HorovodRunner: aprendizado profundo distribuído com Horovod
Saiba como executar o treinamento distribuído de modelos de machine learning usando o HorovodRunner para iniciar trabalhos de treinamento do Horovod como trabalhos do Spark no Azure Databricks.
O que é o HorovodRunner?
HorovodRunner é uma API geral para executar cargas de trabalho de aprendizado profundo distribuídas no Azure Databricks usando a estrutura Horovod. Ao integrar o Horovod ao modo de barreira do Spark, o Azure Databricks é capaz de fornecer maior estabilidade para trabalhos de treinamento de aprendizado profundo de longa duração no Spark. O HorovodRunner usa um método Python que contém código de treinamento de aprendizado profundo com ganchos de Horovod. HorovodRunner trata o método no driver e o distribui para funções de trabalho do Spark. Um trabalho MPI do Horovod é inserido como um trabalho do Spark usando o modo de execução de barreira. O primeiro executor coleta os endereços IP de todos os executores de tarefa usando BarrierTaskContext e dispara um trabalho Horovod usando mpirun. Cada processo de MPI do Python carrega o programa de usuário tratado, o desserializa e o executa.

Treinamento distribuído com o HorovodRunner
O HorovodRunner permite que você inicie trabalhos de treinamento do Horovod como trabalhos do Spark. A API HorovodRunner dá suporte aos métodos mostrados na tabela. Para obter detalhes, confira a documentação da API do HorovodRunner.
| Método e assinatura | Descrição |
|---|---|
init(self, np) |
Crie uma instância de HorovodRunner. |
run(self, main, **kwargs) |
Execute um trabalho de treinamento do Horovod invocando main(**kwargs). A função principal e os argumentos de palavra-chave são serializados usando cloudpickle e distribuídos para funções de trabalho de cluster. |
A abordagem geral para desenvolver um programa de treinamento distribuído usando o HorovodRunner é:
- Criar uma instância inicializada
HorovodRunnercom o número de nós. - Definir um método de treinamento Horovod de acordo com os métodos descritos em uso do Horovod, garantindo a adição de quaisquer instruções de importação dentro do método.
- Passar o método de treinamento para a instância
HorovodRunner.
Por exemplo:
hr = HorovodRunner(np=2)
def train():
import tensorflow as tf
hvd.init()
hr.run(train)
Para executar o HorovodRunner apenas no driver com n subprocessos, use hr = HorovodRunner(np=-n). Por exemplo, se houver quatro GPUs no nó de driver, você poderá escolher de n a 4. Para obter detalhes sobre o parâmetro np, confira a documentação da API do HorovodRunner. Para obter detalhes sobre como fixar uma GPU por subprocesso, confira o Guia de uso do Horovod.
Um erro comum é que os objetos TensorFlow não podem ser encontrados ou tratados. Isso acontece quando as instruções de importação de biblioteca não são distribuídas para outros executores. Para evitar esse problema, inclua todas as instruções de importação (por exemplo, import tensorflow as tf) na parte superior do método de treinamento Horovod e dentro de qualquer outra função definida pelo usuário chamada no método de treinamento do Horovod.
Registre o treinamento do Horovod com a linha do tempo do Horovod
O Horovod tem a capacidade de registrar a linha do tempo de sua atividade, chamada Horovod Timeline.
Importante
O Horovod Timeline tem um impacto significativo no desempenho. A taxa de transferência de Inception3 pode diminuir em cerca de 40% quando o Horovod Timeline estiver habilitado. Para acelerar trabalhos do HorovodRunner, não use o Horovod Timeline.
Não é possível exibir o Horovod Timeline enquanto o treinamento estiver em andamento.
Para registrar um Horovod Timeline, defina a variável de ambiente HOROVOD_TIMELINE para o local onde você deseja salvar o arquivo de linha do tempo. O Databricks recomenda o uso de um local no armazenamento compartilhado para que o arquivo de linha do tempo possa ser facilmente recuperado. Por exemplo, você pode usar APIs de arquivo local do DBFS, conforme mostrado:
timeline_dir = "/dbfs/ml/horovod-timeline/%s" % uuid.uuid4()
os.makedirs(timeline_dir)
os.environ['HOROVOD_TIMELINE'] = timeline_dir + "/horovod_timeline.json"
hr = HorovodRunner(np=4)
hr.run(run_training_horovod, params=params)
Em seguida, adicione o código específico à linha do tempo ao início e ao fim da função de treinamento. O notebook de exemplo a seguir inclui um código de exemplo que você pode usar como solução alternativa para exibir o progresso do treinamento.
Notebook de exemplo do Horovod Timeline
Para baixar o arquivo de linha do tempo, use a CLI do Databricks ou o FileStore e, em seguida, use o recurso de chrome://tracing do navegador Chrome para vê-la. Por exemplo:
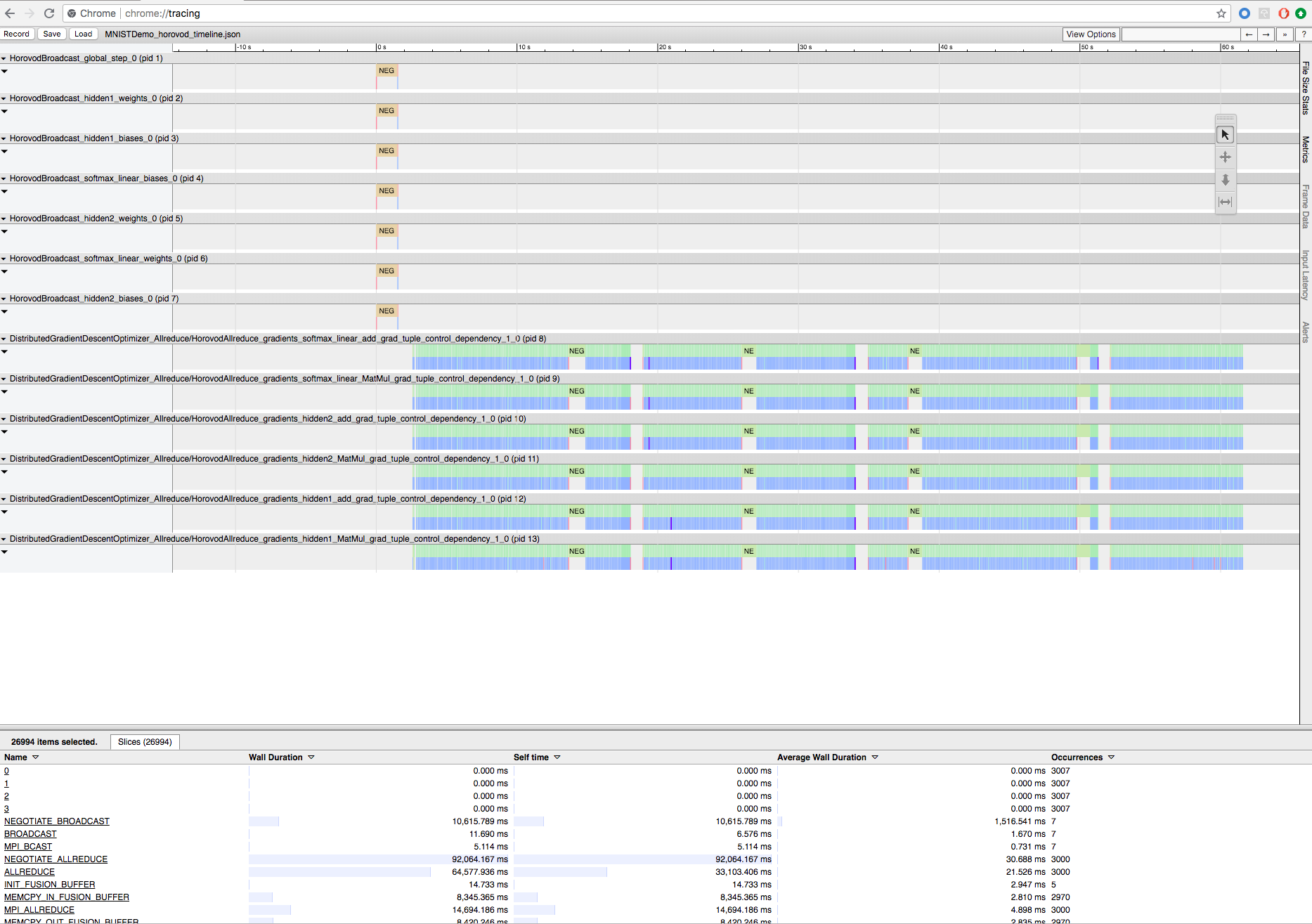
Fluxo de trabalho de desenvolvimento
Estas são as etapas gerais para migrar o código de aprendizado profundo de nó único para o treinamento distribuído. Os Exemplos: migrar para aprendizado profundo distribuído com o HorovodRunner nesta seção ilustram estas etapas.
- Preparar o código de um único nó: prepare e teste o código de nó único com TensorFlow, Keras ou PyTorch.
- Migrar para o Horovod: siga as instruções de uso do Horovod para migrar o código com Horovod e testá-lo no driver:
- Adicione
hvd.init()para inicializar o Horovod. - Fixe uma GPU de servidor a ser usada por este processo usando
config.gpu_options.visible_device_list. Com a configuração típica de uma GPU por processo, isso pode ser definido como classificação local. Nesse caso, o primeiro processo no servidor será alocado para a primeira GPU, o segundo processo será alocado para a segunda GPU e assim por diante. - Inclua um fragmento do conjunto de dados. Esse operador de conjunto de dados é muito útil ao executar o treinamento distribuído, pois permite que cada trabalhador leia um subconjunto exclusivo.
- Escale a taxa de aprendizado por número de funções de trabalho. O tamanho efetivo do lote no treinamento distribuído síncrono é escalado pelo número de funções de trabalho. O aumento da taxa de aprendizagem compensa o aumento do tamanho do lote.
- Encapsule o otimizador em
hvd.DistributedOptimizer. O otimizador distribuído delega a computação de gradiente para o otimizador original, calcula a média de gradientes usando allreduce ou allgather e, em seguida, aplica os gradientes médios. - Adicione
hvd.BroadcastGlobalVariablesHook(0)para transmitir os estados de variável iniciais da classificação 0 a todos os outros processos. Isso é necessário para garantir uma inicialização consistente de todas as funções de trabalho quando o treinamento é iniciado com pesos aleatórios ou restaurado de um ponto de verificação. Como alternativa, se você não estiver usandoMonitoredTrainingSession, poderá executar a operaçãohvd.broadcast_global_variablesapós a inicialização das variáveis globais. - Modifique seu código para salvar pontos de verificação somente na função de trabalho 0 para impedir que outras funções de trabalho os corrompam.
- Adicione
- Migrar para o HorovodRunner: o HorovodRunner executa o trabalho de treinamento do Horovod invocando uma função do Python. Você deve envolver o procedimento de treinamento principal em uma única função do Python. Em seguida, você pode testar o HorovodRunner no modo local e no modo distribuído.
Atualizar as bibliotecas de aprendizado profundo
Observação
Este artigo contém referências ao termo escravo, que o Azure Databricks não usa mais. Quando o termo for removido do software, também o removeremos deste artigo.
Se você atualizar ou fazer downgrade do TensorFlow, do Keras ou do PyTorch, deverá reinstalar o Horovod para que ele seja compilado em relação à biblioteca recentemente instalada. Por exemplo, se você quiser atualizar o TensorFlow, o Databricks recomendará o uso do script init nas instruções de instalação do TensorFlow e acrescentará o seguinte código de instalação do Horovod específico ao TensorFlow ao final dele. Confira as instruções de instalação do Horovod para trabalhar com diferentes combinações, como atualizar ou fazer downgrade do PyTorch e de outras bibliotecas.
add-apt-repository -y ppa:ubuntu-toolchain-r/test
apt update
# Using the same compiler that TensorFlow was built to compile Horovod
apt install g++-7 -y
update-alternatives --install /usr/bin/gcc gcc /usr/bin/gcc-7 60 --slave /usr/bin/g++ g++ /usr/bin/g++-7
HOROVOD_GPU_ALLREDUCE=NCCL HOROVOD_CUDA_HOME=/usr/local/cuda pip install horovod==0.18.1 --force-reinstall --no-deps --no-cache-dir
Exemplos: migrar para o aprendizado profundo distribuído com o HorovodRunner
Os exemplos a seguir, com base no conjunto de dados MNIST, demonstram como migrar um programa de aprendizado profundo de nó único para o aprendizado profundo distribuído com o HorovodRunner.
- Aprendizado profundo usando o TensorFlow com o HorovodRunner para MNIST
- Adapte o PyTorch de nó único à aprendizagem profunda distribuída
Limitações
- Ao trabalhar com arquivos de workspace, o HorovodRunner não funcionará se
npestiver definido como maior que 1 e o notebook importar de outros arquivos relativos. Considere usar horovod.spark em vez deHorovodRunner.