Monitorar Fluxo de Dados
APLICA-SE A: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Dica
Experimente o Data Factory no Microsoft Fabric, uma solução de análise tudo-em-um para empresas. O Microsoft Fabric abrange desde movimentação de dados até ciência de dados, análise em tempo real, business intelligence e relatórios. Saiba como iniciar uma avaliação gratuita!
Após concluir a criação e a depuração do fluxo de dados, recomendamos programá-lo para executar em um agendamento dentro do contexto de um pipeline. Você pode agendar o pipeline usando Gatilhos. Para testar e depurar o fluxo de dados de um pipeline, é possível usar o botão Depurar na faixa de opções da barra de ferramentas ou em Disparar Agora no construtor de pipeline para rodar uma execução única a fim de testar o fluxo de dados no contexto do pipeline.
Ao executar o pipeline, você poderá monitorar o pipeline e todas as atividades que ele contém, incluindo a atividade do Fluxo de Dados. Selecione o ícone de monitoramento no painel da interface do usuário à esquerda. Será exibida uma tela semelhante à tela a seguir. Os ícones realçados permitem que você analise detalhadamente as atividades no pipeline, incluindo a atividade de Fluxo de Dados.
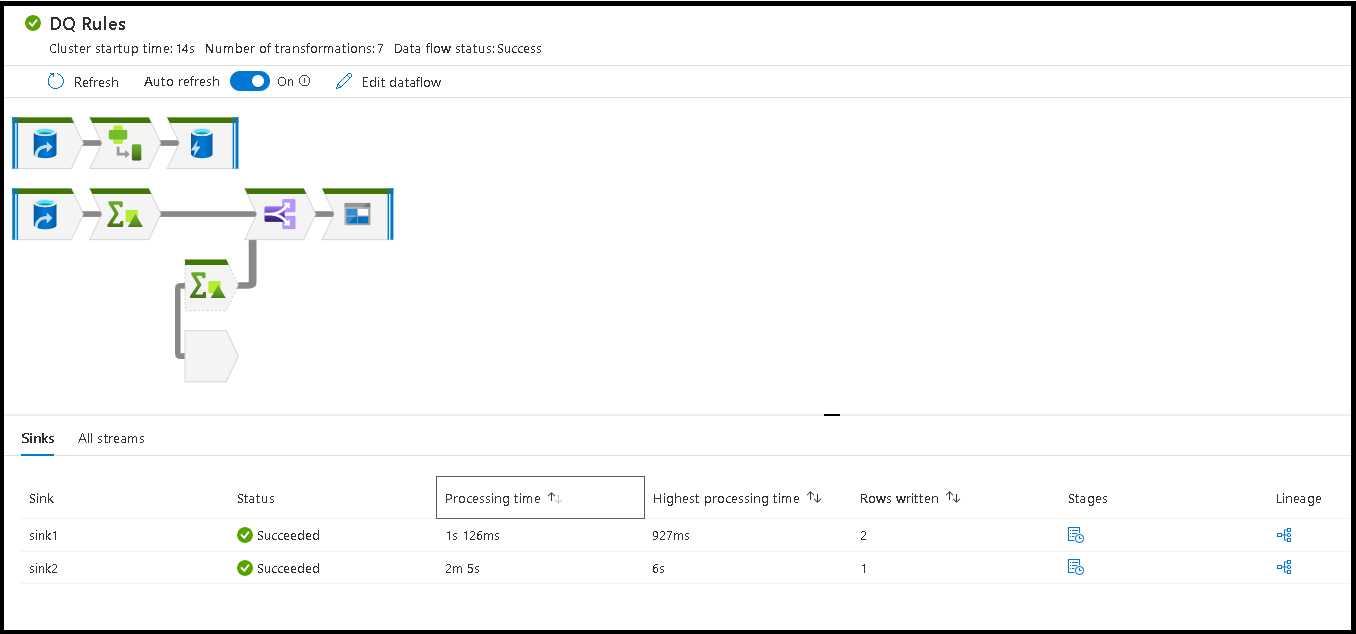
Você verá as estatísticas nesse nível, incluindo os tempos de execução e o status. A ID de execução no nível de atividade é diferente da ID de execução no nível de pipeline. A ID de Execução no nível anterior é para o pipeline. Selecionar o ícone de óculos permite examinar os detalhes da sua execução de fluxo de dados.

Quando estiver na exibição de monitoramento de nós de gráfico, você verá uma versão simplificada do grafo que não pode ser editada do fluxo de dados. Para ver a exibição de detalhes com nós de grafo maiores que incluem rótulos de estágio de transformação, use o controle deslizante de zoom no lado direito da tela. Você também pode usar o botão Pesquisar no lado direito para localizar blocos da lógica de fluxo de dados no grafo.
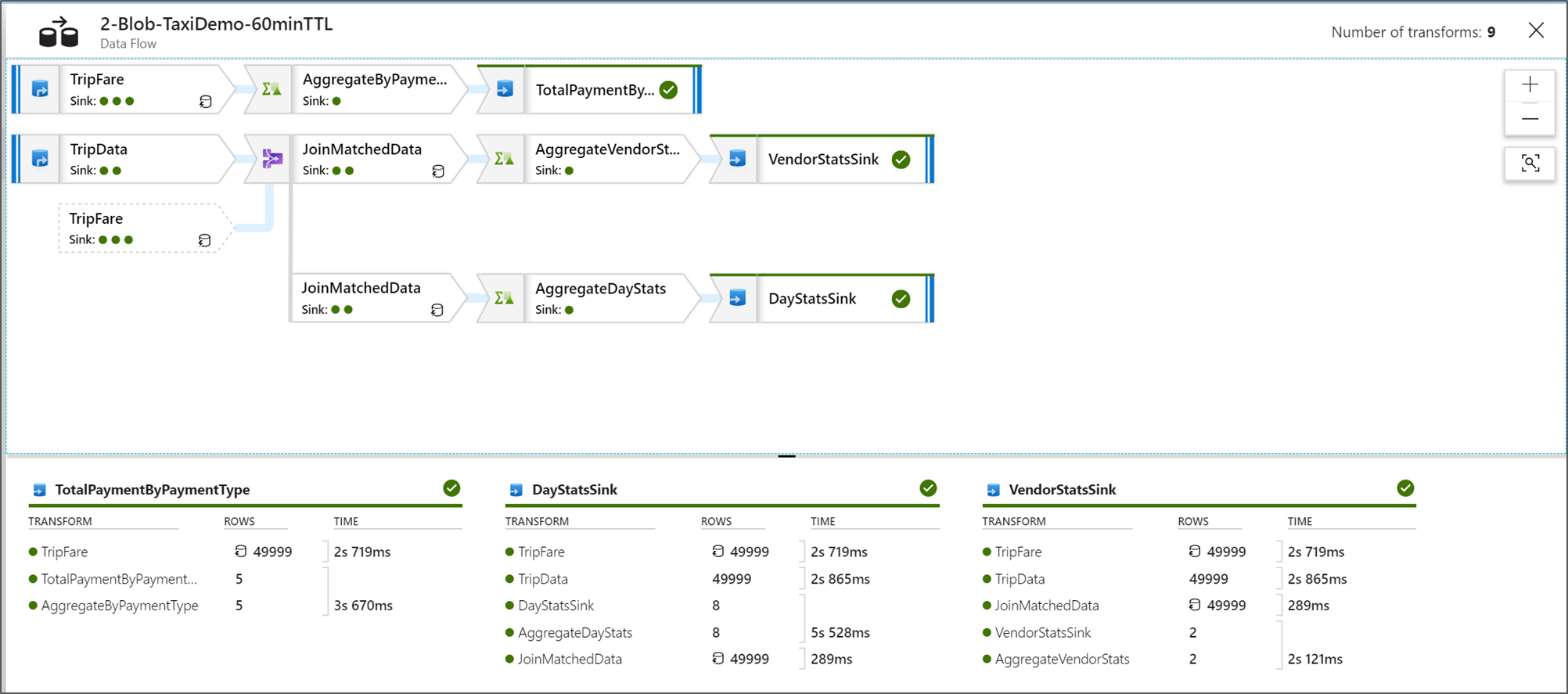
Exibir Planos de Execução do Fluxo de Dados
Quando o Fluxo de Dados é executado no Spark, o serviço determina os caminhos de código ideais com base na totalidade do fluxo de dados. Além disso, os caminhos de execução podem ocorrer em diferentes nós de expansão e partições de dados. Portanto, o grafo de monitoramento representa o design do fluxo, levando em conta o caminho de execução de suas transformações. Ao selecionar nós individuais, você poderá ver “estágios” que representam o código que foi executado junto no cluster. As contagens e intervalos exibidos representam esses grupos ou estágios, ao contrário das etapas individuais no design.
Ao selecionar o espaço aberto na janela de monitoramento, as estatísticas no painel inferior exibem as contagens de linha e tempo para cada coletor e as transformações que conduziram aos dados do coletor para a linhagem de transformação.
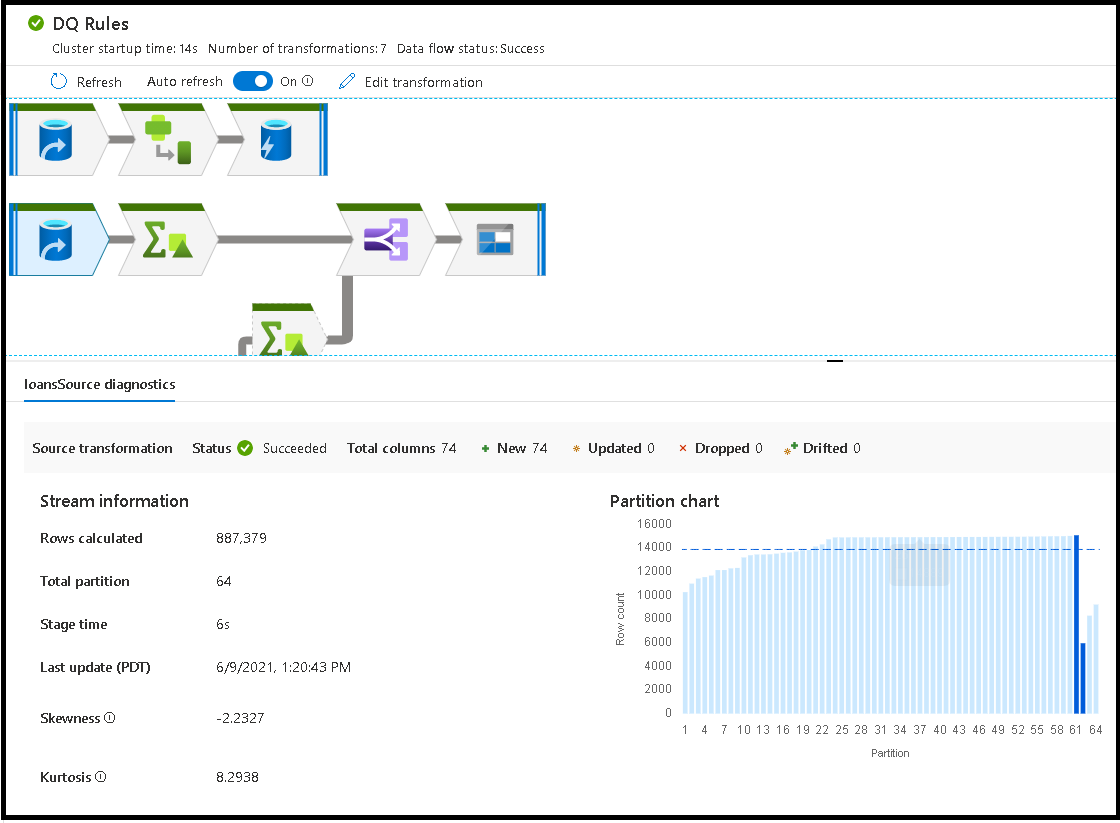
Ao selecionar transformações individuais, você receberá comentários adicionais no painel direito mostrando as estatísticas de partição, contagens de colunas, a assimetria (como os dados estão distribuídos uniformemente em partições) e curtose (se os dados têm muitos picos).
Classificar por tempo de processamento ajuda a identificar quais etapas em seu fluxo de dados levaram mais tempo.
Para descobrir quais transformações dentro de cada estágio levaram mais tempo, classifique o tempo de processamento mais alto.
As *linhas gravadas também são classificáveis como uma maneira de identificar quais fluxos dentro do fluxo de dados estão gravando a maioria dos dados.
Ao selecionar o coletor na exibição do nó, a linhagem da coluna será exibida. Há três métodos diferentes em que as colunas são acumuladas ao longo do fluxo de dados para chegar ao Coletor. Eles são:
- Computado: Você usa a coluna para processamento condicional ou dentro de uma expressão no fluxo de dados, mas não a coloca no coletor
- Derivada: a coluna é uma nova coluna que você gerou no fluxo, ou seja, ela não estava presente na Origem
- Mapeada: a coluna surgiu na origem e você está mapeando-a para um campo de coletor
- Status do fluxo de dados: O status atual da execução
- Tempo de inicialização do cluster: Tempo necessário para adquirir o ambiente de computação do Spark JIT para sua execução de fluxo de dados
- Número de transformações: Quantas etapas de transformação estão sendo executadas no seu fluxo

Tempo total de processamento do coletor versus Tempo de processamento da transformação
Cada estágio de transformação inclui um tempo de execução, com cada tempo de execução de partição totalizado em conjunto. Ao selecionar o Coletor, você obterá o "Tempo de processamento do coletor". Esse tempo inclui o total do tempo de transformação mais o tempo de E/S necessário para gravar os dados no armazenamento de destino. A diferença entre o tempo de processamento do coletor e o total da transformação é o tempo de E/S para gravar os dados.
Outra forma de ver o tempo detalhado de cada etapa de transformação de partição é abrir a saída JSON da atividade do fluxo de dados na exibição de monitoramento de pipeline. O JSON contém o tempo de cada partição em milissegundos, enquanto o modo de exibição de monitoramento de UX é o tempo agregado das partições:
{
"stage": 4,
"partitionTimes": [
14353,
14914,
14246,
14912,
...
]
}
Tempo de processamento do coletor
Quando você selecionar um ícone de transformação do coletor no mapa, o painel deslizante à direita mostrará um ponto de dados adicional chamado "tempo de pós-processamento" na parte inferior. Esse é o tempo da execução do trabalho no cluster Spark depois do carregamento, transformação e gravação dos dados. Esse tempo pode incluir o fechamento de pools de conexão, o desligamento do driver, a exclusão de arquivos, a união de arquivos etc. Ao executar ações em seu fluxo, como "mover arquivos" e "saída para um único arquivo", você provavelmente notará um aumento no valor de tempo pós-processamento.
- Duração do estágio de gravação: o tempo para gravar os dados em um local de preparação para a SQL do Synapse
- Duração do SQL da operação de tabela: O tempo gasto movendo dados de tabelas temporárias para a tabela alvo
- Duração de Pré-SQL e duração de Pós-SQL: o tempo gasto executando comandos pré/pós-SQL
- Duração de pré-comandos e duração de pós-comandos: o tempo gasto na execução de qualquer operação pré/pós para a origem/sinks baseados em arquivo. Por exemplo, mover ou excluir arquivos após o processamento.
- Duração da mesclagem: o tempo gasto mesclando o arquivo, os arquivos de mesclagem são usados para os sinks baseados em arquivo ao gravar em um único arquivo ou quando "Nome do arquivo como dados de coluna" é usado. Se um tempo significativo for gasto nessa métrica, evite usar essas opções.
- Tempo de preparo: Quantidade total de tempo gasto dentro do Spark para concluir a operação como um estágio.
- Preparo temporário estável: Nome da tabela temporária usada por fluxos de dados para preparar dados no banco de dados.
Linhas de erro
A habilitação da manipulação de linhas de erro no coletor de fluxo de dados afeta a saída do monitoramento. Ao definir o coletor como "relatar êxito em caso de erro", a saída de monitoramento mostra o número de linhas com êxito e com falha quando você seleciona o nó de monitoramento do coletor.
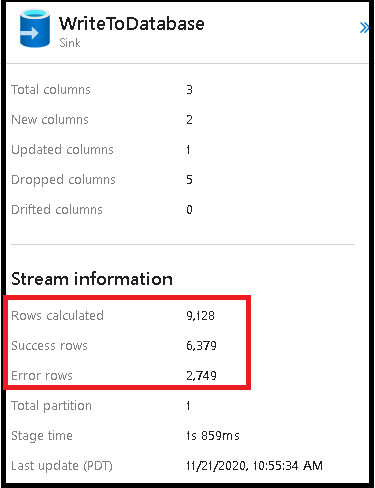
Ao selecionar "relatar falha em caso de erro", a mesma saída é mostrada apenas no texto de saída do monitoramento de atividade. Isso ocorre porque a atividade de fluxo de dados retorna falha para a execução e a exibição de monitoramento detalhada não está disponível.
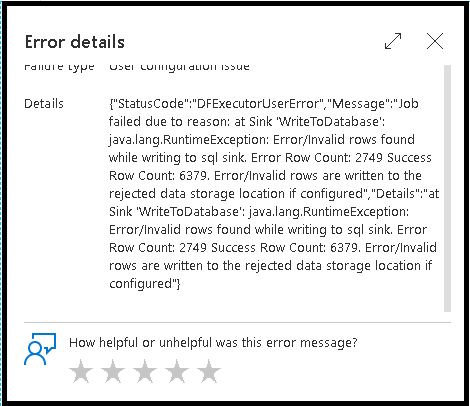
Ícones de monitoramento
Esse ícone significa que os dados de transformação já foram armazenados em cache no cluster, portanto, o caminho de execução e os intervalos levaram isso em consideração:
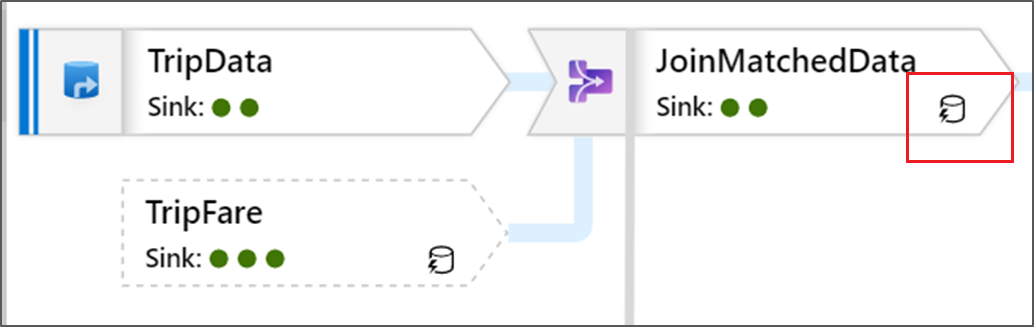
Você também verá ícones de círculo verde na transformação. Eles representam uma contagem do número de coletores para os quais os dados estão fluindo.