 minutos. Novamente, estamos mostrando apenas o tipo de agregação SUM para simplificar.
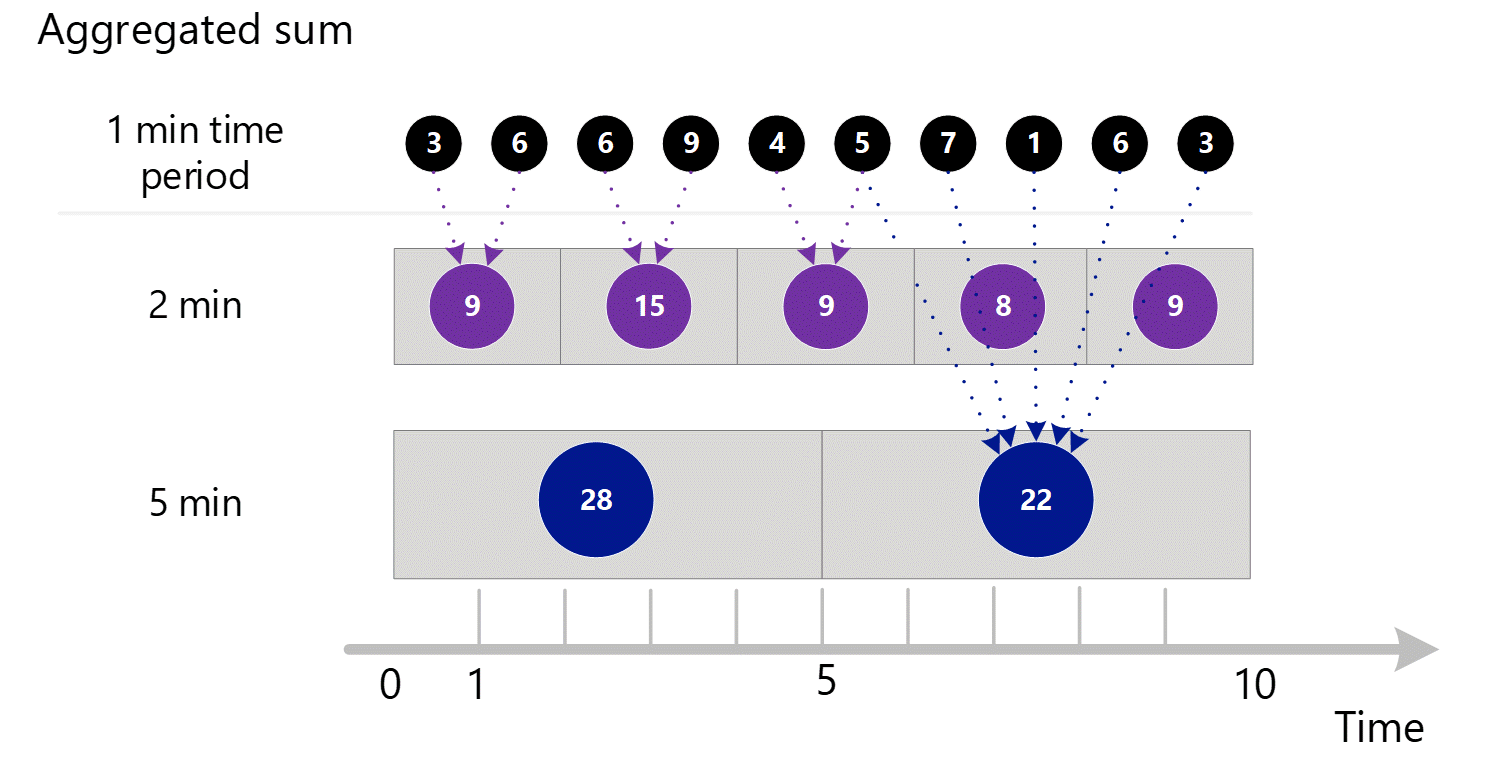
Para a granularidade de tempo de 2 minutos.
| Período | Totaliza |
|---|---|
| Minutos 1 e 2 | (3 + 6) = 9 |
| Minutos 3 e 4 | (6 + 9) = 15 |
| Minutos 4 e 5 | (4 + 5) = 9 |
| Minutes 6 e 7 | (7 + 1) = 8 |
| Minutes 8 e 9 | (6 + 3) = 9 |
Para a granularidade de tempo de 5 minutos.
| Período | Totaliza |
|---|---|
| Minuto de 1 a 5 | 3 + 6 + 6 + 9 + 4 = 28 |
| Minutos de 6 a 10 | 5 + 7 + 1 + 6 + 3 = 22 |
O sistema usa os dados agregados armazenados que proporcionam o melhor desempenho.
A seguir está o diagrama maior para o processo de agregação de 1 minuto anterior, com algumas das setas deixadas para melhorar a legibilidade.
exemplo mais complexo
Veja a seguir um exemplo maior usando valores para uma métrica fictícia chamada tempo de resposta HTTP em milissegundos. Aqui, apresentamos níveis adicionais de complexidade.
- Mostramos a agregação para Sum, Count, Min e Max e o cálculo para Average.
- Mostramos os valores nulos e como eles afetam os cálculos.
Considere o exemplo a seguir. As caixas e setas mostram exemplos de como os valores são agregados e calculados.
O mesmo processo de agregação prévia de 1 minuto, conforme descrito na seção anterior, ocorre para somas, contagem, mínimo e máximo. No entanto, a média NÃO é previamente agregada. Ela é recalculada usando dados agregados para evitar erros de cálculo.

Considere o minuto 6 para a agregação de 1 minuto, conforme destacado acima. Este minuto é o momento em que o servidor B ficou offline e interrompeu os dados de relatório, talvez devido a uma reinicialização.
A partir do minuto 6 acima, os tipos de agregação calculados de 1 minuto são:
| Tipo de agregação | Valor | Observações |
|---|---|---|
| Somar | 53 + 20 = 73 | |
| Contagem | 2 | Mostra o efeito de nulos. O valor teria sido 3 se o servidor estivesse online. |
| Mínimo | 20 | |
| Máximo | 53 | |
| Média | 73 / 2 | Sempre a soma dividida pela contagem. O valor nunca é armazenado e sempre recalculado para cada granularidade de tempo usando os números agregados para essa granularidade. Observe o recálculo para as granularidades de tempo de 5 e 10 minutos, conforme destacado acima. |
A cor de texto vermelho indica os valores que podem ser considerados fora do intervalo normal e mostra como eles se propagam (ou falham) à medida que a granularidade de tempo aumenta. Observe como o mínimo e o máximo indicam que há anomalias subjacentes enquanto a média e as somas perdem essas informações à medida que a granularidade do tempo aumenta.
Você também pode ver que os valores nulos oferecem um melhor cálculo de média do que se zeros fossem usados em seu lugar.
Observação
Embora não seja o caso neste exemplo, a contagem é igual a soma em casos em que uma métrica sempre é capturada com o valor de 1. Isso é comum quando uma métrica acompanha a ocorrência de um evento transacional. Por exemplo, o número de falhas de HTTP mencionado em um exemplo anterior deste artigo.