Fevereiro de 2018
As versões são disponibilizadas em fases. Talvez sua conta do Azure Databricks só seja atualizada uma semana após a data de lançamento inicial.
Novo gráfico de linhas dá suporte a dados de série temporal
27 de fevereiro - 6 de março de 2018: versão 2.66
Um novo gráfico de linhas dá suporte completo a dados de séries temporal e resolve limitações com nossa opção de gráfico de linhas antigo. O gráfico de linhas antigo foi preterido e recomendamos que os usuários migrem todas as visualizações que usam o gráfico de linhas antigo para a nova.
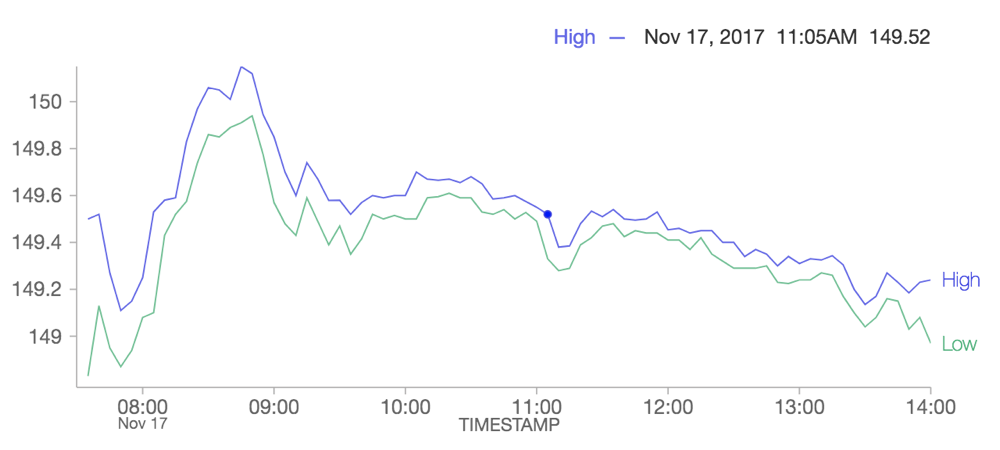
Confira Migrar gráficos de linhas herdados para obter mais informações.
Mais aprimoramentos de visualização
27 de fevereiro - 6 de março de 2018: versão 2.66
Agora você pode classificar colunas na saída da tabela e usar mais de 10 itens de legenda em um gráfico.
Excluir execuções de trabalho usando a API de trabalho
27 de fevereiro - 6 de março de 2018: versão 2.66
Agora você pode usar a API de Trabalho para excluir as execuções de trabalho usando o novo ponto de extremidade jobs/runs/delete.
Consulte Executa a exclusão para obter mais informações.
Biblioteca de renderização matemática do KaTeX atualizada
27 de fevereiro - 6 de março de 2018: versão 2.66
A versão do LtdTeX que o Azure Databricks usa para renderização de equação matemática foi atualizada de 0.5.1 para 0.9.0-beta1.
Essa atualização apresenta alterações que podem quebrar expressões que foram escritas na 0.5.1:
\xLongequalagora é\xlongequal(#997)[text]coloras cores HTML devem ser bem formadas. (#827)\llape\rlapagora renderiza o conteúdo no modo de matemática. Use\mathllap(novo) e\mathrlap(novo) para fornecer o comportamento anterior.\colore\textcoloragora se comportam como no LaTeX (nº 619)
Consulte as notas sobre a versão do KaTeX para obter mais informações.
CLI do Databricks: Versão 0.5.0
27 de fevereiro de 2018: databricks-cli 0.5.0
A CLI do Databricks agora dá suporte a comandos destinados à API de Bibliotecas.
A CLI agora também suporta vários perfis de conexão. Perfis de conexão podem ser usados para configurar a CLI para se falar com várias implantações do Azure Databricks.
Confira CLI do Databricks (herdada) para obter mais informações.
Biblioteca de API do DBUtils
13 a 20 de fevereiro de 2018: Versão 2.65
O Azure Databricks fornece uma variedade de APIs de utilitário que permitem que você trabalhe facilmente com DBFS, fluxos de trabalho de notebook e widgets. A dbutils-api biblioteca acelera o desenvolvimento de aplicativos, permitindo que você compile e execute testes de unidade localmente nessas APIs de utilitário antes de implantar seu aplicativo em um cluster do Azure Databricks.
Confira Biblioteca de API de Utilitários do Databricks para obter mais informações.
Filtrar somente os trabalhos
13 a 20 de fevereiro de 2018: Versão 2.65
Novos filtros na lista Trabalhos permitem exibir apenas os trabalhos que você possui e somente os trabalhos aos que você tem acesso.
Confira Criar e executar trabalhos do Azure Databricks para obter mais informações.
Envio Spark da página Criar trabalho
13 a 20 de fevereiro de 2018: Versão 2.65
Agora você pode configurar parâmetros spark-submit na página Criar Trabalho, bem como por meio da API REST ou da CLI.

Confira Criar e executar trabalhos do Azure Databricks para obter mais informações.
Selecione Python 3 na página criar cluster
13 a 20 de fevereiro de 2018: Versão 2.65
Agora você pode especificar o Python versão 2 ou 3 na nova lista de opções da versão do Python ao criar um cluster. Se você não fizer uma seleção, o Python 2 será o padrão. Você também pode, como antes, criar clusters do Python 3 usando a API REST.
Aprimoramentos de interface do usuário do espaço de trabalho
13 a 20 de fevereiro de 2018: Versão 2.65
Adicionamos a capacidade de classificar arquivos por tipo (pastas, notebooks, bibliotecas) no navegador de arquivos do workspace e a pasta base sempre aparece na parte superior da lista Usuários.
Preenchimento automático para comandos SQL e nomes de banco de dados
13 a 20 de fevereiro de 2018: Versão 2.65
As células de SQL em notebooks agora fornecem o preenchimento automático de comandos SQL e nomes de banco de dados.
Pools sem servidor agora dão suporte a R
1 a 8 de fevereiro de 2018: Versão 2.64
Agora você pode usar o R em pools sem servidor.
XGBoost disponível como um pacote Spark
1 a 8 de fevereiro de 2018: Versão 2.64
A biblioteca de integração do Spark do XGBoost agora pode ser instalada no Azure Databricks como um pacote Spark da interface do usuário da biblioteca ou da API REST. Anteriormente, o XGBoost exigia a instalação da origem por meio de scripts de inicialização e, portanto, um tempo de atividade de cluster mais longo. Consulte Usar o XGBoost no Azure Databricks para obter mais informações.
Controle de acesso de tabela para SQL e Python (Beta)
1 a 8 de fevereiro de 2018: Versão 2.64
No ano passado, introduzimos o controle de acesso de objeto de dados para usuários do SQL. Hoje estamos felizes em anunciar a versão beta pública do controle de acesso de tabela (ACLs de tabela) para usuários do SQL e Python. Com o controle de acesso à tabela, você pode restringir o acesso a objetos protegíveis, como tabelas, bancos de dados, exibições ou funções. Pode também fornecer controle de acesso refinado (para linhas e colunas que correspondam a condições específicas, por exemplo), definindo permissões em exibições derivadas que contenham consultas arbitrárias.
Observação
- Esse recurso está em uma versão beta pública
- Esse recurso requer o Databricks Runtime 3.5 ou superior.
Confira Privilégios e objetos protegíveis do metastore do Hive (herdados) para mais detalhes.