Julho de 2020
Esses recursos e aprimoramentos da plataforma Azure Databricks foram lançados em julho de 2020.
Observação
As versões são disponibilizadas em fases. Talvez sua conta do Azure Databricks só seja atualizada uma semana após a data de lançamento inicial.
Terminal da Web (Versão Prévia Pública)
29 de julho – 4 de agosto de 2020: versão 3.25
O terminal da Web oferece uma maneira conveniente e altamente interativa para que os usuários com as permissão PODE ANEXAR AO em um cluster executem comandos do shell, incluindo editores como Vim ou Emacs. Alguns exemplos de uso do terminal da Web são o monitoramento do uso de recursos e a instalação de pacotes do Linux.
Para obter detalhes, consulte Terminal da Web.
Nova estrutura de script de inicialização global mais segura (Versão Prévia Pública)
29 de julho a 4 de agosto de 2020: Versão 3.25
A nova estrutura de scripts de inicialização global traz melhorias significativas em relação aos scripts de inicialização global herdados:
- Os scripts de inicialização são mais seguros, exigindo permissões de administrador para criar, exibir e excluir.
- As falhas de inicialização relacionadas ao script são registradas em log.
- Você pode definir a ordem de execução de vários scripts de inicialização.
- Os scripts de inicialização podem referenciar variáveis de ambiente relacionadas ao cluster.
- Os scripts de inicialização podem ser criados e gerenciados usando a página de configurações do administrador ou a nova API REST de Scripts de Inicialização Global.
O Databricks recomenda migrar os scripts de inicialização global herdados existentes para a nova estrutura a fim de aproveitar esses aprimoramentos.
Para obter detalhes, consulte Usar scripts de inicialização globais.
Listas de acesso de IP agora em GA
29 de julho a 4 de agosto de 2020: Versão 3.25
A API de Lista de Acesso de IP já está disponível para o público geral.
A versão de disponibilidade geral inclui uma alteração, que é a renomeação dos valores list_type:
WHITELISTemALLOWBLACKLISTemBLOCK
Use a API de Lista de Acesso de IP para configurar os workspaces do Azure Databricks e possibilitar que os usuários se conectem ao serviço apenas por meio de redes corporativas existentes em um perímetro seguro. Os administradores do Azure Databricks podem usar a API de Lista de Acesso de IP para definir um conjunto de endereços IP aprovados, incluindo listas de permissões e bloqueios. Todo o acesso de entrada ao aplicativo Web e às APIs REST exige que o usuário se conecte em um endereço IP autorizado, garantindo que os workspaces não possam ser acessados em uma rede pública como uma cafeteria ou um aeroporto, a menos que os usuários usem a VPN.
Esse recurso requer o plano Premium.
Para obter mais informações, confira Configurar listas de acesso IP para workspaces.
Nova caixa de diálogo de upload do arquivo
29 de julho a 4 de agosto de 2020: Versão 3.25
Agora você pode carregar pequenos arquivos de dados tabulares (como CSVs) e acessá-los em um notebook selecionando Adicionar dados no menu Arquivo do notebook. O código gerado mostra como carregar os dados em Pandas ou DataFrames. Os administradores podem desabilitar esse recurso na guia Avançado do console de administração.
Para obter mais informações, consulte Procurar arquivos no DBFS.
Melhorias na classificação e no filtro da API do SCIM
29 de julho – 4 de agosto de 2020: versão 3.25
A API SCIM agora inclui estas melhorias de filtragem e classificação:
- Os usuários administradores podem filtrar os usuários no atributo
active. - Qualquer usuário pode classificar os resultados usando os parâmetros de consulta
sortByesortOrder. O padrão é classificar por ID.
Regiões do Azure Government adicionadas
25 de julho de 2020
Recentemente, o Azure Databricks foi disponibilizado nas regiões US Gov - Arizona e US Gov - Virgínia para entidades do governo dos EUA e seus parceiros.
GA do Databricks Runtime 7.1
21 de julho de 2020
O Databricks Runtime 7.1 traz muitos recursos adicionais e aprimoramentos em relação ao Databricks Runtime 7.0, incluindo:
- Conector do Google BigQuery
- Comandos
%pippara gerenciar bibliotecas do Python instaladas em uma sessão do notebook - Koalas instalado
- Diversos aprimoramentos do Delta Lake, incluindo:
- Configurar metadados de confirmação definidos pelo usuário
- Obter a versão da última confirmação gravada pelo
SparkSessionatual - Converter tabelas Parquet criadas pelo fluxo estruturado usando o log de transações
_spark_metadata - Aprimoramentos no desempenho de
MERGE INTO
Para ver detalhes, confira as notas completas sobre a versão do Databricks Runtime 7.1 (sem suporte).
GA do Databricks Runtime 7.1 ML
21 de julho de 2020
O Databricks Runtime 7.1 para Machine Learning é criado com base no Databricks Runtime 7.1, e traz os novos recursos e alterações de biblioteca seguintes:
- Comandos mágicos Pip e Conda habilitados por padrão
- spark-tensorflow-distributor: 0.1.0
- pillow 7.0.0 -> 7.1.0
- pytorch 1.5.0 -> 1.5.1
- torchvision 0.6.0 -> 0.6.1
- horovod 0.19.1 -> 0.19.5
- mlflow 1.8.0 -> 1.9.1
Para ver detalhes, confira as notas completas sobre a versão do Databricks Runtime 7.1 para ML (sem suporte).
GA do Databricks Runtime 7.1 Genomics
21 de julho de 2020
O Databricks Runtime 7.1 para Genomics foi desenvolvido com base no Databricks Runtime 7.1 e inclui os seguintes novos recursos:
- Transformação LOCO
- Função de reformatação de saída GloWGR
- O RNASeq dá saída de alinhamentos não emparelhados
Databricks Connect 7.1 (Versão Prévia Pública)
17 de julho de 2020
O Databricks Connect 7.1 está agora em visualização pública.
Atualizações de API da lista de acesso de IP
15 a 21 de julho de 2020: Versão 3.24
As seguintes propriedades da API de Lista de Acesso de IP foram alteradas:
updator_user_idemupdated_bycreator_user_idemcreated_by
Os notebooks do Python agora dão suporte a várias saídas por célula
15 a 21 de julho de 2020: Versão 3.24
Os notebooks do Python agora dão suporte a várias saídas por célula. Isso significa que você pode ter qualquer número de instruções display, displayHTML ou print em uma célula. Aproveite a capacidade de exibir os dados brutos e o gráfico na mesma célula, ou todas as saídas que tiveram êxito antes de surgir um erro.
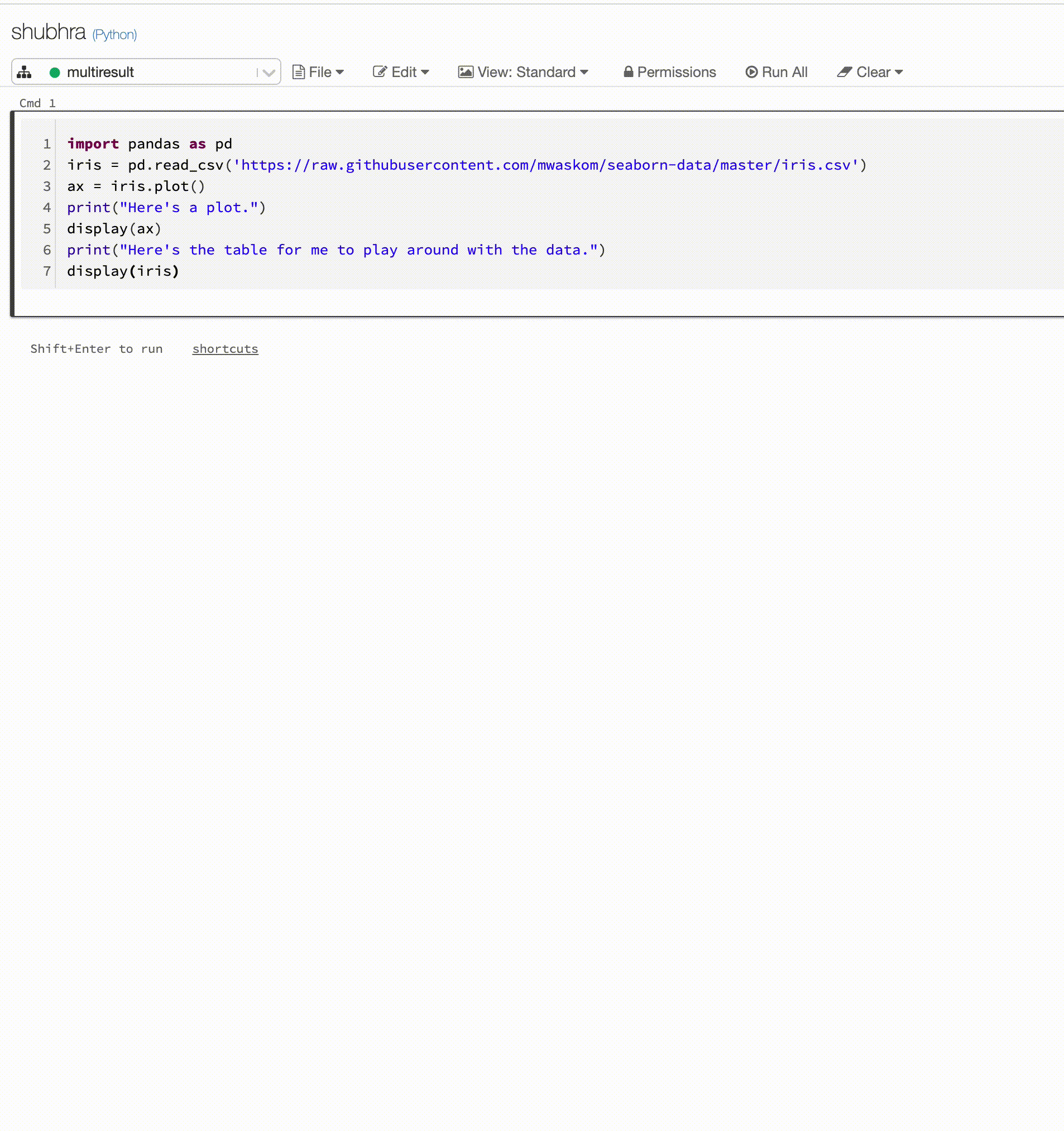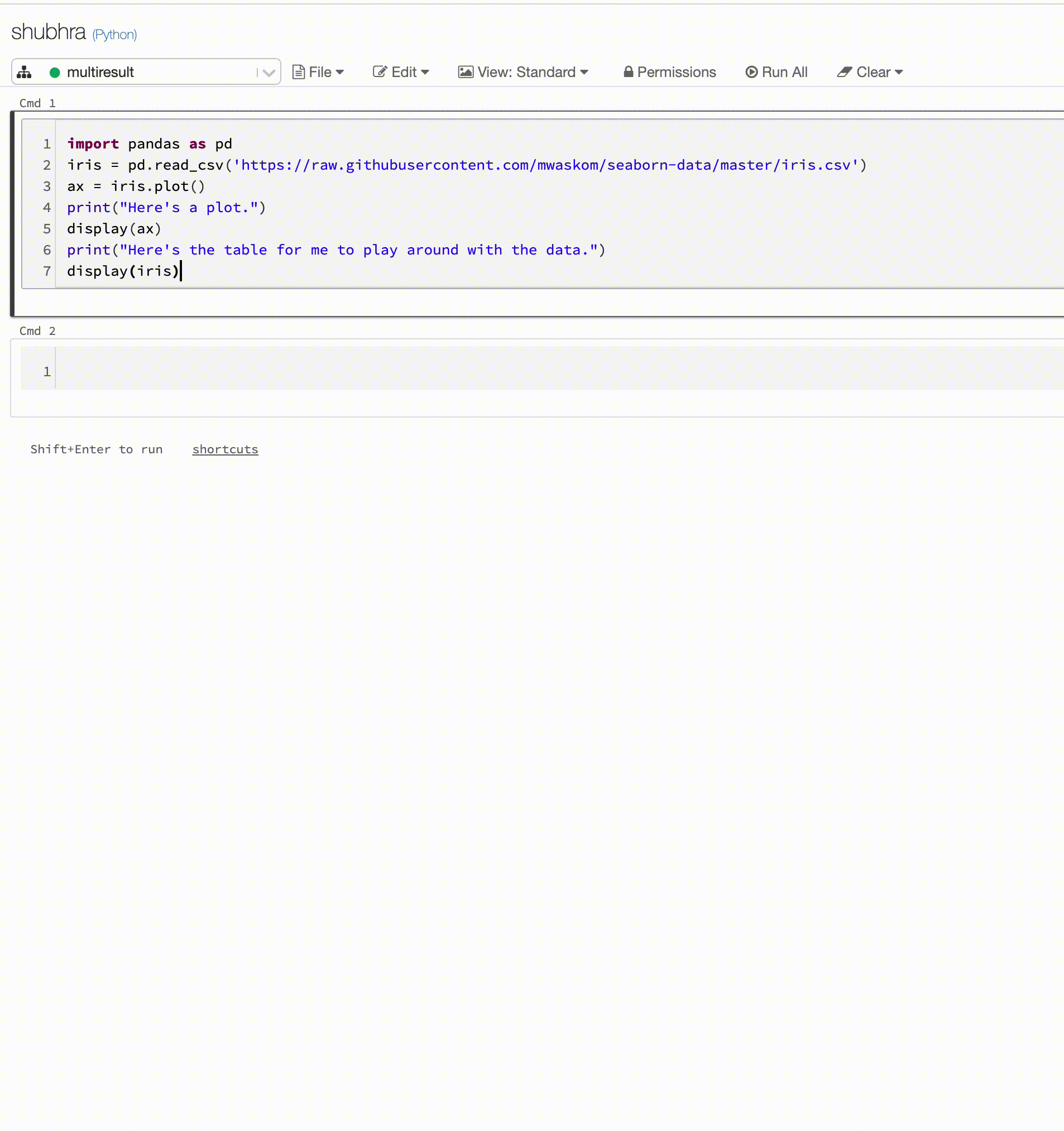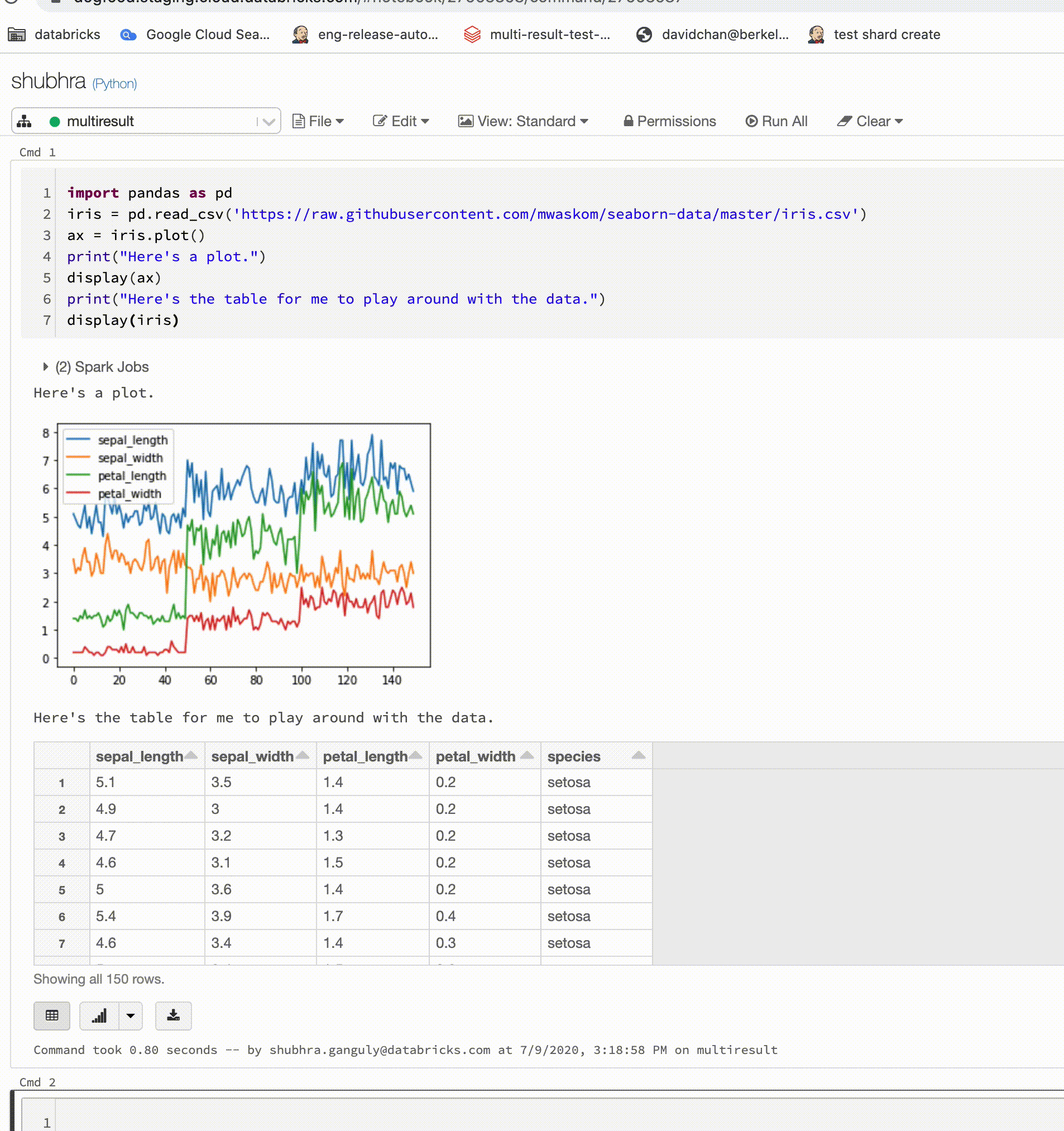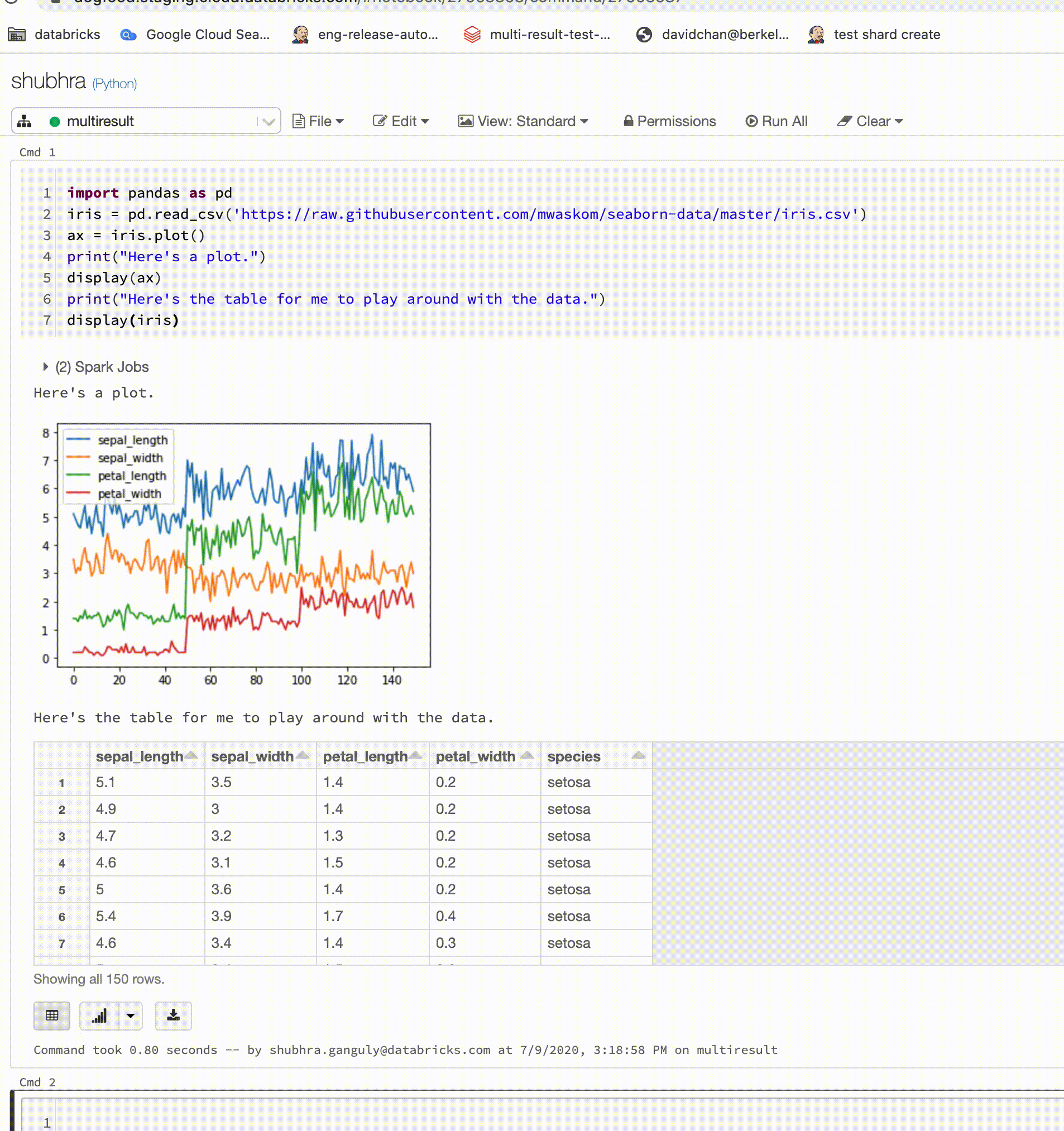
Este recurso requer o Databricks Runtime 7.1 ou superior, e está desabilitado por padrão no Databricks Runtime 7.1. Habilite-o configurando spark.databricks.workspace.multipleResults.enabled true.
Exibir as células de código e de resultados do notebook lado a lado
15 a 21 de julho de 2020: Versão 3.24
A nova opção de exibição de notebook lado a lado permite exibir o código e os resultado um ao lado do outro. Essa opção de exibição une a opção "Padrão" (anteriormente "Código") e a opção "Somente resultados".
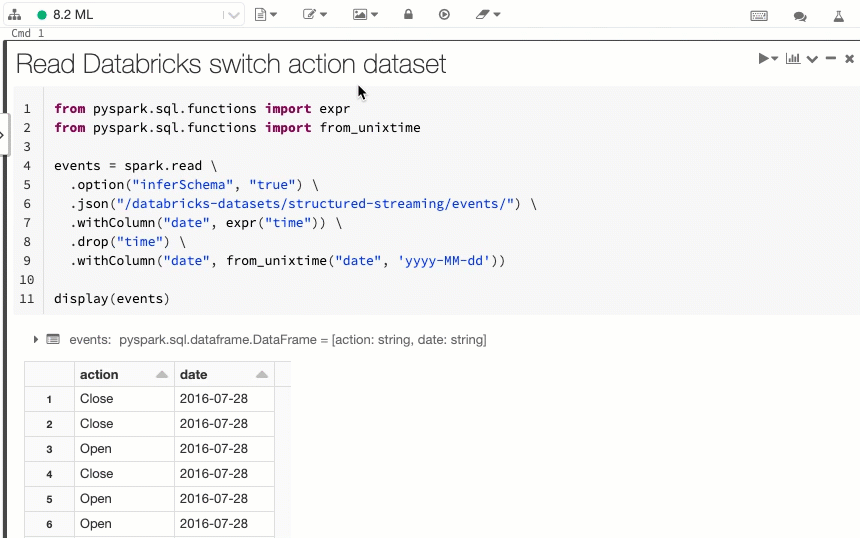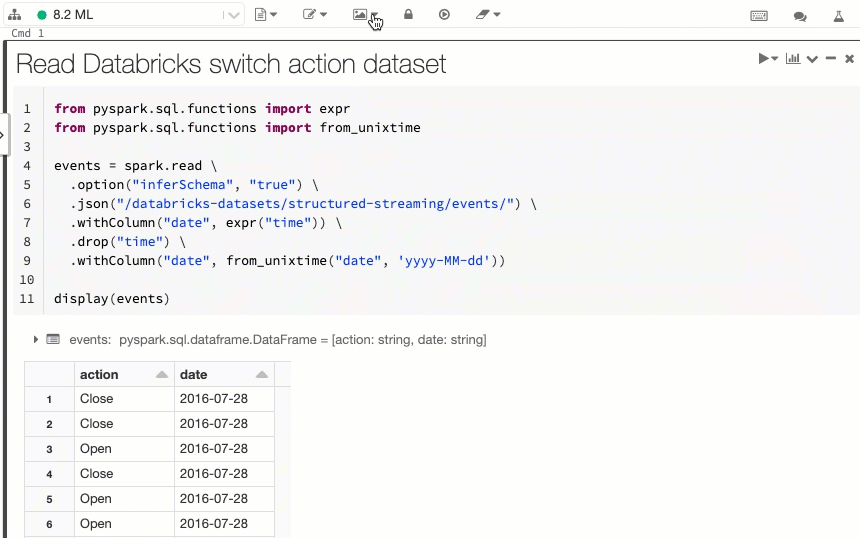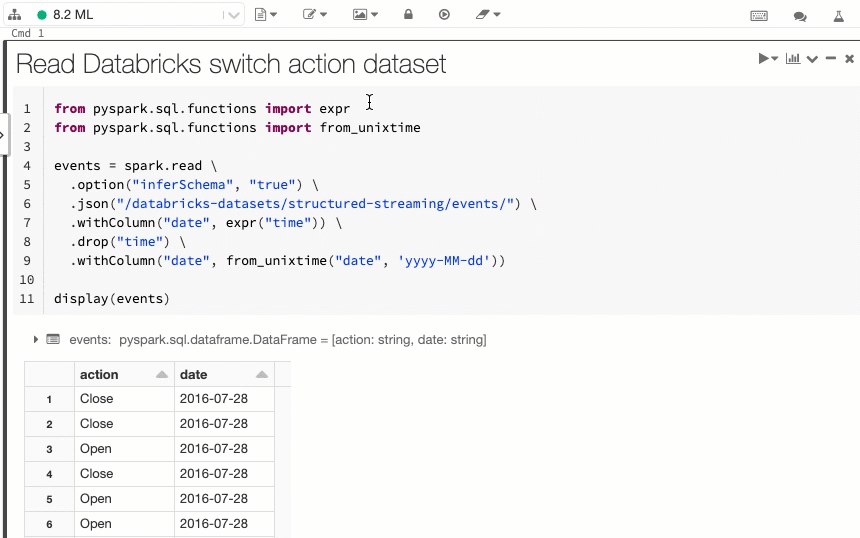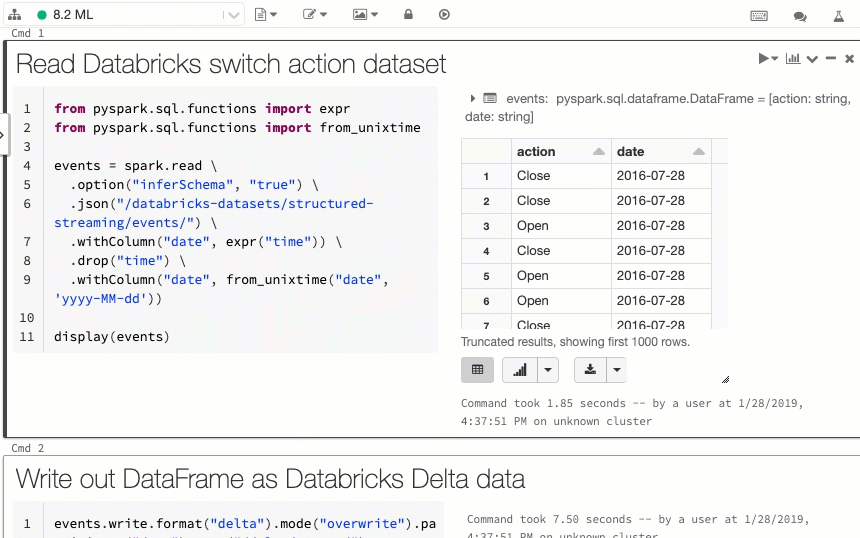
Pausar agendamentos de trabalhos
15 a 21 de julho de 2020: Versão 3.24
Os agendamentos de trabalhos agora têm botões de Pausar e Retomar, facilitando a pausa e a retomada dos trabalhos. Agora você pode fazer alterações em um plano de trabalho sem que as execuções de trabalho adicionais sejam iniciadas enquanto você estiver fazendo as alterações. Execuções atuais ou execuções disparadas por Executar agora não serão afetadas. Para obter detalhes, consulte Pausar e retomar um agendamento de trabalho.
Pontos de extremidade de API de trabalho validam a ID de execução
15 a 21 de julho de 2020: Versão 3.24
Os pontos de extremidade de API jobs/runs/cancel e jobs/runs/output agora validam que o parâmetro run_id é válido. Em caso de parâmetros inválidos, esses pontos de extremidade de API agora retornam o código de status HTTP 400 em vez do código 500.
Tokens do Microsoft Entra ID para autorizar a disponibilidade geral da API REST do Databricks
15 a 21 de julho de 2020: Versão 3.24
O uso de tokens do Microsoft Entra ID para autenticar-se na API do Workspace agora está em disponibilidade geral. Os tokens do Microsoft Entra ID permitem automatizar a criação e a configuração de novos workspaces. Entidades de serviço são objetos de aplicativo no Microsoft Entra ID. Você também pode usar entidades de serviço dentro de seus workspaces do Azure Databricks para automatizar fluxos. Para obter detalhes, consulte tokens do Microsoft Entra ID (anteriormente Azure Active Directory).
Formatar SQL em notebooks automaticamente
15 a 21 de julho de 2020: Versão 3.24
Agora é possível formatar células SQL do notebook de um atalho de teclado, do menu de contexto de comando e do menu Editar do notebook (selecione Editar > Formatar células SQL). A formatação SQL facilita a leitura e a manutenção de código com pouco esforço. Ela funciona em blocos de anotações SQL e em células %sql.

Ordem reproduzível de instalação para bibliotecas Maven e CRAN
1 a 9 de julho de 2020: Versão 3.23
O Azure Databricks agora processa bibliotecas Maven e CRAN na ordem em que foram instaladas no cluster.
Assuma o controle dos tokens de acesso pessoal dos seus usuários com a API de Gerenciamento de Tokens (versão prévia pública)
1 a 9 de julho de 2020: Versão 3.23
Agora, os administradores do Azure Databricks podem usar a API de Gerenciamento de Tokens para gerenciar os tokens de acesso pessoal do Azure Databricks dos usuários:
- Monitorar e revogar tokens de acesso pessoal dos usuários.
- Controlar o tempo de vida de tokens futuros no seu workspace.
- Gerenciar quais usuários podem criar e usar tokens.
Consulte Monitorar e gerenciar tokens de acesso pessoal.
Restaurar células do notebook recortadas
1 a 9 de julho de 2020: Versão 3.23
Agora é possível restaurar células do notebook que foram recortadas. Basta usar o atalho de teclado (Z) ou selecionar Editar > Desfazer Recortar células. Essa funcionalidade é análoga àquela usada para desfazer a exclusão de células.
Atribua a permissão PODE GERENCIAR trabalhos a usuários não administradores
1 a 9 de julho de 2020: Versão 3.23
Agora é possível atribuir a usuários e grupos não administradores a permissão PODE GERENCIAR para trabalhos. Esse nível de permissão permite que os usuários gerenciem todas as configurações do trabalho, incluindo a atribuição de permissões, a alteração do proprietário e a alteração da configuração do cluster (por exemplo, adição de bibliotecas e modificação da especificação do cluster). Confira Controlar o acesso a um trabalho.
Usuários não administradores do Azure Databricks podem ver nomes de usuário e filtrar por esses nomes usando a API SCIM
1 a 9 de julho de 2020: Versão 3.23
Os usuários que não são administradores agora podem exibir nomes de usuário e filtrar usuários por nome_do_usuário usando o ponto de extremidade SCIM/Usuários.
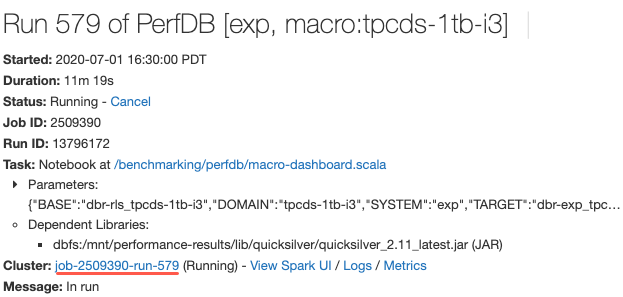
Link para ver a especificação do cluster na exibição de detalhes da execução do trabalho
1 a 9 de julho de 2020: Versão 3.23
Agora, ao exibir os detalhes de uma execução de trabalho, você pode clicar em um link para a página de configuração de clusters para exibir a especificação do cluster. Anteriormente, você precisaria copiar a ID do trabalho da URL e ir procurá-la na lista de clusters.