Julho de 2018
Esses recursos e melhorias da plataforma Azure Databricks foram lançados em julho de 2018.
A API de bibliotecas dá suporte a arquivos wheel do Python
31 de julho a 7 de agosto de 2018: Versão 2.77
Agora você pode instalar bibliotecas wheel usando a API de Bibliotecas. Quando você instala uma biblioteca wheel em um cluster que executa o Databricks Runtime 4.2 ou posterior, todas as dependências especificadas no arquivo setup.py da biblioteca são incluídas. Quando você instala uma biblioteca wheel em um cluster que executa o Databricks Runtime 4.1 ou anterior, o arquivo é adicionado à variável PYTHONPATH, sem instalação das dependências.
Exportar notebook IPython
31 de julho a 7 de agosto de 2018: Versão 2.77
Quando você exporta um bloco de anotações do Azure Databricks para o formato de bloco de anotações do IPython, os resultados agora são incluídos na exportação.
Escopos de segredo com backup Azure Key Vault
19 a 24 de julho de 2018: Versão 2.76
Os segredos agora oferecem suporte a escopos com apoio de um Azure Key Vault. Após criar o escopo, você pode acessar todos os segredos no Key Vault correspondente desse escopo. Para obter detalhes, consulte Criar um escopo de segredo com apoio do Azure Key Vault.
Observação
O escopo do segredo com apoio do Azure Key Vault é uma interface somente leitura para o Key Vault. Para gerenciar segredos no Azure Key Vault, você deve usar a API REST Set Secret do Azure ou a interface do usuário do portal do Azure.
Espaços de trabalho de avaliação Premium
20 a 24 de julho de 2018: Versão 2.76
O Azure Databricks agora oferece espaços de trabalho de Premium de avaliação. Durante uma avaliação de 14 dias, você tem acesso gratuito a DBUs do Azure Databricks. Para obter mais informações, consulte Criar um espaço de trabalho.
Modo de cluster e clusters de Alta Simultaneidade
19 a 24 de julho de 2018: Versão 2.76
Na criação de um cluster, a opção de Tipo de Cluster foi renomeada para Modo de Cluster. A opção de Pool Sem Servidor foi substituída pelo modo de cluster de Alta Simultaneidade. Os clusters de Alta Simultaneidade são ajustados para fornecer utilização eficiente de recursos, isolamento, segurança e o melhor desempenho quando compartilhados por vários usuários simultâneos ativos. Um cluster de Alta Simultaneidade oferece suporte apenas a linguagens SQL, Python e R. Os clusters de Alta Simultaneidade oferecem todos os benefícios dos pools sem servidor, além de flexibilidade no Spark e na configuração de recursos. Para obter mais informações, consulte Clusters de Alta Simultaneidade.
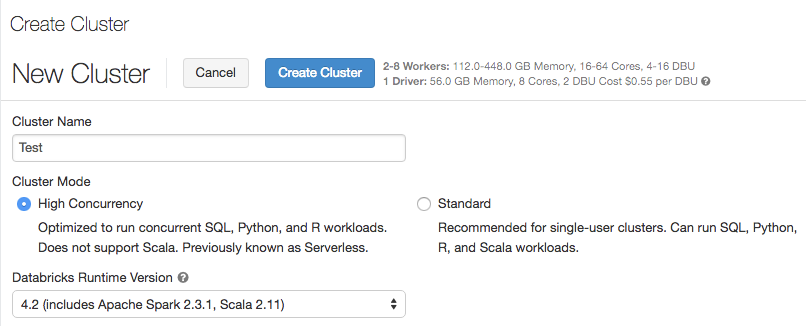
Controle de acesso de tabela
19 a 24 de julho de 2018: Versão 2.76
A caixa de seleção Controle de Acesso à Tabela está disponível apenas para clusters de Alta Simultaneidade.

Tipos de nó de cluster indisponíveis acinzentados
3 a 10 de julho de 2018: Versão 2.75
Os tipos de nó de cluster não disponíveis para sua assinatura e região agora aparecem esmaecidos e você não pode selecioná-los ao criar um cluster.
Markdown R com suporte
3 a 10 de julho de 2018: Versão 2.75
Os blocos de anotações do Azure Databricks R podem ser exportados para o formato R Markdown e documentos do R Markdown podem ser importados como blocos de anotações do Azure Databricks.
Reformulação da página inicial, com a capacidade de descartar arquivos para importar dados
3 a 10 de julho de 2018: Versão 2.75
A nova home page adiciona uma interface mais limpa e simples, com links para um tutorial de Introdução aprimorado e a possibilidade de arrastar e soltar arquivos para importar dados. Consulte Explorar e criar tabelas no DBFS.
Comportamento padrão de widget
3 a 10 de julho de 2018: Versão 2.75
O comportamento de execução padrão quando um novo valor é selecionado para um widget agora é Não Fazer Nada. Você deve atualizar as configurações do widget, se quiser executar um bloco de anotações completo ou apenas comandos relacionados a valores quando alterar um valor de widget. Confira Definir configurações de widget.
IU de criação de tabela
3 a 10 de julho de 2018: Versão 2.75
Ao criar uma tabela na interface do usuário, agora você seleciona Adicionar Dados na Página de Dados.
![]()
Consulte Explorar e criar tabelas no DBFS.
Importação de dados JSON de várias linhas
3 a 10 de julho de 2018: Versão 2.75
Agora você pode importar arquivos de dados JSON multilinha ao criar tabelas. Anteriormente, os arquivos de dados JSON tinham que ser combinados em uma única linha. Consulte Explorar e criar tabelas no DBFS.