Criar e executar trabalhos do Azure Databricks
Este artigo detalha como criar e executar Trabalhos do Azure Databricks usando a interface do usuário de Trabalhos.
Para saber mais sobre as opções de configuração para trabalhos e como editar seus trabalhos existentes, consulte Definir configurações para trabalhos do Azure Databricks.
Para saber como gerenciar e monitorar execuções de trabalho, consulte Exibir e gerenciar execuções de trabalho.
Para criar seu primeiro fluxo de trabalho com um trabalho do Azure Databricks, confira o início rápido.
Importante
- Um workspace é limitado a 1.000 execuções de tarefas simultâneas. Uma resposta
429 Too Many Requestsé retornada quando você solicita uma execução que não pode ser iniciada imediatamente. - O número de trabalhos que um workspace pode criar em uma hora é limitado a 10.000 (inclui “runs submit”). Esse limite também afeta os trabalhos criados pelos fluxos de trabalho da API REST e do notebook.
Criar e executar trabalhos usando a CLI, a API ou os blocos de anotações
- Para saber mais sobre como usar a CLI do Databricks para criar e executar trabalhos, consulte O que é a CLI do Databricks?.
- Para saber mais sobre como usar a API de Trabalhos para criar e executar trabalhos, consulte Trabalhos na referência da API REST.
- Para saber como executar e agendar trabalhos diretamente em um bloco de anotações Databricks, consulte Criar e gerenciar trabalhos de bloco de anotações agendados.
Criar um trabalho
Realize um dos seguintes procedimentos:
- Clique no
 Fluxos de Trabalhos na barra lateral e clique no
Fluxos de Trabalhos na barra lateral e clique no  .
. - Na barra lateral, clique no
 Novo e selecione Trabalho.
Novo e selecione Trabalho.
A guia Tarefas aparece com a caixa de diálogo Criar tarefa, juntamente com o painel lateral Detalhes do trabalho que contém as configurações no nível do trabalho.
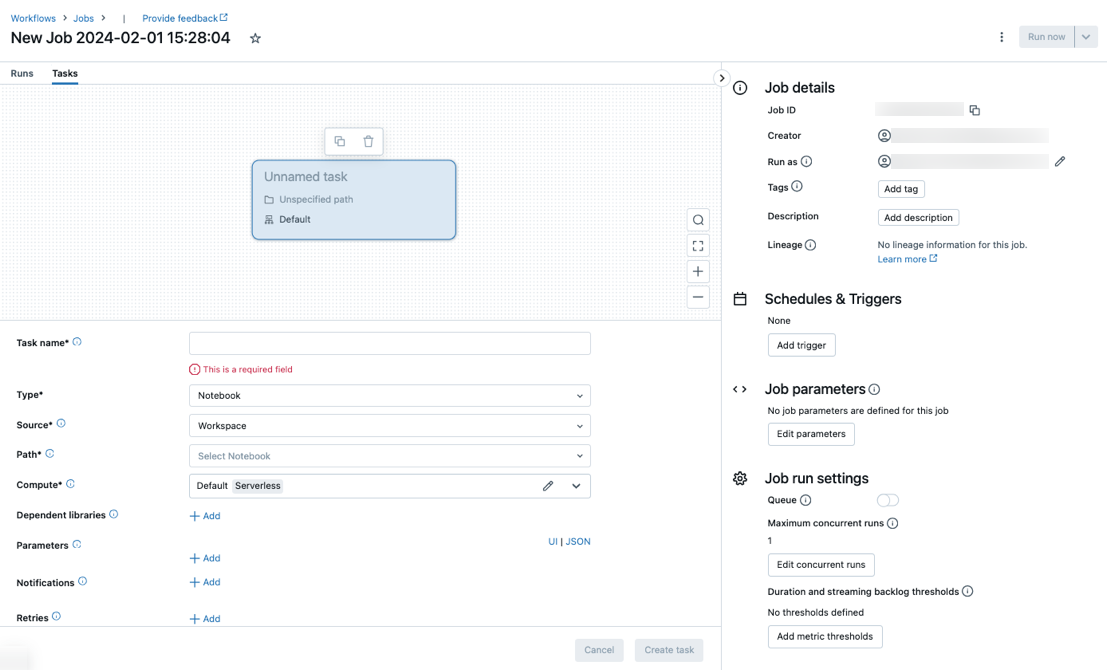
- Clique no
Substitua Novo Trabalho... pelo nome do trabalho.
Insira um nome para a tarefa no campo Nome da tarefa.
No menu suspenso Tipo, selecione o tipo de tarefa a ser executada. Consulte Opções de tipo de tarefa.
Configure o cluster em que a tarefa é executada. Por padrão, a computação sem servidor será selecionada se o seu espaço de trabalho estiver em um espaço de trabalho habilitado para o Unity Catalog e você tiver selecionado uma tarefa compatível com a computação sem servidor para fluxos de trabalho. Veja Execute seu trabalho do Azure Databricks com computação sem servidor para fluxos de trabalho. Se a computação sem servidor não estiver disponível ou você quiser usar um tipo de computação diferente, poderá selecionar um novo cluster de trabalho ou um cluster multifuncional existente no menu suspenso Cálculo.
- Novo Cluster de Trabalho: clique em Editar no menu suspenso Cluster e conclua a configuração do cluster.
- Cluster de Uso Geral Existente: selecione um cluster existente no menu suspenso Cluster. Para abrir o cluster em uma nova página, clique no ícone
 à direita do nome e da descrição do cluster.
à direita do nome e da descrição do cluster.
Para saber mais sobre como selecionar e configurar clusters para executar tarefas, confira Usar a computação do Azure Databricks com seus trabalhos.
Para adicionar bibliotecas dependentes, clique em + Adicionar ao lado de Bibliotecas dependentes. Consulte Configurar bibliotecas dependentes.
Você pode transmitir parâmetros à sua tarefa. Para obter informações sobre os requisitos para formatar e passar parâmetros, consulte Passar parâmetros para uma tarefa de trabalho do Azure Databricks.
Para receber notificações para início de tarefa, êxito ou falha de forma opcional, clique em + Adicionar ao lado de Emails. As notificações de falha são enviadas em caso de falha inicial da tarefa e em novas tentativas subsequentes. Para filtrar notificações e reduzir o número de e-mails enviados, marque Silenciar notificações para execuções ignoradas, Silenciar notificações para execuções canceladas ou Silenciar notificações até a última tentativa.
Para configurar, de forma opcional, uma política de repetição para a tarefa, clique em + Adicionar ao lado de Repetições. Consulte Configurar uma política de repetição para uma tarefa.
Para configurar opcionalmente uma duração esperada ou um tempo limite para a tarefa, clique em + Adicionar ao lado de Limite de duração. Consulte Configurar um tempo de conclusão esperado ou um tempo limite para uma tarefa.
Clique em Criar.
Depois de criar a primeira tarefa, você pode definir configurações no nível do trabalho, como notificações, gatilhos de trabalho e permissões. Consulte Editar um trabalho.
Para adicionar outra tarefa, clique no  na exibição DAG. Uma opção de cluster compartilhado é fornecida se você tiver selecionado computação Sem servidor ou configurado um Novo Cluster de Trabalho para uma tarefa anterior. Você também pode configurar um cluster para cada tarefa ao criar ou editar uma tarefa. Para saber mais sobre como selecionar e configurar clusters para executar tarefas, confira Usar a computação do Azure Databricks com seus trabalhos.
na exibição DAG. Uma opção de cluster compartilhado é fornecida se você tiver selecionado computação Sem servidor ou configurado um Novo Cluster de Trabalho para uma tarefa anterior. Você também pode configurar um cluster para cada tarefa ao criar ou editar uma tarefa. Para saber mais sobre como selecionar e configurar clusters para executar tarefas, confira Usar a computação do Azure Databricks com seus trabalhos.
Opcionalmente, você pode definir configurações de nível de trabalho, como notificações, gatilhos de trabalho e permissões. Consulte Editar um trabalho. Você também pode configurar parâmetros de nível de trabalho compartilhados com as tarefas do trabalho. Consulte Adicionar parâmetros para todas as tarefas de trabalho.
Opções de tipo de tarefa
Veja a seguir os tipos de tarefa que você pode adicionar ao trabalho do Azure Databricks e as opções disponíveis para os diferentes tipos de tarefa:
Notebook: no menu suspenso Origem, selecione Workspace para usar um notebook localizado em uma pasta de workspace do Azure Databricks ou Provedor Git para um notebook localizado em um repositório Git remoto.
Workspace: use o navegador de arquivos para encontrar o notebook, clique no nome do notebook e clique em Confirmar.
Provedor Git: clique em Editar ou Adicionar referência do Git e insira as informações do repositório Git. Consulte Usar um notebook de um repositório Git remoto.
Observação
A saída total de células do notebook (a saída combinada de todas as células do notebook) está sujeita a um limite de tamanho de 20 MB. Além disso, a saída individual da célula está sujeita a um limite de tamanho de 8 MB. Se a saída de células total exceder 20 MB de tamanho, ou se a saída de uma célula individual for maior que 8 MB, a execução será cancelada e marcada com falha.
Se você precisar de ajuda para encontrar células próximas ao limite ou que o tenham ultrapassado, execute o notebook em um cluster de uso geral e use esta técnica de salvamento automático do notebook.
JAR: especifique a classe Main. Use o nome totalmente qualificado da classe que contém o método main, por exemplo,
org.apache.spark.examples.SparkPi. Em seguida, clique em Adicionar em Bibliotecas Dependentes a fim de adicionar bibliotecas exigidas pela execução da tarefa. Uma dessas bibliotecas precisa conter a classe main.Para saber mais sobre tarefas JAR, consulte Usar um JAR em um trabalho do Azure Databricks.
Envio do Spark: na caixa de texto Parâmetros, especifique a classe main, o caminho para o JAR da biblioteca e todos os argumentos, tudo formatado como uma matriz JSON de cadeias de caracteres. O exemplo abaixo configura uma tarefa spark-submit para executar o
DFSReadWriteTestde exemplos do Apache Spark:["--class","org.apache.spark.examples.DFSReadWriteTest","dbfs:/FileStore/libraries/spark_examples_2_12_3_1_1.jar","/discover/databricks-datasets/README.md","/FileStore/examples/output/"]Importante
Há várias limitações nas tarefas spark-submit:
- Você pode invocar tarefas de envio do Spark apenas em novos clusters.
- O spark-submit não dá suporte ao dimensionamento automático do cluster. Para saber mais sobre dimensionamento automático, confira Dimensionamento automático de cluster.
- O spark-submit não dá suporte aos Referência do Utilitários do Databricks (dbutils). Para usar os Utilitários do Databricks, use tarefas JAR.
- Se você estiver usando um cluster habilitado para Catálogo Unity, o spark-submit será suportado somente se o cluster usar o modo acesso atribuído. Não há suporte para o modo de acesso compartilhado.
- Os trabalhos de streaming do Spark nunca devem ter execuções simultâneas máximas definidas como maior que 1. Os trabalhos de streaming devem ser definidos para execução usando a expressão Cron
"* * * * * ?"(a cada minuto). Já que uma tarefa de streaming é executada continuamente, ela sempre deve ser a tarefa final em um trabalho.
Script Python: no menu suspenso Origem, selecione um local para o script Python, Workspace para um script no espaço de trabalho local, DBFS para um script localizado no DBFS ou provedor Git para um script localizado em um repositório Git. Na caixa de texto Caminho, insira o caminho para o script Python:
Workspace: na caixa de diálogo Selecionar Arquivo Python, navegue até o script Python e clique em Confirmar.
DBFS: insira o URI de um script Python no DBFS ou no armazenamento em nuvem; por exemplo,
dbfs:/FileStore/myscript.py.Provedor Git: clique em Editar e insira as informações do repositório Git. Consulte Usar código Python de um repositório Git remoto.
Pipeline do Delta Live Tables: no menu suspenso Pipeline, selecione um pipeline do Delta Live Tables existente.
Importante
Você só pode usar pipelines disparados com a tarefa Pipeline. Não há suporte para pipelines contínuos como uma tarefa de trabalho. Para saber mais sobre os pipelines disparados e contínuos, confira Execução de pipelines contínuos versus pipelines disparados.
Roda do Python: na caixa de texto Nome do pacote, insira o pacote a ser importado, por exemplo,
myWheel-1.0-py2.py3-none-any.whl. Na caixa de texto Entry Point, insira a função a ser chamada ao iniciar o arquivo wheel Python. Clique em Adicionar em Bibliotecas Dependentes a fim de adicionar bibliotecas exigidas pela execução da tarefa.SQL: No menu suspenso Tarefa SQL, selecione Consulta, Painel herdado, Alerta ou Arquivo.
Observação
- A tarefa SQL requer o SQL do Databricks e um warehouse de SQL Pro ou sem servidor.
Consulta: no menu suspenso Consulta SQL, selecione a consulta a ser executada quando a tarefa for executada.
Painel herdado: No menu suspenso Painel SQL, selecione um painel a ser atualizado quando a tarefa for executada.
Alerta: no menu suspenso de alerta do SQL, selecione um alerta a ser disparado para avaliação.
Arquivo: para usar um arquivo SQL localizado em uma pasta de workspace do Azure Databricks, no menu suspenso Origem, selecione Workspace, use o explorador de arquivos para localizar o arquivo SQL, clique no nome do arquivo e clique em Confirmar. Para usar um arquivo SQL localizado em um repositório Git remoto, selecione Provedor Git, clique em Editar ou Adicionar uma referência do Git e insira detalhes para o repositório Git. Consulte Usar consultas SQL de um repositório Git remoto.
No menu suspenso do SQL warehouse, selecione um warehouse de SQL sem servidor ou Pro para executar a tarefa.
dbt: consulte Usar transformações dbt em um trabalho do Azure Databricks para obter um exemplo detalhado de como configurar uma tarefa dbt.
Executar trabalho: no menu suspenso Trabalho selecione um trabalho a ser executado pela tarefa. Para procurar o trabalho a ser executado, comece a digitar o nome do trabalho no menu Trabalho.
Importante
Você não deve criar trabalhos com dependências circulares ao usar a tarefa
Run Jobou trabalhos que aninham mais de três tarefasRun Job. As dependências circulares sãoRun Jobtarefas que direta ou indiretamente acionam umas às outras. Por exemplo, o Trabalho A aciona o Trabalho B e o Trabalho B aciona o Trabalho A. O Databricks não oferece suporte a trabalhos com dependências circulares ou que aninham mais de trêsRun Jobtarefas e podem não permitir a execução desses trabalhos em versões futuras.If/else: para saber como usar a tarefa
If/else condition, consulte Adicionar lógica de ramificação ao seu trabalho com a tarefa de condição If/else.
Passar parâmetros para uma tarefa de trabalho do Azure Databricks
Você pode passar parâmetros para muitos dos tipos de tarefa de trabalho. Cada tipo de tarefa tem requisitos diferentes de formatação e transmissão dos parâmetros.
Para acessar informações sobre a tarefa atual, como o nome da tarefa, ou passar o contexto sobre a execução atual entre tarefas de trabalho, como a hora de início do trabalho ou o identificador da execução do trabalho atual, use referências de valor dinâmico. Para exibir uma lista de referências de valor dinâmico disponíveis, clique em Procurar valores dinâmicos.
Se os parâmetros de trabalho estiverem configurados no trabalho ao qual uma tarefa pertence, esses parâmetros serão exibidos quando você adicionar parâmetros de tarefa. Se os parâmetros de trabalho e tarefa compartilharem uma chave, o parâmetro de trabalho terá precedência. Um aviso será mostrado na interface do usuário se você tentar adicionar um parâmetro de tarefa com a mesma chave que um parâmetro de trabalho. Para passar parâmetros de trabalho para tarefas que não estão configuradas com parâmetros chave-valor, como tarefas JAR ou Spark Submit, formate argumentos como {{job.parameters.[name]}}, substituindo [name] pelo key que identifica o parâmetro.
Notebook: clique em Adicionar e especifique a chave e o valor de cada parâmetro a ser transmitido à tarefa. Você pode substituir ou adicionar parâmetros adicionais ao executar manualmente uma tarefa com a opção Executar um trabalho com parâmetros diferentes. Os parâmetros definem o valor do widget de notebook especificado pela chave do parâmetro.
JAR: use uma matriz de cadeia de caracteres formatada em JSON para especificar parâmetros. Essas cadeias de caracteres são transmitidas como argumentos ao método main da classe main. Consulte Configurar parâmetros de trabalho JAR.
Envio do Spark: os parâmetros são especificados como uma matriz de cadeias de caracteres formatada em JSON. Em conformidade com a convenção spark-submit do Apache Spark, os parâmetros após o caminho JAR são transmitidos ao método main da classe main.
Wheel do Python: no menu suspenso Parâmetros, selecione Argumentos posicionais para inserir parâmetros como uma matriz de cadeias de caracteres no formato JSON ou selecione Argumentos de palavra-chave > Adicionar para inserir a chave e o valor de cada parâmetro. Os argumentos posicionais e de palavra-chave são passados à tarefa de wheel do Python como argumentos de linha de comando. Para ver um exemplo de leitura de argumentos em um script Python empacotado em um arquivo roda Python, veja Usar um arquivo roda Python em um trabalho do Azure Databricks.
Executar Trabalho: insira a chave e o valor de cada parâmetro de trabalho a ser passado para o trabalho.
Script do Python: use uma matriz de cadeia de caracteres formatada em JSON para especificar parâmetros. Essas cadeias de caracteres são passadas como argumentos e podem ser lidas como argumentos posicionais ou analisadas usando o módulo argparse em Python. Para ver um exemplo de leitura de argumentos posicionais em um script Python, consulte Etapa 2: criar um script para buscar dados do GitHub.
SQL: se sua tarefa executar uma consulta parametrizada ou um painel parametrizado, insira valores para os parâmetros nas caixas de texto fornecidas.
Copiar um caminho de tarefa
Determinados tipos de tarefa, por exemplo, tarefas de notebook, permite copiar o caminho para o código-fonte da tarefa:
- Clique na guia Tarefas.
- Selecione a tarefa que contém o caminho a ser copiado.
- Clique no
 ao lado do caminho da tarefa para copiar o caminho na área de transferência.
ao lado do caminho da tarefa para copiar o caminho na área de transferência.
Criar um trabalho a partir de um trabalho existente
Você pode criar rapidamente um novo trabalho clonando um trabalho existente. A clonagem de um trabalho cria uma cópia idêntica do trabalho, exceto sua ID. Na página do trabalho, clique em Mais... ao lado do nome do trabalho e selecione Clonar no menu suspenso.
Criar uma tarefa a partir de uma tarefa existente
Você pode criar rapidamente outra tarefa clonando uma tarefa existente:
- Na página do trabalho, clique na guia Tarefas.
- Selecione a tarefa a ser clonada.
- Clique em
 e selecione Clonar tarefa.
e selecione Clonar tarefa.
Excluir um Trabalho
Para excluir um trabalho, na página do trabalho, clique em Mais... ao lado do nome do trabalho e selecione Excluir no menu suspenso.
Excluir uma tarefa
Para excluir uma tarefa, faça o seguinte:
- Clique na guia Tarefas.
- Selecione a tarefa a ser excluída.
- Clique em e selecione Remover tarefa.
Executar um trabalho
- Clique no Fluxos de Trabalho na barra lateral.
- Selecione um trabalho e clique na guia Execuções. Você pode executar um trabalho imediatamente ou agendar o trabalho para ser executado posteriormente.
Se uma ou mais tarefas em um trabalho de várias tarefas não forem bem-sucedidas, execute novamente o subconjunto de tarefas malsucedidas. Consulte Executar novamente tarefas com falha e ignoradas.
Executar um trabalho imediatamente
Para executar o trabalho imediatamente, clique no  .
.
Dica
Você pode fazer uma execução de teste de um trabalho com uma tarefa de notebook clicando em Executar Agora. Se você precisar fazer alterações no notebook, um clique em Executar Agora novamente depois de editar o notebook executará automaticamente a nova versão do notebook.
Executar um trabalho com parâmetros diferentes
Você pode usar Executar Agora com Parâmetros Diferentes para executar novamente um trabalho com parâmetros diferentes ou valores diferentes para parâmetros existentes.
Observação
Você não poderá substituir parâmetros de trabalho se um trabalho executado antes da introdução dos parâmetros de trabalho tiver substituído os parâmetros de tarefa com a mesma chave.
- Clique no
 ao lado de Executar Agora e selecione Executar Agora com Parâmetros Diferentes ou, na tabela Execuções Ativas, clique em Executar Agora com Parâmetros Diferentes. Insira os novos parâmetros de acordo com o tipo de tarefa. Consulte Passar parâmetros para uma tarefa de trabalho do Azure Databricks.
ao lado de Executar Agora e selecione Executar Agora com Parâmetros Diferentes ou, na tabela Execuções Ativas, clique em Executar Agora com Parâmetros Diferentes. Insira os novos parâmetros de acordo com o tipo de tarefa. Consulte Passar parâmetros para uma tarefa de trabalho do Azure Databricks. - Clique em Executar.
Executar um trabalho como entidade de serviço
Observação
Se o seu trabalho executar consultas SQL usando a tarefa SQL, a identidade usada para executar as consultas será determinada pelas configurações de compartilhamento de cada consulta, mesmo que o trabalho seja executado como uma entidade de serviço. Se uma consulta for configurada como Run as owner, a consulta será sempre executada usando a identidade do proprietário e não a identidade da entidade de serviço. Se a consulta estiver configurada como Run as viewer, a consulta será executada usando a identidade da entidade de serviço. Para saber mais sobre as configurações de compartilhamento de consultas, veja Configurar permissões de consulta.
Por padrão, os trabalhos são executados como a identidade do proprietário do trabalho. Isso significa que o trabalho assume as permissões do proprietário do trabalho. O trabalho só pode acessar dados e objetos do Azure Databricks que o proprietário do trabalho tem permissões para acessar. Você pode alterar a identidade que o trabalho está executando quanto a uma entidade de serviço. Em seguida, o trabalho assume as permissões dessa entidade de serviço em vez do proprietário.
Para alterar a configuração Executar como, é necessário ter a permissão PODE GERENCIAR ou É PROPRIETÁRIO no trabalho. Você pode definir a configuração Executar como para si mesmo ou para qualquer entidade de serviço no workspace no qual você tem a função de Usuário da entidade de serviço. Para obter mais informações, consulte Funções para gerenciar entidades de serviço.
Observação
Quando a configuração RestrictWorkspaceAdmins em um workspace é definida como ALLOW ALL, os administradores do workspace também podem alterar a configuração Executar como para qualquer usuário em seu workspace. Para restringir os administradores do workspace a alterar a configuração Executar como apenas para si mesmos ou entidades de serviço nas quais eles têm a função de Usuário da entidade de serviço, confira Restringir administradores do workspace.
Para alterar o campo executar como, faça o seguinte:
- Na barra lateral, clique em Workflows.
- Na coluna Nome, clique no nome do trabalho.
- No painel lateral Detalhes do trabalho clique no ícone de lápis ao lado do campo Executar como.
- Procure e escolha a entidade de serviço.
- Clique em Save (Salvar).
Você também pode listar as entidades de serviço nas quais você tem a função Usuário usando a API de Entidades de Serviço do Workspace. Para obter mais informações, consulte Listar as entidades de serviço que você pode usar.
Executar um trabalho em uma agenda
Você pode usar uma agenda para executar automaticamente seu trabalho do Azure Databricks em horários e períodos especificados. Consulte Adicionar uma agenda de trabalho.
Executar um trabalho contínuo
Você pode garantir que sempre haja uma execução ativa do seu trabalho. Consulte Executar um trabalho contínuo.
Executar um trabalho quando novos arquivos chegarem
Para disparar a execução de um trabalho quando novos arquivos chegarem a um local ou volume externo do Catálogo do Unity, use um gatilho de chegada de arquivo.
Ver e executar um trabalho criado com um Databricks Asset Bundle
Você pode usar a UI do Azure Databricks Jobs para visualizar e executar trabalhos implantados por um Databricks Asset Bundle. Por padrão, esses trabalhos são somente leitura na UI de trabalhos. Para editar uma tarefa implementada por um pacote configurável, altere o arquivo de configuração do pacote configurável e reimplemente a tarefa. Aplicar alterações somente à configuração do pacote configurável garante que os arquivos de origem do pacote configurável sempre capturem a configuração atual da tarefa.
No entanto, se for necessário fazer alterações imediatas em uma tarefa, você poderá desconectar a tarefa da configuração do pacote configurável para permitir a edição das configurações da tarefa na interface do usuário. Para desconectar o trabalho, clique em Desconectar da origem. Na caixa de diálogo Desconectar da fonte, clique em Desconectar para confirmar.
Quaisquer alterações feitas na tarefa na UI não serão aplicadas à configuração do pacote configurável. Para aplicar alterações feitas na UI ao pacote configurável, você deve atualizar manualmente a configuração do pacote configurável. Para reconectar a tarefa à configuração do pacote configurável, reimplante a tarefa usando o pacote configurável.
E se meu trabalho não puder ser executado devido aos limites de simultaneidade?
Observação
O enfileiramento é habilitado por padrão quando os trabalhos são criados na UI.
Para evitar que execuções de um trabalho sejam ignoradas devido a limites de simultaneidade, você pode habilitar o enfileiramento para o trabalho. Quando a fila está habilitada, se os recursos não estiverem disponíveis para uma execução de trabalho, a execução será enfileirada por até 48 horas. Quando a capacidade está disponível, a execução do trabalho é desenfileirada e executada. As execuções em fila são exibidas na lista de execuções do trabalho e na lista de execuções de trabalho recentes.
Uma execução é enfileirada quando um dos seguintes limites é atingido:
- O máximo de ativos simultâneos é executado no espaço de trabalho.
- O máximo de
Run Jobtarefas simultâneas é executado no espaço de trabalho. - O máximo de execuções simultâneas do trabalho.
Enfileiramento é uma propriedade de nível de trabalho que as filas são executadas somente para esse trabalho.
Para habilitar ou desabilitar o enfileiramento, clique em Configurações avançadas e clique no botão de alternância Fila no painel lateral Detalhes do trabalho.
Comentários
Em breve: Ao longo de 2024, eliminaremos os problemas do GitHub como o mecanismo de comentários para conteúdo e o substituiremos por um novo sistema de comentários. Para obter mais informações, consulte https://aka.ms/ContentUserFeedback.
Enviar e exibir comentários de