A pontuação de confiança de uma resposta
Quando uma consulta de usuário é comparada com uma base de conhecimento, o QnA Maker retorna respostas relevantes, juntamente com uma pontuação de confiança. Essa pontuação indica a confiança de que a resposta é a correspondência ideal da consulta do usuário.
A pontuação de confiança é um número entre 0 e 100. Uma pontuação 100 é, provavelmente, uma correspondência exata; no entanto, uma pontuação 0 significa que nenhuma resposta correspondente foi encontrada. Quanto maior a pontuação, maior a confiança na resposta. Pode haver várias respostas retornadas para uma determinada consulta. Nesse caso, as respostas são retornadas em uma ordem de pontuação de confiança decrescente.
No exemplo abaixo, você pode ver uma entidade QnA com duas perguntas.

No caso do exemplo acima, você pode esperar pontuações como o intervalo de pontuação de exemplo abaixo para diferentes tipos de consultas de usuário:
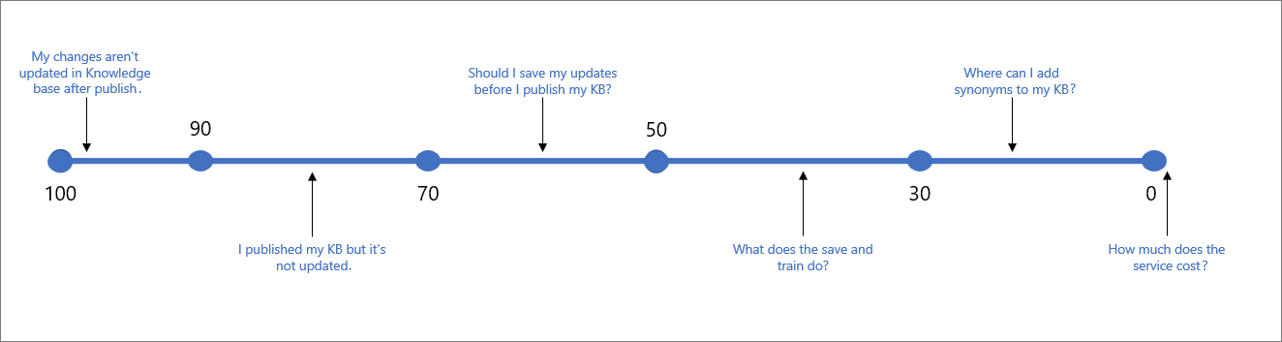
A tabela a seguir indica a confiança típica associada a uma determinada pontuação.
| Valor da pontuação | Significado da pontuação | Consulta de exemplo |
|---|---|---|
| 90 - 100 | Uma correspondência quase exata da consulta de usuário e uma pergunta da KB | "Minhas alterações não são atualizadas na base de conhecimento após a publicação" |
| > 70 | Alta confiança – geralmente uma boa resposta que responde por completo à consulta do usuário | "Publiquei minha Base de conhecimento, mas ela não está atualizada" |
| 50 - 70 | Confiança média – normalmente, uma resposta relativamente boa que deve responder à intenção principal da consulta do usuário | "Devo salvar minhas atualizações antes de publicar minha Base de conhecimento?" |
| 30 - 50 | Pouca confiança – tipicamente uma resposta relacionada que responde parcialmente à intenção do usuário | "O que salvar e treinar faz?" |
| < 30 | Muito pouca confiança – normalmente não responde à consulta do usuário, mas apresenta algumas palavras ou frases correspondentes | "Onde posso adicionar sinônimos à minha Base de conhecimento" |
| 0 | Nenhuma correspondência, portanto, a resposta não é retornada. | "Quanto custa o serviço" |
Escolher um limite de pontuação
A tabela acima mostra as pontuações que são esperadas na maioria das Bases de conhecimento. No entanto, como cada base de dados de conhecimento é diferente e tem diferentes tipos de palavras, intenções e metas, recomendamos que você teste e escolha o limite que melhor funciona para você. Por padrão, o limite é definido como 0, para que todas as respostas possíveis sejam retornadas. O limite recomendado que deve funcionar para a maioria das Bases de conhecimento é 50.
Ao escolher seu limite, tenha em mente o equilíbrio entre Precisão e Cobertura e ajuste seu limite com base em seus requisitos.
Se Precisão for mais importante para seu cenário, aumente seu limite. Dessa forma, sempre que você retornar uma resposta, será muito mais SEGURO e muito mais provável que seja a resposta que os usuários estão procurando. Nesse caso, você pode acabar deixando mais perguntas sem resposta. Por exemplo: se seu limite for 70, é provável que você perca alguns exemplos ambíguos como "o que é salvar e treinar?".
Se a Cobertura (ou o retorno de chamada) for mais importante, e você quiser responder ao maior número de perguntas possível, mesmo que haja apenas uma relação parcial com a pergunta do usuário, então DIMINUA o limite. Isso significa que pode haver mais casos em que a resposta não responda à consulta real do usuário, mas forneça alguma outra resposta relacionada. Por exemplo: se você estabelecer o limite como 30, poderá fornecer respostas para consultas como "Onde posso editar minha base de dados de conhecimento?"
Observação
As versões mais recentes do QnA Maker incluem melhorias na lógica de pontuação e poderão afetar seu limite. Sempre que atualizar o serviço, certifique-se de testar e ajustar o limite, se necessário. Você pode verificar a versão do Serviço QnA aqui e saber como obter as atualizações mais recentes aqui.
Definir limite
Defina a pontuação de limite como uma propriedade do corpo JSON da API GenerateAnswer. Isso significa que você a define para cada chamada para GenerateAnswer.
Na estrutura do bot, defina a pontuação como parte do objeto de opções com C# ou Node.js.
Melhorar as pontuações de confiança
Para melhorar a pontuação de confiança de uma resposta específica a uma consulta de usuário, você poderá adicionar a consulta do usuário à base de dados de conhecimento como uma pergunta alternativa na resposta. Você também pode usar alterações de palavra que não diferenciam maiúsculas de minúsculas para adicionar sinônimos a palavras-chave em sua base de conhecimento.
Pontuações de confiança semelhantes
Quando várias respostas tiverem uma pontuação de confiança semelhante, é provável que a consulta tenha sido muito genérica e, portanto, com correspondências com probabilidades iguais com várias respostas. Tente estruturar melhor suas perguntas e respostas para que cada entidade QnA tenha uma intenção distinta.
Diferenças de pontuação de confiança entre teste e produção
A pontuação de confiança de resposta pode alterar pouco entre o teste e a versão publicada da base de dados de conhecimento, mesmo se o conteúdo for o mesmo. Isso ocorre porque o conteúdo do teste e a base de dados de conhecimento publicada estão localizados em diferentes índices da Pesquisa de IA do Azure.
O índice de teste contém todos os pares de perguntas e respostas de suas bases de dados de conhecimento. Ao consultar o índice de teste, a consulta se aplica a todo o índice e os resultados são restritos à partição dessa base de dados de conhecimento específica. Se os resultados da consulta de teste estiverem afetando negativamente a sua capacidade de validar a base de dados de conhecimento, você poderá:
- organizar sua base de dados de conhecimento usando uma das seguintes opções:
- Um recurso restrito a 1 KB: restrinja seu único recurso do QnA (e o índice de teste resultante da Pesquisa de IA do Azure) a uma única base de dados de conhecimento.
- 2 recursos: 1 para teste, 1 para produção: tenha dois recursos do QnA Maker, usando um para teste (com índices próprios de teste e produção) e outro para o produto (também tendo índices próprios de teste e produção)
- e sempre use os mesmos parâmetros, como top ao consultar a base de dados de conhecimento de teste e de produção
Ao publicar uma base de dados de conhecimento, o conteúdo de perguntas e respostas base de dados de conhecimento é movido do índice de teste para um índice de produção no Azure Search. Veja como funciona a operação publicar.
Se você tiver uma base de conhecimento em regiões diferentes, cada região usa seu próprio índice da Pesquisa de IA do Azure. Como índices diferentes são usados, as pontuações não serão exatamente as mesmas.
Nenhuma correspondência encontrada
Quando nenhuma boa correspondência for encontrada pelo classificador, a pontuação de confiança 0,0 ou "Nenhuma" é retornada e a resposta padrão é "Nenhuma correspondência boa encontrada na KB". Você pode substituir essa resposta padrão no código do aplicativo ou do bot chamando o ponto de extremidade. Como alternativa, você também pode definir a resposta de substituição no Azure, e isso altera o padrão para todas as bases de dados de conhecimento implantadas em um determinado serviço QnA Maker.