Gravar amostras de voz para voz neural personalizada
Este artigo fornece instruções sobre como preparar exemplos de voz de alta qualidade para criar um modelo de voz profissional usando o projeto de pro de voz neural personalizado.
Criar do zero uma sintetização de voz personalizada de alta qualidade para produção não é uma tarefa qualquer. O componente central de uma Sintetização de Voz Personalizada é uma coleção grande de amostras de áudio de fala humana. É vital que essas gravações de áudio sejam de alta qualidade. Escolha um talento de voz que tenha experiência com esses tipos de gravações e solicite que um engenheiro de gravação as registre usando equipamento profissional.
Antes de fazer essas gravações, no entanto, você precisa de um script: as palavras são faladas pelo seu talento de voz para criar os exemplos de áudio.
Muitos detalhes pequenos, mas importantes, envolvem a criação de uma gravação de voz profissional. Este guia é um roteiro para um processo que irá ajudá-lo a obter resultados bons e consistentes.
Dicas de preparação de dados para obter uma voz de alta qualidade
Uma voz neural personalizada altamente natural depende de vários fatores, como a qualidade e o tamanho dos dados de treinamento.
A qualidade dos dados de treinamento é um fator principal. Por exemplo, no mesmo conjunto de treinamento, volume consistente, taxa de fala, tom de fala e estilo de fala são essenciais para criar uma voz neural personalizada de alta qualidade. Você também deve evitar ruído de fundo na gravação e verificar se o script e a gravação correspondem. Para garantir a qualidade dos dados, você precisa seguir os critérios de seleção de script e os requisitos de gravação.
Em relação ao tamanho dos dados de treinamento, na maioria dos casos, você pode criar uma boa voz neural personalizada com 500 enunciados. De acordo com nossos testes, adicionar mais dados de treinamento na maioria dos idiomas não necessariamente melhora a naturalidade da própria voz (testado usando a pontuação MOS), no entanto, com mais dados de treinamento que abrangem mais instâncias de palavras, você tem maior possibilidade de reduzir a taxa de partes insatisfatórias da fala para a voz, como as falhas. Para ouvir como são as partes insatisfatórias da fala, consulte os exemplos do GitHub.
Em alguns casos, talvez você queira uma persona de voz com características exclusivas. Por exemplo, uma persona de desenho animado precisa de uma voz com um estilo de fala especial ou uma voz dinâmica em entonação. Nesses casos, recomendamos que você prepare pelo menos 1000 enunciados (preferencialmente 2000) e grave-os em um estúdio de gravação profissional. Para saber mais sobre como aprimorar a qualidade do modelo de voz, confira características e limitações para usar a voz neural personalizada.
Funções de gravação de voz
Há quatro funções básicas em um projeto de gravação de Sintetização de Voz Personalizada:
| Função | Finalidade |
|---|---|
| Ator de voz | A voz dessa pessoa forma a base da voz neural personalizada. |
| Engenheiro de gravação | Supervisiona os aspectos técnicos da gravação e opera o equipamento de gravação. |
| Diretor | Prepara o script e orienta o desempenho do ator de voz. |
| Editor | Finaliza os arquivos de áudio e prepara-os para o upload no Speech Studio |
Um indivíduo pode preencher mais de uma função. Este guia pressupõe que você esteja preenchendo a função de diretor e contratando um talento de voz e um engenheiro de gravação. Caso você mesmo queira fazer as gravações, este artigo inclui algumas informações sobre a função do engenheiro de gravação. A função de editor não é necessária até depois da sessão de gravação. Enquanto isso, o diretor ou o engenheiro de gravação podem preencher essa função.
Escolha seu locutor
Atores com experiência em narração, trabalho de personagem de voz, anúncio ou leitura de notícias fazem um bom talento de voz. Escolha o ator de voz cuja voz natural você aprecia. É possível criar vozes exclusivas de "personagem", mas é mais difícil para a maioria dos talentos executá-las consistentemente, e o esforço pode causar tensão de voz. O fator mais importante para a escolha de talentos de voz é a consistência. As gravações para o mesmo estilo de voz devem soar como se tivessem sido feitas no mesmo dia e na mesma sala. É possível aproximar-se desse ideal por meio de melhores práticas de gravação e engenharia.
O talento de voz deve ser capaz de falar com taxa consistente, nível de volume, densidade e tom com um ditado claro. Eles também precisam ser capazes de controlar sua variação de tom, efeito emocional e maneirismos de fala. Gravar exemplos de voz pode ser mais cansativo do que outros tipos de trabalho de voz, então a maioria dos talentos de voz só pode gravar por duas ou três horas por dia. Se possível, limite as sessões a três ou quatro dias por semana, com um dia de folga entre elas.
Trabalhe com o talento de voz para desenvolver uma persona que defina o tom geral e emocional da sintetização de voz personalizada. É importante identificar a sonoridade "neutra" para essa persona. Você define os estilos de fala de sua persona e pede ao seu talento de voz para ler o script de uma maneira que ressoe com os estilos que você deseja.
Por exemplo, uma persona com personalidade naturalmente otimista carregaria uma nota de otimismo mesmo quando falasse de maneira neutra. No entanto, esse traço de personalidade deve ser sutil e consistente. Ouça as leituras de vozes existentes para ter uma ideia do que você está procurando.
Dica
Normalmente, você vai querer ter as gravações de voz que faz. O ator de voz deve ser favorável a um contrato de prestação de serviço para o projeto.
Criar um script
O ponto de partida de qualquer sessão de gravação de Sintetização de Voz Personalizada é o script, que contém os enunciados a serem falados pelo talento de voz. O termo "enunciados" engloba sentenças completas e frases curtas. A criação de uma sintetização de voz personalizada necessita de pelo menos 300 enunciados gravados como dados de treinamento.
Os enunciados no script podem vir de qualquer lugar: ficção, não ficção, transcrições de discursos, relatórios de notícias e qualquer outro material disponível em formato impresso. Para uma breve discussão sobre possíveis problemas legais, veja a seção "Questões legais". Você também pode gravar seu próprio texto.
Os enunciados não precisam vir da mesma origem, do mesmo tipo de origem ou ter algo a ver uns com os outros. No entanto, se você usar frases configuradas (por exemplo, "Você fez logon com êxito") no aplicativo de fala, não deixe de incluí-las no script. Ele dá à sua voz neural personalizada uma melhor chance de pronunciar bem essas frases.
Recomendamos que os scripts de gravação incluam frases gerais e as frases específicas do domínio. Por exemplo, se você planeja gravar 2 mil frases, metade delas pode ser de sentenças gerais, a outra metade delas pode ser de sentenças do seu domínio de destino ou do caso de uso do seu aplicativo.
Fornecemos scripts de exemplo nos domínios 'Geral', 'Chat' e 'Atendimento ao cliente' para cada idioma para ajudar você a preparar seus scripts de gravação. Você pode usar esses scripts compartilhados da Microsoft diretamente em suas gravações ou usá-los como referência para criar os seus.
Critérios de seleção de script
Veja abaixo algumas diretrizes gerais que você pode seguir para criar um bom corpus (exemplos de áudio gravados) para treinamento de sintetização de voz neural personalizada.
Equilibre seu script para cobrir tipos de sentença diferentes em seu domínio, incluindo instruções, perguntas, exclamações, frases longas e frases curtas.
Cada frase deve conter quatro palavras a 30 palavras e nenhuma frase duplicada deve ser incluída em seu script.
Para saber como equilibrar os tipos de sentença diferentes, consulte a seguinte tabela:Tipos de sentença Cobertura Sentenças de instrução As sentenças de instrução devem ser de 70 a 80% do script. Frases interrogativas As frases interrogativas devem ser cerca de 10% a 20% do seu script de domínio, incluindo 5% a 10% de tons crescentes e 5% a 10% de tons decrescentes. Frases exclamativas As frases exclamativas devem ser cerca de 10% a 20% do script. Palavra/frase abreviada Os scripts de palavra/frase curta devem ser cerca de 10% do total de enunciados, com 5 a 7 palavras por caso. Observação
As palavras/frases curtas devem ser separadas com vírgulas. Elas ajudam a lembrar o talento de voz para pausar brevemente ao lê-las.
Melhores práticas incluem:
- Cobertura equilibrada para Partes de Fala, como verbos, substantivos, adjetivos e assim por diante.
- Cobertura equilibrada para pronúncias. Inclua todas as letras de A a Z para que o mecanismo de Conversão de texto em fala aprenda a pronunciar cada letra em seu estilo.
- Scripts legíveis, compreensíveis, de bom senso para o locutor fazer a leitura.
- Evite muitos padrões semelhantes para palavras/frases, como "fácil" e "mais fácil".
- Inclua formatos diferentes de números: endereço, unidade, telefone, quantidade, data e assim por diante, em todos os tipos de sentença.
- Inclua frases ortográficas se for algo que sua voz neural personalizada lerá. Por exemplo, "A grafia de Apple é A P P L E".
Não coloque várias frases em uma linha/enunciado. Separe cada linha por enunciado.
Certifique-se de que a frase seja compreensível. Geralmente, não inclua muitas palavras fora do padrão, como números ou abreviações, pois são difíceis de ler. Alguns aplicativos podem exigir a leitura de muitos números ou acrônimos. Nesses casos, você pode incluir essas palavras, mas normalize-as na forma oral.
Abaixo estão algumas melhores práticas, por exemplo:
- Em linhas com abreviações, em vez de "BTW", escreva "a propósito".
- Em linhas com dígitos, em vez de "190", escreva "1 9 0".
- Para linhas com acrônimos, em vez de "ABC", escreva "A B C".
Com isso, garanta que seu talento de voz pronuncie essas palavras da maneira esperada. Mantenha o script e as gravações correspondentes durante o processo de treinamento.
O script deve incluir muitas palavras e frases diferentes com tipos diferentes de comprimentos de frases, estruturas e estados de humor.
Verifique o script cuidadosamente para observar se há erros. Se possível, solicite a uma outra pessoa que também verifique o script. Quando você percorre o script com seu talento de voz, você pode pegar mais erros.
Diferença entre script de talento de voz e script de treinamento
O script de treinamento pode ser diferente do script de talento de voz, especialmente para scripts que contêm dígitos, símbolos, abreviações, data e hora. Os scripts preparados para o talento de voz devem seguir as convenções de leitura nativa, como 50% e US$ 45. Os scripts usados para treinamento devem ser normalizados para corresponder à gravação de áudio, como 50% e 45 dólares.
Observação
Fornecemos alguns scripts de exemplo para o talento de voz em GitHub. Para usar os scripts de exemplo para treinamento, você deve normalizá-los de acordo com as gravações do seu talento de voz antes de carregar o arquivo.
A tabela a seguir mostra a diferença entre os scripts para o talento de voz e o script normalizado para treinamento.
| Categoria | Exemplo de script de talento de voz | Exemplo de script de treinamento (normalizado) |
|---|---|---|
| Dígitos | 123 | cento e vinte e três |
| Símbolos | 50% | cinquenta por cento |
| Abreviação | O mais rápido possível | O mais breve possível |
| Data e hora | 3 de março às 17:00 | 3 de março às 17:00 |
Defeitos típicos de um script
A qualidade ruim do script pode afetar negativamente os resultados de treinamento. Para obter resultados de treinamento em alta qualidade, é crucial evitar os defeitos.
Os defeitos de script geralmente se enquadram nas seguintes categorias:
| Categoria | Exemplo |
|---|---|
| Conteúdo sem sentido. | "As ideias verdes incolores dormem furiosamente." |
| Frases incompletas. | - "Esta foi minha última véspera" (sem assunto, nenhum significado específico) - "Eles já são engraçados (sem aspas no final, não é uma frase completa) |
| Erro de digitação nas frases. | - Iniciar com uma letra minúscula - Sem pontuação final, caso necessária - Ortografia incorreta - Falta de pontuação: sem ponto no final (exceto título de notícia) - Terminar com símbolos, exceto vírgula, interrogação, exclamação - Formato incorreto, como: - 45$ (deve ser $45) - Sem espaço ou excesso de espaços entre a palavra/pontuação |
| Duplicação em formato semelhante, uma por cada padrão é o suficiente. | - "Agora são 13h00 em Nova York" - "Agora são 14h00 em Nova York" - "Agora são 15h00 em Nova York" - "Agora são 13h00 em Seattle" - "Agora são 13h00 em Washington D.C." |
| Palavras estrangeiras incomuns: somente as palavras estrangeiras comumente usadas são aceitáveis no script. | Em inglês, pode-se usar a palavra francesa "faux" em discurso comum, mas uma expressão francesa como "coincer la bulle" seria incomum. |
| Emojis ou quaisquer outros símbolos incomuns |
Formato do script
O script é para uso durante a sessão de gravação, para que você possa configurá-lo da melhor maneira que deseja trabalhar. Crie o arquivo de texto exigido pelo Speech Studio separadamente.
Um formato de script básico contém três colunas:
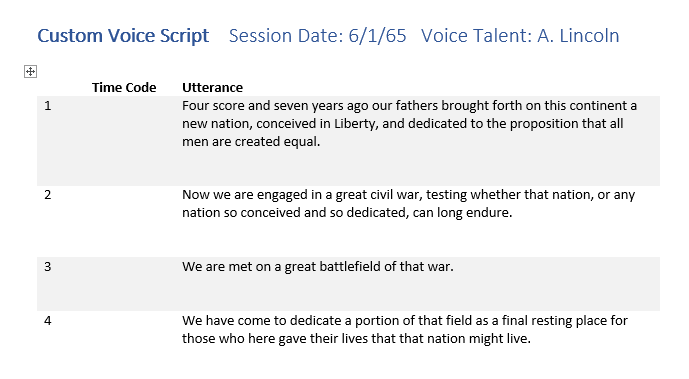
- O número do enunciado, começando em 1. A numeração torna fácil para todos no estúdio referirem-se a um enunciado específico ("vamos tentar o número 356 novamente"). É possível usar o recurso de numeração de parágrafo do Microsoft Word para numerar as linhas da tabela automaticamente.
- Uma coluna em branco em que você escreve o código de tempo ou número de tomada de cada enunciado para ajudá-lo a encontrá-lo na gravação concluída.
- O texto do próprio enunciado.
Observação
A maioria dos estúdios grava em pequenos segmentos conhecidos como "tomadas". Cada tomada normalmente contém de 10 a 24 enunciados. Apenas anotar o número da tomada é o suficiente para localizar um enunciado posteriormente. Se estiver gravando em um estúdio que prefere fazer gravações mais longas, convém anotar o código de tempo. O estúdio terá uma exibição de tempo proeminente.
Deixe espaço suficiente após cada linha para escrever notas. Certifique-se de que nenhum enunciado está dividido entre páginas. Numere as páginas e imprima o script em um lado do papel.
Imprima três cópias do script: uma para o talento de voz, uma para o engenheiro de gravação e outra para o diretor (você). Use um clipe de papel em vez de grampos: um artista de voz experiente separa as páginas para evitar fazer barulho à medida que as páginas são viradas.
Declaração do talento de voz
Para treinar uma voz neural, você deve criar um perfil de talento de voz com um arquivo de áudio gravado pelo talento de voz consentindo o uso dos dados de fala para treinar um modelo de voz personalizada. Ao preparar o script de gravação, lembre-se de incluir a sentença de instrução.
Legalidades
Sob a lei de direitos autorais, a leitura de um texto com direitos autorais pelo ator pode ser uma performance para a qual o autor do trabalho deve ser compensado. Esse trabalho de texto não será reconhecido no produto final, a Sintetização de Voz Personalizada. Mesmo assim, a legalidade do uso de um trabalho com direitos autorais para este fim não está bem estabelecida. A Microsoft não pode fornecer assistência jurídica sobre essa questão, portanto, consulte seu advogado.
Felizmente, é possível evitar completamente essas questões. Há muitas fontes de texto que podem ser utilizadas sem permissão ou licença.
| Fonte de texto | Descrição |
|---|---|
| Corpus CMU Arctic | Cerca de 1100 frases selecionadas de obras que não possuem direitos autorais, especificamente para uso em projetos de sintetização de fala. Um excelente ponto de partida. |
| Obras que não estão mais sob direitos autorais |
Normalmente, obras publicadas antes de 1923. Para inglês, o Project Gutenberg oferece dezenas de milhares de obras desse tipo. Talvez você queira se concentrar em trabalhos mais recentes, pois o idioma está mais próximo do inglês moderno. |
| O governo funciona | Obras criadas pelo governo dos Estados Unidos não têm direitos autorais nos Estados Unidos, embora o governo possa reivindicar direitos autorais em outros países/regiões. |
| Domínio público | Funciona para os quais os direitos autorais são explicitamente direcionados ou dedicados ao domínio público. Talvez não seja possível renunciar totalmente aos direitos autorais em algumas jurisdições. |
| Obras com licença permissiva | Obras distribuídas sob licença como Creative Commons ou GFDL (Licença GNU de Documentação Livre). Wikipedia usa GFDL. Algumas licenças, no entanto, podem impor restrições ao desempenho do conteúdo licenciado que podem afetar a criação de um modelo de voz neural personalizado, portanto, leia a licença com cuidado. |
Gravar o script
Grave o script em um estúdio de gravação profissional especializado em trabalho de voz. Eles têm uma cabine de gravação, o equipamento certo, e as pessoas certas para operá-lo. É recomendável não economizar na gravação.
Discuta seu projeto com o engenheiro de gravação do estúdio e ouça os conselhos dele. A gravação deve ter pouca ou nenhuma compressão de gama dinâmica (máximo de 4: 1). É essencial que o áudio tenha um volume consistente e uma alta relação sinal-ruído, além de estar livre de sons indesejados.
Requisitos de gravação
Para obter resultados de treinamento de alta qualidade, siga os seguintes requisitos durante a gravação ou a preparação de dados:
Claridade e boa pronuncia
Velocidade natural: não é lenta demais e nem rápida demais entre os arquivos de áudio.
Volume apropriado, prosódia e pausa: estável na mesma frase ou entre frases, pausa correta para pontuação.
Sem ruído durante a gravação
Encaixe seu design pessoal
Sem acentos incorretos: ajustar ao design de destino
Sem pronúncia incorreta
Você pode consultar a especificação abaixo para se preparar para os exemplos de áudio como melhor prática.
| Propriedade | Valor |
|---|---|
| Formato de arquivo | *.wav, Mono |
| Taxa de amostragem | 24 kHz |
| Formato de exemplo | 16 bits, PCM |
| Níveis de pico de volume | -3 dB para -6 dB |
| SNR | > 35 dB |
| Silêncio | - Deve haver algum silêncio (recomendável 100 ms) no início e no final, mas não mais do que 200 ms - Silêncio entre palavras ou frases < -30 dB - Silêncio na onda após a última palavra ser falada <-60 dB |
| Ruído ou eco do ambiente | - O nível de ruído no início da onda antes de falar < -70 |
Observação
Você pode gravar em uma taxa de amostragem mais alta e uma profundidade de bits, por exemplo, no formato de PCM 48 KHz de 24 bits. Durante o treinamento de voz neural personalizada, reduziremos a amostra do PCM 24 KHz de 16 bits automaticamente.
Uma SNR (relação de sinal de ruído) superior indica menor ruído no áudio. Normalmente, é possível alcançar uma SNR de 35+ com gravação em estúdios profissionais. O áudio com uma SNR abaixo de 20 pode resultar em ruído óbvio na voz gerada.
Considere regravar quaisquer enunciados com pontuações baixas de pronúncia ou relações de sinal de ruído ruins. Se não for possível regravar, considere a possibilidade de excluir esses enunciados dos dados.
Erros típicos de áudio
Para resultados de treinamento de alta qualidade, é altamente recomendável evitar erros de áudio. Os erros de áudio geralmente estão dentro das seguintes categorias:
O nome do arquivo de áudio não corresponde à ID do script.
O arquivo WAR tem um formato inválido e não pode ser lido.
A taxa de amostragem de áudio é inferior a 16 KHz. É recomendado que a taxa de amostragem do arquivo .wav seja igual ou maior do que 24 KHz para sintetização de voz de alta qualidade.
O pico de volume não está dentro do intervalo de -3 dB (70% de volume máximo) para -6 dB (50%).
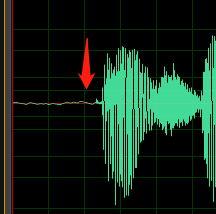
Estouro da forma de onda: a forma de onda é cortada no valor de pico e, portanto, não está completa.
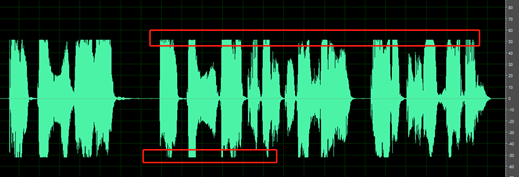
As partes silenciosas da gravação não estão limpas; você pode ouvir sons como ruído ambiente, ruído da boca e eco.
Por exemplo, o áudio abaixo contém o ruído do ambiente entre as falas.

A amostra abaixo contém sinais de deslocamento ou eco de DC.
O volume em geral está muito baixo. Seus dados serão marcados como um problema se o volume for menor que -18 dB (10% do volume máximo). Verifique se todos os arquivos de áudio devem ser consistentes no mesmo nível de volume.
Sem silêncio antes da primeira palavra ou após a última palavra. Além disso, o silêncio inicial ou final não deve ser maior do que 200 ms ou menor do que 100 ms.
Faça você mesmo
Se você mesmo quer fazer a gravação, em vez de entrar em um estúdio de gravação, aqui está um breve manual. Graças à ascensão da gravação caseira e podcast, é mais fácil do que nunca encontrar bons conselhos e recursos de gravação online.
Sua "cabine de gravação" deve ser uma sala pequena sem eco perceptível ou "tom de sala". Ele deve ser o mais silencioso e à prova de som possível. Cortinas nas paredes podem ser usadas para reduzir o eco e neutralizar ou "isolar" o tom da sala.
Use um microfone condensador de estúdio de alta qualidade ("mic" para abreviar) destinado a gravação de voz. Microfones Sennheiser, AKG e mesmo Zoom mais recentes podem produzir bons resultados. Você pode comprar um microfone ou alugar um de uma locadora de equipamentos audiovisuais local. Procure um com uma interface USB. Esse tipo de microfone combina convenientemente o elemento do microfone, pré-amplificador e conversor analógico-digital em um único pacote, simplificando a conexão.
Você também pode usar um microfone analógico. Muitas locadoras oferecem microfones "vintage" conhecidos pela singularidade vocal. A engrenagem analógica profissional usa conectores XLR equilibrados, em vez do plug-in de 1/4 polegada usado em equipamentos de consumo. Se for analógico, também precisará de um pré-amplificador e uma interface de áudio do computador com esses conectores.
Instale o microfone em um suporte ou boom e instale um filtro pop na frente do microfone para eliminar o ruído de consoantes "ativas", como "p" e "b". Alguns microfones vêm com uma montagem de suspensão que os isola de vibrações no suporte, o que é útil.
O ator de voz deve ficar a uma distância consistente do microfone. Use fita adesiva no piso para marcar onde devem ficar posicionados. Se o ator de voz preferir sentar, tenha cuidado especial para monitorar a distância do microfone e evitar o ruído da cadeira.
Use um suporte para manter o script. Evite inclinar o suporte para que o som não seja refletido em direção ao microfone.
A pessoa que opera o equipamento de gravação – o engenheiro de gravação – deve estar em uma sala separada do ator de voz, com alguma forma para comunicar-se com o ator na cabine de gravação (um circuito de talkback).
A gravação deve conter o mínimo de ruído possível, com uma meta de 80 dB.
Ouça atentamente uma gravação de silêncio na "cabine", descubra onde origina-se qualquer ruído e elimine a causa. As fontes comuns de ruído são saídas de ar, reatores de luz fluorescente, tráfego nas estradas próximas e ventiladores de equipamentos (até mesmo os notebooks podem ter ventiladores). Microfones e cabos podem captar o ruído elétrico da fiação CA próxima, geralmente uma vibração ou zumbido. Uma agitação também pode ser causada por uma loop de aterramento, que é causado pela conexão de equipamento a mais de um circuito elétrico.
Dica
Em alguns casos, você poderá usar um equalizador ou um plug-in de software de redução de ruído para ajudar a remover o ruído das gravações, embora seja sempre melhor interrompê-lo na origem.
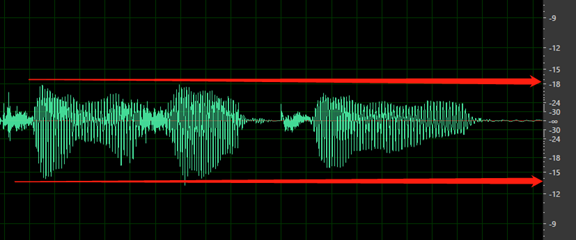
Defina os níveis, de modo que a maior parte do intervalo dinâmico disponível de gravação digital seja usada sem distorção. Isso significa definir o áudio para um nível alto, mas não tão alto que fique distorcido. Um exemplo da forma de onda de uma boa gravação é mostrado na imagem a seguir:
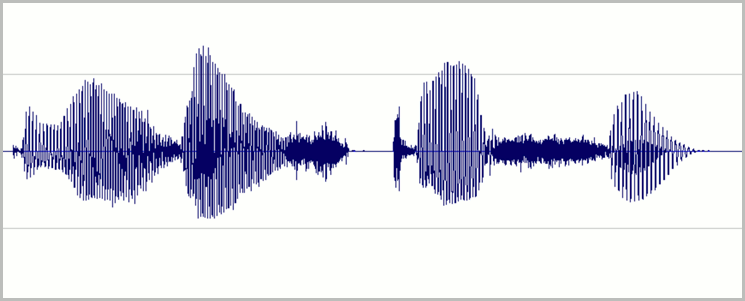
Aqui, a maior parte da gama (altura) é usada, mas os picos mais altos do sinal não atingem a parte superior ou inferior da janela. Você também pode ver que o silêncio na gravação aproxima-se de uma linha horizontal fina, indicando um baixo nível de ruído. Essa gravação possui gama dinâmica aceitável e relação sinal-ruído.
Grave diretamente no computador usando uma interface de áudio de alta qualidade ou uma porta USB, dependendo do microfone que estiver usando. Para analógico, mantenha a cadeia de áudio simples: mic, pré-amplificador, interface de áudio, computador. Você pode licenciar tanto o Avid Pro Tools quanto o Adobe Audition mensalmente a um custo razoável. Se o orçamento estiver extremamente limitado, experimente o Audacity gratuito.
Grave em 44.1 KHz monofônico de 16 bits (qualidade de CD) ou melhor. A última geração é de 48 kHz/24 bits se o equipamento tiver suporte para isso. Você reduzirá o tamanho do áudio para 24 kHz de 16 bits antes de enviá-lo ao Speech Studio. Ainda assim, vale a pena ter uma gravação original de alta qualidade se for necessário ter edições.
O ideal é ter pessoas diferentes nas funções de diretor, engenheiro e ator de voz. Não tente fazer tudo sozinho. Em uma situação de emergência, uma pessoa pode ser tanto o diretor quanto o engenheiro.
Antes da sessão
Para evitar desperdiçar tempo de estúdio, repasse o script com o ator de voz antes da sessão de gravação. Enquanto o ator de voz familiariza-se com o texto, poderá esclarecer a pronúncia de qualquer palavra desconhecida.
Observação
A maioria dos estúdios de gravação oferece exibição eletrônica de scripts na cabine de gravação. Nesse caso, digite diretamente no documento do script as observações a serem repassadas rapidamente. Ainda será necessário ter uma cópia em papel para fazer anotações durante a sessão. A maioria dos engenheiros também vai querer uma cópia impressa. Além disso, é necessário ter uma terceira cópia impressa como backup para o ator de voz, caso o computador esteja inoperante.
O ator de voz pode perguntar qual palavra você quer enfatizar em um enunciado (a "palavra operativa"). Diga-lhe que você quer uma leitura natural sem ênfase particular. A ênfase poderá ser adicionada quando a fala for sintetizada e não deve fazer parte da gravação original.
Direcione o ator de voz para pronunciar palavras distintamente. Cada palavra do script deve ser pronunciada como escrita. Os sons não devem ser omitidos nem desarticulados, como é comum em fala casual, a menos que tenham sido escritos dessa maneira no script.
| Texto escrito | Pronúncia casual indesejada |
|---|---|
| nunca vou desistir de você | nunca vo desistir de você |
| existem quatro luzes | existe quatro luzes |
| como está o tempo hoje | como tá o tempo hoje |
| diga oi para o meu amiguinho | diga oi pro meu amiguinho |
O talento não deve* adicionar pausas distintas entre palavras. A frase ainda deve fluir naturalmente, mesmo quando soar um pouco formal. Talvez seja necessário treinar essa sutil distinção para acertá-la.
A sessão de gravação
Crie uma gravação de referência ou um arquivo de correspondência, de um enunciado típica no início da sessão. Peça ao ator que repita essa linha mais ou menos a cada página. A cada vez, compare a nova gravação com a referência. Essa prática ajuda o ator a permanecer consistente em volume, tempo, densidade e entonação. Enquanto isso, o engenheiro pode usar o arquivo correspondente como referência para níveis e consistência geral do som.
O arquivo correspondente será especialmente importante ao retomar a gravação após um intervalo ou em outro dia. Reproduza ele algumas vezes para o ator e peça que ele repita a cada vez até que esteja correspondendo adequadamente.
Para gravar um corpus com um estilo específico, escolha cuidadosamente os scripts que demonstram o estilo desejado. Durante a gravação, certifique-se de que o talento de voz mantenha a consistência no volume, no ritmo, no tom e no timbre para obter gravações que incorporem o estilo pretendido.
Treine o ator para respirar fundo e pausar por um momento antes de cada enunciado. Grave alguns segundos de silêncio entre os enunciados. As palavras devem ser pronunciadas da mesma maneira sempre que aparecem, considerando o contexto. Por exemplo, "analise" como um verbo é pronunciado diferente de "análise" como um substantivo.
Grave cerca de cinco segundos de silêncio antes da primeira gravação para capturar o "tom do ambiente". Essa prática ajuda o Speech Studio a compensar os ruídos residuais nas gravações.
Dica
Tudo o que você precisa capturar é o talento de voz para que possa fazer uma gravação monofônica (apenas um canal) apenas das falas. No entanto, se você gravar em estéreo, poderá usar o segundo canal para gravar a conversa na sala de controle e capturar a discussão de determinadas falas ou tomadas. Remova essa faixa da versão carregada no Speech Studio.
Ouça atentamente, usando fones de ouvido, a performance do ator de voz. Você está procurando uma boa dicção natural, pronúncia correta e ausência de sons indesejados. Não hesite em pedir ao ator de voz para regravar um enunciado que não atenda a esses padrões.
Dica
Se você estiver usando um grande número de enunciados, um enunciado apenas pode não ter um efeito notável na Sintetização de Voz Personalizada resultante. Pode ser mais vantajoso simplesmente perceber os enunciados com problemas, excluí-los do conjunto de dados e ver o resultado da Sintetização de Voz Personalizada. Mais tarde, você pode voltar ao Studio e gravar as amostras perdidas.
Observe o número da tomada ou código de tempo no script para cada enunciado. Peça para o engenheiro marcar cada um dos enunciados nos metadados da gravação ou na lista de deixas.
Faça pausas regulares e ofereça uma bebida para ajudar o ator de voz a manter uma boa voz.
Após a sessão
Estúdios de gravação modernos são executados em computadores. No final da sessão, você receberá um ou mais arquivos de áudio, não uma fita. Esses arquivos provavelmente são formato WAV ou AIFF na qualidade do CD (44,1 KHz de 16 bits) ou melhor. 24 kHz/16 bits é comum e recomendável. A taxa de amostragem padrão para uma voz neural personalizada é de 24 KHz. É recomendável que você use uma taxa de amostragem de 24 KHz para seus dados de treinamento. Taxas de amostragem mais altas, como 96 KHz, geralmente não são necessárias.
O Speech Studio exige que cada enunciado fornecido esteja em um arquivo separado. Cada arquivo de áudio fornecido pelo Estúdio contém vários enunciados. Portanto, a principal tarefa de pós-produção é dividir as gravações e prepará-las para envio. O engenheiro de gravação pode ter colocado marcadores no arquivo (ou fornecido uma folha de deixas separada) para indicar o ponto em que cada enunciado começa.
Use as anotações para localizar as tomadas corretas que você quer e então use uma ferramenta de edição de som como Avid Pro Tools, Adobe Audition ou o Audacity gratuito para copiar cada enunciado em um novo arquivo.
Ouça cada arquivo atentamente. Nessa fase, é possível editar pequenos sons indesejados que não foram percebidos durante a gravação, como um leve som labial antes de uma fala, mas tenha cuidado para não remover nenhuma fala real. Se você não conseguir consertar um arquivo, remova-o do conjunto de dados e anote que você fez isso.
Converta cada arquivo em 16 bits e em uma taxa de amostragem de 24 KHz antes de salvá-lo e, se você tiver registrado a conversa no estúdio, remova o segundo canal. Salve cada arquivo no formato WAV, nomeando os arquivos com o número do enunciado no script.
Por fim, crie a transcrição que associa cada arquivo WAV a uma versão em texto do enunciado correspondente. Treinar o modelo de voz inclui detalhes do formato necessário. É possível copiar o texto diretamente do script. Em seguida, crie um arquivo zip dos arquivos WAV e a transcrição do texto.
Arquive as gravações originais em um local seguro, caso precise delas posteriormente. Guarde também o script e as anotações.
Próximas etapas
Você está pronto para carregar as gravações e criar a Sintetização de Voz Personalizada.