O que é a Sintetização de Voz Personalizada?
A Voz Neural Personalizada (CNV) é um recurso de conversão de texto em fala que permite criar uma voz sintética personalizada e exclusiva para seus aplicativos. Com a Voz Neural Personalizada, é possível criar uma voz que soe extremamente natural para sua marca ou personagens, fornecendo amostras de fala humana como dados de treinamento.
Importante
O acesso à Sintetização de Voz Personalizada é limitado de acordo com os critérios de qualificação e uso. Solicite acesso no formulário de entrada.
O acesso à Voz Neural Personalizada (CNV) Lite está disponível a todos para demonstração e avaliação da CNV antes de investir em gravações profissionais para criar uma voz de maior qualidade.
Pronta para uso, a conversão de texto em fala pode ser usada com vozes neurais predefinidas para cada idioma com suporte. As vozes neurais pré-construídas funcionam bem na maioria dos cenários de conversão de texto em fala, se não for necessária uma voz exclusiva.
A Voz Neural Personalizada se baseia na tecnologia neural de conversão de texto em fala e no modelo universal multilíngue, de vários locutores. Você pode criar vozes sintéticas que são ricas em estilos de fala ou linguagens cruzadas adaptáveis. A voz realista e natural da Voz Neural Personalizada pode representar marcas, personificar máquinas e permitir que os usuários interajam conversando com os aplicativos. Confira os idiomas com suporte para sintetização de voz personalizada.
Como ele funciona?
Para criar uma Sintetização de Voz Personalizada, use o Speech Studio para carregar o áudio gravado e os scripts correspondentes, treinar o modelo e implantar a voz em um ponto de extremidade personalizado.
Dica
Experimente a Voz Neural Personalizada (CVN) Lite para demonstração e avaliação da CNV antes de investir em gravações profissionais para criar uma voz de maior qualidade.
A criação de uma excelente sintetização de voz personalizada requer um controle de qualidade cuidadoso em cada etapa, desde o design da voz e a preparação de dados até a implantação do modelo de voz em seu sistema.
Antes de começar a usar o Speech Studio, aqui estão algumas considerações:
- Crie uma persona da voz que represente sua marca usando um documento de resumo da persona. Esse documento define elementos como as características da voz e o personagem por trás dela. Isso ajuda a orientar o processo de criação de um modelo de sintetização de voz personalizada, incluindo a definição dos scripts, a seleção do talento de voz, bem como o treinamento e o ajuste da voz.
- Selecione o script de gravação para representar os cenários de usuário para a voz. Por exemplo, você poderá usar as frases das conversas de bot como script de gravação se estiver criando um bot de serviço de atendimento ao cliente. Inclua diferentes tipos de frases nos scripts, como afirmativas, perguntas e exclamações.
Aqui está uma visão geral das etapas para criar uma voz neural personalizada no Speech Studio:
- Crie um projeto para conter seus dados, modelos de voz, testes e pontos de extremidade. Cada projeto é específico para um país/região e idioma. Se você for criar várias vozes, é recomendável criar um projeto para cada voz.
- Configurar o talento de voz. Para treinar uma voz neural, envie uma gravação da declaração de consentimento do talento de voz. A declaração do talento de voz consiste em uma gravação do talento de voz lendo uma declaração de que consente com o uso de seus dados de fala para treinar um modelo de voz personalizada.
- Prepare os dados de treinamento no formato certo. É uma boa ideia capturar as gravações de áudio em um estúdio de gravação de qualidade profissional para obter uma boa proporção de sinal para ruído. A qualidade do modelo de voz depende muito dos dados de treinamento. É necessário ter volume, velocidade de fala e densidade de fala consistentes, além de consistência nos maneirismos expressivos.
- Treinar o modelo de voz. Selecione, pelo menos, 300 enunciados para criar uma sintetização de voz personalizada. Uma série de verificações de qualidade de dados é executada automaticamente quando você as carrega. Para criar modelos de voz de alta qualidade, você precisa corrigir todos os erros e fazer o envio novamente.
- Teste sua voz. Prepare scripts de teste para o modelo de voz que abranjam os diferentes casos de uso de seus aplicativos. É uma boa ideia usar scripts dentro e fora do conjunto de dados de treinamento para que você possa testar a qualidade de maneira mais ampla para conteúdos diferentes.
- Implante e use seu modelo de voz em seus aplicativos.
Você pode aperfeiçoar, ajustar e usar sua voz personalizada da mesma forma que usaria uma voz neural predefinida. Converta texto em fala em tempo real ou gere conteúdo de áudio offline com entrada de texto. Você usa a API REST, o SDK de Fala ou o Speech Studio.
Dica
Você também pode usar o SDK de Fala e a API REST de voz personalizada para treinar uma voz neural personalizada.
Confira os exemplos de código no repositório do Speech SDK no GitHub para ver como usar a voz neural personalizada em seu aplicativo.
O estilo e as características do modelo de voz treinado dependem do estilo e da qualidade das gravações do talento de voz usado para treinamento. No entanto, vários ajustes podem ser feitos por meio da SSML (Speech Synthesis Markup Language) quando você faz as chamadas à API para que o modelo de voz gere uma voz sintética. SSML é a linguagem de marcação usada para comunicação com o serviço de conversão de texto em fala para converter um texto em áudio. Os ajustes que podem ser feitos incluem alteração de tom, velocidade, entonação e correção de pronúncia. Se o modelo de voz for criado com vários estilos, a SSML também poderá ser usada para alternar os estilos.
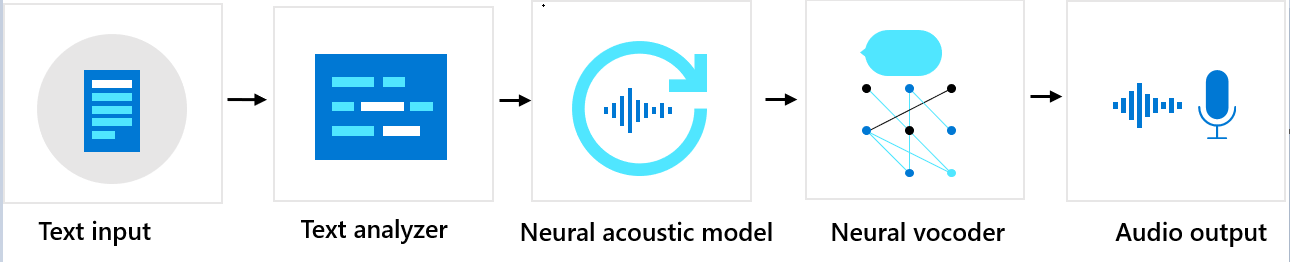
Sequência de componentes
A Voz Neural Personalizada consiste em três componentes principais: o analisador de texto, o modelo acústico neural e o vocoder neural. Para gerar uma voz sintética natural com base no texto, primeiro, é necessário inserir o texto no analisador de texto, que fornece a saída na forma de uma sequência de fonemas. Um fonema é uma unidade básica de som que distingue uma palavra de outra em um idioma específico. Uma sequência de fonemas define as pronúncias das palavras fornecidas no texto.
Em seguida, a sequência de fonemas entra no modelo acústico neural para prever recursos acústicos que definem os sinais da fala. Os recursos acústicos incluem o timbre, o estilo de fala, a velocidade, as entonações e os padrões de acento tônico. Por fim, o vocoder neural converte os recursos acústicos em ondas audíveis para que a voz sintética seja gerada.
Os modelos de voz de conversão de texto em fala neural são treinados com o uso de redes neurais profundas com base em exemplos de gravação de vozes humanas. Para saber mais, confira esta postagem no blog da Microsoft. Para saber mais sobre como um vocoder neural é treinado, confira esta postagem no blog da Microsoft.
Migrar para a sintetização de voz personalizada
Se estiver usando a versão antiga da Voz Neural Personalizada (agendada para ser desativada em fevereiro de 2024), consulte Como migrar para a Voz Neural Personalizada.
IA responsável
Um sistema de IA inclui não apenas a tecnologia, mas também as pessoas que a usam, que serão afetadas por ela e o ambiente em que ela foi implantada. Leia as notas de transparência para saber mais sobre o uso e a implantação de IA responsável em seus sistemas.
- Observação de transparência e casos de uso para a voz neural personalizada
- Características e limitações para usar a voz neural personalizada
- Acesso limitado à voz neural personalizada
- Diretrizes para a implantação responsável da tecnologia de voz sintética
- Divulgação para ator de voz
- Diretrizes de design de divulgação
- Padrões de design de divulgação
- Código de Conduta para integrações de Conversão de texto em fala
- Dados, privacidade e segurança para a voz neural personalizada